从Elasticsearch来看分布式系统架构设计
分布式系统类型多,涉及面非常广,不同类型的系统有不同的特点,批量计算和实时计算就差别非常大。这篇文章中,重点会讨论下分布式数据系统的设计,比如分布式存储系统,分布式搜索系统,分布式分析系统等。
我们先来简单看下Elasticsearch的架构。
Elasticsearch 集群架构
Elasticsearch是一个非常著名的开源搜索和分析系统,目前被广泛应用于互联网多种领域中,尤其是以下三个领域特别突出。一是搜索领域,相对于solr,真正的后起之秀,成为很多搜索系统的不二之选。二是Json文档数据库,相对于MongoDB,读写性能更佳,而且支持更丰富的地理位置查询以及数字、文本的混合查询等。三是时序数据分析处理,目前是日志处理、监控数据的存储、分析和可视化方面做得非常好,可以说是该领域的引领者了。
Elasticsearch的详细介绍可以到官网查看。我们先来看一下Elasticsearch中几个关键概念:
节点(Node):物理概念,一个运行的Elasticearch实例,一般是一台机器上的一个进程。
索引(Index),逻辑概念,包括配置信息mapping和倒排正排数据文件,一个索引的数据文件可能会分布于一台机器,也有可能分布于多台机器。索引的另外一层意思是倒排索引文件。
分片(Shard):为了支持更大量的数据,索引一般会按某个维度分成多个部分,每个部分就是一个分片,分片被节点(Node)管理。一个节点(Node)一般会管理多个分片,这些分片可能是属于同一份索引,也有可能属于不同索引,但是为了可靠性和可用性,同一个索引的分片尽量会分布在不同节点(Node)上。分片有两种,主分片和副本分片。
副本(Replica):同一个分片(Shard)的备份数据,一个分片可能会有0个或多个副本,这些副本中的数据保证强一致或最终一致。
用图形表示出来可能是这样子的:

Index 1:蓝色部分,有3个shard,分别是P1,P2,P3,位于3个不同的Node中,这里没有Replica。
Index 2:绿色部分,有2个shard,分别是P1,P2,位于2个不同的Node中。并且每个shard有一个replica,分别是R1和R2。基于系统可用性的考虑,同一个shard的primary和replica不能位于同一个Node中。这里Shard1的P1和R1分别位于Node3和Node2中,如果某一刻Node2发生宕机,服务基本不会受影响,因为还有一个P1和R2都还是可用的。因为是主备架构,当主分片发生故障时,需要切换,这时候需要选举一个副本作为新主,这里除了会耗费一点点时间外,也会有丢失数据的风险。
Index流程
