ByteBuffer源码分析
在进行数据传输的时候,往往需要使用到缓冲区,常用的缓冲区就是JDK NIO类库中提供的java.nio.Buffer,实现类如下:
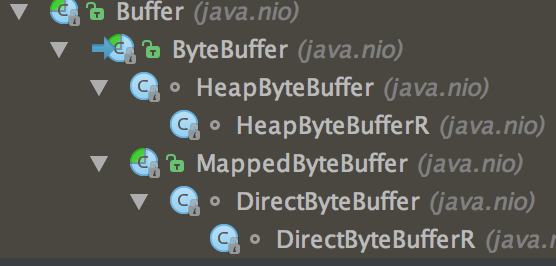
在使用NIO编程时,最常用的是其中的ByteBuffer,本篇分析ByteBuffer内部的源码实现,顺序从父类Buffer入手,了解父类中基础API的实现,再到各个实现子类的实现。
Buffer
Buffer是存放一种特定的、原始的数据的容器。Buffer是一种特定原始类型元素的线性的有限序列集合,其核心的属性有capacity、limit、Position。

capacity:Buffer的容量,表示可以容纳的元素数量
limit:表示第一个不可以被读取或者写入的元素的位置
position:表示下一个被读取或者写入的位置
三者之间的关系如下:0<=position<=limit<=capacity
Buffer只有一个构造方法:

这个构造方式是protected的,也就是说只有在包内可以调用。构造方法中除了capacity、limit、position外还有一个mark参数,且校验了mark参数必须小于position。这个参数非常简单,用于标记position的当前位置,在进行读取写入之类的操作之后可以通过API重新将position重置到标记的位置,对应的API为:Buffer#mark()\Buffer#reset()
Buffer中一个比较重要的API是Buffer#flip
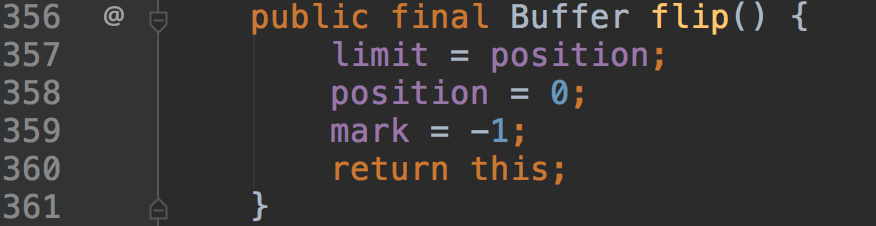
这个方法就是将limit设置到position位置,将position调整到0,将mark设置为-1。
为什么需要有这么一个方法调整位置呢?
这个主要和Buffer只有一个position作为游标相关,读写都是基于position的,所以在写操作完成之后需要进行读操作时,需要将limit设置为position标记有写到哪儿了,而将position 重新移到0,这样就可以读取到所有的写入数据。假设如果有两个游标分别表示读取和写入的位置,是否就可以不用这个API了呢?
