scrapy框架 + selenium 爬取豆瓣电影top250......
废话不说,直接上代码.....
目录结构
items.py
import scrapy class DoubanCrawlerItem(scrapy.Item):
# 电影名称
movieName = scrapy.Field()
# 电影id
movieId = scrapy.Field()
# 海报地址
img = scrapy.Field()
# 电影信息网址
info_website = scrapy.Field()
# 评分
data_score = scrapy.Field()
# 片长
data_duration = scrapy.Field()
# 上映日期
data_release = scrapy.Field()
# 导演
data_director = scrapy.Field()
# 主演
data_actors = scrapy.Field()
# 制作国家/地区
data_region = scrapy.Field()
# 编剧
data_attrs = scrapy.Field()
# 评论人数
data_number = scrapy.Field()
# 简介
introduction = scrapy.Field()
# 类型
movie_type = scrapy.Field()
# 语言
movie_language = scrapy.Field()
# 又名
also_called = scrapy.Field()
# 排名
movie_ranking = scrapy.Field()
# 这里是重点
spiders
movie_spider.py
import scrapy
from scrapy.spiders import Rule, CrawlSpider
from ..items import DoubanCrawlerItem
from scrapy.linkextractors import LinkExtractor
from selenium import webdriver
from scrapy import log
# 请求添加cookies和headers
cookies = {}
headers = {''} class DoubanspiderSpider(CrawlSpider):
# spider名称
name = 'douban'
# 爬取规则,获取给定request中的电影信息界面url
rules = (
Rule(LinkExtractor(allow=r'^https://movie.douban.com/subject/\d+/$'), callback='parse_item', follow=True),
) # 初始化request
def start_requests(self):
for i in range(0, 250, 25):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i)
request = scrapy.Request(url, cookies=cookies, headers=headers)
yield request # 爬取数据并处理
def parse_item(self, response):
info_url = response.url
item = self.selenium_js(info_url)
item['website'] = info_url
url_list = info_url.split('/')
for i in url_list:
if i == '':
url_list.remove(i)
item['movieId'] = url_list[-1]
movie_introduction = response.xpath('//*[@id="link-report"]/span[1]/text()').extract()
introduction = ''
for i in movie_introduction:
introduction += i.strip().replace('\n', '').replace('\t', '')
item['introduction'] = introduction
item['movie_ranking'] = response.xpath('//*[@id="content"]/div[1]/span[1]/text()').extract()
img_list = response.xpath('//*[@id="mainpic"]/a/img/@src').extract()
item['movieName'] = response.xpath('//*[@id="content"]/h1/span[1]/text()').extract()
for img in img_list:
item['img'] = img.replace('.webp', '.jpg')
log.msg(item)
yield item # 使用 selenium 爬取一些动态数据
def selenium_js(self, info_url):
item = DoubanCrawlerItem()
driver = webdriver.Chrome()
driver.get(info_url)
driver.maximize_window()
driver.implicitly_wait(10)
data = driver.find_element_by_xpath('//div[@class="subject clearfix"]/div[2]').text
data_list = data.split('\n')
for d in data_list:
if d != '':
j = d.split(':', 1)
if '导演' in j[0]:
item['data_director'] = j[1]
elif '编剧' in j:
item['data_attrs'] = j[1]