建索引(Index)的时候,一个Doc先是经过路由规则定位到主Shard,发送这个doc到主Shard上建索引,成功后再发送这个Doc到这个Shard的副本上建索引,等副本上建索引成功后才返回成功。
在这种架构中,索引数据全部位于Shard中,主Shard和副本Shard各存储一份。当某个副本Shard或者主Shard丢失(比如机器宕机,网络中断等)时,需要将丢失的Shard在其他Node中恢复回来,这时候就需要从其他副本(Replica)全量拷贝这个Shard的所有数据到新Node上构造新Shard。这个拷贝过程需要一段时间,这段时间内只能由剩余主副本来承载流量,在恢复完成之前,整个系统会处于一个比较危险的状态,直到failover结束。
这里就体现了副本(Replica)存在的一个理由,避免数据丢失,提高数据可靠性。副本(Replica)存在的另一个理由是读请求量很大的时候,一个Node无法承载所有流量,这个时候就需要一个副本来分流查询压力,目的就是扩展查询能力。
角色部署方式
接下来再看看角色分工的两种不同方式:
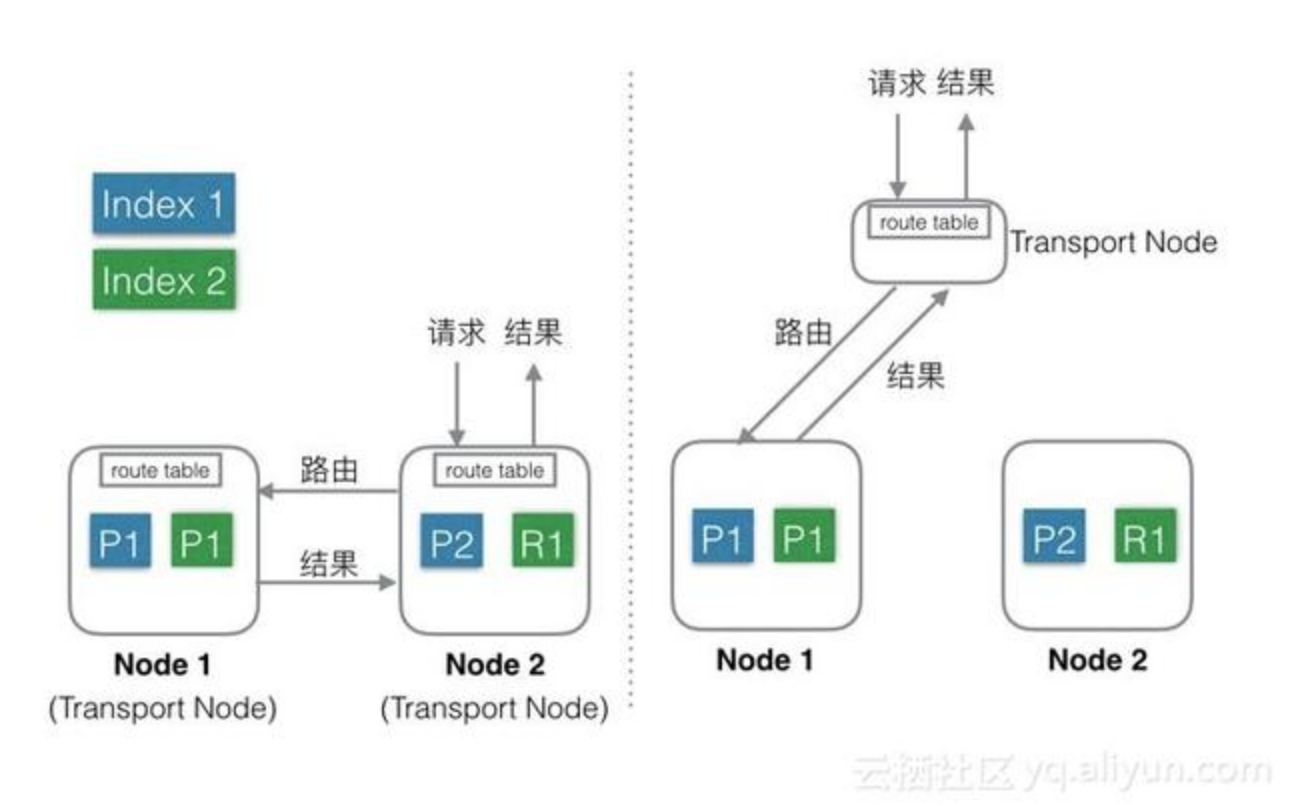
Elasticsearch支持上述两种方式:
混合部署(左图):
默认方式。
不考虑MasterNode的情况下,还有两种Node,Data Node和Transport Node,这种部署模式下,这两种不同类型Node角色都位于同一个Node中,相当于一个Node具备两种功能:Data和Transport。
当有index或者query请求的时候,请求随机(自定义)发送给任何一个Node,这台Node中会持有一个全局的路由表,通过路由表选择合适的Node,将请求发送给这些Node,然后等所有请求都返回后,合并结果,然后返回给用户。一个Node分饰两种角色。
好处就是使用极其简单,易上手,对推广系统有很大价值。最简单的场景下只需要启动一个Node,就能完成所有的功能。
缺点就是多种类型的请求会相互影响,在大集群如果某一个Data Node出现热点,那么就会影响途经这个Data Node的所有其他跨Node请求。如果发生故障,故障影响面会变大很多。
Elasticsearch中每个Node都需要和其余的每一个Node都保持13个连接。这种情况下,每个Node都需要和其他所有Node保持连接,而一个系统的连接数是有上限的,这样连接数就会限制集群规模。
还有就是不能支持集群的热更新。
分层部署(右图):
通过配置可以隔离开Node。
设置部分Node为Transport Node,专门用来做请求转发和结果合并。
其他Node可以设置为DataNode,专门用来处理数据。
缺点是上手复杂,需要提前设置好Transport的数量,且数量和Data Node、流量等相关,否则要么资源闲置,要么机器被打爆。