Buffer中的代码都非常简单,主要就是自身属性信息的设置和返回,像返回position、返回limit信息等,展开细看。
ByteBuffer
ByteBuffer是Buffer的一个子类,是字节缓冲区。ByteBuffer在Buffer之上定义了6中操作:
- 通过当前位置和指定位置的方式读取和写入byte
- 通过get(byte[])的方式将ByteBuffer中的数据读取到byte[]中
- 通过put(byte[])的方式将连续大量的byte数据写入缓冲区
- 通过当前位置和指定位置的方式将其他类型的数据写入缓冲区或从缓冲区读取数据转换成特定类型
- 提供将ByteBuffer转换成其他类型的Buffer视图的方法,例如ByteBuffer#asCharBuffer
- 提供compact、duplicate、slice来执行一些对ByteBuffer的操作
ByteBuffer的构造方法如下:
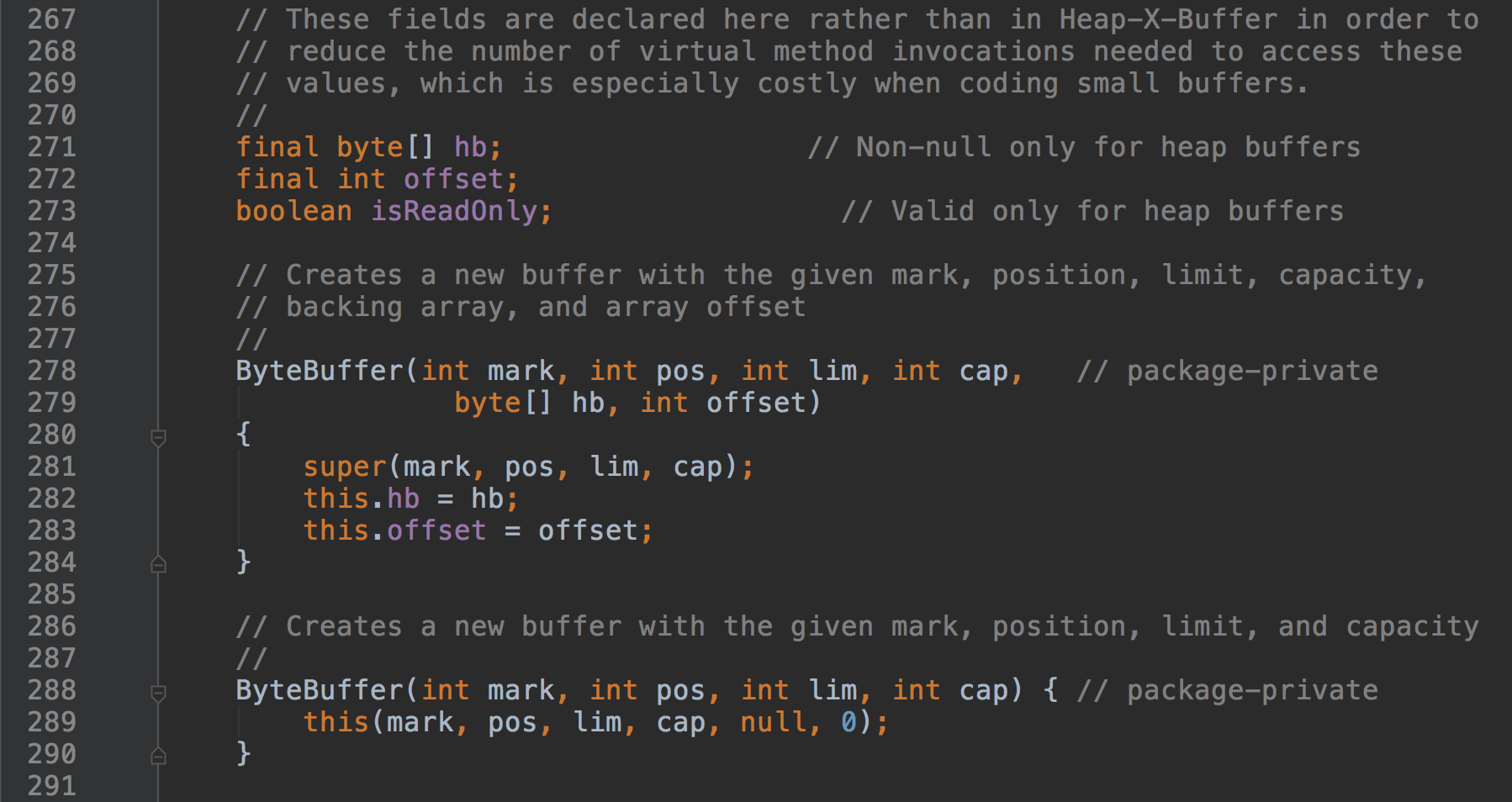
提供了两个构造方法,相对于Buffer增加了一个byte数组和一个offset。byte数组用于存储数据,offset表示ByteBuffer背后实际用于存储的byte数据的其实位置。即你可以使用一个byte数据,从它的任何一个下标开始存储数据,而不一定是0。
