目标检测-yolo2
转载自:http://blog.csdn.net/qq_34784753/article/details/78825493
对于现在的最好的检测系统来说,yolo_v1 的问题主要出现在两方面,也就是:
(1)yolo_v1存在大量的定位错误;
(2)yolo_v1 的 召回率(recall) 比较低。
***科普时间***:
准确率(accuracy) :预测对的/所有 = (TP+TN)/(TP+FN+FP+TN)
精确率(precision):这个概念是针对预测结果而言的,表示的是预测结果中的正例中有多少本身就是正例,也就是真正例占所预测正例的比例。
公式:TP/(TP+FP)
召回率(recall):这个概念是针对原来样本而言的,表示样本中的正例有多少被正确的预测了。也就是真正例中被预测正确的样本所占的比例。
公式:TP/(TP+FN)
TP(True Positive):正类预测为正类
FP(False Positive):负类预测为正类
FN(True Negative):正类预测为负类
TN(False Negative):负类预测为负类
对于yolo_v1存在的两个问题,作者并没有过分的增加网络复杂度或者是结合几种不同的方法(bagging),因为这样会影响检测的实时性,作者主要是从下面这几个方法来改进网络的:
(1)Batch Normalization
(2)High Resulution Classifier
(3)Convolutional With Anchor Boxes
(4)Dimension Clusters
(5)Direct location prediction
(6)Fine-Grained Features
1、准确率改进
1.1 Batch Normalization
Batch Normalization 是 Google 在2014 提出的一种对数据进行处理的方法,论文提出了为了避免 covariate shift 现象的发生,对所有输入网络的数据都首先进行一次 BN 处理,具体算法可以参考论文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift。这里给出算法流程图:

BN 的原理就是对所有输入到网络的数据做一个归一化处理。在 yolo_v2 中,作者在每一个卷积层的前面都附加一个 BN 层,加入BN 层后,不但将检测的 mAP 提升了 2%,同时,也对整个网络起到了正则化的作用。并且在加入了 BN 层后,全连接层后的 dropout 层也可以去掉,因此说明 BN 层还起到了改善网络过拟合的作用。
1.2 High Resulution Classifier
作者在论文中提到,目前最好的图像分类器都是采用基于 ImageNet 数据集的。以 AlexNet 开始的分类网络的输入大多都小于 256*256。在原始 yolo 中网络一开始使用 224*224 大小的图像进行分类任务的训练然后使用 448*448 大小的图像作为检测任务的输入。而这种方式进行训练也就意味着网络必须同时切换到学习对象检测并调整到新的输入分辨率。
在 yolo_v2 中,首先,我们在开始的 10 epoches 上进行微调来适应 448*448 大小的分辨率,这给了网络时间来调整其滤波器以更好地处理更高分辨率的输入。然后我们对得到的网络在检测任务上进行微调。
最后的结果表明,使用这样的网络进行分类预训练是我们得到的检测任务的 mAP 提升了将近 4%。
1.3 Convolutional With Anchor Boxes