好处就是角色相互独立,不会相互影响,一般Transport Node的流量是平均分配的,很少出现单台机器的CPU或流量被打满的情况,而DataNode由于处理数据,很容易出现单机资源被占满,比如CPU,网络,磁盘等。独立开后,DataNode如果出了故障只是影响单节点的数据处理,不会影响其他节点的请求,影响限制在最小的范围内。
角色独立后,只需要Transport Node连接所有的DataNode,而DataNode则不需要和其他DataNode有连接。一个集群中DataNode的数量远大于Transport Node,这样集群的规模可以更大。另外,还可以通过分组,使Transport Node只连接固定分组的DataNode,这样Elasticsearch的连接数问题就彻底解决了。
可以支持热更新:先一台一台的升级DataNode,升级完成后再升级Transport Node,整个过程中,可以做到让用户无感知。
上面介绍了Elasticsearch的部署层架构,不同的部署方式适合不同场景,需要根据自己的需求选择适合的方式。
Elasticsearch 数据层架构
接下来我们看看当前Elasticsearch的数据层架构。
数据存储
Elasticsearch的Index和meta,目前支持存储在本地文件系统中,同时支持niofs,mmap,simplefs,smb等不同加载方式,性能最好的是直接将索引LOCK进内存的MMap方式。默认,Elasticsearch会自动选择加载方式,另外可以自己在配置文件中配置。这里有几个细节,具体可以看官方文档。
索引和meta数据都存在本地,会带来一个问题:当某一台机器宕机或者磁盘损坏的时候,数据就丢失了。为了解决这个问题,可以使用Replica(副本)功能。
副本(Replica)
可以为每一个Index设置一个配置项:副本(Replicda)数,如果设置副本数为2,那么就会有3个Shard,其中一个是PrimaryShard,其余两个是ReplicaShard,这三个Shard会被Mater尽量调度到不同机器,甚至机架上,这三个Shard中的数据一样,提供同样的服务能力。
副本(Replica)的目的有三个:
保证服务可用性:当设置了多个Replica的时候,如果某一个Replica不可用的时候,那么请求流量可以继续发往其他Replica,服务可以很快恢复开始服务。
保证数据可靠性:如果只有一个Primary,没有Replica,那么当Primary的机器磁盘损坏的时候,那么这个Node中所有Shard的数据会丢失,只能reindex了。
提供更大的查询能力:当Shard提供的查询能力无法满足业务需求的时候, 可以继续加N个Replica,这样查询能力就能提高N倍,轻松增加系统的并发度。