当然,这两个方法都是protected的,也就是说实际我们“不能”通过这两个方法去构造我们需要的缓冲区。
那么当我们需要使用缓冲区的时候我们如何去构造一个呢?ByteBuffer提供了两个API:ByteBuffer#allocateDirect、ByteBuffer#allocate
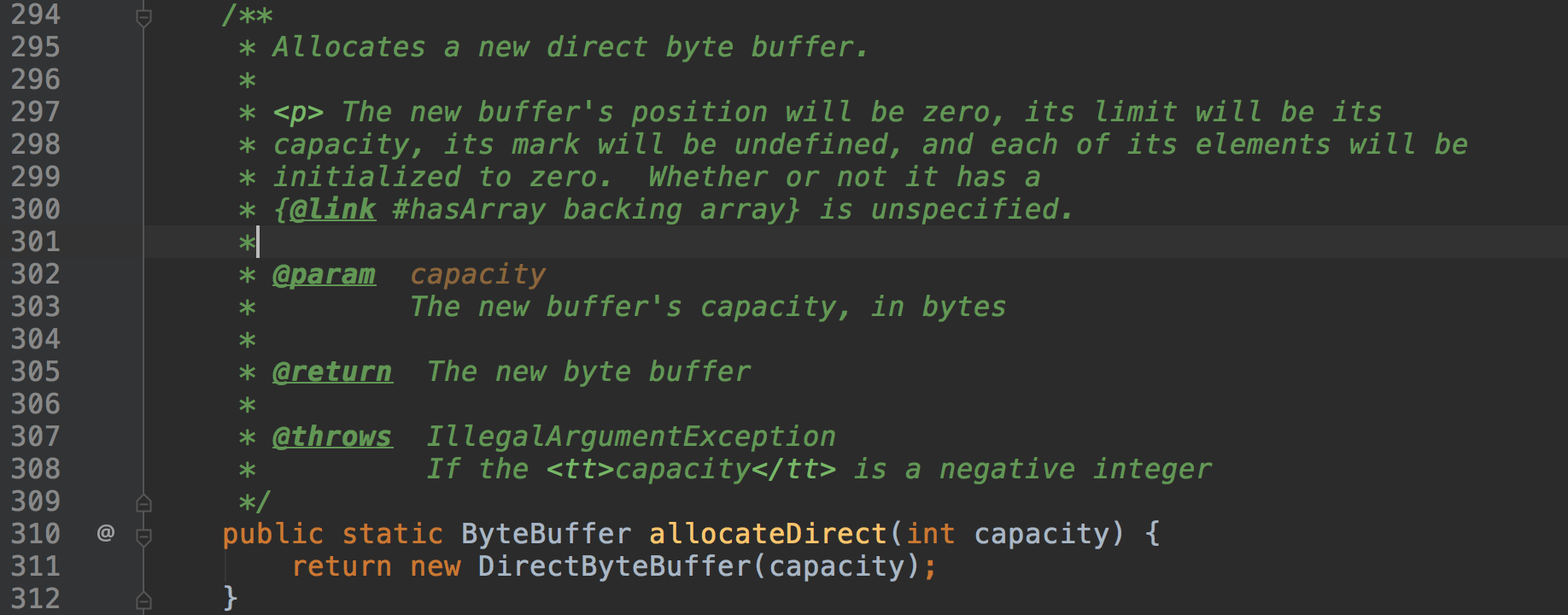
ByteBuffer#allocateDirect分配一个DirectByteBuffer,即这个缓冲区是使用堆外内存的。
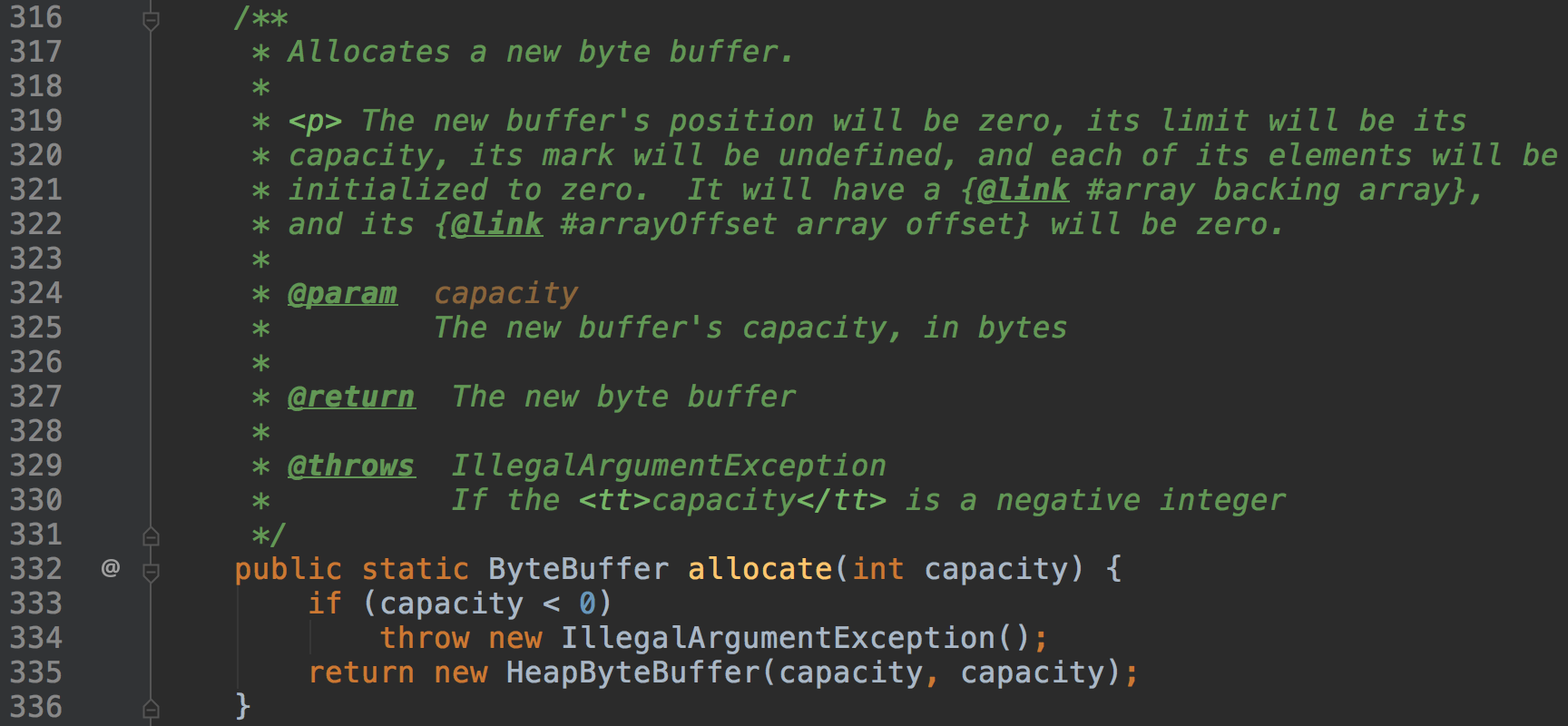
ByteBuffer#allocate在JVM堆上分配一块内存。
新分配的内存position都是0,limit为容量,初始内部填充的数据都为0。
除了通过allocate去创建ByteBuffer,还有一种方式是通过wrap来包装一个byte数组,这样就可以使用ByteBuffer的API来对byte数据进行操作。

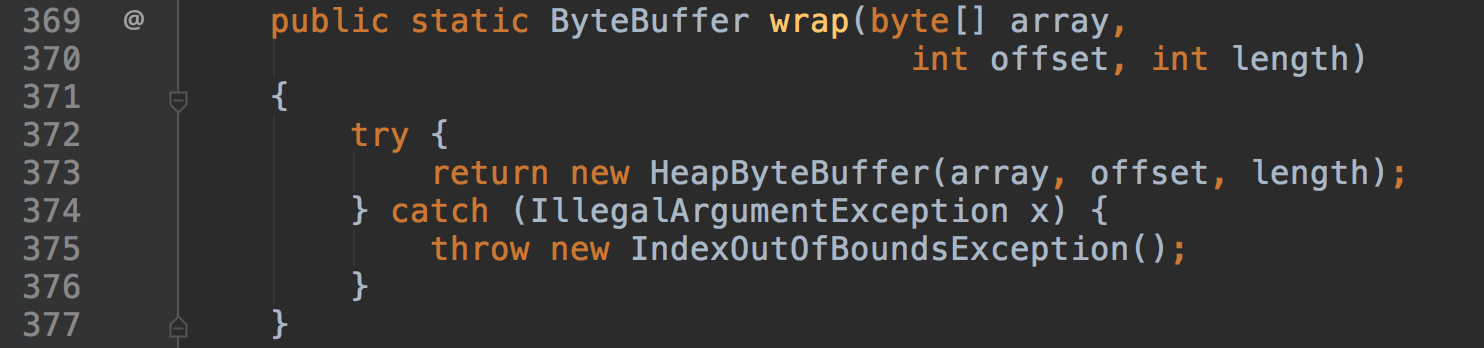
因为byte数据本身在堆内,所以wrap的ByteBuffer也就是HeapByteBuffer。
offset和length将被作为ByteBuffer初始的position和limit。
