pycharm下打开、执行并调试scrapy爬虫程序
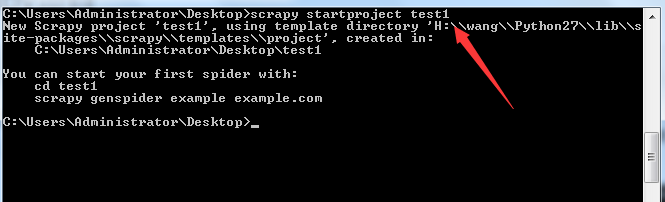
首先得有一个Scrapy项目,我在Desktop上新建一个Scrapy的项目叫test,在Desktop目录打开命令行,键入命令:
scrapy startproject test1
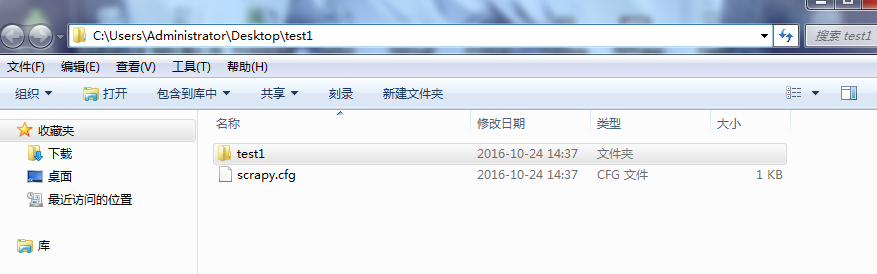
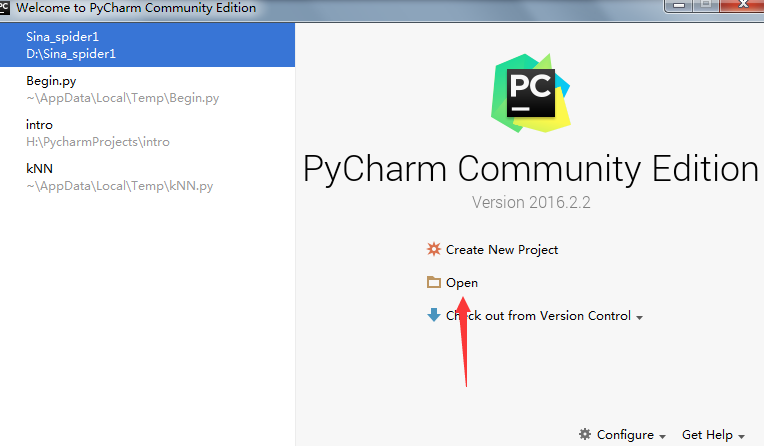
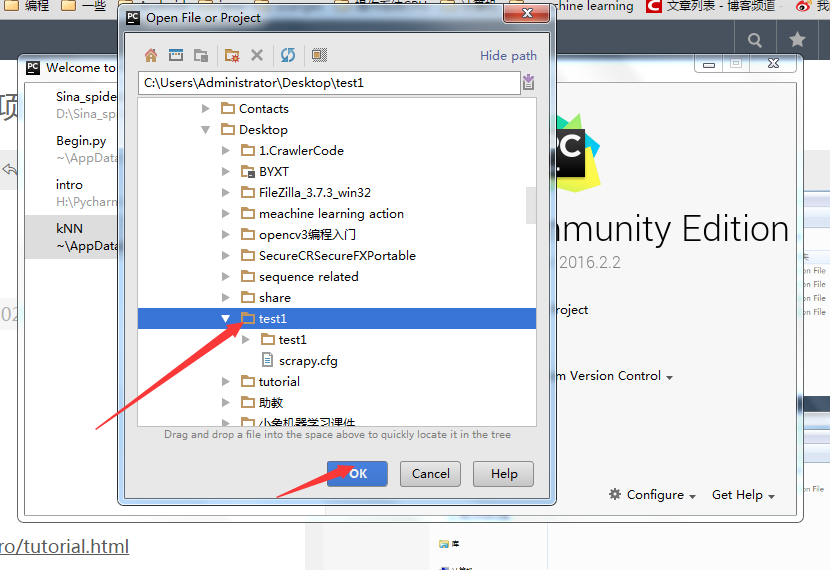
目录结构如下:打开Pycharm,选择open