问题
上面说了一些优势,这种架构同样在一些场景下会有些问题。
Elasticsearch采用的是基于本地文件系统,使用Replica保证数据可靠性的技术架构,这种架构一定程度上可以满足大部分需求和场景,但是也存在一些遗憾:
Replica带来成本浪费。为了保证数据可靠性,必须使用Replica,但是当一个Shard就能满足处理能力的时候,另一个Shard的计算能力就会浪费。
Replica带来写性能和吞吐的下降。每次Index或者update的时候,需要先更新Primary Shard,更新成功后再并行去更新Replica,再加上长尾,写入性能会有不少的下降。
当出现热点或者需要紧急扩容的时候动态增加Replica慢。新Shard的数据需要完全从其他Shard拷贝,拷贝时间较长。
上面介绍了Elasticsearch数据层的架构,以及副本策略带来的优势和不足,下面简单介绍了几种不同形式的分布式数据系统架构。
分布式系统
第一种:基于本地文件系统的分布式系统
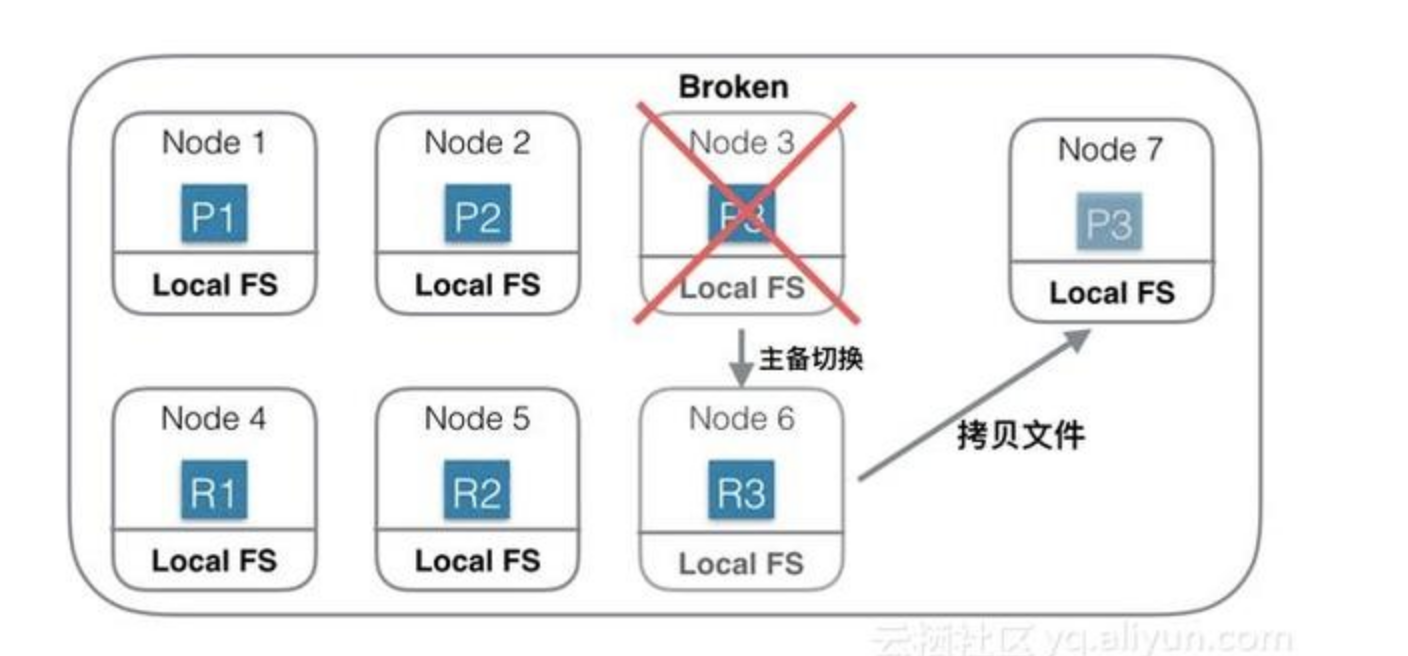
上图中是一个基于本地磁盘存储数据的分布式系统。Index一共有3个Shard,每个Shard除了Primary Shard外,还有一个Replica Shard。当Node 3机器宕机或磁盘损坏的时候,首先确认P3已经不可用,重新选举R3位Primary Shard,此Shard发生主备切换。然后重新找一台机器Node 7,在Node7 上重新启动P3的新Replica。由于数据都会存在本地磁盘,此时需要将Shard 3的数据从Node 6上拷贝到Node7上。如果有200G数据,千兆网络,拷贝完需要1600秒。如果没有replica,则这1600秒内这些Shard就不能服务。
为了保证可靠性,就需要冗余Shard,会导致更多的物理资源消耗。
这种思想的另外一种表现形式是使用双集群,集群级别做备份。
在这种架构中,如果你的数据是在其他存储系统中生成的,比如HDFS/HBase,那么你还需要一个数据传输系统,将准备好的数据分发到相应的机器上。
这种架构中为了保证可用性和可靠性,需要双集群或者Replica才能用于生产环境,优势和副作用在上面介绍Elasticsearch的时候已经介绍过了,这里就就不赘述了。
Elasticsearch使用的就是这种架构方式。
第二种:基于分布式文件系统的分布式系统(共享存储)
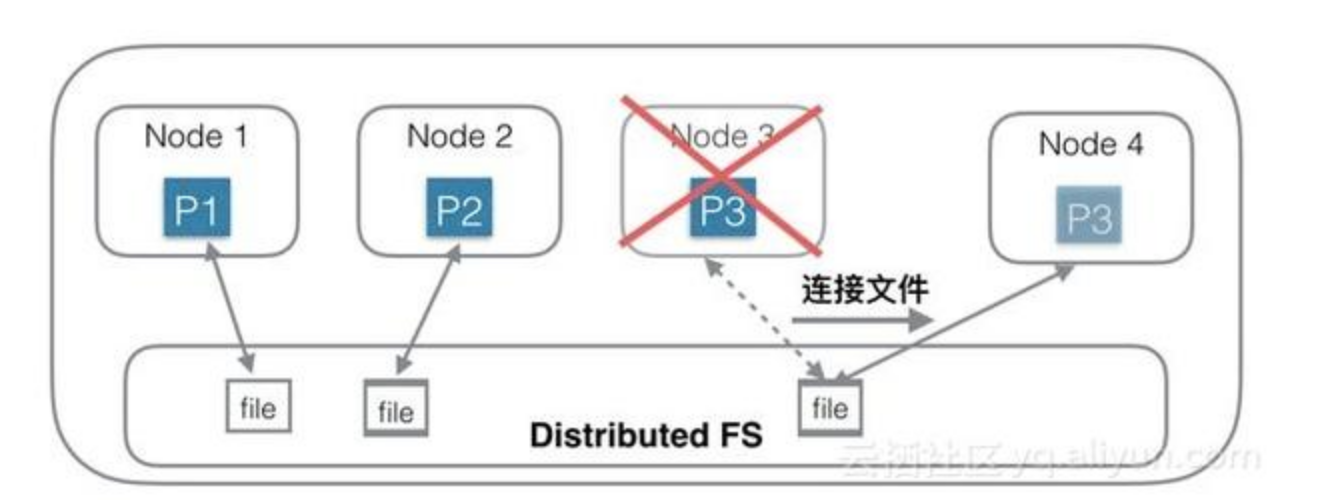
针对第一种架构中的问题,另一种思路是:存储和计算分离。