elif '主演' in j:
item['data_actors'] = j[1]
elif '类型' in j:
item['movie_type'] = j[1]
elif '制片国家/地区' in j:
item['data_region'] = j[1]
elif '语言' in j:
item['movie_language'] = j[1]
elif '上映日期' in j:
item['data_release'] = j[1]
elif '片长' in j:
item['data_duration'] = j[1]
elif '又名' in j:
item['also_called'] = j[1]
else:
pass item['data_number'] = driver.find_element_by_xpath('//*[@id="interest_sectl"]/div[1]/div[2]/div/div[2]/a/span').text
driver.close()
return item
pipelines.py
import pymysql
import time
from scrapy.exceptions import DropItem
from scrapy import log class DoubancrawlerPipeline: def process_item(self, item, spider):
# 判断如果没有本科人数字段,则丢弃该item
if not item.get('img'):
raise DropItem('缺少字段:{}'.format('img'))
# 判断如果没有研究生人数字段,则丢弃该item
if not item.get('movieName'):
raise DropItem('缺少字段:{}'.format('movieName'))
if not item.get('also_called'):
item['also_called'] = ''
return item class MysqlPipeline(object): def __init__(self):
""""初始化mysql链接和游标对象"""
self.conn = None
self.cur = None
# self.movies = False
# self.commentary = False def open_spider(self, spider):
""""初始化mysql链接"""
self.conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='xxxxx',
db='douban',
charset='utf8mb4',
)
# 初始化游标对象
self.cur = self.conn.cursor()
# 初始化数据库
# self.delete_data() def delete_data(self):
"""在保存爬取数据前,清空库 递归清空"""
sql = 'select `movieName` from `top250`'
self.cur.execute(sql)
if self.cur.fetchone():
sql = 'delete from `top250`'
self.cur.execute(sql)
self.conn.commit()
time.sleep(1)
self.delete_data()
else:
log.msg('数据库初始化完成!') def check_data(self, table):
sql = 'select `movieId` from {}'.format(table)
self.cur.execute(sql)
self.conn.commit()
s = self.cur.fetchall()
id_list = []
# 判断数据是否已经存在
for i in range(len(s)):
for j in s[i]:
id_list.append(j)
return set(id_list) def process_item(self, item, spider):
"""处理,保存爬取数据"""
if spider.name == 'douban':
id_list = self.check_data('top250')
if int(item['movieId']) not in id_list:
sql = 'insert into `top250`(`movieName`, `movieId`, `data_number`,`data_release`,`img`, ' \
'`introduction`, `data_duration`, `data_region`, `data_director`, `data_actors`, `data_attrs`, ' \
'`website`, `movie_ranking`, `movie_type`, `movie_language`, `also_called`) values ' \
'(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)'
self.cur.execute(sql, (item['movieName'], item['movieId'], item['data_number'], item['data_release'],
item['img'], item['introduction'], item['data_duration'],
item['data_region'], item['data_director'], item['data_actors'],
item['data_attrs'], item['website'], item['movie_ranking'], item['movie_type'],
item['movie_language'], item['also_called']))
self.conn.commit()
