sharc dsp 学习记录1---2014-07-30
从今天开始记录学习sharc dsp过程中的点点滴滴吧。
DPI:Digital Peripheral Interface
DAI:Digital Audio Interface
SHARC SIMD Core
SIMD 单指令多数据
ADSP-2148x包含两个用作单指令、多数据(SIMD)引擎的计算处理器元件,分别称为PEX和PEY,各元件均由ALU、乘法器、移位器和寄存器文件组成。
PEX始终有效,PEY可通过将MODE1寄存器的PEYEN模式位设为1来使能。SIMD模式允许处理器在两个处理元件中执行同一指令,但各处理元件处理不
同的数据。这种架构对于执行计算密集型DSP算法非常有效
SIMD Enabled:
When any computation or data access is executed, it will be performed automatically in both processing elements
F0 = F1 + F2; explicitly defined in source code Will execute in PEx
S0 = S1 + S2; implicit operation not defined in source code Will be automatically executed in PEy in the same instruction cycle
SIMD Disabled (SISD Mode):
Only the explicit instruction will be executed in PEx
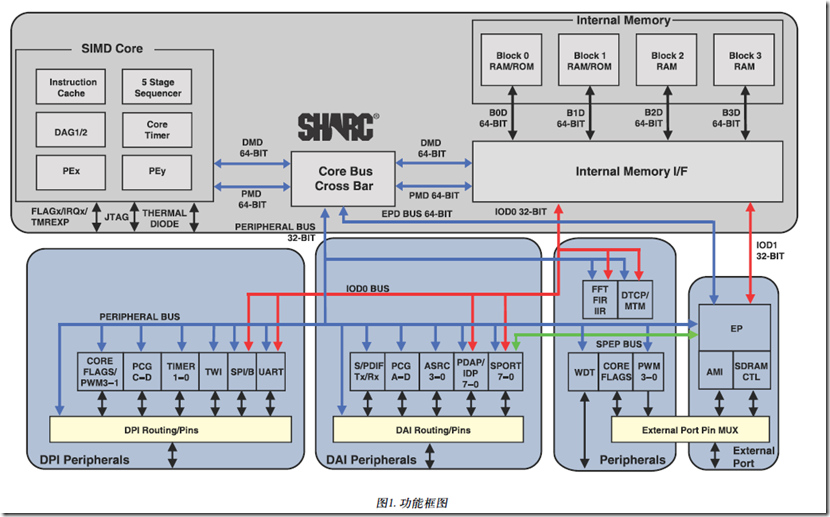
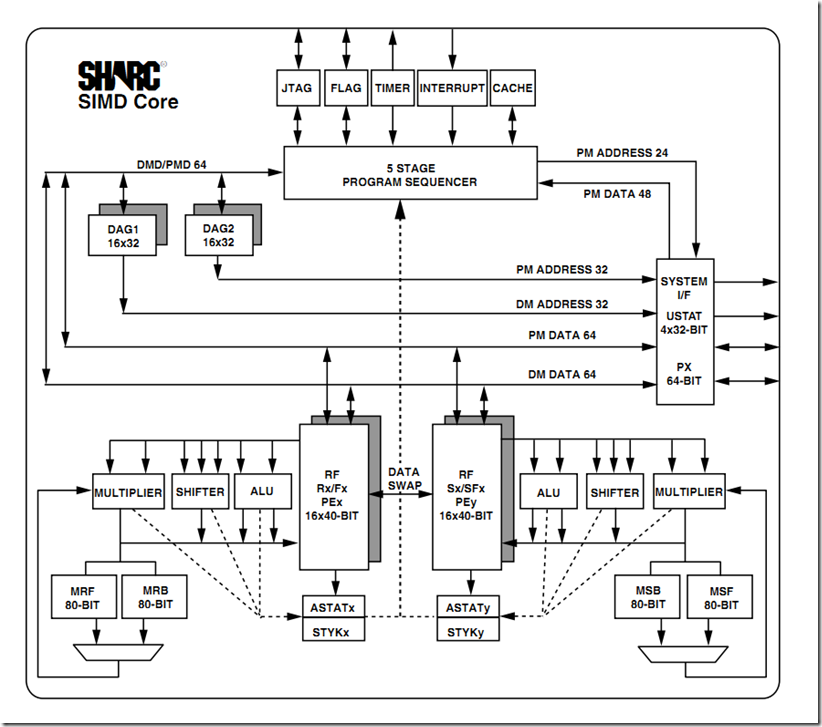
PM地址总线的宽度 = 24bits 。可最多访问16Mbit的程序/数据。
PM数据总线的宽度 = 48bits。 用以存取48 位字长的指令,当用来存放数据时,32 位单精度浮点数或32位定点数将位于48 位的高32 位中
48位指令字支持各种并行操作,可实现简练编程。例如,处理器可以有条件地在两个处理元件中执行乘法、加法和减法,同时进行分支并从存储
器获取最多4个32位数据值,所有这些只需一个指令。
汇编程序分析(FIR)
#include "def21364.h" /* Symbol Definition File */
#define TAPS 64 /* length of filter */
#define N 128 /* number of samples */.extern ss_fir;
/* DM data */
.section/dm seg_dmda; /* Segments are declared in the .ldf file*/
.ALIGN 2; /* Set alignment to long-word boundary for next variable */
.var dline[TAPS+1]; /* delay line compensate for circ buffer, see comments in SS_FIR.asm */
.ALIGN 2;
.var input[N] = "input.dat"; /* array of samples *//* PM data */
.section/dm seg_pmda;
.ALIGN 2;
.var coeffs[TAPS] = "ssfcoeffs.dat"; /* Filter coefficients */
.ALIGN 2;
.var output[N]; /* Output array *//* PM interrupt vector code */
.section/pm seg_rth;
Reserved_1: rti; nop; nop; nop;
Chip_Reset: idle; jump start; nop; nop;/* program memory code */
.segment/pm seg_pmco;start:
/*--------------------- Setup modify registers for arrays --------------------*/
m1 = 1;
m2 = -1;
m3 = 2;m9 = 2;
m10= 1;
/*----------------------------------------------------------------------------*/
/*--------------------- Initialization delay line ----------------------------*/
b0 = dline;
l0 = @dline-1;f8=0.0;
lcntr = TAPS, do clear_fir until lce;
clear_fir: dm(i0,m1) = f8;i0 = dline;
/*----------------------------------------------------------------------------*/