在 yolo_v1 中,预测 bounding boxes 采用的是直接使用卷积层后的全连接层直接预测坐标和置信度等信息(需要将 1470*1 的全连接层 reshape 成为 7*7*30 的最终特征)。而我们之前介绍过的 Faster R-CNN 中,采用的是人手工选择的 bounding boxes,yolo_v2 中也正是借鉴了这种思想其 anchor boxes 的主要思想是:
在最后的卷积特征图上进行滑窗采样,每个中心预测 9 种大小不同和比例的建议框。由于都是卷积操作,因此并不需要再进行一次 reshape,因此这种方法能够很好地保留原图像的空间位置信息,通过简单计算能够得到在特征图上每一个位置都能对应在原图上。而且使用相对偏移(offset)取代直接预测坐标简化了直接预测坐标位置的问题。
在 yolo_v2 中,我们将 yolo_v1 中的全连接层去掉而使用 anchor boxes 机制来预测 bounding boxes 的位置信息,具体如下所示:
- 首先去掉在最后的卷积层后的池化层,目的是为了是卷积网络输出的特征具有更高的分辨率。
- 对网络的输入进行缩减,让输入图片的分辨率从 448*448 缩减到 416*416,目的是使得最后得到的 feature map 的 size 是一个奇数。而奇数的 feature map,能够产生一个单独的 center cell。这样做的原因是因为作者发现,特别是对于大目标来说,他们通常占据了图像的中间位置。而可以只用一个中心的 cell 来预测这些物体的位置,而如果是偶数,就需要使用中心的四个 cell 进行预测。取到奇数可以提升一定的效率。
- yolo_v1 网络最后输出的 feature map (不含最后一个池化)下采样率为 32,因此最终得到的 feature map 大小为 13*13。(416*416 输入)。
- 使用 anchor boxes 机制以后,我们将预测空间位置与预测类别两个任务分开进行,由 anchor boxes 同时预测类别以及坐标。因为 yolo_v1 是使用每个 cell 来预测类别,每个 cell 对应的 bounding boxes 来预测位置信息。在 yolo_v2 中,作者不在令类别的预测和每个 cell 绑定在一起,而是将这些任务全部放在 anchor boxes 中。
示意图如下所示:图来自YOLO2
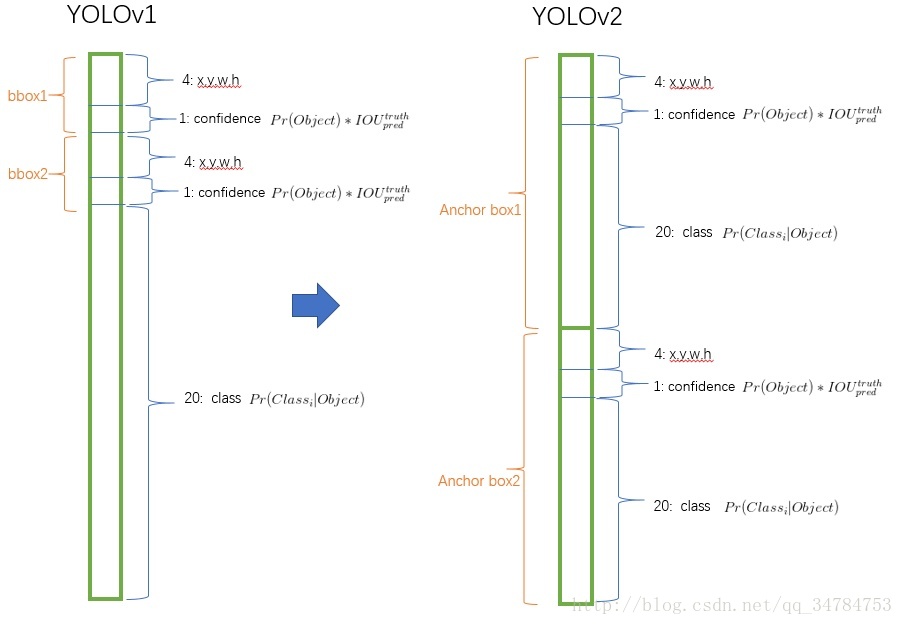
最终的实验结果表明,在使用了 anchor boxes 机制以后,网络在精确率方面有了细微的下降(69.5 -> 69.2),但是在召回率(Recall) 却有了很大的提升(81% -> 88%)。虽然在准确率方面有了略微的下降,但是召回率的提升说明了模型还有更多的改进的空间。
原因:在 yolo_v1 中,我们将 feature map 分为 7*7 个 cells,那么对于 13*13 大小的 feature map 来说,会得到 7*7*2 = 98 个 bounding boxes,在 yolo_v2 中,如果 feature map 上每个 点 也对应 2 个不同的 bounding boxes,则一共有 13*13*2 = 338 个bounding boxes。因此会以更大的概率覆盖原始的 ground-truth。更何况 yolo_v2 在实验中常取 3或者 5个 anchor boxes。
1.4 Dimension Clusters
在 yolo_v2 中使用 Faster R-CNN 中提出的 anchor boxes 机制时,作者发现会遇到两个问题,其中第一个问题就是:
- 在Faster R-CNN 中 anchor boxes 的 尺度(dimension) 是手工选取的(hand-picked priors)(经验值?)
因此虽然网络可以自已调整bounding boxes 的位置,但是如果我们在一开始就使用一些比较好的 anchor boxes,那么网络就应该更容易预测准确的位置。