选择项目,ok
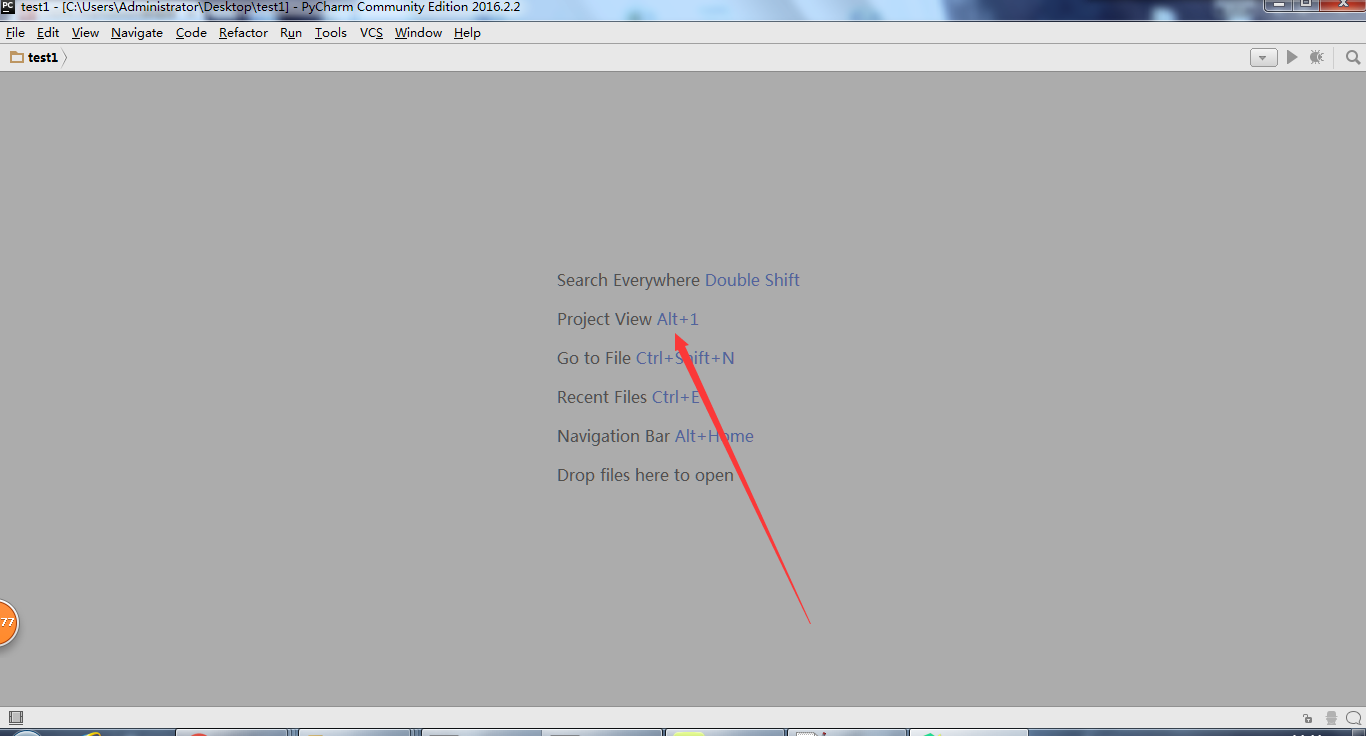
打开如下界面之后,按alt + 1, 打开project 面板
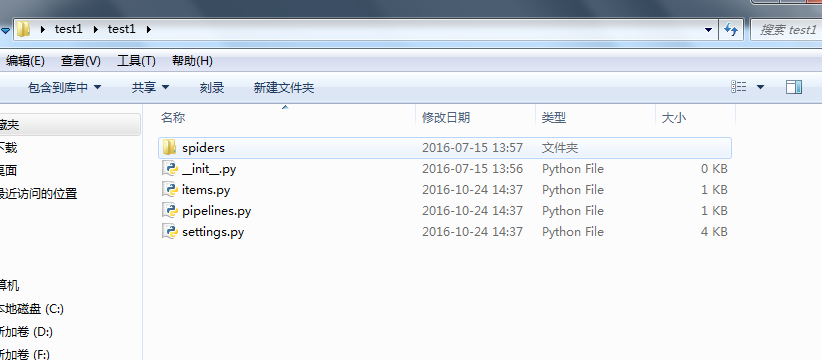
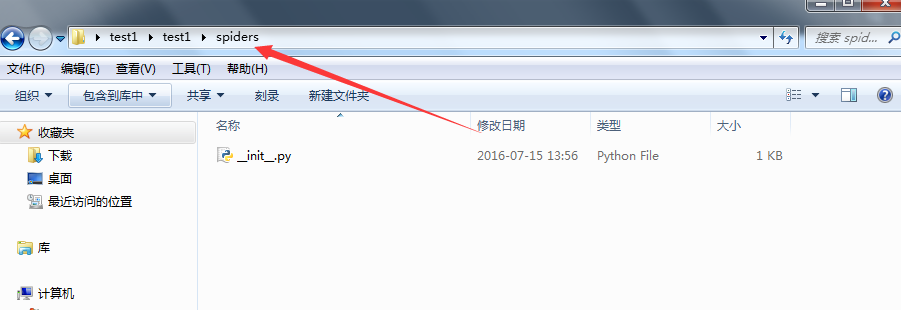
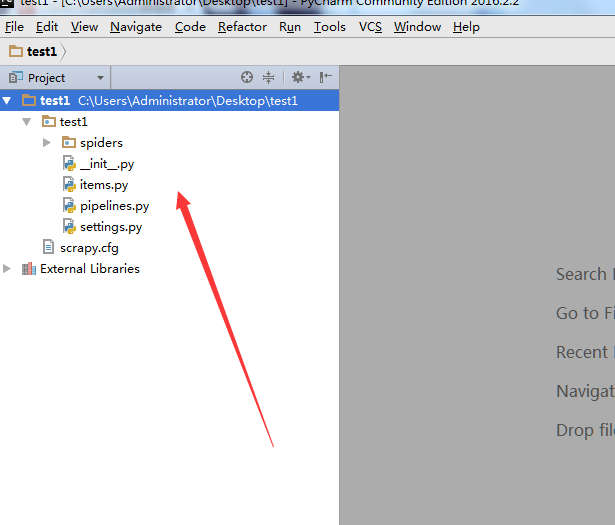
在test1/spiders/,文件夹下,新建一个爬虫spider.py, 注意代码中的
