浅析SQL Server数据库中的伪列以及伪列的含义
本文出处:http://www.cnblogs.com/wy123/p/6833116.html
SQL Server中的伪列
下午看QQ群有人在讨论(非聚集)索引的存储,
说,对于聚集索引表,非聚集索引存储的是索引键值+聚集索引键值;对于非聚集索引表,索引存储的是索引键值+RowId,这应该是一个常识,对此不作具体详细阐述。
这里主要是提到的RowId引起了一点思考。
那么,这个RowId是个什么玩意?能不能更加直观一点来看看RowId的信息?代表什么含义?这个当然也是可以的。
Oracle中的表中有一个伪列的概念,就是在查询表的时候加上select rowid,* from Table,会查询出来伪列。
SQL Server中同样有这么一个伪列,在SQL Server中,这个伪列可以认为是数据行的物理地址,下面简单来观察一下这个RowId以及RowId的含义。
伪列的测试
建一张简单的表,下面借助这个表来查看说明伪列
CREATE TABLE Test
(
id int identity(1,1),
name varchar(50)
)
GO INSERT INTO Test VALUES (NEWID())
GO 100
SQL Server中有一个未公开的伪列“%%physloc%%”,也就是在查询的时候,对于任何一张表,可以加上这个字段,比如如下,就可以查到表中每一行的伪列。
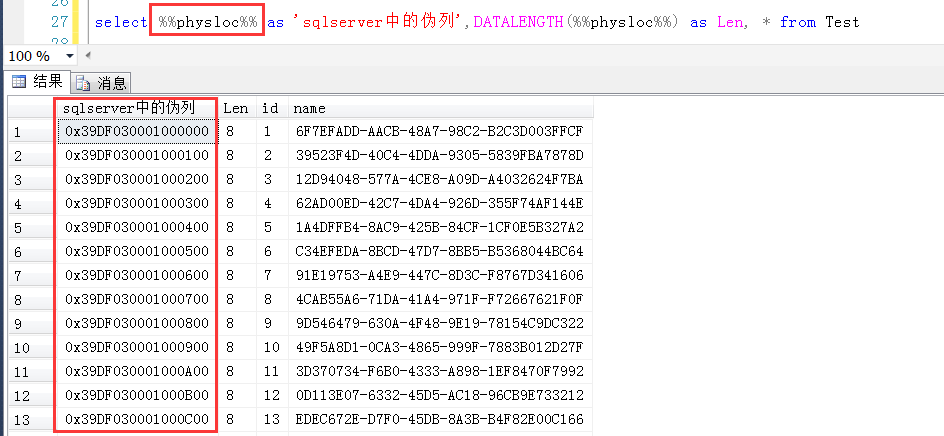
这个伪列的类型是binary(8),也就是有8个字节,参考上图的DATALENGTH(%%physloc%%) as Len,
%%physloc%%返回的记录的物理地址,其中前四个字节表示页号,中间两个字节表示文件号,最后两个字节表示槽号
为了更加方便地观察伪列的含义,sqlserver提供了一个未公开的系统函数sys.fn_PhysLocFormatter,下面借助sys.fn_PhysLocFormatter这个函数来继续观察这个伪列
如下图,这里就可以清晰地看到伪列中的信息了。
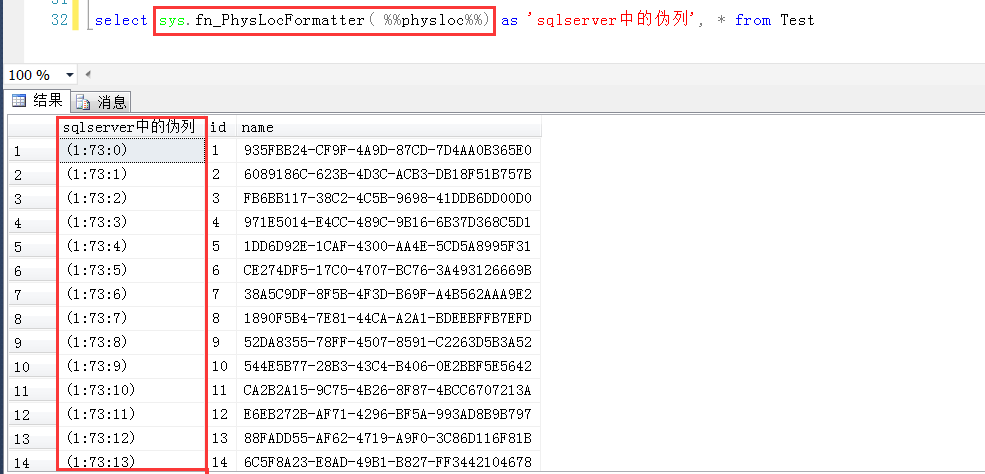
比如第一行中的(1:73:0),上面说了,其中前四个字节表示页号,中间两个字节表示文件号,最后两个字节表示槽号,