log.msg('{},保存成功!'.format(item['movieName']))
return item def close_spider(self, spider):
"""关闭mysql链接和游标"""
self.cur.close()
self.conn.close() middlewares proxy.py
import random
from urllib.request import _parse_proxy
import requests
from scrapy.exceptions import NotConfigured
from scrapy import log def reform_url(url):
# 重组url,返回不带用户名密码的格式
proxy_type, *_, hostport = _parse_proxy(url)
return '{}://{}'.format(proxy_type, hostport) class RandomProxyMiddleware:
# 代理的最多失败次数,超过此值的代理,从代理池中删除
max_failed = 3 def __init__(self, settings):
# 从设置中获取代理池
# self.proxies = settings.getlist('PROXIES')
self.proxies = self.choice_proxies()
if self.proxies:
# 初始化统计信息,一开始失败次数都是0
self.stats = {}.fromkeys(map(reform_url, self.proxies), 0) def choice_proxies(self):
self.proxies = []
# 1个ip
url = '可以返回ip的url'
# 30个
# url = 'xxxx'
r = requests.get(url)
# eval() 计算字符串中的有效表达式
ip_dict = eval(r.text)
if ip_dict['code'] == '0':
for i in ip_dict['msg']:
# 拼接成有效的代理ip
ip = 'http://' + i['ip'] + ':' + i['port']
self.proxies.append(ip)
log.msg(self.proxies)
return self.proxies
else:
log.msg('代理ip接口返回状态码异常...{}'.format(ip_dict['code']))
return '-1' # 判断是否启用了代理
@classmethod
def from_crawler(cls, crawler):
if not crawler.settings.getbool('HTTPPROXY_ENABLED'):
raise NotConfigured
return cls(crawler.settings) def process_request(self, request, spider):
# 如果request.meta中没有设置proxy,则从代理池中随机设置一个,作为本次请求的代理
if 'proxy' not in request.meta:
request.meta['proxy'] = random.choice(self.proxies) def process_response(self, request, response, spider):
# 获取当前使用的proxy
cur_proxy = request.meta['proxy']
# 判断http code是否大于400,响应是否出错
if response.status >= 400:
# 将该代理的失败次数加1
self.stats[cur_proxy] += 1
# 判断该代理的总失败次数是否已经超过最大失败次数
if self.stats[cur_proxy] >= self.max_failed:
log.msg('{} 获得一个 {} 返回结果'.format(cur_proxy, response.status))
# 从代理池中删除该代理
# if cur_proxy in self.proxies:
# self.proxies.remove(cur_proxy)
for proxy in self.proxies:
if reform_url(proxy) == cur_proxy:
self.proxies.remove(proxy)
break
log.msg('{} 超过最大失败次数,从代理列表删除'.format(cur_proxy))
# 将本次请求重新设置一个代理,并返回
if not self.proxies:
self.proxies = self.choice_proxies()
log.msg('超过最大失败次数,代理池为空...再次请求api')
# return
request.meta['proxy'] = random.choice(self.proxies)
return request
return response def process_exception(self, request, exception, spider):
cur_proxy = request.meta['proxy']
# 如果出现网络超时或者链接被拒绝,则删除该代理
if cur_proxy in self.proxies:
self.proxies.remove(cur_proxy)
log.msg('{} 代理ip出现错误,从代理列表删除'.format(cur_proxy))
# 将本次请求重新设置一个d代理并返回
if not self.proxies:
self.choice_proxies()
log.msg('代理ip出现错误,代理池为空...再次请求api')
# return
request.meta['proxy'] = random.choice(self.proxies)
return request useragent.py