而作者提出的解决方案,就是利用统计学习中的 k-means 聚类方法,通过对数据集中的 ground truth box 做聚类分析,以此来找到 ground truth box 的统计上的规律。
在这里 k-means 中的 k 表示最终要取得的 anchor boxes 的数量。以 k 个聚类中心 box 的宽高维度也就是 anchor box 的维度。
K-means算法可以参考:算法杂货铺——k均值聚类(K-means)
从D中随机取k个元素,作为k个簇的各自的中心。
分别计算剩下的元素到k个簇中心的相异度,将这些元素分别划归到相异度最低的簇。 根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数。 将D中全部元素按照新的中心重新聚类。 重复第4步,直到聚类结果不再变化。 将结果输出。
上面提到的相异度也就是我们常说的距离,在这里我们可以根据问题的不同选用不同的距离进行度量。通常使用的距离是欧氏距离。
在 yolo_v2 中,作者用的并不是欧式距离,因为作者想用一个 IOU 与所使用 anchor box 的 size 无关的距离值,也就是说,使用欧氏距离函数会使得大的 anchor boxes 比小 anchor boxes 产生更多的 error(误差),因此作者最终选用如下的距离度量:
聚类的结果如下图所示:
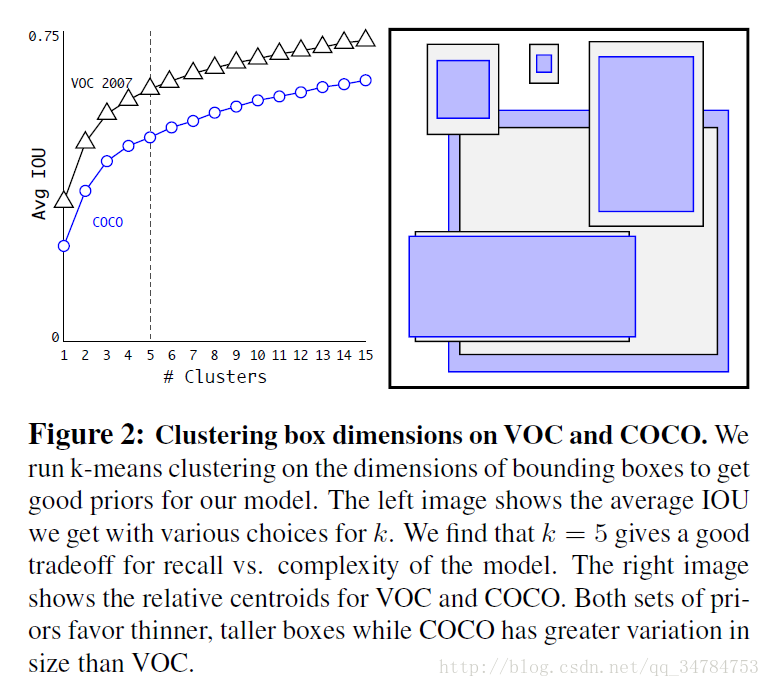
上图中作图说明,随着 k 值得增大,平均 IOU 也在相应的增大,我们发现在 k=5 时可以平衡模型的召回率和复杂度。右图显示的是 k = 5 的聚类结果(对于 VOC 和 COCO 数据集)。我们可以看到这两个数据集都更倾向于“瘦高”的 bounding boxes,而且 COCO 数据集 bounding boxes 的size 变化要比 VOC 数据集变化大。 作者在之后做了对比试验说明了采用这种 k-means 方法取代手动选取。
1.5 Direct location prediction
在 yolo_v2 中使用 anchor boxes 机制的第二个问题就是:
- 模型的不稳定性,尤其是在早期迭代的时候
并且作者也同时说明,这种不稳定性主要是发生在预测 box 的 (x, y) 坐标的时候。
在 RPN 网络中,网络预测 tx,ty 以及中心点坐标 (x,y)的公式如下所示:
需要说明的一点是,在原文中,公式里是 −xa 以及 −ya 但由 RPN 网络bounding boxes 的计算公式可以知道,这里应该是 +。
下面给出 Faster-R-CNN 中的坐标计算公式:

因此,由上面公式可以知道,当 tx=1 的时候会将 box 向右移动 anchor box 的宽度,预测tx=−1的时候会将 box向左移动anchor box 的宽度。
可以看到,在 RPN 网络中这个公式并没有任何条件限制,也就是说,任何 anchor box 都可以在图像中的任何一点上结束,而不管盒子在什么位置预测。因此随机初始化模型需要很长时间才能稳定以预测合理的偏移量。
因此,作者没有预测偏移量,而是按照YOLO的方法预测相对于网格单元位置的位置坐标。也就是说,网络预测的是 相对于 cell 的坐标位置。这就使得 ground truth 的值落在了 0 到 1 之间,而我们使用 logistic 激活函数来使得网络的预测自也落在 0 到 1 之间。
因此,网络在特征图的每个 cell 上预测 5 个bounding boxes (聚类得到的值)。同时每一个 bounding boxes 预测 5 个值,也就是 tx, ty, tw, th, to。其中前四个是坐标值,最后一个是置信度。如果这个 cell 距离图像左上角的边距为 (cx,cy),以及该 cell 对应的 box 对应的 box 维度(bounding box prior) 的长和宽分别为??,那么对应的box为:
