ForkJoin
概述
从JDK1.7开始,Java提供Fork/Join框架用于并行执行任务,它的思想就是讲一个大任务分割成若干小任务,最终汇总每个小任务的结果得到这个大任务的结果。
这种思想和MapReduce很像(input --> split --> map --> reduce --> output)
主要有两步:
- 第一、任务切分;
- 第二、结果合并
它的模型大致是这样的:线程池中的每个线程都有自己的工作队列(PS:这一点和ThreadPoolExecutor不同,ThreadPoolExecutor是所有线程公用一个工作队列,所有线程都从这个工作队列中取任务),当自己队列中的任务都完成以后,会从其它线程的工作队列中偷一个任务执行,这样可以充分利用资源。
工作窃取(work-stealing)
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:
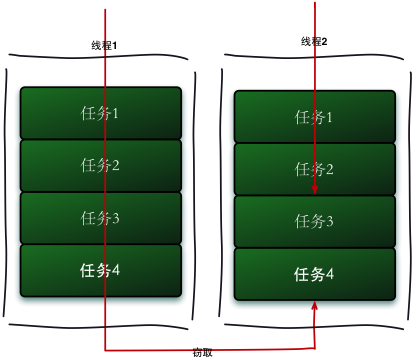
那么为什么需要使用工作窃取算法呢?
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
ForkJoinPool与其它的ExecutorService区别主要在于它使用“工作窃取”。
ForkJoinTask
ForkJoinTask代表运行在ForkJoinPool中的任务。
主要方法:
- fork() 在当前线程运行的线程池中安排一个异步执行。简单的理解就是再创建一个子任务。
- join() 当任务完成的时候返回计算结果。
- invoke() 开始执行任务,如果必要,等待计算完成。
子类:
- RecursiveAction 一个递归无结果的ForkJoinTask(没有返回值)
- RecursiveTask 一个递归有结果的ForkJoinTask(有返回值)
ForkJoinWorkerThread
ForkJoinWorkerThread代表ForkJoinPool线程池中的一个执行任务的线程。
类图
Contended
即:缓存行与伪共享
如果看过 类似 disrupter 这种高效率队列的开源实现,大家肯定会对cache line记忆犹新,他们通常的做法自己设置伪变量来填充,jdk1.8�中官网为我们带来了sun.misc.Contended,所以你如果阅读ForkJoinPool源码可以发现该类也被sun.misc.Contended标识。
ForkJoinPool
WorkQueue是一个ForkJoinPool中的内部类,它是线程池中线程的工作队列的一个封装,支持任务窃取。
什么叫线程的任务窃取呢?就是说你和你的一个伙伴一起吃水果,你的那份吃完了,他那份没吃完,那你就偷偷的拿了他的一些水果吃了。存在执行2个任务的子线程,这里要讲成存在A,B两个个WorkQueue在执行任务,A的任务执行完了,B的任务没执行完,那么A的WorkQueue就从B的WorkQueue的ForkJoinTask数组中拿走了一部分尾部的任务来执行,可以合理的提高运行和计算效率。
每个线程都有一个WorkQueue,而WorkQueue中有执行任务的线程(ForkJoinWorkerThread owner),还有这个线程需要处理的任务(ForkJoinTask<?>[] array)。那么这个新提交的任务就是加到array中。
ForkJoinWorkerThread
ForkJoinWorkThread持有ForkJoinPool和ForkJoinPool.WorkQueue的引用,以表明该线程属于哪个线程池,它的工作队列是哪个。
使用示例
package bingfa; import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask; /**
* 数字相加
*/
public class ForkJoinTest extends RecursiveTask<Long> { private static final long serialVersionUID = 8396165282949096335L; private static int thresold = 2; private long start; private long end; public ForkJoinTest(long start, long end) {
if (start < end) {
this.start = start;
this.end = end;
} else {
this.start = end;
this.end = start;
}
} @Override
protected Long compute() {
long sum = 0;
boolean canCompute = (end - start) <= thresold;
if (canCompute) {
for (long i = start; i <= end; i++)
{
sum += i;
}
} else {
long mid = (start + end) >> 1;
ForkJoinTest leftTask = new ForkJoinTest(start, mid);
ForkJoinTest rightTask = new ForkJoinTest(mid + 1, end); // 执行子任务
// leftTask.fork();
// rightTask.fork();
invokeAll(leftTask, rightTask); sum = leftTask.join() + rightTask.join();
}
return sum;
} public static void main(String[] args) throws Exception {
ForkJoinPool.commonPool();
ForkJoinPool forkjoinPool = new ForkJoinPool(1);
ForkJoinTest task = new ForkJoinTest(1, 10000);
ForkJoinTask<Long> future = forkjoinPool.submit(task);
System.out.println(future.get());
System.out.println(forkjoinPool.getPoolSize());
}
}
api文档中的两个示例:
package bingfa; import java.util.Arrays;
import java.util.concurrent.*; /**
* 归并
*/
public class RecursiveActionDemo { private static class SortTask extends RecursiveAction { static final int THRESHOLD = 100; final long[] array;
