oracle 11g AUTO_SAMPLE_SIZE动态采用工作机制
Note that if you're interested in learning about Oracle Database 12c, there's an updated version of this post here.
When it comes to gathering statistics, one of the most critical decisions you have to make is, what sample size should be used? A 100% sample will ensure accurate statistics but could take a really long time. Whereas a 1% sample will finish quickly but could result in poor statistics.
The ESTIMATE_PERCENT parameter in the DBMS_STATS.GATHER_*_STATS procedures controls the sample size used when gathering statistics and its default value is AUTO_SAMPLE_SIZE.
In an earlier blog post, we talked about the new implementation of AUTO_SAMPLE_SIZE in Oracle Database 11g in terms of its improvements in the speed and accuracy of statistics gathering compared to the old AUTO_SAMPLE_SIZE prior to Oracle Database 11g.
In this post, we will offer a closer look at the how the new AUTO_SAMPLE_SIZE algorithm works and how it affects the accuracy of the statistics being gathered.
Before we delve into how the new algorithm works, let us briefly recap how the old algorithm works and its downsides. The old AUTO_SAMPLE_SIZE used the following approach:
Step 1. Oracle starts with a small sampling percentage. If histograms need to be gathered, Oracle might materialize the sample, depending on the sampling percentage.
Step 2. Oracle gathers basic column statistics on the sample. For example, suppose a table T has only one column C1, then the basic stats gathering query looks like below (this is not the exact syntax we use but a simplified version for illustration purpose):
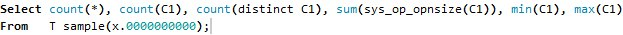
Query 1 Query Gathering Basic Column Statistics Using AUTO_SAMPLE_SIZE Prior to 11g
The select list items in the query correspond to number of rows in table T, number of non-null values, number of distinct values, total column length, minimal and maximal values of column C1respectively. “X.0000000000” in the FROM clause is the sampling percentage determined by Oracle.
Step 3: if histograms need to be gathered, Oracle issues a SQL query on the sample for each column that requires a histogram.
Step 4: For each column that requires a histogram, Oracle uses several metrics to determine whether the current sample is sufficient:
- Non-null value metric: Whether the sample contains sufficient non-null values of this column;
- NDV metric: Whether number of distinct values (NDV) can be properly scaled from the sample.
Step 5: If all metrics in step 4 pass, Oracle concludes that the current sample size is sufficient and the histogram creation for that column is complete. Otherwise, it bumps up the sample size and goes though the above steps again until it finds a satisfactory sample or reaches 100% sampling.
Note that step 3 to step 5 are done per column. For example, if there are 3 columns in the table that require histograms. In the first iteration, we get a sample and materialize it. We issue 3 queries, one per column, on the same materialized sample to gather histograms. Suppose Oracle determines that the sample is sufficient for columns 1 and 2 but insufficient for column 3. Then we bump up the sample size. In the second iteration, only 1 query is issued on the sample to gather histogram for column 3.
As you can see the old AUTO_SAMPLE_SIZE can be inefficient if several iterations are required. A dominating contributor for several iterations is the inability to gather accurate NDVs using a small sample. If there is a skew in the data, a lot of low frequency values may not make into the sample and thus the sample fails the NDV metric.
In Oracle Database 11g, we use a completely different approach for gathering basic column statistics. We issue the following query to gather basic column statistics (again this is a simplified version for illustration purpose).

You will notice in the new basic column statistics gathering query, no sampling clause is used. Instead we do a full table scan. Also, there is no more count(distinct C1) to gather NDV for C1. Instead, during the execution we inject a special statistics gathering row source to this query. The special gathering row source uses a one-pass, hash-based distinct algorithm to gather NDV. More information on how this algorithm works can be found in the paper, “efficient and scalable statistics gathering for large databases in Oracle 11g”. The algorithm requires a full scan of the data, uses a bounded amount of memory and yields a highly accurate NDV that is nearly identical to a 100 percent sampling (can be proven mathematically). The special statistics gathering row source also gathers the number of rows, number of nulls and average column length on the side. Since we do a full scan on the table, the number of rows, average column length, minimal and maximal values are 100% accurate.
AUTO_SAMPLE_SIZE also affects histogram gathering and index statistics gathering in the following ways.
Effect of auto sample size on histogram gathering
- With the new AUTO_SAMPLE_SIZE, histogram gathering is decoupled from basic column statistics gathering (they used to be gathered on the same sample). Therefore when determining whether we need to bump up the sample size, the new AUTO_SAMPLE_SIZE algorithm no longer performs the “NDV metric” check (see step 4 in above description) because we do not derive NDV from the sample. Sample size needs to be bumped up for a histogram only when the sample contains too many nulls or too few rows. This helps to reduce number of iterations of the histogram creation. More information on this can be found in this blog post.
- If the minimal (resp. maximal) value that appears in the sample used for gathering the histogram is not the minimal (resp. maximal) value gathered in basic statistics, we will modify the histogram so that the minmal (resp. maximal) value gathered in basic statistics now appears as the endpoint of the first (resp. last) bucket in the histogram.
Effect of auto sample size on index stats gathering
The new AUTO_SAMPLE_SIZE also affects how index statistics are gathered. The flow chart below shows how index statistics are gathered in 11g when AUTO_SAMPLE_SIZE is specified. Index statistics gathering are sampling based. It could potentially go through several iterations because either the sample contained too few blocks or the sample size was too small to properly gather number of distinct keys (NDKs). With the new AUTO_SAMPLE_SIZE algorithm, however, if the index is defined on a single column, or if the index is defined on multiple columns that correspond to a column group, then the NDV of the column or column group will be used as NDK of the index. The index statistics gathering query will NOT gather NDK in such cases. This helps to alleviate the need to bump up sample size for index statistics gathering.