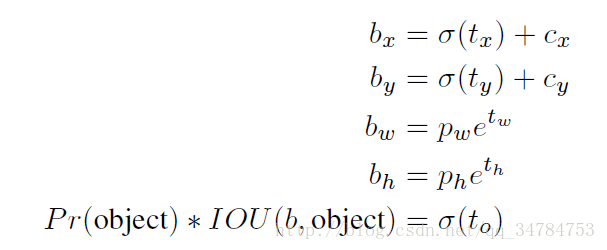
可以看到,tx 和 ty 经过了 sgmoid 的处理之后,落在了 0 到 1 之间,实际意义就是使得 anchor 只负责周围的 box,这样有利于提升效率以及网络的收敛。
在进行了预测值归一化以后,我们可以看到,参数就更容易得到学习,因此模型也就更加稳定。作者最后提出,在特征图上进行 Dimension Cluster 和 Direct location prediction 这两项 anchor boxes 改进方法,mAP 获得了 5% 的提升。
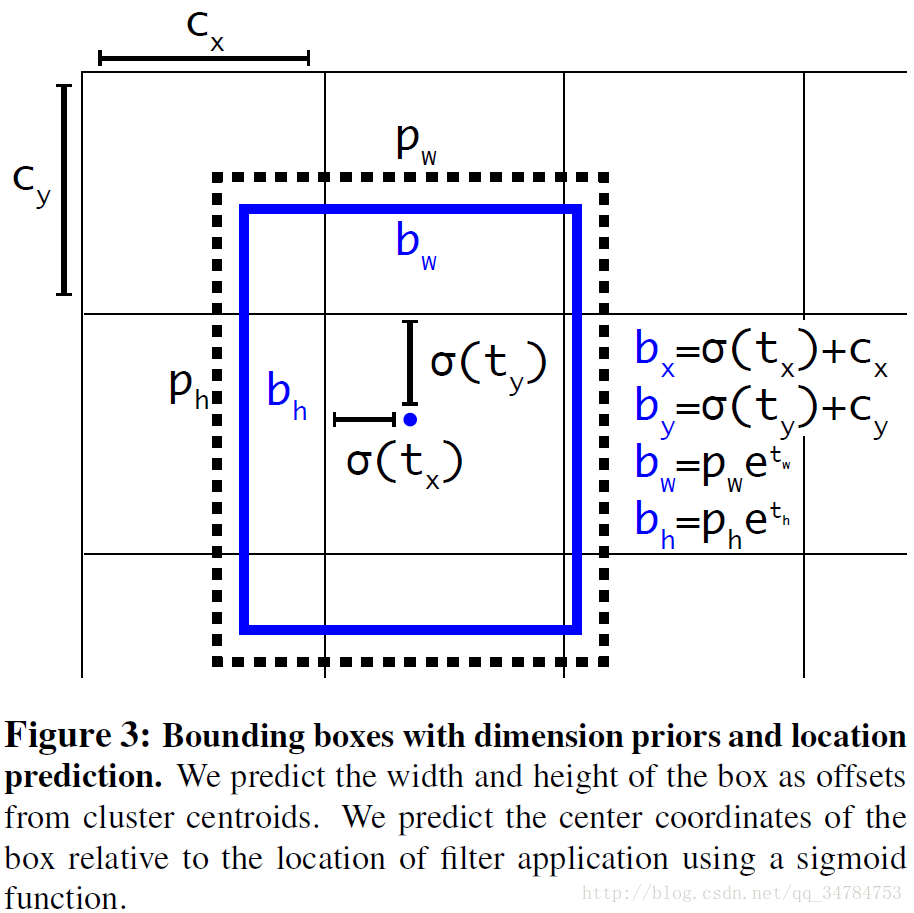
上图是说,我们预测 bounding box的宽度和高度是从每个聚类中心的偏移量。 我们使用sigmoid函数预测相对于中心坐标的位置。
1.6 Fine-Grained Features(细粒度特征)
yolo_v2 中网络是在 13*13 的特征图上进行预测检测的,这对于大目标是足够的,但是对于小粒度特征来说,再利用上细粒度特征对它的检测应该有帮助。Faster R-CNN 和 SSD 都在不同层次的特征图上产生 region proposal 以来获得多尺度的适应性。yolo_v2 采用的是另一种不同的方法,是简单添加一个 passthrough layer,这样可以直接将浅层的特征图(分辨率为 26*26) 连接到深层特征图(分辨率 13*13)。
这种连接方式将高低两种分辨率得到特征图做链接,叠加相邻特征到不同的通道(而非是空间位置)。可以看到,这种方法类似于 ResNet 的“快捷连接”,利用这个方法,作者将 26 * 26 * 512 的feature map 变为 13*13*2048 的 feature map,然后和原来的深层特征图相连。
1.7 Multi-Scale Training(多尺度训练)
在原始的 yolo_v1 中,检测任务中使用 448*448 大小的图像作为输入。而在加入了 anchor boxes 机制以后,作者将输入图像的尺寸调整到了 416*416。但需要注意的是,因为我们的模型仅仅使用了卷积层和池化层,因此可以随时改变模型的输入尺寸。
为了使网络能够适应多尺度的目标检测任务,作者采用了一种 “多尺度训练的方法”,主要流程为每隔几轮(10 batches)就改变模型输入尺寸。这样能够使得网络对不同尺度的图像具有良好的鲁棒性。因为所采用的的模型下采样率为 32,因此这里选用的多尺度均为 32 的倍数,分别为:{320,352,…,608}。改变模型输入尺寸后,继续对模型进行训练。
这种训练机制迫使网络学习如何在各种输入维度上做好预测。 这意味着相同的网络可以预测不同分辨率下的检测结果。因为 yolo_v2 模型在小尺度输入上运行速度很快,因此,yolo_v2 提供了一种在速度和准确性两者之间进行权衡的方案。
此外,作者还进一步说明, yolo_v2 在小分辨率图像的检测上,能够保持和 Fast R-CNN 持平的准确率的情况下,处理速度能够达到 90fps。在高分辨率下,yolo_v2 在 voc2007 数据集上能够达到 state of the art(78.6mAP),具体实验结果如下图所示:
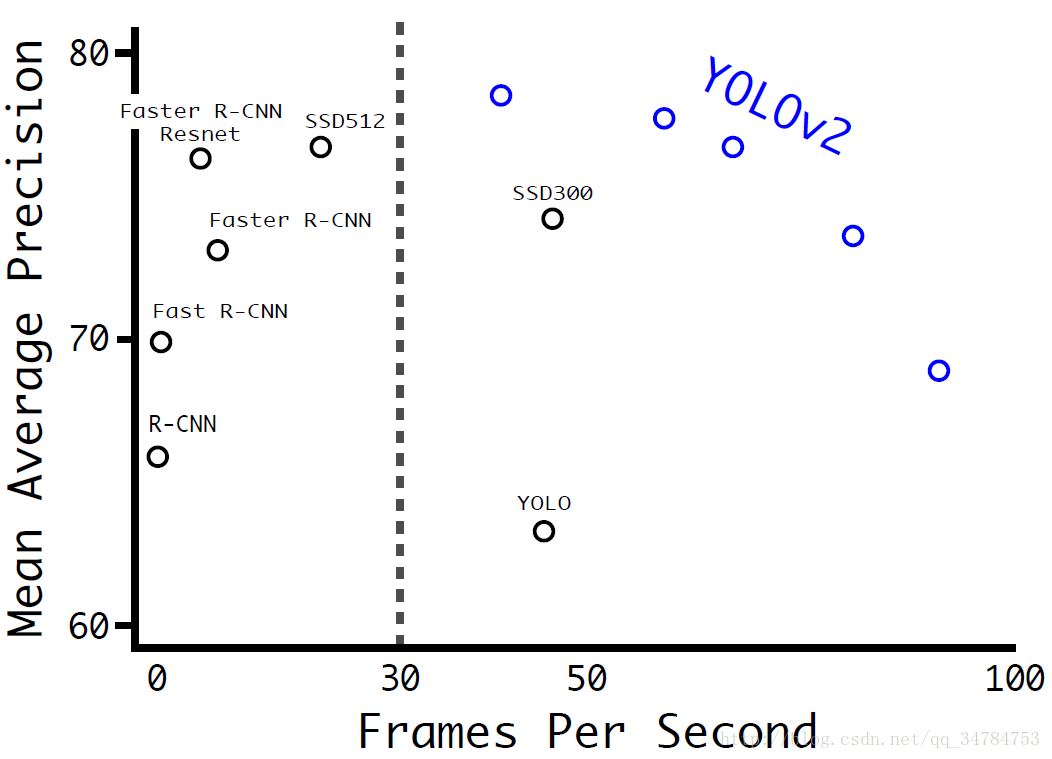
2、速率改进
2.1 Darknet-19