(1:73:0)这种格式是经过sys.fn_PhysLocFormatter格式化显式之后的结果。
把文件号1放在最前面,中间的73是页号(page number),最后一位0是槽号(sloc number)。
下面粗略地说一下这几个字段的含义。这里要求对SQL Server的存储只是有一个基本的认识,否则看的云里雾里。
1,首先说什么是文件号
如截图,文件号就是数据库的数据文件编号,这里只有一个数据文件,文件编号为1,
建表的时候默认(这里也只能建立)建立在fileid = 1 的文件上面,fileid=2的是日志文件,就不多说了。

2,其次是页号,页号就是分配给当前这张表的数据页面(8kb的最小分配单元)的页号,我们看一下Test这个表的页面情况
借助DBCC IND命令,查询分配给这个表的页面信息,其中77号页面是IMA也面,至于什么事IMA页面,不多解释。
73号页面才是真正存储数据的页,与上面的1:73:0中的73一样,没毛病。

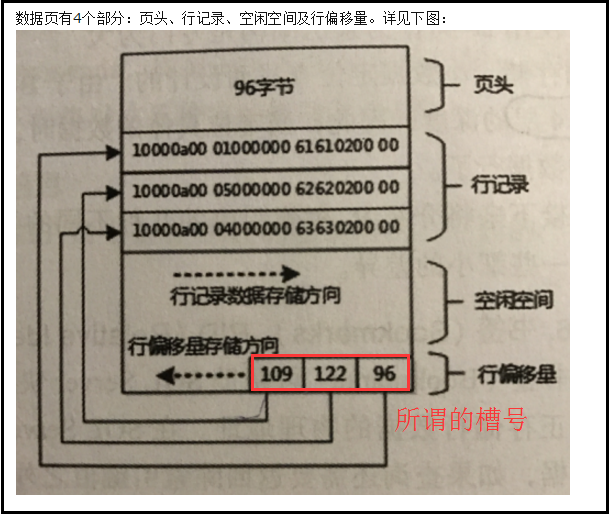
3,最后看一下槽号,槽号的概念要对SQL Server的数据页面有一个基本的认识,这里盗用一张网友的图。
所谓的槽号就是在数据页面中,每个页面存储多行数据,槽号用来标记每一行数据的偏移量,用大白话说就是“存储每一行数据的地址空间开始的位置”,
因为每一行数据的总长度是不一样的(存在可变长度列的情况下),每一行的占用的存储空间也是不一样的,
槽号或者行偏移量就是说明每一行数据在页内的开始位置。
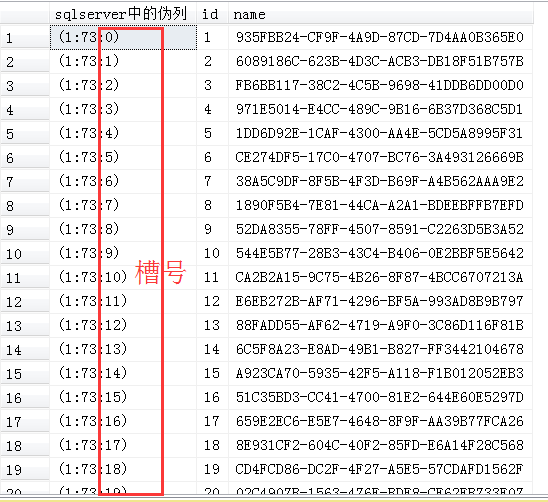
不过sys.fn_PhysLocFormatter格式化显式的槽号并不是如下截图的偏移量,而是第N个数据行的这个N的信息,
因此第1行的槽号就是1,第2行的槽号就是2,以此类推,当第一个page存储满之后,从第二个page开始存储,槽号又从0开始编号且累加
至此,对SQL Server的伪列,也就说经常说的RowId有了一个简单的认识。
这里可以认为,在SQL Server数据库中,伪列RowId就是数据行的物理地址,至于别的数据库中的伪列(RowId)是不是物理地址倒是不确定(很有可能也是的)
这里简单提一下一开始说的一个问题:
为什么SQL Server的聚集表(有聚集索引的表)存储数据的时候存储的是“索引键值+聚集索引键值”,对于非聚集索引表,索引存储的是索引键值+RowId?