allocate和wrap都是创建了“新”的ByteBuffer,这里新的含义是他们背后都有自己独立的byte数组用于存储数据。还有一类API,他们也创建ByteBuffer,但是它只是个视图,拥有自己的position、limit等属性,但是存储的byte数组是共享的:
- ByteBuffer#slice:创建一个的ByteBuffer,内容是当前ByteBuffer的一个子序列,共享一个byte数组;两个ByteBuffer的position、limit、mark是独立的;新ByteBuffer的起始位置是原ByteBuffer的position位置
- ByteBuffer#duplicate:“复制”一个ByteBuffer,共享存储的byte数据,拥有独立的capacity、limit、position、mark属性;如果当前ByteBuffer是DirectByteBuffer,那么新Buffer也是DirectByteBuffer,如果当前是HeapByteBuffer,那么新分配的也是HeapByteBuffer
ByteBuffer提供另外一类API来将自己转换成另一个类型的缓冲区:
- ByteBuffer#asXXXBuffer:比如asLongBuffer创建一个新的LongBuffer,底层的存储还是共享当前的byte数组,同时拥有自己的position、limit、mark属性,新Buffer的position为0,limit和capacity为原Buffer除8,因为一个long类型占用8个byte;其他asXXXBuffer方法都类似
ByteBuffer中还有一类API是提供基于当前位置或者指定位置来读写数据的:
- byte getByte()
- byte getByte(int index)
- int getInt()
- int getInt(int index)
- ...
这两种API的差异是没有参数的API会从当前position开始读取数据,之后会修改position位置。而通过传入index,会从index开始读取数据,不会变更position信息。所以如果只是要读取数据,并不希望更改Buffer本身的信息(position),应该使用带有参数的方法。
ByteBuffer的内容只有这么多,接着看它的子类实现,主要是HeapByteBuffer和DirectByteBuffer。
HeapByteBuffer
HeapByteBuffer顾名思义就是JVM堆上的字节缓冲区,他用于缓存数据的byte数组就是直接在堆内申请的。默认的构造方法直接就是new一个byte数组作为数据存储的缓冲区。
HeapByteBuffer非常简单,就是实现了ByteBuffer定义的各种put和get方法,没有什么好分析的。