/*-------------- Setup DAGs for input/output/coeffs and call ss_fir ----------*/
r3 = TAPS;
r3 = lshift r3 by -1; /* r3 = taps/2 due to SIMD mode */
r0 = 3; /* 3 macs outside of fir mac loop */
r3 = r3 - r0; /* r3 = taps/2 - 3 for fir mac loop counter */
b1 = input;
l1 = 0;b9 = output;
l9 = 0;b8 = coeffs;
l8 = @coeffs;
lcntr = N, do fir_loop until lce;
call ss_fir (db); /* Call fir */
f0 = dm(i1,m1); /* Read one sample */
nop; /* Call can't be in last three locations of a loop */
fir_loop: pm(i9,m10)=f8; /* Write result to output */
/*----------------------------------------------------------------------------*/
/* Terminate and wait */
wait1: idle;
jump wait1;
#include "def21364.h" /* Symbol Definition File */
.global ss_fir;
/* program memory code */
.section/pm seg_pmco;ss_fir:
bit set MODE1 CBUFEN; /* Circular Buffer Enable, one cycle effect latency */
nop; /* Circular Buffering not in effect until next cycle */
s0 = dm(i0, m1); /* move pointer to delay[1] */
bit set MODE1 PEYEN; /* SIMD Mode Enable, one cycle effect latency */
s0 = dm(i0, m2); /* load s0 with the value of delay[1] for SIMD store, move pointer to delay[0] */
dm(i0,m3)=f0, f4 = pm(i8,m9); /* transfer sample to delayline, done in SIMD to load end of buffer + 1 */
/* to compensate for circular buffer issue described above, read 2 coeffs */f8=f0*f4, f0=dm(i0,m3), f4=pm(i8,m9); /* samples * coeffs, read 2 samples, read 2 coeffs */
f12=f0*f4, f0=dm(i0,m3), f4=pm(i8,m9); /* samples * coeffs, read 2 samples, read 2 coeffs */
lcntr=r3, do macs until lce; /* FIR loop */
macs:f12=f0*f4, f8=f8+f12, f0=dm(i0,m3), f4=pm(i8,m9); /* samples * coeffs, accum, read 2 samples, read 2 coeffs */
f12=f0*f4, f8=f8+f12, s0=dm(i0,m2); /* samples * coeffs, accum, dummy read to move pointer to oldest sample */
f8=f8+f12; /* final SIMD accum */
r12=s8; /* move PEy total into PEx register file */
rts (db);
bit clr MODE1 CBUFEN | PEYEN; /* Circular Buffer Disable, SIMD Mode Disable */
f8=f8+f12; /* last accum */
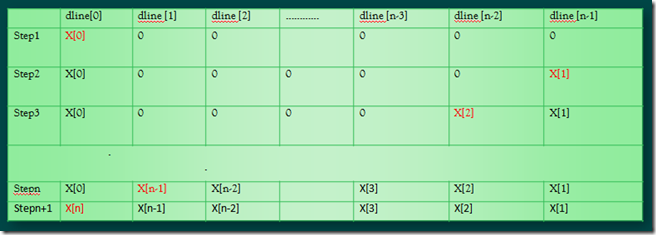
dline的读写
红色表示进入macs 循环前 i0指针指向的位置。
该程序使用了循环寻址的方式
Bx、Lx、Ix 三个寄存器的序号x 必须一致,而Mx 寄存器可以在同一个DAG 组中任意选取
R3 = lshift R3 by -1; //右移1bit
sharc dsp 学习记录1---2014-07-30的更多相关文章
- C语言学习记录_2019.02.07
C99开始,可以用变量来定义数组的大小:例如,利用键盘输入的变量来定义数组大小: 赋值号左边的值叫做左值: 关于数组:编译器和运行环境不会检查数组下标是否越界,无论读还是写. 越界数组可能造成的问题提 ...