name="dmoz"。这个名字后面会用到。在test1目录和scrapy.cfg同级目录下面,新建一个begin.py文件(便于理解可以写成main.py),注意箭头2所指的名字和第5步中的
name='dmoz'名字是一样的。
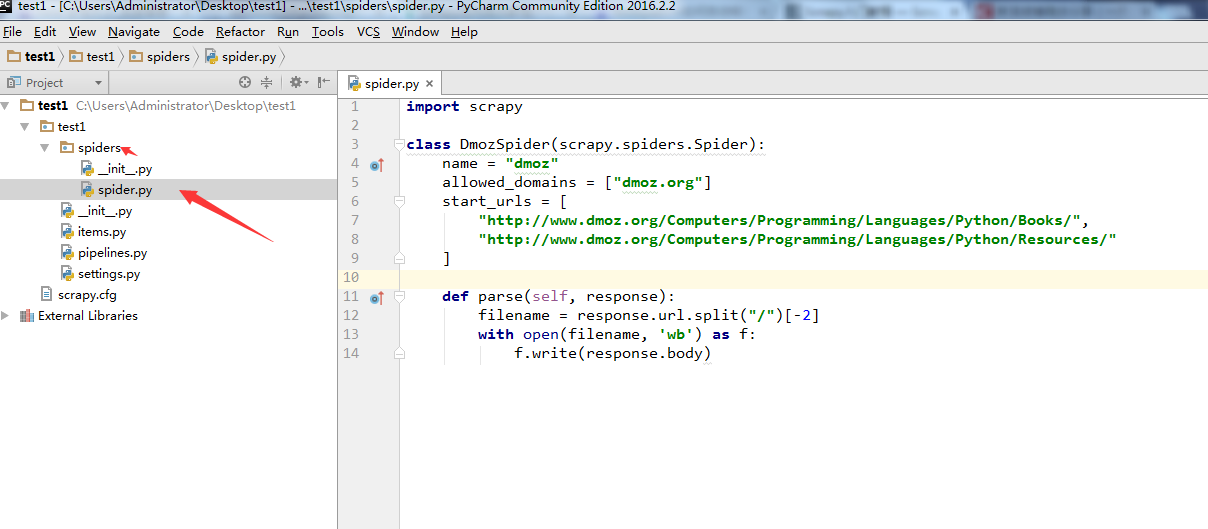
from scrapy import cmdline
cmdline.execute("scrapy crawl dmoz".split())- 1
- 2
- 3
- 1
- 2
- 3
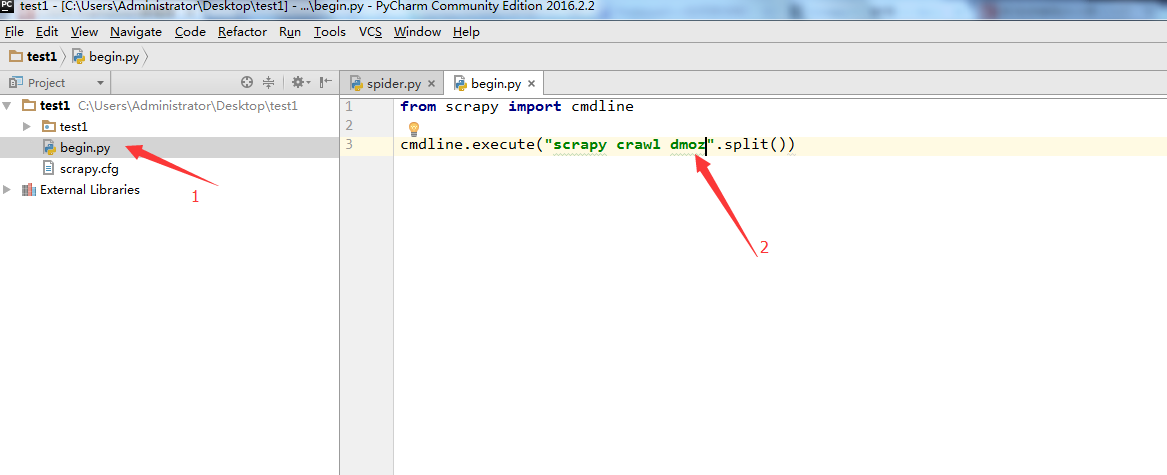
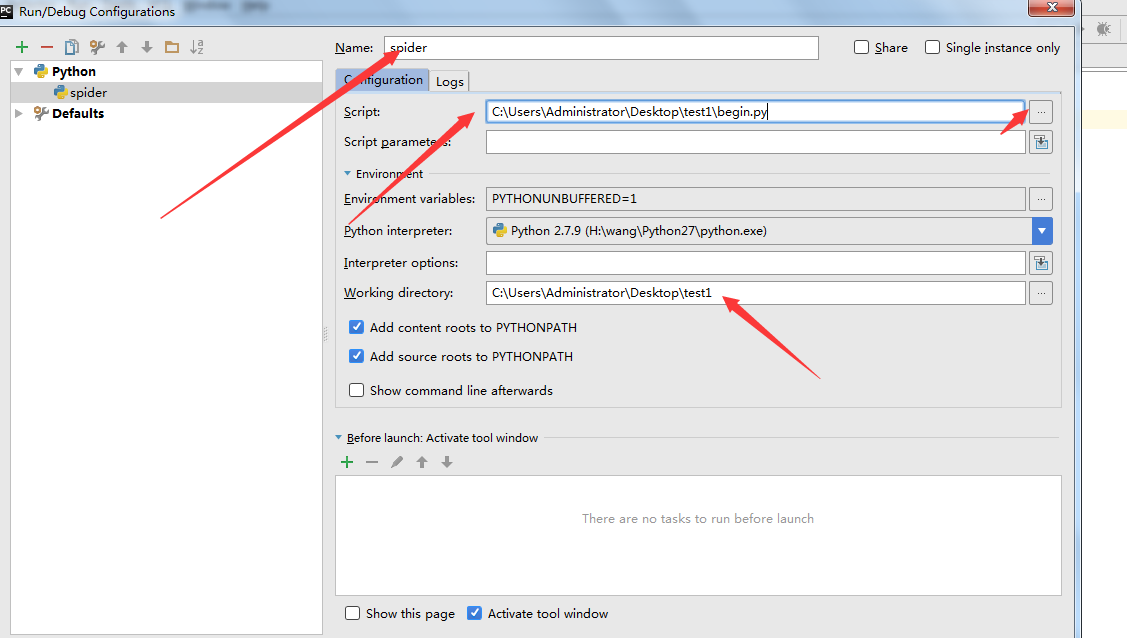