DirectByteBuffer
DirectByteBuffer翻译过来就是直接的字节缓冲区,它是使用直接内存的,即不从JVM的堆上分配内存。
首先看DirectByteBuffer的一个内部类:Deallocator。从类名可以看出这个类应该是做“回收的”。
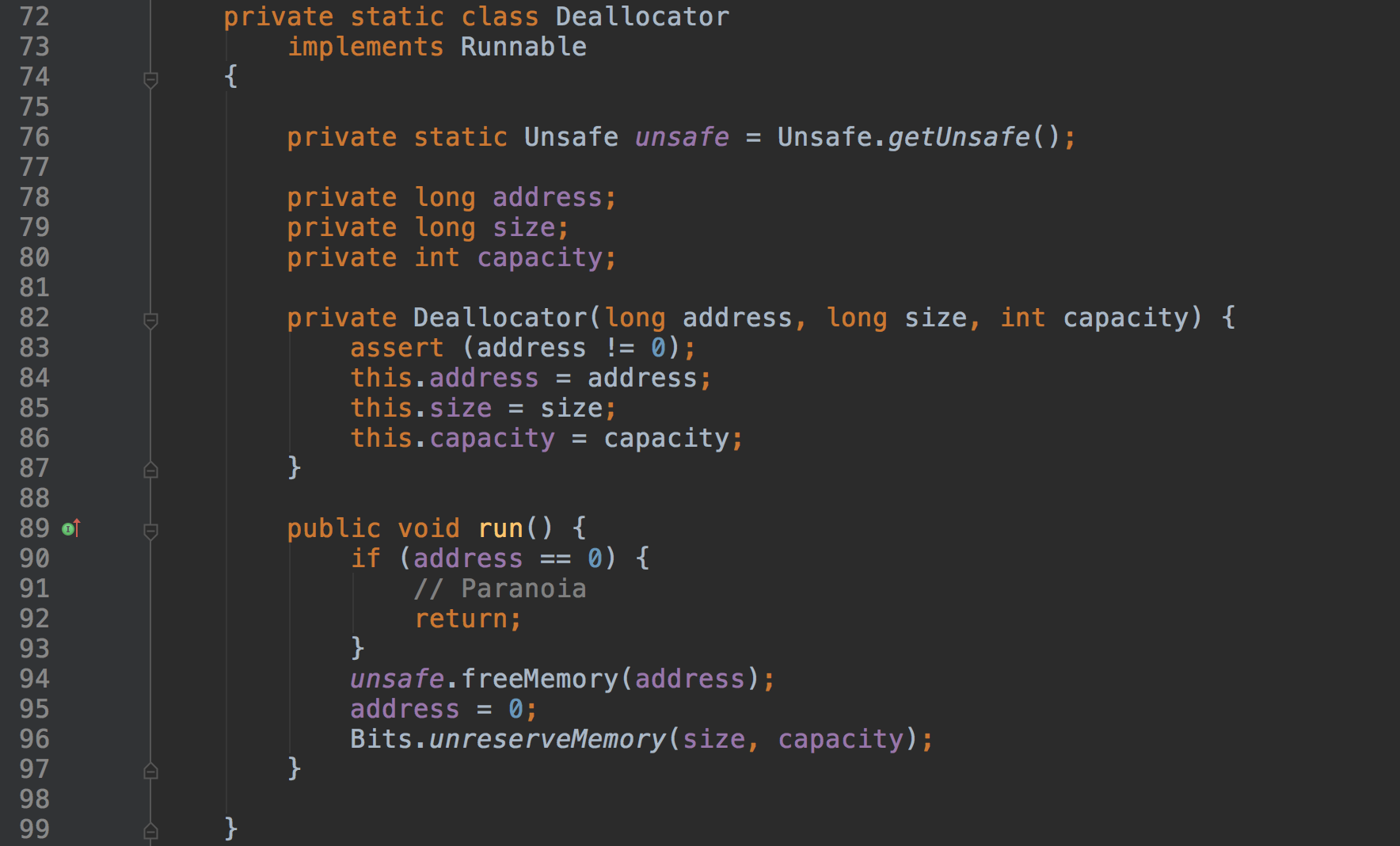
从代码看,Deallocator实现了Runnable接口,run方法内的实现就是通过unsafe释放内存。


结合Cleaner就能明白Cleaner是统一的接口,返回Cleaner来执行清楚操作,而真正的内存回收在Deallocator中执行。
接着看DirectByteBuffer的构造方法:
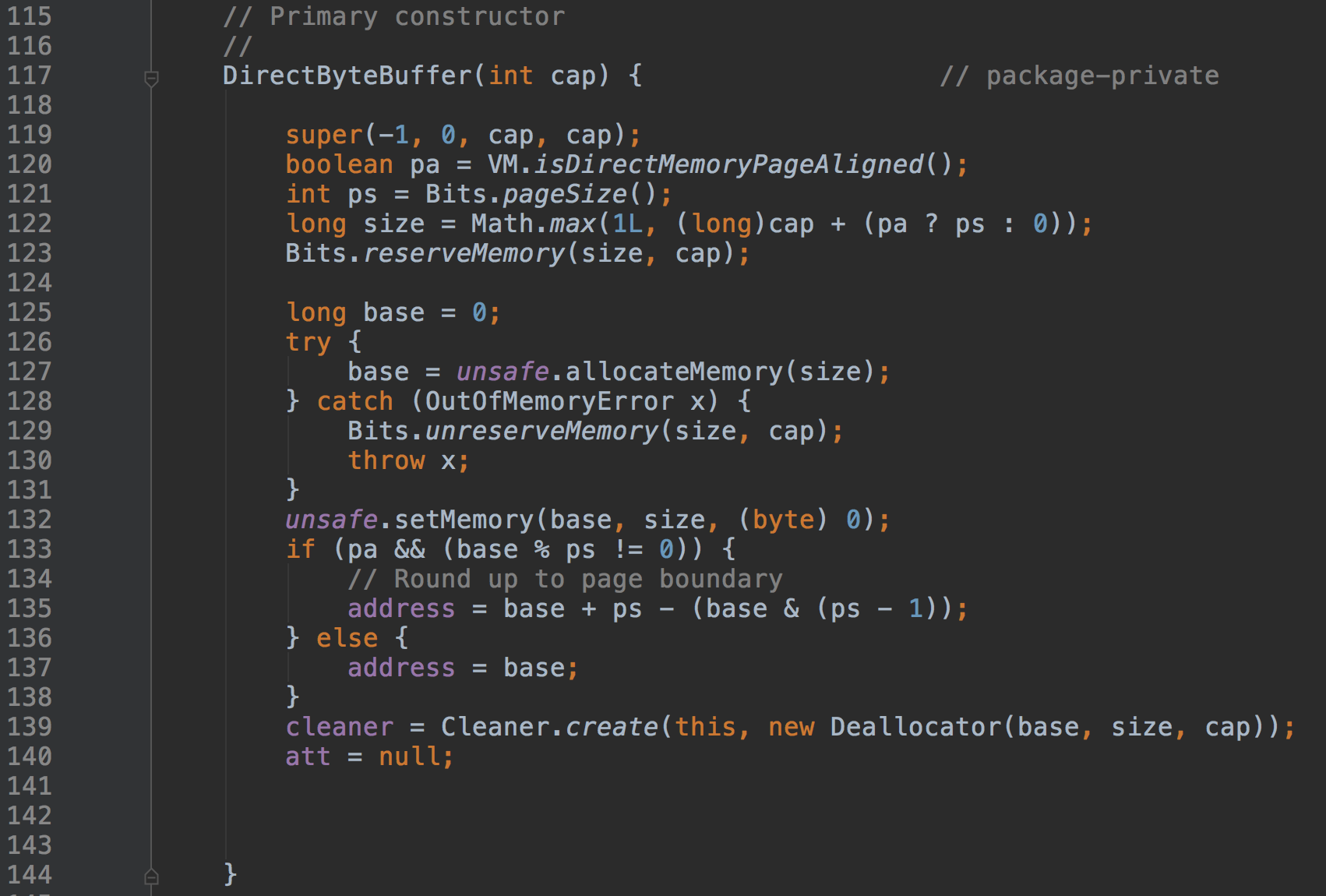
只有一个容量作为参数,而内存是直接通过unsafe分配的,可见内存是直接分配的,而不是在堆上申请的。另外这是一个受保护的方法,也就是说用户是不能直接调用的。
另外还有几个构造方法,可以直接通过内存地址来初始化,或者通过文件描述符来初始化(For memory-mapped buffers),通过已近存在的DirectBuffer来初始化。

这些方法都是提供给MMAP之类的使用的,一般用户都不会直接调用到。
剩下的方法,像是slice、duplicate,包括通过address返回内存地址都非常简单就不描述了。
另外DirectByteBuffer内部还有一个特殊的方法是asReadOnlyBuffer方法,返回了一个DirectByteBufferR对象。下面看一下DirectByteBufferR做了些什么。
简单从方法出发,大概就是返回只读的一个对象,不能做写入操作。

实际上也是非常简单,所有的put操作都抛出了异常。剩下get和slice等也类似,不再赘述。
----------------------------------------------------------------------------------------------------------------------------

这是我的公众号,计划写一个《从0到写一个消息中间件》的系列,目前写了第一篇《什么是消息中间件》,欢迎关注交流。
ByteBuffer源码分析的更多相关文章
- Buffer的创建及使用源码分析——ByteBuffer为例
目录 Buffer概述 Buffer的创建 Buffer的使用 总结 参考资料 Buffer概述 注:全文以ByteBuffer类为例说明 在Java中提供了7种类型的Buffer,每一种类型的Buf ...
