Zookeeper简介与集群搭建【转】
Zookeeper简介
Zookeeper是一个高效的分布式协调服务,可以提供配置信息管理、命名、分布式同步、集群管理、数据库切换等服务。它不适合用来存储大量信息,可以用来存储一些配置、发布与订阅等少量信息。Hadoop、Storm、消息中间件、RPC服务框架、分布式数据库同步系统,这些都是Zookeeper的应用场景。
Zookeeper集群中节点个数一般为奇数个(>=3),若集群中Master挂掉,剩余节点个数在半数以上时,就可以推举新的主节点,继续对外提供服务。
客户端发起事务请求,事务请求的结果在整个Zookeeper集群中所有机器上的应用情况是一致的。不会出现集群中部分机器应用了该事务,而存在另外一部分集群中机器没有应用该事务的情况。在Zookeeper集群中的任何一台机器,其看到的服务器的数据模型是一致的。Zookeeper能够保证客户端请求的顺序,每个请求分配一个全局唯一的递增编号,用来反映事务操作的先后顺序。Zookeeper将全量数据保存在内存中,并直接服务于所有的非事务请求,在以读操作为主的场景中性能非常突出。
Zookeeper使用的数据结构为树形结构,根节点为"/"。Zookeeper集群中的节点,根据其身份特性分为leader、follower、observer。leader负责客户端writer类型的请求;follower负责客户端reader类型的请求,并参与leader选举;observer是特殊的follower,可以接收客户端reader请求,但是不会参与选举,可以用来扩容系统支撑能力,提高读取速度。
Zookeeper是一个基于观察者模式设计的分布式服务管理框架,负责存储和管理相关数据,接收观察者的注册。一旦这些数据的状态发生变化,zookeeper就负责通知那些已经在zookeeper集群进行注册并关心这些状态发生变化的观察者,以便观察者执行相关操作。
Zookeeper使用的是ZAB原子消息广播协议,节点之间的一致性算法为Paxos,能够保障分布式环境中数据的一致性。分布式场景下高可用是Zookeeper的特性,可以采用第三方客户端的实现,即Curator框架。
memory)和消息传递(Messages passing)。Paxos 算法就是一种基于消息传递模型的一致性算法。
Zookeeper集群搭建
在本文中Zookeeper节点个数(奇数)为3个。Zookeeper默认对外提供服务的端口号2181 。Zookeeper集群内部3个节点之间通信默认使用2888:3888
192.168.0.217 192.168.0.218 192.168.0.219
下载zookeeper对应的tar包
分别上传tar包到192.168.0.217
192.168.0.218 192.168.0.219
在217、218、219三个zookeeper节点上分别执行下行指令,然后将解压后的文件名zookeeper-3.4.10修改为zookeeper。
tar -zxvf zookeeper-3.4.10.tar.gz -C /usr/local/
在三个zookeeper节点配置环境变量
vim /etc/profile
添加export ZOOKEEPER_HOME=/usr/local/zookeeper