import faker class RandomUserAgentMiddleware(object):
"""该中间件负责给每个请求随机分配一个user agent""" def __init__(self, settings):
self.faker = faker.Faker() @classmethod
def from_crawler(cls, crawler):
# 创建一个中间件实例,并返回
return cls(crawler.settings) def process_request(self, request, spider):
# 设置request头信息内的user-Agent字段
request.headers['User-Agent'] = self.faker.user_agent() def process_response(self, request, response, spider):
# print(request.headers['User-Agent'])
return response
settings.py import time
# 是否使用代理
HTTPPROXY_ENABLED = True
# 启用log
LOG_ENABLED = True
# log文件编码
LOG_ENCODING = 'utf-8'
# 打印日志文件位置
today = time.strftime('%Y-%m-%d')
LOG_FILE = "./log/{}.log".format(today)
# 提高日志级别
LOG_LEVEL = 'INFO'
# 禁⽤用重定向
REDIRECT_ENABLED = False
# 请求之间的间隔
DOWNLOAD_DELAY = 2
DOWNLOADER_MIDDLEWARES = {
'doubanCrawler.middlewares.useragent.RandomUserAgentMiddleware': 543,
'doubanCrawler.middlewares.proxy.RandomProxyMiddleware': 749,
}
ITEM_PIPELINES = {
'doubanCrawler.pipelines.DoubancrawlerPipeline': 300,
# # 'doubanCrawler.pipelines.RedisPipeline': 301,
'doubanCrawler.pipelines.MysqlPipeline': 302,
}
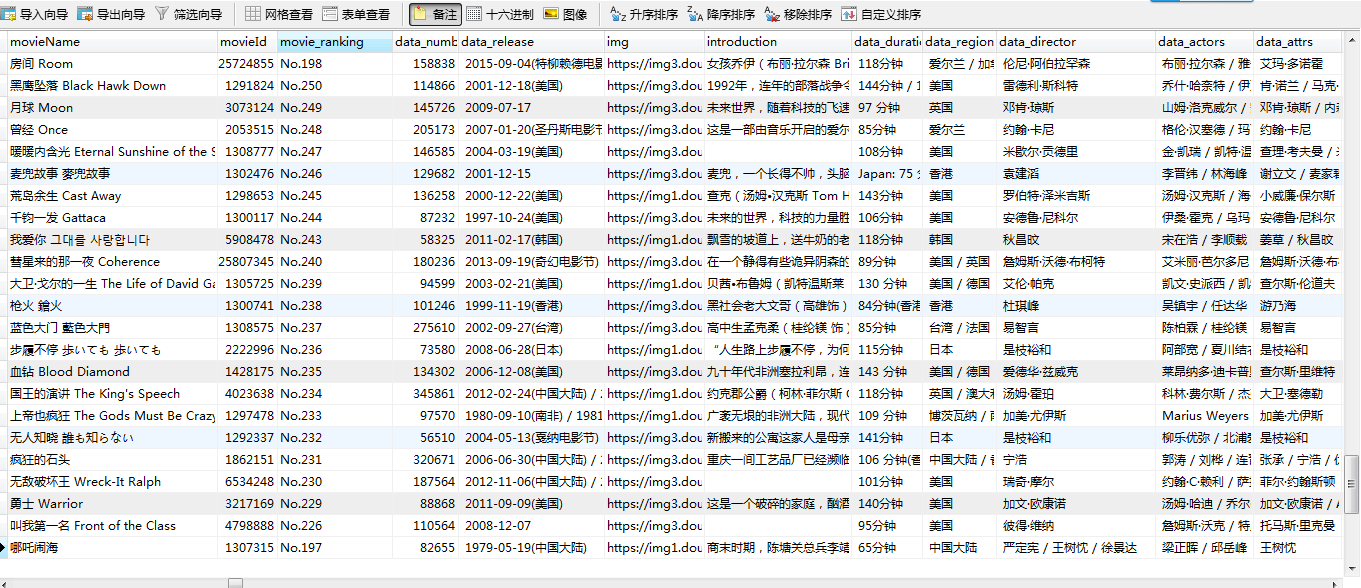
run:scrapy crawl douban
result:
so, 大家多多指教...

scrapy框架 + selenium 爬取豆瓣电影top250......的更多相关文章
- 利用selenium爬取豆瓣电影Top250
这几天在学习selenium,顺便用selenium + python写了一个比较简陋的爬虫,现附上源码,有时间再补充补充: from selenium import webdriver from s ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- urllib+BeautifulSoup无登录模式爬取豆瓣电影Top250
对于简单的爬虫任务,尤其对于初学者,urllib+BeautifulSoup足以满足大部分的任务. 1.urllib是Python3自带的库,不需要安装,但是BeautifulSoup却是需要安装的. ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
随机推荐
- 多点数据同步服务器sql汇总
1. a表中是否存在c的列 IF COL_LENGTH('FeeType', 'ftName') IS NOT NULL select N'存在'as result ELSE select N'不存在 ...
- 【SQL】where 后不可以接聚合函数,都哪些是聚合函数?
where 后不可以接聚合函数,比如函数:SUM(count),AVG(count),MIN(count),MAX(count)
- 生成器-代码举例:()和yield
怎么自定义一个生成器:两个方法: 1.小括号包裹表达式 2.函数中用yield返回 方法一:①小括号包裹表达式 G=(x*2 for x in range(5)) print(G)输出:<gen ...
- Redis入门到高可用(八)——list
一.结构 key - value 结构,value是一个有序队列. 可进行左边的添加及弹出,右边的添加及弹出. 可获取列表的长度,删除列表中指定元素,获取列表的子列表,按照索引获取列表的指定元素. 特 ...
- 云服务器--linux系统操作命令以及安装ngnix记录,以及手动部署本地文件
1.控制台登陆服务器,需要首先知道服务器ip和密码,,命令是 ssh root@1.1.1.1(服务器IP),然后输入密码登入服务器 2.查看linux 版本的系统命令是 cat /etc/redha ...
- sap 调试工具,修改变量值
1: 点击修改,输入变量值,按enter键.
- easyui——validType属性值
- Swagger Editor本地安装
一:安装Node JS 二:下载源码swagger-editor源码,解压 下载地址:https://github.com/swagger-api/swagger-editor 三:在解压目录下运行进 ...
- Wix制作安装包
Wix制作安装包,找起资料来很费劲,记录一下: Product.wxs,该文件只能制作出msi形式的安装包,不能做到自动检测framework. <?xml version="1.0& ...
- zabbix 监控 redis
redis 可以直接使用zabbix官方的模板 模板地址: https://github.com/blacked/zbx_redis_template redis 主机通过脚本把数据推送到zabbi ...