final int lo, hi; public SortTask(long[] array, int lo, int hi) {
this.array = array;
this.lo = lo;
this.hi = hi;
} public SortTask(long[] array) {
this(array, 0, array.length);
} public void sortSequentially(int lo, int hi) {
Arrays.sort(array, lo, hi);
} public void merge(int lo, int mid, int hi) {
long[] buf = Arrays.copyOfRange(array, lo, mid);
for (int i = 0, j = lo, k = mid; i < buf.length; j++) {
array[j] = (k == hi || buf[i] < array[k]) ? buf[i++] : array[k++];
}
} @Override
protected void compute() {
if (hi - lo < THRESHOLD) {
sortSequentially(lo, hi);
}else {
int mid = (lo + hi) >>> 1;
invokeAll(new SortTask(array, lo, mid), new SortTask(array, mid, hi));
merge(lo, mid, hi);
}
}
} public static void main(String[] args) throws ExecutionException, InterruptedException {
long[] array = new long[120];
for (int i = 0; i < array.length; i++) {
array[i] = (long) (Math.random() * 1000);
}
System.out.println(Arrays.toString(array)); ForkJoinPool pool = new ForkJoinPool();
pool.submit(new SortTask(array));
pool.awaitTermination(5, TimeUnit.SECONDS);
pool.shutdown();
System.out.println(Arrays.toString(array));
} }
package com.cjs.boot.demo;
import java.util.concurrent.*;
public class RecursiveTaskDemo {
private static class Fibonacci extends RecursiveTask<Integer> {
final int n;
public Fibonacci(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1) {
return n;
}else {
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 1);
return f2.compute() + f1.join();
}
}
}
public static void main(String[] args) throws InterruptedException, ExecutionException {
ForkJoinPool pool = new ForkJoinPool();
Future<Integer> future = pool.submit(new Fibonacci(10));
System.out.println(future.get());
pool.shutdown();
}
}
错误范例
protected Long compute() {
if (任务足够小?) {
return computeDirect();
}
// 任务太大,一分为二:
SumTask subtask1 = new SumTask(...);
SumTask subtask2 = new SumTask(...);
// 分别对子任务调用fork():
subtask1.fork();
subtask2.fork();
// 合并结果:
Long subresult1 = subtask1.join();
Long subresult2 = subtask2.join();
return subresult1 + subresult2;
}
DK用来执行Fork/Join任务的工作线程池大小等于CPU核心数。在一个4核CPU上,最多可以同时执行4个子任务。对400个元素的数组求和,执行时间应该为1秒。但是,换成上面的代码,执行时间却是两秒。
这是因为执行compute()方法的线程本身也是一个Worker线程,当对两个子任务调用fork()时,这个Worker线程就会把任务分配给另外两个Worker,但是它自己却停下来等待不干活了!这样就白白浪费了Fork/Join线程池中的一个Worker线程,导致了4个子任务至少需要7个线程才能并发执行。
打个比方,假设一个酒店有400个房间,一共有4名清洁工,每个工人每天可以打扫100个房间,这样,4个工人满负荷工作时,400个房间全部打扫完正好需要1天。
Fork/Join的工作模式就像这样:首先,工人甲被分配了400个房间的任务,他一看任务太多了自己一个人不行,所以先把400个房间拆成两个200,然后叫来乙,把其中一个200分给乙。
紧接着,甲和乙再发现200也是个大任务,于是甲继续把200分成两个100,并把其中一个100分给丙,类似的,乙会把其中一个100分给丁,这样,最终4个人每人分到100个房间,并发执行正好是1天。
如果换一种写法:
// 分别对子任务调用fork():
subtask1.fork();
subtask2.fork();
这个任务就分!错!了!
比如甲把400分成两个200后,这种写法相当于甲把一个200分给乙,把另一个200分给丙,然后,甲成了监工,不干活,等乙和丙干完了他直接汇报工作。乙和丙在把200分拆成两个100的过程中,他俩又成了监工,这样,本来只需要4个工人的活,现在需要7个工人才能1天内完成,其中有3个是不干活的。
其实,我们查看JDK的invokeAll()方法的源码就可以发现,invokeAll的N个任务中,其中N-1个任务会使用fork()交给其它线程执行,但是,它还会留一个任务自己执行,这样,就充分利用了线程池,保证没有空闲的不干活的线程。
ForkJoin的更多相关文章
- Java并发之工具类 ForkJoin 任务分解
Fork/Join框架的介绍 第一步分割任务.首先我们需要有一个fork类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停的分割,直到分割出的子任务足够小. 第二步执行任务并合并结果.分割 ...