第一种思路的问题根源是数据量大,拷贝数据耗时多,那么有没有办法可以不拷贝数据?为了实现这个目的,一种思路是底层存储层使用共享存储,每个Shard只需要连接到一个分布式文件系统中的一个目录/文件即可,Shard中不含有数据,只含有计算部分。相当于每个Node中只负责计算部分,存储部分放在底层的另一个分布式文件系统中,比如HDFS。
上图中,Node 1 连接到第一个文件;Node 2连接到第二个文件;Node3连接到第三个文件。当Node 3机器宕机后,只需要在Node 4机器上新建一个空的Shard,然后构造一个新连接,连接到底层分布式文件系统的第三个文件即可,创建连接的速度是很快的,总耗时会非常短。
这种是一种典型的存储和计算分离的架构,优势有以下几个方面:
在这种架构下,资源可以更加弹性,当存储不够的时候只需要扩容存储系统的容量;当计算不够的时候,只需要扩容计算部分容量。
存储和计算是独立管理的,资源管理粒度更小,管理更加精细化,浪费更少,结果就是总体成本可以更低。
负载更加突出,抗热点能力更强。一般热点问题基本都出现在计算部分,对于存储和计算分离系统,计算部分由于没有绑定数据,可以实时的扩容、缩容和迁移,当出现热点的时候,可以第一时间将计算调度到新节点上。
这种架构同时也有一个不足:
访问分布式文件系统的性能可能不及访问本地文件系统。在上一代分布式文件系统中,这是一个比较明显的问题,但是目前使用了各种用户态协议栈后,这个差距已经越来越小了。
HBase使用的就是这种架构方式。
Solr也支持这种形式的架构。
总结
上述两种架构,各有优势和不足,对于某些架构中的不足或缺陷,思路不同,解决的方案也大相径庭,但是思路跨度越大,收益一般也越大。
上面只是介绍了分布式数据(存储/搜索/分析等等)系统在存储层的两种不同架构方式,希望能对大家有用。但是分布式系统架构设计所涉及的内容广,细节多,权衡点众,如果大家对某些领域或者方面有兴趣,也可以留言,后面再探讨。
参考文献:
从Elasticsearch来看分布式系统架构设计的更多相关文章
- dba和运维专家们说有丰富的大型分布式系统架构设计经验纯属扯淡
如果,一开始就从事dba和运维的专家们说他们有丰富的大型分布式系统架构设计经验,那纯属扯淡.除非,他们从是从开发专家或者架构师转型而来,那么他们才有资格说自己有丰富的大型分布式系统架构设计经验. 运维 ...
- 从MySQL高可用引出对高可用架构设计的一些思考
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间. 假设系统一直能够提供服务,我们说系统的可用性是100%.如果 ...
- 从mysql高可用架构看高可用架构设计
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间. 假设系统一直能够提供服务,我们说系统的可用性是100%.如果 ...