或者反过来说,为什么聚集索引表的非聚集索引存储的是“索引键值+聚集索引键值”而不是“索引存储的是索引键值+RowId”
作为一个常识,聚集索引要按照聚集索引的顺序存放,这就意味着聚集索引表的行数据物理位置有可能发生变化,比如在众所周知的“页拆分(page split)”中发生变化,
在数据行的物理位置发生了变化的时候,如果非聚集索引存储的是索引键值+RowId,那么这个RowId也势必要发生变化,这个变化当然要耗费一定的性能,
为了防止此种情况的发生,聚集表中的非聚集索引存储成相对不变的索引键值+聚集索引键值,因为在数据行的物理位置发生变化的时候,聚集索引键值是相对不变的,这一点也不难理解。
当然有一种例外,当对聚集索引表做更新的时候,直接更新聚集索引的键值,这样的话,也有可能造成聚集索引表中当前数据行的物理位置发生变化,这一点也比较有意思,就不展开叙述了。
这一点跟绕口令一样,这里要求对SQL Server中的聚集索引和非聚集索引,以及存储结构有一个基础的认识才容易理解。
最后高能预警
高能预警,别说我瞎比比误导人,上述解析伪列的函数sys.fn_PhysLocFormatter是一个未公开的函数,
未公开的函数就有可能潜在一些问题,事实上这个函数有一个非常严重的bug。
该bug就是在解析物理存储位置的时候有一定的逻辑错误,这个问题早有细心的人分析过了
参考:http://blog.itpub.net/81227/viewspace-751898/
目前测试来看,在SQL Server 2014中仍然存在bug,N前年啃书的时候就了解到有这么一个函数,
但是一直不想提及sys.fn_PhysLocFormatter这个函数的原因,因此对于未公开的函数,请不要做验证性测试,
再次声明:该函数有bug,请谨慎使用。
附上这个函数的源代码,并参考原文的结论
create function sys.fn_PhysLocFormatter (@physical_locator binary (8))
returns varchar (128)
as
begin
declare @page_id binary (4)
declare @file_id binary (2)
declare @slot_id binary (2)
-- Page ID is the first four bytes, then 2 bytes of page ID, then 2 bytes of slot
--
select @page_id = convert (binary (4), reverse (substring (@physical_locator, 1, 4)))
select @file_id = convert (binary (2), reverse (substring (@physical_locator, 5, 2)))
select @slot_id = convert (binary (2), reverse (substring (@physical_locator, 7, 2)))
return '(' + cast (cast (@file_id as int) as varchar) + ':'
+ cast (cast (@page_id as int) as varchar) + ':'
+ cast (cast (@slot_id as int) as varchar) + ')'
end
问题出在reverse函数上。
reverse函数的作用是字符反转,而不是字节反转,当遇到81-FE之间的字节时,被认为是双字节字符而组合在一起参与反转操作,造成了错误。
总结
本文简单阐述了SQL Server中的伪列,以及伪列的含义,通过伪列对非聚集索引以及数据行的存储结构有一个简单的了解。
浅析SQL Server数据库中的伪列以及伪列的含义的更多相关文章
- 转:SQL SERVER数据库中实现快速的数据提取和数据分页
探讨如何在有着1000万条数据的MS SQL SERVER数据库中实现快速的数据提取和数据分页.以下代码说明了我们实例中数据库的“红头文件”一表的部分数据结构: CREATE TABLE [dbo]. ...
- .NET客户端下载SQL Server数据库中文件流保存的大电子文件方法(不会报内存溢出异常)
.NET客户端下载SQL Server数据库中文件流保存的大电子文件方法(不会报内存溢出异常) 前段时间项目使用一次性读去SQL Server中保存的电子文件的文件流然后返回给客户端保存下载电子文件, ...
