Hadoop 目录分析及存储机制
NameNode元数据目录分析
在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘:
|
$HADOOP_HOME/bin/hdfs namenode -format |
格式化完成之后,将会在$dfs.namenode.name.dir/current目录下如下的文件结构
current/ |-- VERSION |-- edits_* |-- fsimage_0000000000008547077 |-- fsimage_0000000000008547077.md5 `-- seen_txid |
其中的dfs.name.dir是在hdfs-site.xml文件中配置的,默认值如下:
<property> <name>dfs.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value>
</property> hadoop.tmp.dir是在core-site.xml中配置的,默认值如下 <property> <name>hadoop.tmp.dir</name> <value>/tmp/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description> </property> |
dfs.namenode.name.dir属性可以配置多个目录,
如/data1/dfs/name,/data2/dfs/name,/data3/dfs/name,....。各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到Hadoop的元数据,特别是当其中一个目录是NFS(网络文件系统Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
下面对$dfs.namenode.name.dir/current/目录下的文件进行解释。
1、VERSION文件是Java属性文件,内容大致如下:
#Fri Nov 15 19:47:46 CST 2013 namespaceID=934548976 clusterID=CID-cdff7d73-93cd-4783-9399-0a22e6dce196 cTime=0 storageType=NAME_NODE blockpoolID=BP-893790215-192.168.24.72-1383809616115 layoutVersion=-47 |
其中
(1)namespaceID是文件系统的唯一标识符,在文件系统首次格式化之后生成的;
(2)storageType说明这个文件存储的是什么进程的数据结构信息(如果是DataNode,storageType=DATA_NODE);
(3)cTime表示NameNode存储时间的创建时间,由于我的NameNode没有更新过,所以这里的记录值为0,以后对NameNode升级之后,cTime将会记录更新时间戳;
(4)layoutVersion表示HDFS永久性数据结构的版本信息, 只要数据结构变更,版本号也要递减,此时的HDFS也需要升级,否则磁盘仍旧是使用旧版本的数据结构,这会导致新版本的NameNode无法使用;
(5)clusterID是系统生成或手动指定的集群ID,在-clusterid选项中可以使用它;如下说明
a、使用如下命令格式化一个Namenode:
$HADOOP_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
选择一个唯一的cluster_id,并且这个cluster_id不能与环境中其他集群有冲突。如果没有提供cluster_id,则会自动生成一个唯一的ClusterID。
b、使用如下命令格式化其他Namenode:
$HADOOP_HOME/bin/hdfs namenode -format -clusterId <cluster_id>
c、升级集群至最新版本。在升级过程中需要提供一个ClusterID,例如:
$HADOOP_PREFIX_HOME/bin/hdfs start namenode --config $HADOOP_CONF_DIR -upgrade -clusterId <cluster_ID>
如果没有提供ClusterID,则会自动生成一个ClusterID。
(6)blockpoolID:是针对每一个Namespace所对应的blockpool的ID,上面的这个BP-893790215-192.168.24.72-1383809616115就是在我的ns1的namespace下的存储块池的ID,这个ID包括了其对应的NameNode节点的ip地址。
2、$dfs.namenode.name.dir/current/seen_txid非常重要,是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits_*文件的尾数,namenode重启的时候,会按照seen_txid的数字,循序从头跑edits_0000001~到seen_txid的数字。所以当你的hdfs发生异常重启的时候,一定要比对seen_txid内的数字是不是你edits最后的尾数,不然会发生建置namenode时metaData的资料有缺少,导致误删Datanode上多余Block的资讯。
3、$dfs.namenode.name.dir/current目录下在format的同时也会生成fsimage和edits文件,及其对应的md5校验文件。
补充:seen_txid
文件中记录的是edits滚动的序号,每次重启namenode时,namenode就知道要将哪些edits进行加载edits
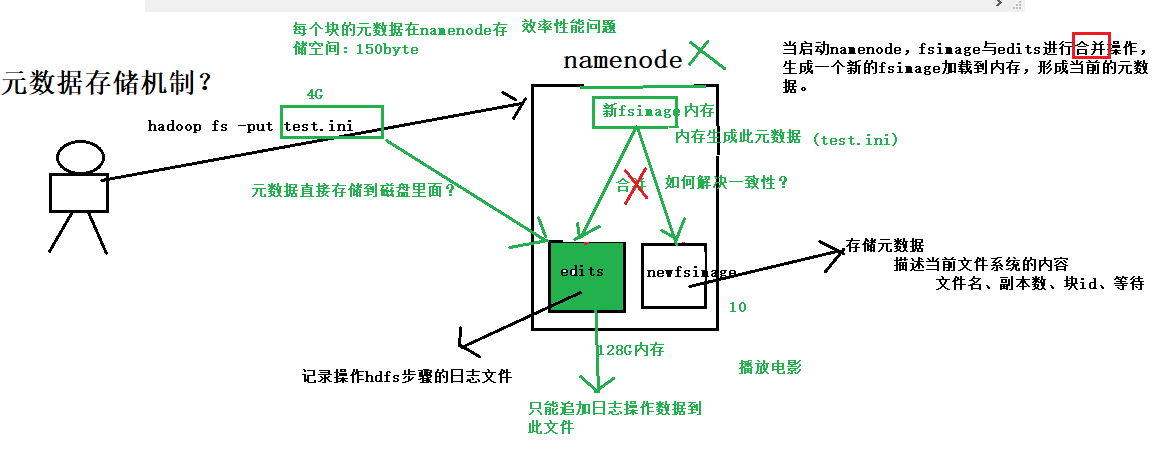
元数据的存储机制
首先,我们假设如果存储在Namenode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。
因此,元数据需要存放在内存中。但如果只存在内存中,一旦断点,元数据丢失,整个集群就无法工作了!!