为了进一步提升网络速度以及检测效果,作者提出了一种新的分类网络模型作为 yolo_v2 的基础。与 VGG 相似的是这个框架中使用了大量的 3*3 小尺度卷积用来提取特征,并且用到了 NIN 中的使用 1*1 卷积压缩feature map 以及全局平均池化技术。此外还是用了 BN 层用来稳定训练过程以及加速收敛和对模型的正则化。
最后将构建的网络框架称为“Darknet-19”,网络中一共有 19 个卷积层以及 5 个池化层,网络的具体构成如下所示:
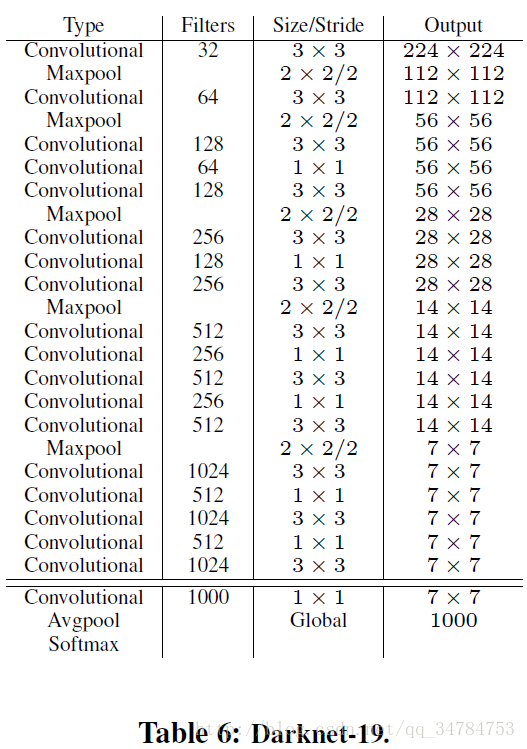
2.2 Training for classification
作者使用 Darknet-19 在标准 ImageNet 的 1000 类数据集上训练了 160 epochs,使用随机梯度下降算法,初始学习速率为 0.1,指数为 4 的多项式衰减,weight decay 为 0.0005,momentum 系数为 0.9。在训练中,我们使用标准的数据增强方法,包括随机剪裁,旋转以及 色度,饱和度 和 亮度(exposure)的变换。
正如之前所讨论的,在初始的 224*244 训练后 将分辨率上升到 448*448,并使用相同的参数又训练了 10 次,将学习率调整到 10−3。在高分辨率下训练的分类网络 top-1 准确率为 76.5%,top-5 准确率为 93.3%。
2.3 Training for detection
为了适应检测任务,作者将上面的分类用的网络进行了部分修改,包括去掉原网络中的最后一个卷积层,然后增加了 3*3*1024 的卷积层,并且在每一个卷积层后都跟着一个 1*1 的卷积,最后输出的维度数是检测所需要的数量。
对于 VOC 数据集来说,网络最后预测 5 个 boxes 并且每个 boxes 有 5个 坐标值和 20 个分类值。因此一共有 125 (5*(20+5)) 个滤波输出维度。示意图如下所示,图像来自于:YOLO2
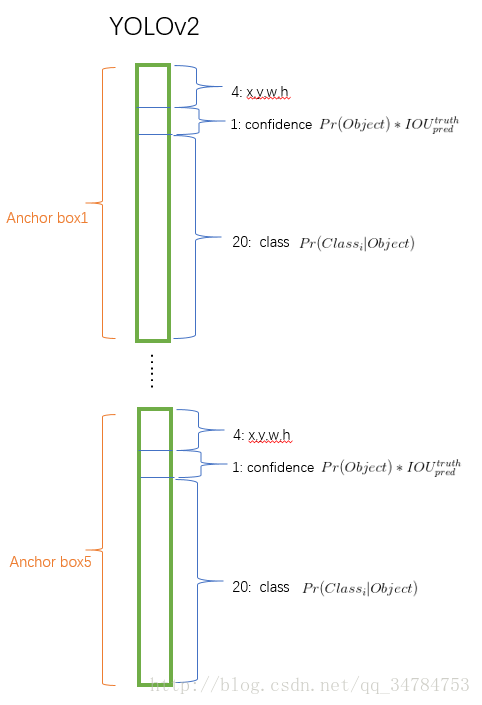
同时,在网络中也添加了 passthrough layer 进行快捷连接用来获得低层次的 feature map,是从 最后的 3*3*512 的卷积层连接到 倒数第二层,从而获得细粒度特征。
对于检测任务,网络一共训练了 160 epochs,初始学习速率为 0.001,并且在第 60 和 第 90 次学习率都 衰减为原来的十分之一。weight decay 参数为0.0005,momentum 系数为 0.9。数据增强的方案类似于 SDD 和 Faster-R-CNN 中所使用的,包括随机剪裁,颜色变换等等。并且使用相同的策略在 COCO 和 VOC 数据集上进行训练。
3、yolo9000
作者提出了一种利用分类和检测数据进行联合训练网络的机制。其方法是使用标记为检测的图像来学习像边界框坐标预测和对常见目标进行分类。而使用仅仅标记为分类的图像用来扩充网络能够检测的数据集。
在训练过程中我们将分类数据集和检测数据集进行混合。当我们的网络接受目标检测的训练数据时,反馈网络采用的是 yolo_v2 的完整 loss function,当网络接受的是分类任务的训练数据时,反馈网络只对分类任务相关的 loss function 进行更新。
这种训练方法会带来一定的困难,因为检测数据集通常只包含常见的目标以及通用 labels,像“dog”,“boat”之类。分类数据集具有更“宽”更“深”的 labels。ImageNet 数据集有 100 多种狗的分类,包括“Norfolk terrier”,“Yorkshire terrier”以及“Bedlington terrier” 等。如果想要在这两种数据集上进行联合训练,需要寻找一种连贯(coherent) 的方式来合并这些标签。