在path中添加$ZOOKEEPER_HOME/bin
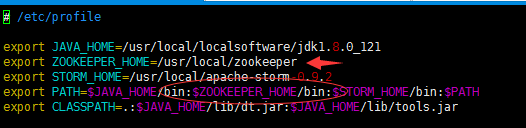
执行source /etc/profile 使环境变量立即生效
修改zookeeper中conf目录下的zoo_sample.cfg为zoo.cfg
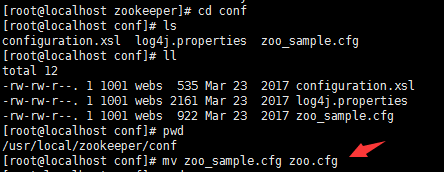
修改三个zookeeper节点中的zoo.cfg文件,修改dataDir,添加server.0、server.1、server.2
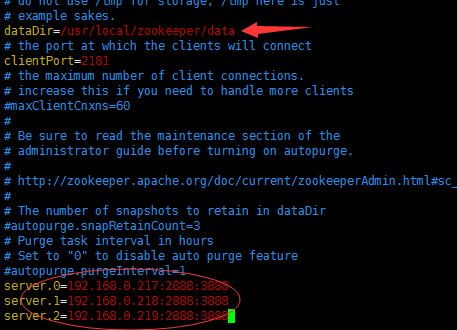
在zookeeper目录下,创建data目录。在3个zookeeper节点中data目录下分别创建myid文件,并分别添加内容0、1、2



启动zookeeper
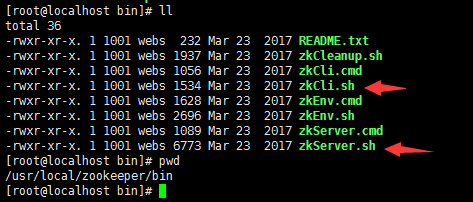
zkServer.sh start
zkServer.sh status
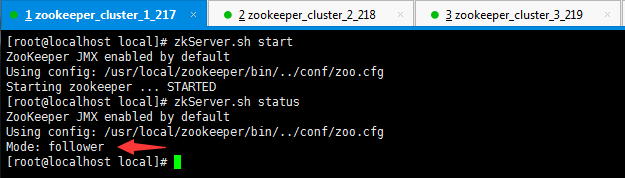
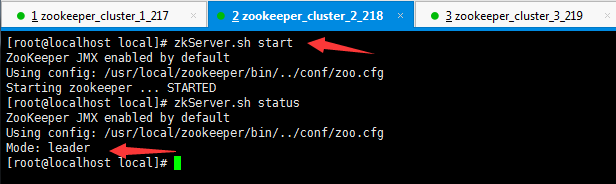
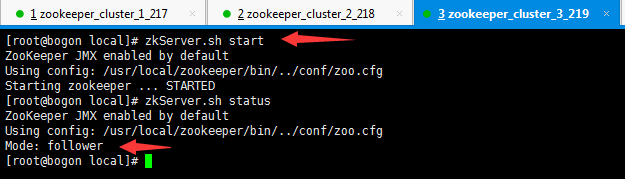
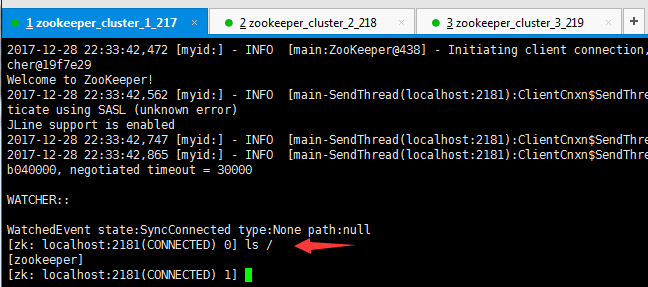
在zookeeper中任意一个节点,执行指令zkCli.sh
执行指令zkCli.sh help ,查看帮助信息
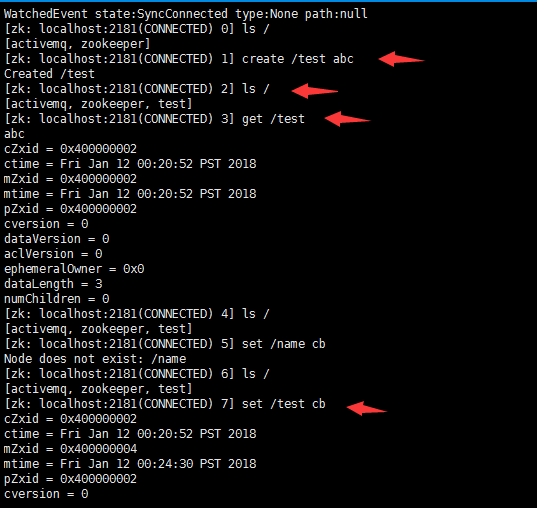
ls / 查找根目录
create /test abc 创建节点并赋值
get /test 获取指定节点的值
set /test cb 设置已存在节点的值
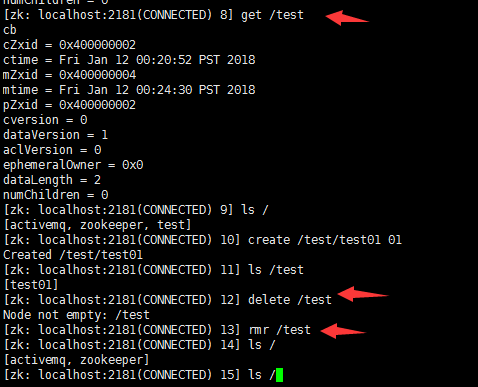
rmr /test 递归删除节点
delete /test/test01 删除不存在子节点的节点
在Eclipse中查看Zookeeper集群节点
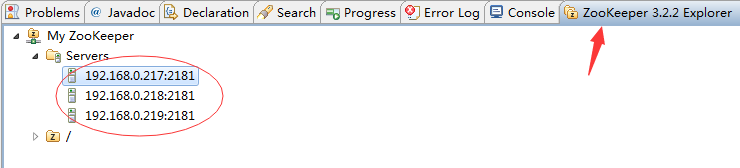
也可以使用ZooInspector查看。

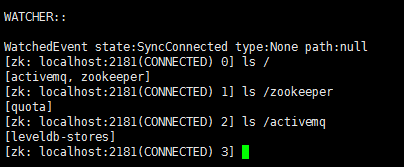
此时,在Xshell中执行zkCli.sh,查看Zookeeper集群中树形结构的内容
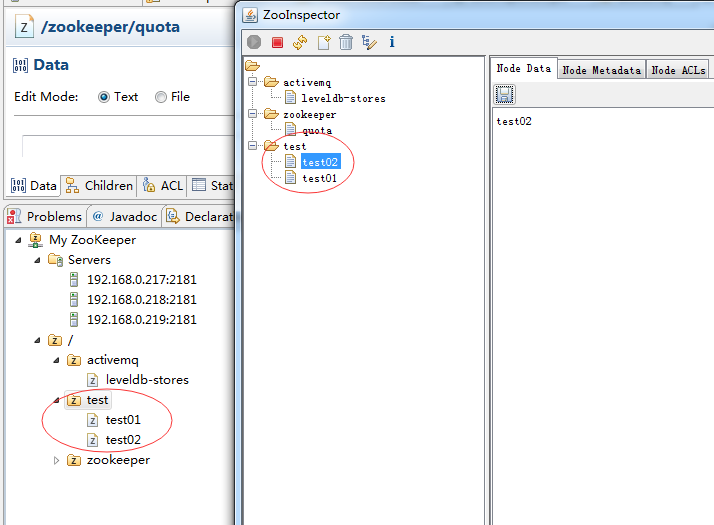
在Eclipse、ZooInspector中均可以添加、删除Zookeeper集群的节点
转自
Zookeeper简介与集群搭建 - CSDN博客 https://blog.csdn.net/qiushisoftware/article/details/79043379
Zookeeper简介与集群搭建【转】的更多相关文章
- Zookeeper简介与集群搭建
Zookeeper简介 Zookeeper是一个高效的分布式协调服务,可以提供配置信息管理.命名.分布式同步.集群管理.数据库切换等服务.它不适合用来存储大量信息,可以用来存储一些配置.发布与订阅等少 ...
