linux -- 基于zookeeper搭建yarn的HA高可用集群
linux -- 基于zookeeper搭建yarn的HA高可用集群
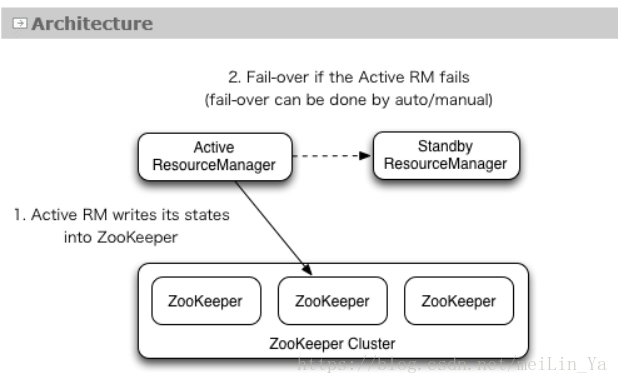
实现方式:配置yarn-site.xml配置文件
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value> beiwangyarn</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>1707a-hadoop1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>1707a-hadoop2</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>1707a-hadoop1:2181,1707a-hadoop2:2181,1707a-hadoop3:2181</value>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>1707a-hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>1707a-hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>1707a-hadoop1:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>1707a-hadoop1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>1707a-hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>1707a-hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>1707a-hadoop2:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>1707a-hadoop2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>1707a-hadoop2:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>1707a-hadoop2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>1707a-hadoop2:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>1707a-hadoop2:8033</value>
</property>
<property>