7. 上面把文件搞定了,下面要配置一下pycharm了。点击Run->Edit Configurations
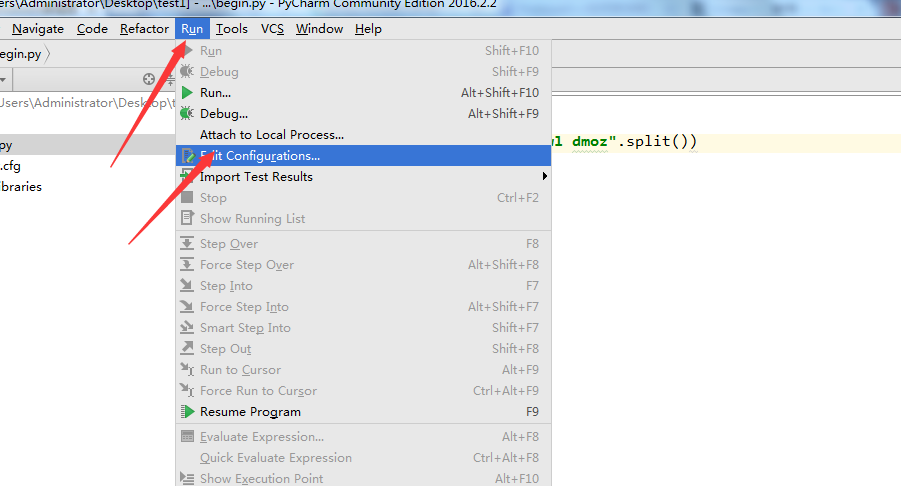
8. 新建一个运行的python模块
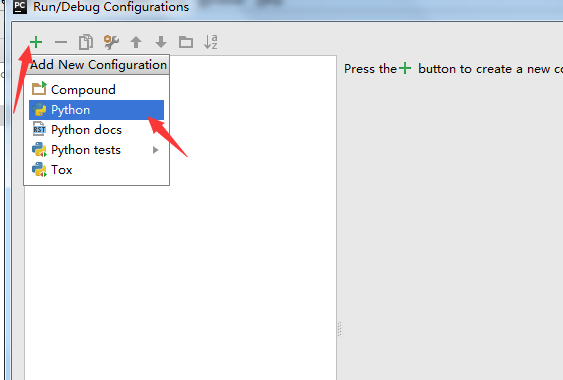
9. Name:改成spider; script:选择刚才新建的那个begin.py文件;Working Direciton:改成自己的工作目录
10. 至此,大功告成了,点击下图,右上角的按钮就能运行了。
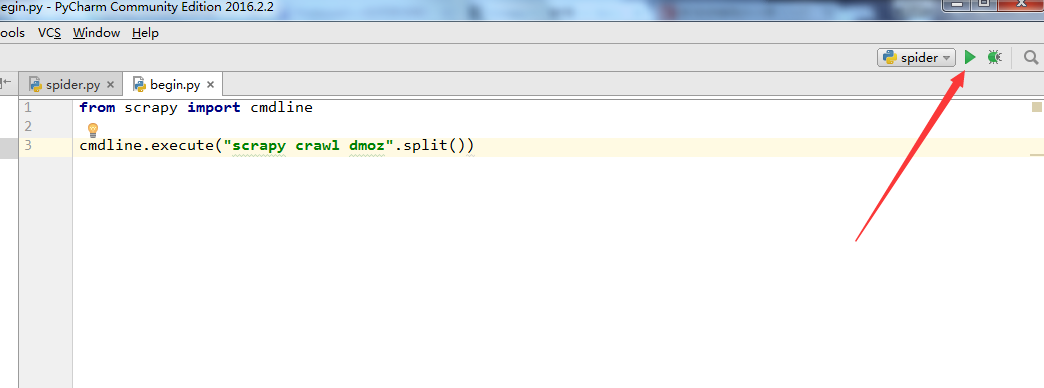
调试
可以在其他代码中设置断点,就可以debug运行


转载1:http://www.jianshu.com/p/f85120fcbca0
转载2:http://blog.csdn.net/wangsidadehao/article/details/52911746
pycharm下打开、执行并调试scrapy爬虫程序的更多相关文章
- liunx系统下crontab定时启动Scrapy爬虫程序
定时启动爬虫 # 查看命令得绝对路径 # which scrapy # cd到爬虫得项目目录下 + scrapy命令得绝对路径 + 启动命令 */5 * * * * cd /opt/mafengwo/ ...