- zookeeper源码分析之四服务端(单机)处理请求流程
上文: zookeeper源码分析之一服务端启动过程 中,我们介绍了zookeeper服务器的启动过程,其中单机是ZookeeperServer启动,集群使用QuorumPeer启动,那么这次我们分析 ...
- zookeeper源码分析之三客户端发送请求流程
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的 ...
- MyCat源码分析系列之——结果合并
更多MyCat源码分析,请戳MyCat源码分析系列 结果合并 在SQL下发流程和前后端验证流程中介绍过,通过用户验证的后端连接绑定的NIOHandler是MySQLConnectionHandler实 ...
- MyCat源码分析系列之——BufferPool与缓存机制
更多MyCat源码分析,请戳MyCat源码分析系列 BufferPool MyCat的缓冲区采用的是java.nio.ByteBuffer,由BufferPool类统一管理,相关的设置在SystemC ...
- MyCat源码分析系列之——前后端验证
更多MyCat源码分析,请戳MyCat源码分析系列 MyCat前端验证 MyCat的前端验证指的是应用连接MyCat时进行的用户验证过程,如使用MySQL客户端时,$ mysql -uroot -pr ...
- Spark技术内幕:Stage划分及提交源码分析
http://blog.csdn.net/anzhsoft/article/details/39859463 当触发一个RDD的action后,以count为例,调用关系如下: org.apache. ...
- soundtouch源码分析__based on csdn :
1. soundtouch介绍和相关资源 The SoundTouch Library Copyright © Olli Parviainen 2001-2014 SoundTouch is an o ...
- 【Zookeeper】源码分析之持久化--FileTxnLog
一.前言 前一篇已经分析了序列化,这篇接着分析Zookeeper的持久化过程源码,持久化对于数据的存储至关重要,下面进行详细分析. 二.持久化总体框架 持久化的类主要在包org.apache.zook ...
随机推荐
- 关于使用JavaScript实现图片点击切换(附带改变导航图片 方案二)
具体需求见方案一. 这种方案相比方案一更加专业. <!DOCTYPE html> <html> <head lang="en"> <met ...
- hadoop配置文件的作用
core-site.xml <property> //指定hdfs的主端口 namenode要放在哪台机器上 <name>fs.defaultFS</name> & ...
- MySQL数据库操作常用命令
MySQL数据库操作常用命令DOS连接数据库1.安装MySQL配置好环境2.运行cmd命令net start mysql3.找到mysql文件根目录输入命令mysql -h localhost -u ...
- HTML5 02. 多媒体控件、拖拽事件、历史记录、web存储、应用程序缓存、地理定位、网络状态
多媒体 video:是行内块(text-align: center; 对行内块适用) <figure></figure>: 多媒体标签 : <figcaption> ...
- kotlin 语言入门指南(二)--代码风格
语言风格 这里整理了 kotlin 惯用的代码风格,如果你有喜爱的代码风格,可以在 github 上给 kotlin 提 pull request . 创建DTOs(POJSs/POCOs) 文件: ...
- java虚拟机内存分配
- Windows Server 2016中,安装PHP Manager,ARR3.0或者URL Rewrite 2.0无法成功的解决办法
如图: 无法安装原因都是这几个工具无法识别10.0这个版本,可以修改注册表来先完成安装,然后再改回去 PHPManager的修改方法如下: 打开注册表工具(运行Regedt32),找到:HKEY_LO ...
- Python爬虫01——第一个小爬虫
Python小爬虫——贴吧图片的爬取 在对Python有了一定的基础学习后,进行贴吧图片抓取小程序的编写. 目标: 首先肯定要实现图片抓取这个基本功能 然后实现对用户所给的链接进行抓取 最后要有一定的 ...
- A Bayesian election prediction, implemented with R and Stan
If the media coverage is anything to go by, people are desperate to know who will win the US electio ...
- matlab错误:Subscript indices must either be real positive integers or logicals.
matlab错误:Subscript indices must either be real positive integers or logicals. 中文解释:下标索引必须是正整数类型或者逻辑类 ...