大所属分类问题都使用一个 softmax 层来对输出类别进行预测,通过产生所有种类的概率分布。但是使用 softmax 是假设了所有类别都是互不相关的。而这对于联合数据集来说却带了一定的问题。因为当我们联合 ImageNet 和 COCO 数据集的时候,“Norfolk terrier”和“dog”这两个分类并不是互不相关的。
对于上面的问题,作者提出了一种“多标签模型”(multi-label model)来将这个不同的数据集联合到一起,并且这种模型并没有假设 label 之间是 互不相关的。
3.1 Hierarchical classification(层次分类)
ImageNet 的数据标签来源于 WordNet,这是一个具有一定层级结构的“词典”。例如,在 WordNet 中,“Norfolk terrier”和“Yorkshire terrier”都是 “terier”的下义词(hyponyms),而“terrier”又是 “hunting dog”的下义词,“hunting dog”又是“dog”的下义词,而“dog”则是“canine”的下义词。大多数分类任务都假设 label 的数据结构的 flat (扁平?)的,然而对于联合的数据集来说,上面这种分层次的结构才是我们所需要的。
需要说明的是, WordNet 实际上是一个有向图结构。但是为了使用简单,我们并没有使用全图结构,而是根据 ImageNet 的labels 简单的建立了一个分层树(hierarchical tree)。
为了建立这颗分层树,我们需要遍历 ImageNet 数据集中的每一个名词,以此来找到它们通向 WordNet 的根节点(physical object)的路径。有许多词只有一条路径通向根节点,我们首先将这些路径添加到我么你的树种,然后我们迭代的检查我们剩下的词的路径然后添加路径最短的那一条到我们的树种。因此如果一个词有两条路径通向根节点并且路径长度分别是 1 和 3,那么我们就将长度为 1 的路径添加到我们的分层树种。
因此最后得到的就是一颗 WordTree,一个关于 labels 的分层模型。为了完成分类任务,我们在这个 WordTree 上的每一个节点上都预测一个它关于它下语义的条件概率。例如,在“terrier”节点时,如下所示:

如果想要计算特定节点的绝对概率值,只需要简单的顺着节点通向根节点的路径并将所有的条件概率相乘即可。例如如果我们想要知道一幅图像是 “Norfolk terrier”的概率,只需要如下计算:

为了能够计算,这里我们定义根节点的概率为1。
为了验证这种方法我们在基于 ImageNet 的 1000 类上建立的 WordTree 上进行训练。为了建立这个 WordTree1k 我们添加了一些中间结点让最后的 label space 从 1000 扩展到了 1369。在训练过程中,我们将真实标签沿着树向上传播,因此如果一个图像被标记为“Norfolk terrier”,它同样被标记为“dog”以及“mammal”等。为了计算相应的概率值,我们的模型上预测了一个具有 1369 个值得向量。并且计算了所有具有相同概念的下语义所有系统集的 softmax。具体如下图所示:
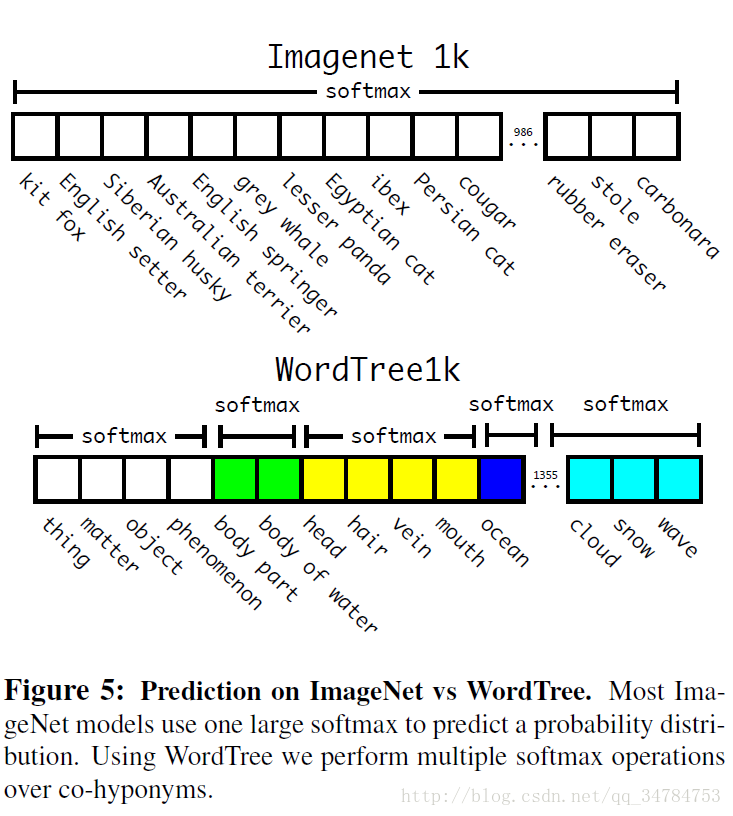
我们使用和之前相同的训练参数,我们的 分层的 Darknet 达到了 71.9% 的top-1 准确率以及 90.4%的 top-5 准确率。尽管额外添加了 369 个节点,但是这种模型预测的准确率并没有怎么下降。而且这种方式对于分类任务也有提升,但是对于未知的目标类别的性能表现通常不是很好。例如这个网络如果看到一张图片是“dog”但是并不确定是哪一种狗,网络还是会以很高的置信度预测是“dog”,但是至于“dog”的下义词的置信度却都比较低。