- python2.7下同步华为云照片的爬虫程序实现
1.背景 随着华为手机的销量加大,华为云的捆绑服务使用量也越来越广泛,华为云支持自动同步照片.通讯录.记事本等,用着确实也挺方便的,云服务带来方便的同时,也带来了数据管理风险.华为目前只提供一个www ...
- scrapy爬虫程序xpath中文编码报错
2017-03-23 问题描述: #选择出节点中“时间”二字 <h2>时间</h2> item["file_urls"]= response.xpath(& ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- 关于Scrapy爬虫项目运行和调试的小技巧(上篇)
扫除运行Scrapy爬虫程序的bug之后,现在便可以开始进行编写爬虫逻辑了.在正式开始爬虫编写之前,在这里介绍四种小技巧,可以方便我们操纵和调试爬虫. 一.建立main.py文件,直接在Pycharm ...
- 关于Scrapy爬虫项目运行和调试的小技巧(下篇)
前几天给大家分享了关于Scrapy爬虫项目运行和调试的小技巧上篇,没来得及上车的小伙伴可以戳超链接看一下.今天小编继续沿着上篇的思路往下延伸,给大家分享更为实用的Scrapy项目调试技巧. 三.设置网 ...
- scrapy爬虫,cmd中执行日志中显示了爬取的内容,但是运行时隐藏日志后(运行命令后添加--nolog),就没有输出结果了
cmd下执行scrapy爬虫程序,不报错也没有输出,解决方案 想要执行parse能够在cmd看到parse函数的执行结果: 解决方法: settings.py 中设置 ROBOTSTXT_OBEY ...
- pycharm下运行和调试scrapy项目
1. 新建项目 默认在本地已经新建了一个scrapy爬虫项目 2. 打开项目 点击open à 选择刚刚那个本地的scrapy项目meijutt100 3. 项目结构 各个py文件的作用不作介绍,不懂 ...
- python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
现在我们现在一个分机上引入一个SCRAPY的爬虫项目,要求数据存储在MONGODB中 现在我们需要在SETTING.PY设置我们的爬虫文件 再添加PIPELINE 注释掉的原因是爬虫执行完后,和本地存 ...
随机推荐
- 引入jquery利用Vue生命周期的钩子函数mounted操作DOM
html <div id="app"> <div>{{message}}</div> </div> js var vm = new ...
- shiro中authc和user的权限区别
前者(authc)是认证过,后者(user)是登录过,如果开启了rememberMe功能的话,后者(user)也是可以通过的,而前者(authc)通过不了.故我们用authc来校验一些关键操作,比如购 ...
- Latex 三线表及设置列数
参考: latex的三线表格及一些错误的修改 latex 三线表 Latex 三线表 及设置列数 绘制三线表: \begin{table}[htbp] \caption{\label{tab:test ...
- 6、lvs使用进阶(02)
把web server服务和443服务绑定在一起之后呢? 假设一种场景,对web服务器来讲需要session保持.一个在线购物网站,在购物时,如果不结账,一般是http协议,当结账时,需要网站跳转,可 ...
- git切换分支报错:error: pathspec 'origin/XXX' did not match any file(s) known to git
项目上有一个分支test,使用git branch -a看不到该远程分支,直接使用命令git checkout test报错如下: error: pathspec 'origin/test' did ...
- 百度“搜索设置”之基于定位下拉框或者需要点击link才显示的下拉框,二次定位与多次定位实现的实际效果区别
还是基于上次那个练习的后续出现的思考,http://www.cnblogs.com/8013-cmf/p/6555790.html 界面: 源码: 写法如下: 继续解释这两种的区别: 1.其实基于定 ...
- ege demo
#include <ege.h> const float base_speed = 0.5f; const float randspeed = 1.5f; //自定义函数,用来返回一个0 ...
- swt-designer安装教程
http://jingyan.baidu.com/article/3f16e003c87b082590c10343.html
- axios写法
- angular在组件中选择dom元素
想选择 在组件中选择自己template里的dom元素,要使用ElementRef. import { Component, EventEmitter, HostListener, OnIni ...