Summary:
- New AUTO_SAMPLE_SIZE algorithm does a full table scan to gather basic column statistics
- NDV gathered by new AUTO_SAMPLE_SIZE has an accuracy close to 100% sampling
- Other basic column statistics, such as the number of nulls, average column length, minimal and maximal values have an accuracy equivalent to 100% sampling
- Both Histogram and index statistics gathering under new auto sample size algorithm still use sampling. But new auto sample size algorithm helps to alleviate the need to bump up sample size.
oracle 11g AUTO_SAMPLE_SIZE动态采用工作机制的更多相关文章
- oracle 12c AUTO_SAMPLE_SIZE动态采用工作机制
The ESTIMATE_PERCENT parameter in DBMS_STATS.GATHER_*_STATS procedures controls the percentage of ro ...
- 2014年2月5日 Oracle ORACLE的工作机制[转]
网上看到一篇描写ORACLE工作机制的文章,觉得很不错!特摘录了下来. ORACLE的工作机制-1 (by xyf_tck) 我们从一个用户请求开始讲,ORACLE的简要的工作机制是怎样的,首 ...
- Oracle 11g安装过程工作Oracle数据库安装图解
一.Oracle 下载 注意Oracle分成两个文件,下载完后,将两个文件解压到同一目录下即可. 路径名称中,最好不要出现中文,也不要出现空格等不规则字符. 官方下地址: oracle.com/tec ...
- Oracle 11g新特性
文章转自网络 Oracle 11g于2007年7月11日美国东部时间11时(北京时间11日22时)正式发布,11g是甲骨文公司30年来发布的最重要的数据库版本,根据用户的需求实现了信息生命周期管理(I ...
- Oracle 11g R2 RAC 高可用连接特性
转自-阿里巴巴许春值 1.scan概念 什么叫 SCAN,SCAN (Single Client Access Name) 是 Oracle 从11g R2 开始推出的,客户端可以通过 SCAN 特性 ...
- [转]Oracle 11g R2 RAC高可用连接特性 – SCAN详解
原文地址:http://czmmiao.iteye.com/blog/2124373 昨天帮朋友解决11g RAC SCAN问题,当时为这朋友简单解答了一些SCAN特性相关的问题,但我知道这仅仅是 ...
- RedHat 6.7 Enterprise x64环境下使用RHCS部署Oracle 11g R2双机双实例HA
环境 软硬件环境 硬件环境: 浪潮英信服务器NF570M3两台,华为OceanStor 18500存储一台,以太网交换机两台,光纤交换机两台. 软件环境: 操作系统:Redhat Enterpris ...
- RedHat 6.7 Enterprise x64环境下使用RHCS部署Oracle 11g R2双机HA
环境 软硬件环境 硬件环境: 浪潮英信服务器NF570M3两台,华为OceanStor 18500存储一台,以太网交换机两台,光纤交换机两台. 软件环境: 操作系统:Redhat Enterprise ...
- Oracle 11g RAC features
<一,> oracle 11g r2 RAC提供了以下功能: 高可用:shared-everything 模式保证了单节点的故障不会停止服务,集群中的其他节点将快速接管 可扩展性:多节点分 ...
随机推荐
- [LeetCode] 154. Find Minimum in Rotated Sorted Array II_Hard
Suppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand. (i.e. ...
- CentOS6.5 安装openssl
安装比较简单! 1.下载安装包 [root@mycentos ~]# wget http://www.openssl.org/source/openssl-1.0.2f.tar.gz 2.解压和编译 ...
- 配置opensips经验总结
主要参考https://www.cnblogs.com/Forever-Kenlen-Ja/p/7741776.html (ubuntu),还有https://blog.csdn.net/sunyun ...
- php 下载完成后删除文件
最近遇到一个需求:下载用户上传的图片,但是图片不断更新. 1.需要将图片从图片服务器下载到网站后台服务器 2.压缩文件夹生成zip压缩包 3.下载压缩包 4.删除压缩包和临时文件夹 其中遇到了一个问题 ...
- D Cloud of Hashtags Codeforces Round #401 (Div. 2)
Cloud of Hashtags [题目链接]Cloud of Hashtags &题意: 给你一个n,之后给出n个串,这些串的总长度不超过5e5,你要删除最少的单词(并且只能是后缀),使得 ...
- C# 如何批量修改集合元素的属性值?
我们往往会遇到要批量修改集合中元素的值,最笨的办法就是foreach循环,但本文介绍几种优雅的方法. 首先,我们准备好元素类和初始集合: 下面就是几种方法,目前并没有对性能做进一步的测试,有兴趣的童鞋 ...
- FutureTask demo
package com.xinwei.order.entity; import java.util.concurrent.ExecutorService; import java.util.concu ...
- java 控制台输入
import java . util . Scanner ; public class Test { public static void main(String[] args) { Scanner ...
- Java操作队列
Java操作队列 常见的几种模式: 1 简单队列simple 模型:(p + 队列 + c) P:生产者producer,将消息发送到队列 红色:消息队列 C:消费者consumer,从队列消费消 ...
- 17.Setters/getters
知道类的成员变量何时因某种原因发生变化通常很有用.也可能需要以某种方式封装其访问. 为此,GDScript使用 setget 关键字提供了一个 setter/getter 语法.在变量定义后可直接使用 ...