!因此必须在磁盘中有备份,在磁盘中的备份就是fsImage,存放在Namenode节点对应的磁盘中。
当在内存中的元数据更新时,如果同时更新fsImage镜像文件(文件的随机读写),会导致效率过低,
但如果不更新,就会发生一致性问题,一旦Namenode节点断电,就会产生数据丢失。
因此,引入操作日志文件edits.log(只进行追加操作,效率很高)。
每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到edits.log中。
这样,一旦Namenode节点断电,可以通过镜像文件fsImage和edits.log的合并,合成元数据。
但是,如果长时间添加数据到edit.log中,会导致该文件数据过大,效率降低且一旦断电,恢复元数据需要的时间过长。
因此,需要定期进行fsImage和edits.log的合并,如果这个操作由Namenode节点完成,又会效率过低。
因此,引入一个新的secondaryNamenode,专门用于fsImage和edits.log的合并。

Hadoop 目录分析及存储机制的更多相关文章
- Java提高篇——通过分析 JDK 源代码研究 Hash 存储机制
HashMap 和 HashSet 是 Java Collection Framework 的两个重要成员,其中 HashMap 是 Map 接口的常用实现类,HashSet 是 Set 接口的常用实 ...
- 通过分析 JDK 源代码研究 Hash 存储机制--转载
通过 HashMap.HashSet 的源代码分析其 Hash 存储机制 集合和引用 就像引用类型的数组一样,当我们把 Java 对象放入数组之时,并不是真正的把 Java 对象放入数组中,只是把对象 ...
- Hadoop HDFS元数据目录分析
元数据目录分析 在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘: $HADOOP_HOME/bin/hdfs namenode -format 格式化完成之后 ...
- 【RabbitMQ学习记录】- 消息队列存储机制源码分析
本文来自 网易云社区 . RabbitMQ在金融系统,OpenStack内部组件通信和通信领域应用广泛,它部署简单,管理界面内容丰富使用十分方便.笔者最近在研究RabbitMQ部署运维和代码架构,本篇 ...
- 通过分析 JDK 源代码研究 Hash 存储机制
通过 HashMap.HashSet 的源代码分析其 Hash 存储机制 实际上,HashSet 和 HashMap 之间有很多相似之处,对于 HashSet 而言,系统采用 Hash 算法决定集合元 ...
- kafka知识体系-kafka设计和原理分析-kafka文件存储机制
kafka文件存储机制 topic中partition存储分布 假设实验环境中Kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka broker中 ...
- java-通过 HashMap、HashSet 的源码分析其 Hash 存储机制
通过 HashMap.HashSet 的源码分析其 Hash 存储机制 集合和引用 就像引用类型的数组一样,当我们把 Java 对象放入数组之时,并非真正的把 Java 对象放入数组中.仅仅是把对象的 ...
- 在HDInsight中从Hadoop的兼容BLOB存储查询大数据的分析
在HDInsight中从Hadoop的兼容BLOB存储查询大数据的分析 低成本的Blob存储是一个强大的.通用的Hadoop兼容Azure存储解决方式无缝集成HDInsight.通过Hadoop分布式 ...
- HTML5分析实战Web存储机制(Web Storage)
Web Storage它是Key-Value在持久性数据存储的形式.Web Storage为了克服cookie把所引起的一些限制.当数据需要严格格控制client准时,没有必要不断地发回数据serve ...
随机推荐
- 【Python】socket编程-3
. SocketServer最简单的使用方法: () 创建一个Handler类,继承自BaseRequestHandler,重写其handle(),在该方法中完成对请求的处理. () 实例化一个Ser ...
- redis实现api限流
redis官方给出了参考文档:INCR 这里参考第一种方法,使用token bucket实现:每个用户每秒有一个Counter: func RateLimiter(uid string, rlType ...
- 解决Python2.7的UnicodeEncodeError: ‘ascii’ codec can’t encode异常错误
更改 sys.defaultencoding 为文件的编码方式 #! /usr/bin/env python # -*- coding: utf-8 -*- import sys reload ...
- Linux more命令详解
more功能类似 cat ,cat命令是整个文件的内容从上到下显示在屏幕上. more会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回( ...
- Django中HtttpRequest请求
1.什么是HttpRequest HttpRequest,就是对请求对象的封装,里面封装的是请求过程中的所有信息.在Django中HttpRequest被封装成request对象并封装到视图处理函数中 ...
- 关于 transparent rgba display:none; opacity visiblity 关于em
关于 transparent rgba display:none; opacity visiblity display 之后不会占位. 其余都会占位 opacity 还会继承,子元素也会 ...
- 组合数的求法 (n<=1e8 可以过来看)
C(n,m) =n!/(m!* (n-m)! ); o(n) 求 1-m的逆元 o(n) 求 n的阶乘 代码实现 https://www.cnblogs.com/linyujun/p/5194189 ...
- oracle 数据库中(创建、解锁、授权、删除)用户
上文我们已经建立了名为orcl66的数据库. 想要在数据库中创建.修改用户需要我们以管理员权限登录到数据库中. 首先我们通过sqlplus命令登录连接数据库. 输入sqlplus命令--用户名: sy ...
- Java中的Graphics2D类基本使用教程
Java语言在Graphics类提供绘制各种基本的几何图形的基础上,扩展Graphics类提供一个Graphics2D类,它拥用更强大的二维图形处理能力,提供.坐标转换.颜色管理以及文字布局等更精确的 ...
- 【java多线程】线程状态分析
一.java线程的状态 NEW: 新建状态,线程对象已经创建,但尚未启动 RUNNABLE:就绪状态,可运行状态,调用了线程的start方法,已经在java虚拟机中执行,等待获取操作系统资源如CPU, ...