这种机制同样适用于检测任务。 此时不再假设每张图像中仅有一个 目标,作者使用 yolo_v2 目标预测器来给出存在物体的概率——Pr(physical object)。检测器预测出一个 bounding box 以及这棵树的各个节点的概率。我们遍历树,在每个分割中采用最高的置信度路径,直到达到某个阈值,然后我们预测对象类。
3.2 Dataset combination with WordTree
可以使用WordTree以合理的方式将多个数据集组合在一起。 只需将数据集中的类别映射到树中的同义词 (synsets) 即可。下图给出的是利用 WordTree 将ImageNet 和 COCO 数据集结合在一起,事实证明,我们可以利用这项技术应用于大多数数据集。
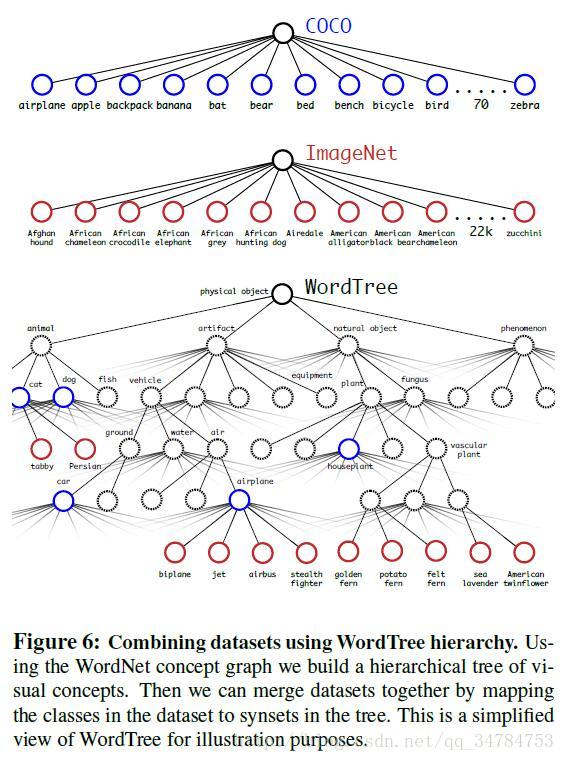
3.3 Joint classification and detection
现在我们可以使用WordTree组合数据集,我们可以训练联合模型的分类和检测。 我们想要训练一个非常大规模的探测器,所以我们使用COCO探测数据集和完整的ImageNet版本中的前9000个类创建我们的组合数据集。我们还需要评估我们的方法,以便从ImageNet检测挑战中添加任何尚未包含的类。 该数据集的相应WordTree有9418个类。 ImageNet是一个更大的数据集,所以我们通过对COCO进行过采样来平衡数据集,使得ImageNet仅仅以4:1的比例增大。
使用这个数据集来训练YOLO9000。 我们使用基础的YOLOv2体系结构,但是在聚类的时候 K 只取 3 而非 5 以此用来限制输出的尺寸。当我们的网络看到一个检测图像时,我们反向传播是 yolo_v2 的全部损失。对于分类损失,我们只是将损失反向传播到标签的相应水平或以上。 例如,如果标签是“dog”,我们不会在树中的“German Shepherd”与“Golden Retriever”中进一步分析任何错误,因为我们没有这些信息。
当设计的网络看到一张分类的图片时,它只会反向传播分类损失, 要做到这一点,作者提出只需找到预测该类别最高概率的边界框,然后计算其预测树上的损失。 此外作者还假定预测的框至少重叠了 ground truth 的 IOU >0.3,并且基于这个假设反向传播对象损失。
使用这种联合训练,YOLO9000学习使用COCO 中的检测数据来查找图像中的对象,并学习使用来自ImageNet的数据对各种这些对象进行分类。
作者在 ImageNet 检测任务上评估YOLO9000。 用 COCO 对 ImageNet 共享44个对象类别的检测任务,这意味着 YOLO9000 只能看到大多数测试图像的分类数据,而不是检测数据。YOLO9000 在不相交的156个对象类中分别获得了 19.7 mAP,16.0 mAP 并且从未见过任何标记的检测数据。这个 mAP 高于 DPM 的结果,但是 YOLO9000 只是在不同的数据集上训练,只有部分监督。它也同时检测 9000 个其他对象类别,所有这些都是实时的。
最后,作者提出在分析YOLO9000在 ImageNet 上的表现时,发现它能够很好地学习新的动物种类,但是却在像服装和设备这样的学习类别中表现不佳。新动物比较容易学习,因为 COCO 中的动物可以很好地概括物体的预测。 相反,COCO 没有任何类型的衣服的边框标签,只适用于人,所以YOLO9000很难模仿“太阳镜”或“泳裤”等类别。
目标检测-yolo2的更多相关文章
- YOLO2:实时目标检测视频教程,视频演示, Android Demo ,开源教学项目,论文。
实时目标检测和分类 GIF 图: 视频截图: 论文: https://arxiv.org/pdf/1506.02640.pdf https://arxiv.org/pdf/1612.08242.pdf ...