- 基于zookeeper的Swarm集群搭建
简介 Swarm:docker原生的集群管理工具,将一组docker主机作为一个虚拟的docker主机来管理. 对客户端而言,Swarm集群就像是另一台普通的docker主机. Swarm集群中的每台 ...
- zookeeper及kafka集群搭建
zookeeper及kafka集群搭建 1.有关zookeeper的介绍可参考:http://www.cnblogs.com/wuxl360/p/5817471.html 2.zookeeper安装 ...
- 【运维技术】Zookeeper单机以及集群搭建教程
Zookeeper单机以及集群搭建教程 单机搭建 单机安装以及启动 安装zookeeper的前提是必须有java环境 # 选择目录进行下载安装 cd /app # 下载zk,可以去官方网站下载,自己上 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- zookeeper高可用集群搭建
前提:已经在master01配置好hadoop:在各个slave节点配置好hadoop和zookeeper: (该文是将zookeeper配置在各slave节点上的,其实也可以配置在各master上, ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- zookeeper 高可用集群搭建
前言 记录Zookeeper集群搭建的过程! 什么是 Zookeeper ? ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hado ...
- zookeeper安装与集群搭建
此处以centos系统下zookeeper安装为例,详细步骤可参考官网文档:zookeeper教程 一.单节点部署 1.下载zookeeper wget http://mirrors.hust.edu ...
随机推荐
- 【AGC010D】Decrementing
Solution 日常博弈论做不出来. 首先,数值全部为1的局面先手必败. 在接下来的过程中,我们只关注那些大于1的数值. 按照官方题解的思路,首先想一个简化版的问题:没有除的操作,其余相同.那么局面 ...
- Dijstra算法求最短路径
参考博客:http://blog.51cto.com/ahalei/1387799 与Floyd-Warshall算法一样这里仍然使用二维数组e来存储顶点之间边的关系,初始值如下. ...
- (转)使用 Spring缓存抽象 支持 EhCache 和 Redis 混合部署
背景:最近项目组在开发本地缓存,其中用到了redis和ehcache,但是在使用注解过程中发现两者会出现冲突,这里给出解决两者冲突的具体方案. spring-ehcache.xml配置: <?x ...
- 服务器内存占用不断的增加 & 任务管理器(PF使用率)不断的增加:关注句柄数
最近一二个月以来,我发现服务器的内存占用正按着每天60M的速度增加. 一台windows 2003的服务器(2G内存),刚刚启起时占用内存:600M左右. 运行20天后,内存占用(PF使用):1.8G ...
- git中如何切换分支,拉取分支,合并分支
idea中如何使用git来做分支的切换合并: https://blog.csdn.net/autfish/article/details/52513465 本地分支与远程分支: https://seg ...
- pyglet and opengl -- 纹理映射以及动画
#-*- coding:gbk -*- #from pyglet.gl import * from OpenGL.GL import * import pyglet from pyglet impor ...
- 《Linux就该这么学》第二期视频
Linux就该这么学--第二期学习笔记... ------------- 你的未来取决于你现在点点滴滴的努力 需要用到的一些工具: Vm11激活码 ---------- root在Linux系统中相当 ...
- 函数和常用模块【day05】:生成器(四)
本节内容 1.概述 2.列表生成式 3.生成器 4.函数实现生成器 5.生成器表达式 一.概述 我们在使用一组数据时,通常情况下会定义一个列表,然后循环里面的元素,但是你想过没有,如果你只需要使用列表 ...
- MVC中常用的跳转方法
MVC中常用的跳转方法 这里总结了几种MVC中的跳转方式,主要汇总了前端页面跳转,后台的跳转,和过滤器中的跳转方式. 1.在前端页面的跳转方式 <!--属性形式---> <a hre ...
- Spring RMI (Spring 远程方法调用)【原】
所需jar包...? 不纠结,一股脑儿全导! 源码地址:http://pan.baidu.com/s/1jG8eOmy 先放结构图如下,客户端和服务端都在一个项目中.也可以把服务端的xxx导成j ...