<description>Address where the localizer IPC is.</description>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:23344</value>
</property>
<property>
<description>NM Webapp address.</description>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:23999</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/tmp/pseudo-dist/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/tmp/pseudo-dist/yarn/log</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>1707a-hadoop1:2181,1707a-hadoop2:2181,1707a-hadoop3:2181</value>
</property>
</configuration>
将mapred-site.xml.template改为:mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hu-hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hu-hadoop1:19888</value>
</property>
</configuration>
同步数据
scp * hu-hadoop3:/`pwd`

启动:
start-yarn.sh
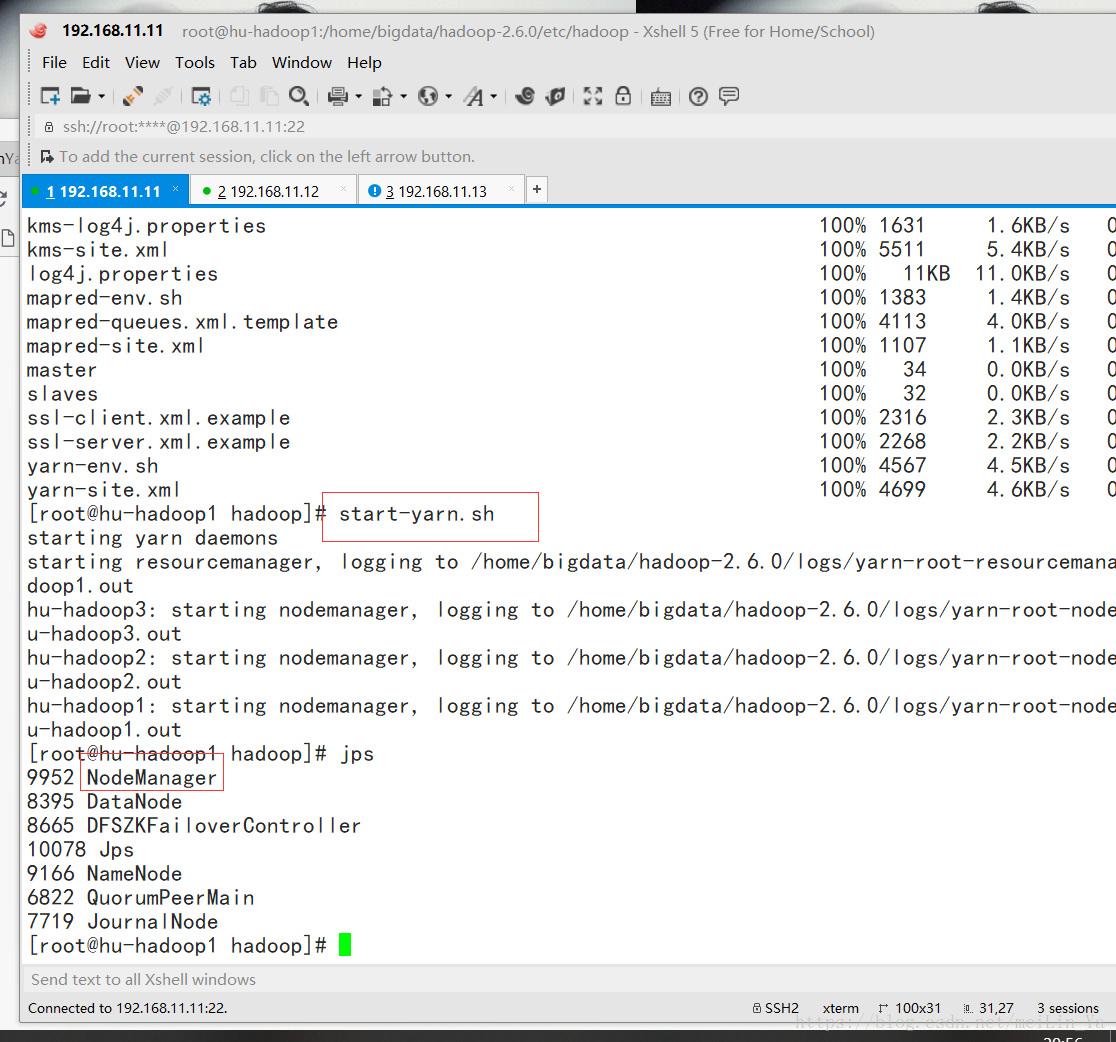
手动在hu-hadoop2中启动ResourceManager
yarn-daemon.sh start resourcemanager
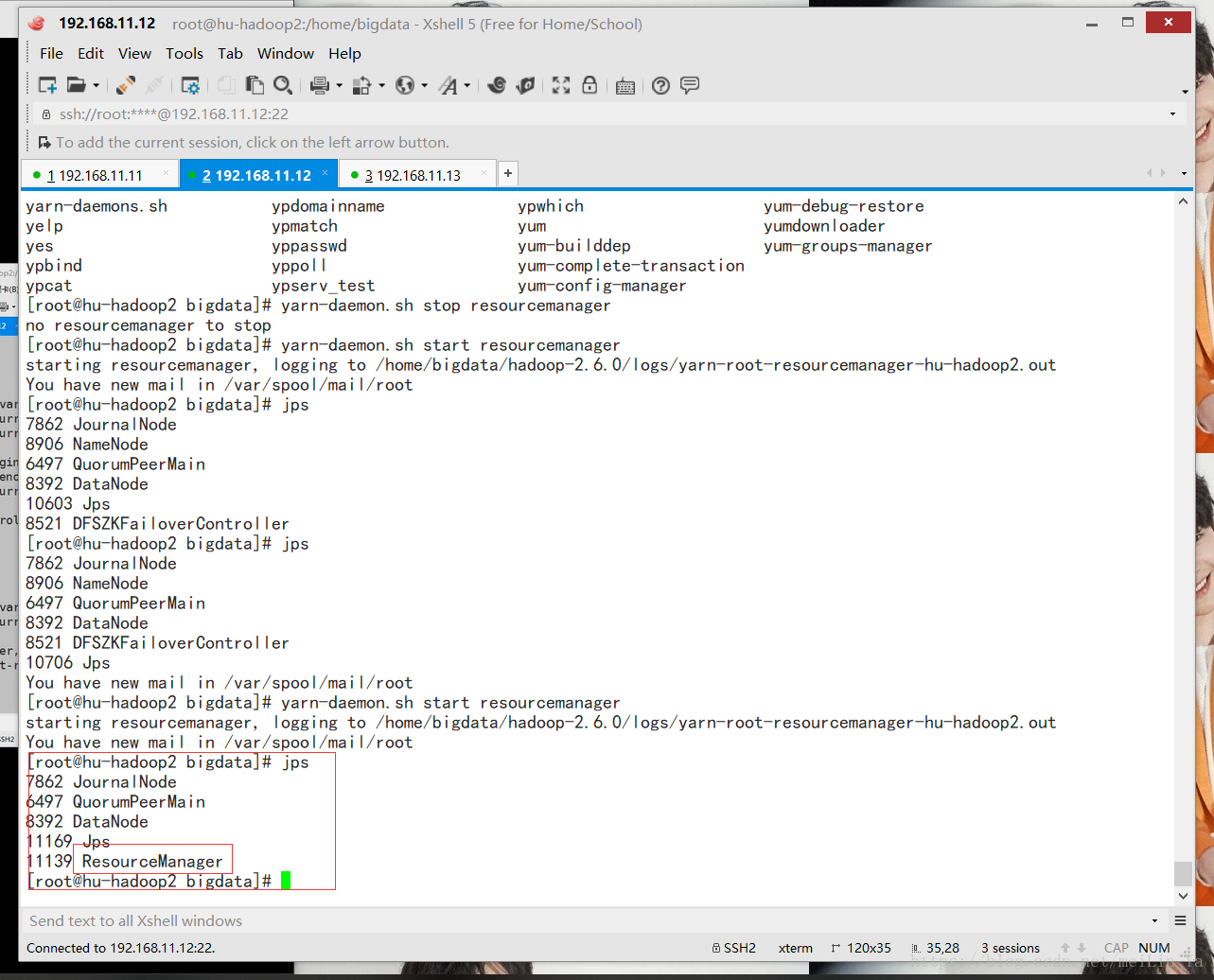

看看网页吧!!!
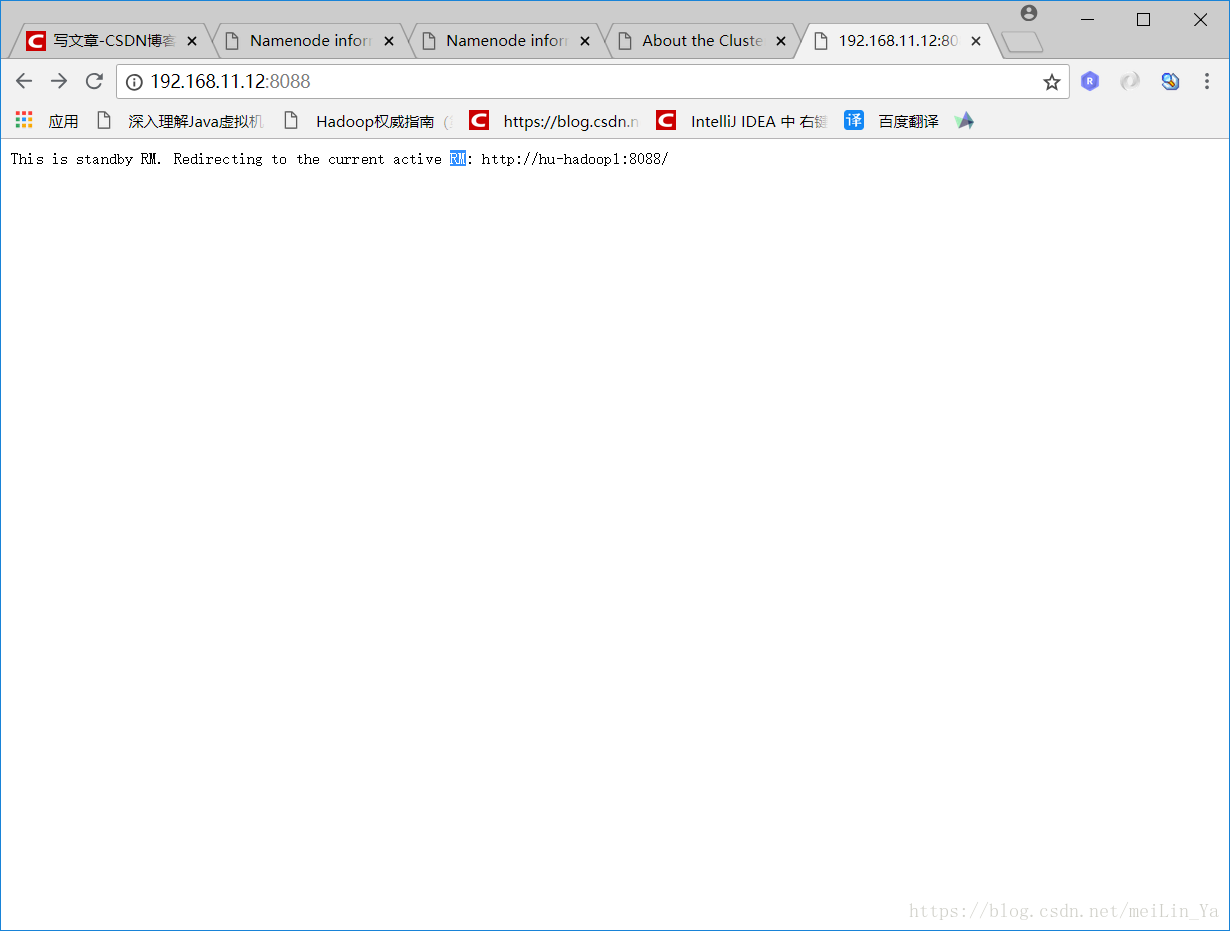
之后他会跳到主的页面中:
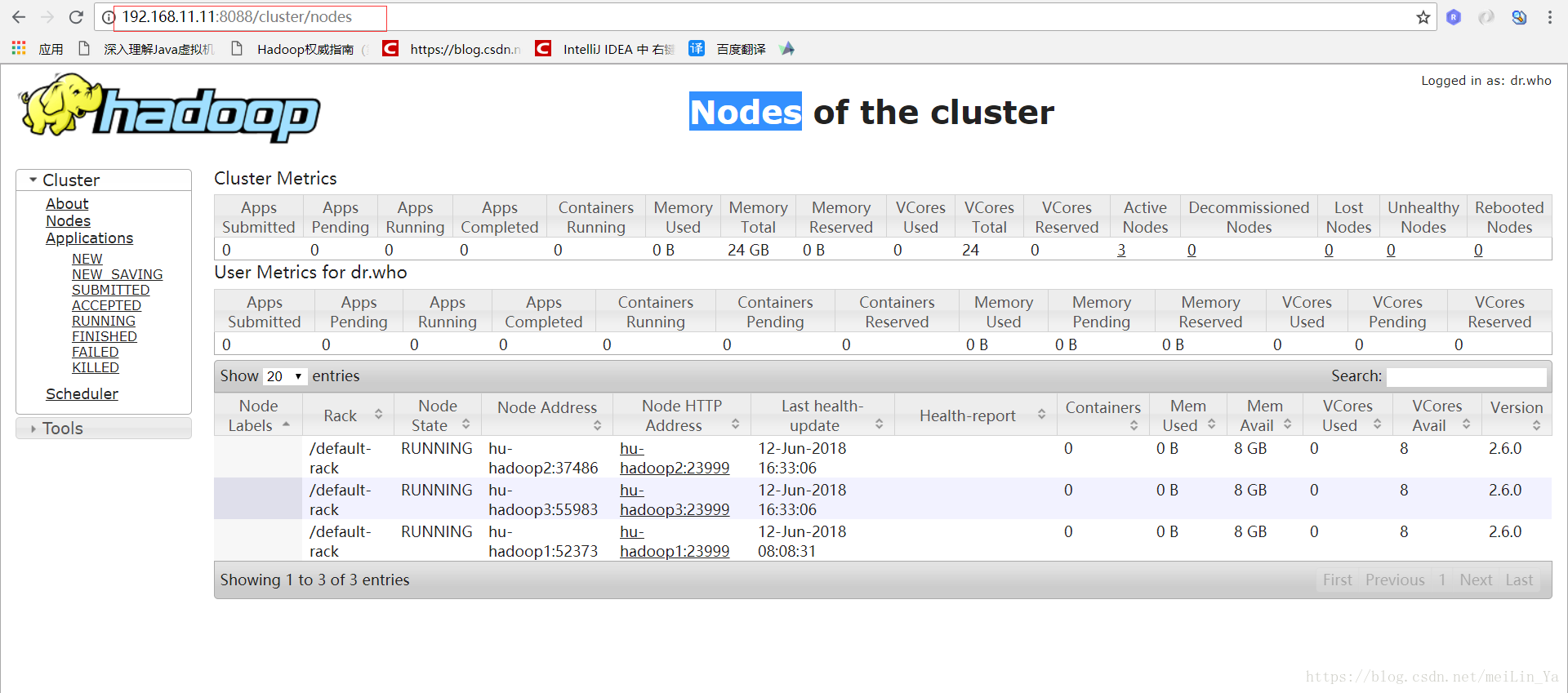
linux -- 基于zookeeper搭建yarn的HA高可用集群的更多相关文章
- 七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
目录 前文 Hadoop3.3.1 HA 高可用集群的搭建 QJM 的 NameNode HA Hadoop HA模式搭建(高可用) 1.集群规划 2.Zookeeper集群搭建: 3.修改Hadoo ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课
centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课 heartbeat是Linu ...