- 机器学习框架ML.NET学习笔记【8】目标检测(采用YOLO2模型)
一.概述 本篇文章介绍通过YOLO模型进行目标识别的应用,原始代码来源于:https://github.com/dotnet/machinelearning-samples 实现的功能是输入一张图片, ...
- 深度学习笔记之目标检测算法系列(包括RCNN、Fast RCNN、Faster RCNN和SSD)
不多说,直接上干货! 本文一系列目标检测算法:RCNN, Fast RCNN, Faster RCNN代表当下目标检测的前沿水平,在github都给出了基于Caffe的源码. • RCNN RCN ...
- 【目标检测】YOLO:
PPT 可以说是讲得相当之清楚了... deepsystems.io 中文翻译: https://zhuanlan.zhihu.com/p/24916786 图解YOLO YOLO核心思想:从R-CN ...
- 目标检测方法——SSD
SSD论文阅读(Wei Liu--[ECCV2016]SSD Single Shot MultiBox Detector) 目录 作者及相关链接 文章的选择原因 方法概括 方法细节 相关背景补充 实验 ...
- 目标检测方法总结(R-CNN系列)
目标检测方法系列--R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD 目录 相关背景 从传统方法到R-CNN 从R-CNN到SPP Fast R-CNN ...
- #Deep Learning回顾#之基于深度学习的目标检测(阅读小结)
原文链接:https://www.52ml.net/20287.html 这篇博文主要讲了深度学习在目标检测中的发展. 博文首先介绍了传统的目标检测算法过程: 传统的目标检测一般使用滑动窗口的框架,主 ...
- 目标检测的图像特征提取之(一)HOG特征(转载)
目标检测的图像特征提取之(一)HOG特征 zouxy09@qq.com http://blog.csdn.net/zouxy09 1.HOG特征: 方向梯度直方图(Histogram of Orien ...
- (转) 技术揭秘:海康威视PASCAL VOC2012目标检测权威评测夺冠之道
技术揭秘:海康威视PASCAL VOC2012目标检测权威评测夺冠之道 原创 2016-09-21 钟巧勇 深度学习大讲堂 点击上方“深度学习大讲堂”可订阅哦!深度学习大讲堂是高质量原创内容平台,邀请 ...
随机推荐
- go 基础(二)
strings和strconv使用 1.strings使用 strings.HasPrefix(s string, prefix string) bool:判断字符串s是否以prefix开头. str ...
- 修改Linux Operating System的时间与时区
修改Linux Operating System的时间与时区 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 有的小伙伴可能会遇到安装了linux系统后,尽管时区选择正确,也会发现系 ...
- Ansible拷贝文件遇到的问题
ansible报错Aborting, target uses selinux but python bindings (libselinux-python) aren't installed 报错内容 ...
- centos7下安装nginx的方法
没有用tar包的方法,太麻烦,还需要找,还需要编译,还需要下乱七八糟的依赖模块.麻烦的一逼,看网上说的.就采用了在线安装的方法.很快.注意一下,这种方法安装是安装到系统默认的位置.我也不知道怎么换.留 ...
- sublime js头部代码多行注释
安装 DocBlockr 插件,在写完function()的时候,在函数上面输入: /** + tab键(或回车键,Atom里不用另外安装插件,直接在函数的上面输入:/** + 回车键 即可).
- Tomcat 或JBOSS java.lang.ArrayIndexOutOfBoundsException: 8192 解决方案【转】
错误信息: 2017-1-17 10:09:39 org.apache.catalina.core.StandardWrapperValve invoke 严重: Servlet.service() ...
- Git fetch & pull
转:https://blog.csdn.net/qq_36113598/article/details/78906882 1.简单概括 先用一张图来理一下git fetch和git pull的概念: ...
- Error: failed to execute 'C:\Keil\ARM\ARMCC'的解决办法
在KEIL新建工程时,容易出现该问题,我查了一些资料,最终找到该问题解决方法: 第一步:在keil里的菜单栏依次选择Project->Manage->Components,Environm ...
- js设置按钮不可用
<input type="button" value="确定" id="stamp" onclick="stampBill( ...
- POJ3694 Network【连通分量+LCA】
题意: 一个无向图可以有重边,下面q个操作,每次在两个点间连接一条有向边,每次连接后整个无向图还剩下多少桥(注意是要考虑之前连了的边,每次回答是在上一次的基础之上). 思路: 首先运行一次Tarjan ...