- sql server数据库中char,varchar,nvarchar字段的区别
Char,varchar,nvarchar字段是sql server数据库中的三种字段类型.好多人在选择存储的时候不知道如何抉择,我给大家讲下这个三个字段类型的区别. Char(n)是长度为n个字节的 ...
- 清空SQL Server数据库中所有表数据的方法(转)
清空SQL Server数据库中所有表数据的方法 其实删除数据库中数据的方法并不复杂,为什么我还要多此一举呢,一是我这里介绍的是删除数据库的所有数据,因为数据之间可能形成相互约束关系,删除操作可能陷入 ...
- SQL server数据库中的DateTime类型出现的问题
我们知道这个SQL server数据库中的DateTime类型是数据库应用开发中经经常使用到的一种数据类型.而C#语言中也有DateTime类型,尽管二者都是用来描写叙述时间的,可是它们的默认值是不同 ...
- C#同步SQL Server数据库中的数据--数据库同步工具[同步新数据]
C#同步SQL Server数据库中的数据 1. 先写个sql处理类: using System; using System.Collections.Generic; using System.Dat ...
- C#从SQL server数据库中读取l图片和存入图片
原文:C#从SQL server数据库中读取l图片和存入图片 本实例主要介绍如何将图片存入数据库.将图片存入数据库,首先要在数据库中建立一张表,将存储图片的字段类型设为Image类型,用FileStr ...
- 清空SQL Server数据库中所有表数据的方法
原文:清空SQL Server数据库中所有表数据的方法 其实删除数据库中数据的方法并不复杂,为什么我还要多此一举呢,一是我这里介绍的是删除数据库的所有数据,因为数据之间可能形成相互约束关系,删除操作可 ...
- SQL Server 数据库中的异常信息与编号
SQL Server 数据库中的系统表提供了强大的元数据信息,其中 dbo.sysmessages 表中存储了数据库执行命令过程中的所有消息. SELECT * FROM master.dbo.sys ...
随机推荐
- Babel指南——基本环境搭建
ECMAScript的现状 ECMAScript,本身是一个脚本语言的设计规范,基于此规范,有许多为人熟知的语言,如JavaScript.ActionScript等.而时至几年前,随着Node.js的 ...
- js原生API----查找dom
一.祖先接口Node,及他的扩展接口EventTarget Node是一个接口,许多DOM类型从这个接口继承,并允许类似地处理(或测试)这些各种类型. 以下接口都从Node继承其方法和属性: Docu ...
- Unity3d在Window上使用SAPI进行语音识别
前言 在之前<Unity利用Sapi进行windows语音开发>中,本计划不准备继续做语音识别.因为在unity3d中已经提供了语音识别的相关方法,详见unity3d的官方文档:https ...
- MongoDB Sharding
sharding集群中的组件: 1.mongos:router,可以通过keepalived实现高可用. 2.config server:元数据服务器,这里要借助zookeeper存放配置信息. 3. ...
- js数组的几个练习题
第一次在博客园写文章,之前一直自己做记录.现在前端工作两年了,对前端整体技术有较清晰的了解.项目用了vue,react之类的写,如今打算从基础开始,慢慢深入了解原生的JS.这几天清明节,玩的嗨皮,最后 ...
- TCP/IP笔记(四)IP协议
前言 IP相当于OSI参考模型的第3层--网络层:主要作用是"实现终端节点之间的通信"又称"点对点通信". IP作为整个TCP/IP中至关重要的协议,主要负责将 ...
- bootstrap(响应式)加减输入框
<div class="row"> <div class="col-lg-6"> <div class="inp ...
- Android kernel LOGO的更换方法
[从制作logo到LCD显示或者VGA显示logo] 1.制作logo的方法: 首先选择一个自己喜欢的图片,然后通过GIMP软件将该图片保存为.png格式, 变换方式这个就不说了(very easy) ...
- 初步了解关于js跨域问题
js跨域问题是指在js在不同的域中进行数据传输或者数据通信,比如通过ajax向不同的域请求数据(说到ajax,不可避免的就会遇到两个问题:一是ajax是如何传递数据的?二是ajax是如何实现跨域的?) ...
- DOM的发展,DOM0,DOM1,DOM2,DOM3
Documentc Object Model文档对象模型是针对XML但经过扩展用于HTML的应用程序接口(API Application programming Interface).DOM把整个界面 ...