- HA 高可用集群概述及其原理解析
HA 高可用集群概述及其原理解析 1. 概述 1)所谓HA(High Available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件 ...
- 基于Keepalived实现LVS双主高可用集群
Reference: https://mp.weixin.qq.com/s?src=3×tamp=1512896424&ver=1&signature=L1C7us ...
- Kubeadm 1.9 HA 高可用集群本地离线镜像部署【已验证】
k8s介绍 k8s 发展速度很快,目前很多大的公司容器集群都基于该项目,如京东,腾讯,滴滴,瓜子二手车,易宝支付,北森等等. kubernetes1.9版本发布2017年12月15日,每三个月一个迭代 ...
- [K8s 1.9实践]Kubeadm 1.9 HA 高可用 集群 本地离线镜像部署
k8s介绍 k8s 发展速度很快,目前很多大的公司容器集群都基于该项目,如京东,腾讯,滴滴,瓜子二手车,北森等等. kubernetes1.9版本发布2017年12月15日,每是那三个月一个迭代, W ...
- Zookeeper(四)Hadoop HA高可用集群搭建
一.高可就集群搭建 1.集群规划 2.集群服务器准备 (1) 修改主机名(2) 修改 IP 地址(3) 添加主机名和 IP 映射(4) 同步服务器时间(5) 关闭防火墙(6) 配置免密登录(7) 安装 ...
随机推荐
- SAP 财务模块 FI-TV 差旅管理
SAP 财务模块 FI-TV 差旅管理 Travel Management差旅管理事务码 描述PRT3 Trip Costs: Maintain Postings ...
- Oracle spatial、openlayers、geoserver开发地理信息系统总结
感谢开源,使用OpenLayers+Geoserver的地理信息系统开发很简单,完全可以套用开发MIS系统的经验,我这里总结为三个步骤: 1.数据准备 2.数据发布 3.数据展现 我将按照这个思路来介 ...
- Android 4.0之后的日历控件拥挤的解决办法
本意是想做成这个样子的控件: 发现使用datepicker之后,效果完全不同,把整个日历都显示出来了.非常拥挤. 在datepicker中加入android:calendarViewShown=&qu ...
- activity 运行流程图
- AndroidImageSlider第一张图闪过的问题解决
1. AndroidImageSlider的使用: 参考源码:https://github.com/daimajia/AndroidImageSlider 当然网上介绍使用方法的很多,搜一搜. 2. ...
- 《剑指offer》第四十五题(把数组排成最小的数)
// 面试题45:把数组排成最小的数 // 题目:输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼 // 接出的所有数字中最小的一个.例如输入数组{3, 32, 321},则打印出这3 ...
- js 动画效果实现
1. 实现方式 - 应用场景 自己写 - 简单的.不用 jq 的项目 jq - 普通动画 成熟插件 - 复杂动画 2. 相关文章 JavaScript基于时间的动画算法 九种原生js动画效果 Twee ...
- PySpark笔记
spark源码位置:https://github.com/apache/spark Spark Core核心RDD及编程 什么是RDD:1.是一个抽象类不能直接使用,在子类中实现抽象方法是一个抽象类不 ...
- vue 导出excel表格
对于涉及到数据比较多的管理后台导出excel 表格这个需求就非常的常见了 所以? vue 怎么到处excel表格的? 有两种办法 1:请求接口后台直接给你的是excel文件,你需要做的就是怎么接收ex ...
- 第 8 章 容器网络 - 061 - flannel 的连通与隔离
flannel 的连通与隔离 测试 bbox1 和 bbxo2 的连通性: bbox1 能够 ping 到位于不同 subnet 的 bbox2,通过 traceroute 分析一下 bbox1 到 ...