- Java并发编程核心方法与框架-Fork-Join分治编程(一)
在JDK1.7版本中提供了Fork-Join并行执行任务框架,它的主要作用是把大任务分割成若干个小任务,再对每个小任务得到的结果进行汇总,这种开发方法也叫做分治编程,可以极大地利用CPU资源,提高任务 ...
- 混合使用 ForkJoin, Akka, Future 实现一千万个不重复整数的排序
定位 本文适合于想要了解新语言 Scala 以及异步并发编程框架 Akka, Future 的筒鞋. 读完本文后,将了解如何使用 ForkJoin 框架.如何使用 Akka 构建并发程序.如何使用 ...
- ForkJoin框架
1. 什么是Fork/Join框架 Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架. 我们再通过 ...
- [转]Java并发的四种风味:Thread、Executor、ForkJoin和Actor
这篇文章讨论了Java应用中并行处理的多种方法.从自己管理Java线程,到各种更好几的解决方法,Executor服务.ForkJoin 框架以及计算中的Actor模型. Java并发编程的4种风格:T ...
- JAVA并行框架学习之ForkJoin
当硬件处理能力不能按照摩尔定律垂直发展的时候,选择了水平发展,多核处理器已经广泛应用.未来随着技术的进一步发展,可能出现成百上千个处理核心,但现有的程序运行在多核心处理器上并不能得到较大性能的提升,主 ...
- Java 8 的 JVM 有多快?Fork-Join 性能基准测试
Java 8 已经发布一段时间了,许多开发者已经开始使用 Java 8.本文也将讨论最新发布在 JDK 中的并发功能更新.事实上,JDK 中已经有多处java.util.concurrent 改动,但 ...
- 6.跑步者--并行编程框架 ForkJoin
本文如果您已经了解一般并行编程知识.了解Java concurrent部分如ExecutorService等相关内容. 虽说是Java的ForkJoin并行框架.但不要太在意Java,当中的思想在其他 ...
- java fork-join框架应用和分析
http://shmilyaw-hotmail-com.iteye.com/blog/1897636 java fork-join框架应用和分析 博客分类: concurrency multithre ...
- Java7中的ForkJoin并发框架初探(中)——JDK中实现简要分析
原文发表于 2013 年 8 月 28 日 由 三石 根据前文描述的Doug Lea的理论基础,在JDK1.7中已经给出了Fork Join的实现.在Java SE 7的API中,多了ForkJoin ...
随机推荐
- js之鼠标随动后面跟随事件(类似于长龙跟着跑)
<!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF-8&quo ...
- bash:command not found解决方法
先用:echo $PATH 查看path是否含有:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin如果没有先用临时环境变量(重启 ...
- 细菌多位点序列分型(Multilocus sequence typing,MLST)的原理及分型方法
摘 要: 多位点序列分型(MLST)是一种基于核酸序列测定的细菌分型方法,通过PCR扩增多个管家基因内部片段,测定其序列,分析菌株的变异,从而进行分型.MLST被广泛应用于病原菌.环境菌和真核生物中. ...
- Python深入:Distutils发布Python模块--转载
https://blog.csdn.net/gqtcgq/article/details/49255995 Distutils可以用来在Python环境中构建和安装额外的模块.新的模块可以是纯Pyth ...
- js中setTimeout和clearTimeout的使用
setTimeout,延迟n秒后执行指定代码 clearTimeout,清除计时器 <html> <head> <script type="text/javas ...
- django 配置 Django
Django项目的设置文件位于项目同名目录下,名叫settings.py.这个模块,集合了整个项目方方面面的设置属性,是项目启动和提供服务的根本保证. 一.简述 settings.py文件本质上是一个 ...
- Discrete Log Algorithms :Baby-step giant-step 【二】
import gmpy2 def discreteLog(g,p,a): #离散对数,求 g^x=a mod p中的x table={} sq=gmpy2.isqrt(p-1) m=gmpy2.add ...
- Xcode打包上传遇到的坑
1.安装测试包的时候提示APIInternalError ①是否增加了测试设备的UUID ②是否使用adhoc证书打包 2.打包错误:error: couldn't remove '/Users/xx ...
- zabbix自定义监控方式
- HTML 第九章总结
前言 这一章节主要讲了关于 HTML 中关于留白的知识:在这一章节中,从大到小,有: margin border padding context 这四个部分. 关于margin和padding mar ...