- Java生鲜电商平台-电商中海量搜索ElasticSearch架构设计实战与源码解析
Java生鲜电商平台-电商中海量搜索ElasticSearch架构设计实战与源码解析 生鲜电商搜索引擎的特点 众所周知,标准的搜索引擎主要分成三个大的部分,第一步是爬虫系统,第二步是数据分析,第三步才 ...
- 基于WCF大型分布式系统的架构设计
在大型系统中应用中,一个架构设计较好的应用系统,其总体功能肯定是由很多个功能模块所组成的,而每一个功能模块所需要的数据对应到数据库中就是一个或多个表.而在架构设计中,各个功能模块相互之间的交互点 越统 ...
- Medium开发团队谈架构设计_转
转自:Medium开发团队谈架构设计 背景 说到底,Medium是个社交网络,人们可以在这里分享有意思的故事和想法.据统计,目前累积的用户阅读时间已经超过14亿分钟,合两千六百年. 我们支持着每个月两 ...
- QingStor 对象存储架构设计及最佳实践
对象存储概念及特性 在介绍 QingStor️对象存储内部的的架构和设计原理之前,我们首先来了解一下对象存储的概念,也就是从外部视角看,对象存储有什么特性,我们应该如何使用. 对象存储本质上是一款存储 ...
- SOA架构设计经验分享—架构、职责、数据一致性
阅读目录: 1.背景介绍 2.SOA的架构层次 2.1.应用服务(原子服务) 2.2.组合服务 2.3.业务服务(编排服务) 3.SOA化的重构 3.1.保留服务空间,为了将来服务的组合 4.运用DD ...
- SOA架构设计(转发)
阅读目录: 1.背景介绍 2.SOA的架构层次 2.1.应用服务(原子服务) 2.2.组合服务 2.3.业务服务(编排服务) 3.SOA化的重构 3.1.保留服务空间,为了将来服务的组合 4.运用DD ...
随机推荐
- 【Javascript Demo】图片瀑布流实现
瀑布流就是像瀑布一样的网站——丰富的网站内容,特别是绚美的图片会让你流连忘返.你在浏览网站的时候只需要轻轻滑动一下鼠标滚轮,一切的美妙的图片精彩便可呈现在你面前.瀑布流网站是新兴的一种网站模式——她的 ...
- 解决IE6-IE8 Js代码不执行问题
一种可能的原因:form标签不完整. 使用在线工具,测试html代码标签的完整性.
- 【Zookeeper】源码分析之服务器(二)之ZooKeeperServer
一.前言 前面阐述了服务器的总体框架,下面来分析服务器的所有父类ZooKeeperServer. 二.ZooKeeperServer源码分析 2.1 类的继承关系 public class ZooKe ...
- python dash 初探 --- k 线国内版
python dash 的应用首页,是用一个 k 线图来做 damo 的,奈何数据源用的 Google,上不去.当然,可以换 yahoo,但是毕竟国内的还是更亲切些. 官方的 demo 用的 pand ...
- elasticsearch日志删除命令
通过curl发送DELETE命令给elasticsearch服务器,进行日志删除操作.命令示例如下: curl -XDELETE *' curl -XDELETE 'http://192.168.10 ...
- C#后台执行js
StringBuilder sb = new StringBuilder(); sb.Append("<script type='text/javascript'>") ...
- git+gitolite如何实现权限控制
前言 首先说明一下,这还是本人第一次写这类文章,如有不妥,多多见谅. 基本情况 因为现在公司的人不是很多,但是还对代码有着严格的管控,所以采用了gitolite的管理方式 其实正常来讲,这种权限的把控 ...
- java 对一个字符串进行加减乘除的运算
记录一个小程序,里面涉及到的JAVA知识点有:字符串扫描,list删除元素的方法,泛型的使用,JAVA中的/要注意的事项.有兴趣的可以看看 package com.demo; import java. ...
- 一篇文章让你读懂iOS和Android的历史起源
智能手机虽说是移动电话,但我们完全可以将其作为小型化的电脑来思考.这样一来也能够显示出智能手机OS的高性能.我们首先一起来回顾下智能手机OS的历史. OS的黎明期 其实在很早之前就已经有这样的想法,即 ...
- Django Web开发学习笔记(1)
一.Python的标准类型 (1)bool型 >>> bool("") False >>> bool(None) False >>& ...