- [转]Oracle学习记录 九 Prc C学习
经过前面的了解,现在想用C语言来编程了,搜索了很多东西,后来决定先用Pro C来进行学习 在安装完Oracle数据库后就可以进行编程了,里面有一个命令proc就是对程序进行预编译的. 在这记一下,这是 ...
- Python学习记录day6
title: Python学习记录day6 tags: python author: Chinge Yang date: 2016-12-03 --- Python学习记录day6 @(学习)[pyt ...
- Python学习记录day5
title: Python学习记录day5 tags: python author: Chinge Yang date: 2016-11-26 --- 1.多层装饰器 多层装饰器的原理是,装饰器装饰函 ...
- Matlab 进阶学习记录
最近在看 Faster RCNN的Matlab code,发现很多matlab技巧,在此记录: 1. conf_proposal = proposal_config('image_means', ...
- Git学习记录
一.简要说明 Git是分布式版本控制系统,而非集中式版本控制系统.其优势如下: 自由和开放源码 速度快,体积小 隐式备份(每台用户机上都有一个备份) 安全 不需要强大的硬件 更简单的分支 二.基本概念 ...
- Uboot 2014.07 makefile分析 - 其他Cortex系列
uboot的官网可以通过谷歌搜索得到,显示结果第一个链接就是. 官网:: http://www.denx.de/wiki/U-Boot ftp下载: ftp://ftp.denx.de/pub/u-b ...
- 【转】BLE 学习记录
原文网址:http://m.blog.csdn.net/blog/chiooo/43985401 BLE 学习记录 ANROID BLE 开发,基于 bluetoothlegatt 分析 mBluet ...
- 强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning)
强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning) 学习笔记: Reinforcement Learning: An Introductio ...
随机推荐
- luogu P2596 [ZJOI2006]书架
传送门 感觉要死在\(Splay\)里了 orz 这题用\(Splay\)维护这个序列,其中的第\(k\)大点代表这个序列的第\(k\)个数 第一个操作,先把那个数所在的点旋到根,然后把整个根的左子树 ...
- weblogic中部署SSH项目遇到的坑
总结将SSH项目部署到weblogic遇到的坑.项目中是SSH,另外还用到了webservice.quartz等框架.在tomcat部署是可以的,现在总结部署到weblogic遇到的坑. 在这里说一下 ...
- python学习笔记:"爬虫+有道词典"实现一个简单的英译汉程序
1.有道的翻译 网页:www.youdao.com Fig1 Fig2 Fig3 Fig4 再次点击"自动翻译"->选中'Network'->选中'第一项',如下: F ...
- css 背景图片自适应元素大小
一.一种比较土的方法,<img>置于底层. 方法如下: CSS代码: HTML: <img src="背景图片路径" /> <span>字在背景 ...
- HTTP协议中PUT和POST使用上的区别
有的观点认为,应该用POST来创建一个资源,用PUT来更新一个资源:有的观点认为,应该用PUT来创建一个资源,用POST来更新一个资源:还有的观点认为可以用PUT和POST中任何一个来做创建或者更新一 ...
- Django 查询集简述
通过模型中的管理器构造一个查询集(QuerySet),来从数据库中获取对象.查询集表示从数据库中取出来的对象的集合.它可以含有零个.一个或者多个过滤器.过滤器基于所给的参数限制查询的结果. 从SQL ...
- ioremap 与 mmap【转】
转自:http://blog.csdn.net/junllee/article/details/7415732 内存映射 对于提供了MMU(存储管理器,辅助操作系统进行内存管理,提供虚实地址转换等硬件 ...
- 手把手教你写makefile【原创】
Makefile 编写 Make -f makefile1 指定 如下是 本人的一点makefile学习笔记,再分享一个不错的写makefile总结的网址: http://www.cnblogs ...
- HTML学习笔记01-HTML简介
主要是为了做接口测试,试着自己写爬虫,所以学习一下HTML一些基础的东西,方便用来解析网页.学习内容主要来自菜鸟教程的HTML教程,W3school的HTML 超文本标记语言(英语:HyperText ...
- 初识numpy
from numpy import * 导入numpy包 random可以生成随机数组 通过mat函数,将数组转换成矩阵,可以对矩阵进行求逆计算等.其中.I操作实现了矩阵求逆计算操作. 执行矩阵乘 ...