O_DIRECT与O_SYNC区别(转)
O_DIRECT和O_SYNC是系统调用open的flag参数。通过指定open的flag参数,以特定的文件描述符打开某一文件。
这两个flag会对写盘的性能有很大的影响,因此对这两个flag做一些详细的了解。
先看一个open函数的使用例子.
/* Open new or existing file for reading and wrting,
sync io and no buffer io; file permissions read+
write for owner, nothing for all others */
fd = open("myfile", O_RDWR | O_CREAT | O_SYNC | O_DIRECT, S_IRUSR | S_IWUSR);
if (fd == -)
errExit("open");
一,O_DIRECT,绕过缓冲区高速缓存,直接IO
- 用于传递数据的缓冲区,其内存边界必须对齐为块大小的整数倍
- 数据传输的开始点,即文件和设备的偏移量,必须是块大小的整数倍
- 待传递数据的长度必须是块大小的整数倍。
不遵守上述任一限制均将导致EINVAL错误。
二,O_SYNC,以同步方式写入文件
功能:强制刷新内核缓冲区到输出文件。这是有必要的,因为为了数据安全,需要确保将数据真正写入磁盘或者磁盘的硬件告诉缓存中。
我们先熟悉一下同步IO相关定义和系统调用。
同步IO数据完整性和同步IO文件完整性
- synchronized IO data integrity completion:确保针对文件的一次更新传递了足够的信息(部分文件元数据)到磁盘,以便于之后对数据的获取。
- synchronized IO file integrity completion:确保针对文件的一次更新传递了所有的信息(所有文件元数据)到磁盘,即使有些在后续对文件数据的操作并不需要。
用于控制文件IO内核缓冲的系统调用
1 fsync
#include
int fsync(int fd);
- 0: success
- -1: error
#include
int fdatasync(int fd);
- 0: success
- -1: error
#include
void sync(void);
fd = open(pathname, O_WRONLY | O_SYNC)
作用:调用open后,每个write调用会自动将文件数据和元数据刷新到磁盘上,即按照Synchronized IO file integrity completion的要求执行写操作。
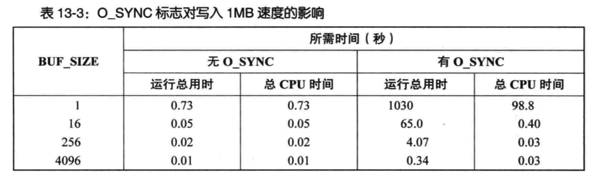
- 采用O_SYNC标志(或者频繁调用fsync(), fdatasync()或sync())对性能影响极大。
- 性能下降的直接表现为运行总用时大为增加:在缓冲区为1字节的情况下,运行时间相差1000多倍。
- 以O_SYNC标志执行写操作时运行总用时和CPU时间之间的巨大差异(1030 - 98.8),原因是系统在每个缓冲区中将数据向磁盘传递时会把程序阻塞起来。
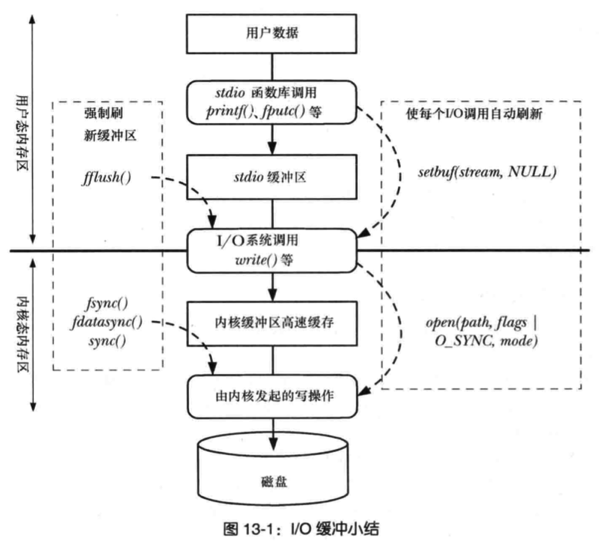
三,IO缓冲层次关系
- 首先,通过stdio库将用户数据传递到stdio缓冲区,该缓冲区位于用户态内存区。
- 当缓冲区填满,stdio库会调用write()系统调用,将数据传递到内核高速缓冲区,该缓冲区位于内核态内存区。
- 最终,内核发起磁盘操作。
四,小结
O_DIRECT与O_SYNC区别(转)的更多相关文章
- UNIX高级环境编程(14)文件IO - O_DIRECT和O_SYNC详解 < 海棠花溪 >
春天来了,除了工作学习,大家也要注意锻炼身体,多出去运动运动. 上周末在元大都遗址公园海棠花溪拍的海棠花. 进入正题. O_DIRECT和O_SYNC是系统调用open的flag参数.通过指定o ...
- Linux系统:保证数据安全落盘
在很多IO场景中,我们经常需要确保数据已经安全的写到磁盘上,以便在系统宕机重启之后还能读到这些数据.但是我们都知道,linux系统的IO路径还是很复杂的,分为很多层,每一层都可能会有buffer来加速 ...
- Linux:保证数据安全落盘
背景 在很多IO场景中,我们经常需要确保数据已经安全的写到磁盘上,以便在系统宕机重启之后还能读到这些数据.但是我们都知道,linux系统的IO路径还是很复杂的,分为很多层,每一层都可能会有buffer ...
- 关于innodb_flush_log_at_trx_commit、innodb_flush_method、innodb_log_block_size和fsync()、O_DIRECT、iops、云盘的关系与总结
想着整理关于innodb_flush_log_at_trx_commit.innodb_flush_method.innodb_log_block_size和fsync().O_DIRECT.iops ...
- sync fsync fdatasync ---systemtap跟踪
aa.stp: probe kernel .function ( "sys_sync" ) { printf ( "probfunc:%s fun:%s\n", ...
- UNIX高级环境编程1
UNIX高级环境编程1 故宫角楼是很多摄影爱好者常去的地方,夕阳余辉下的故宫角楼平静而安详. 首先,了解一下进程的基本概念,进程在内存中布局和内容. 此外,还需要知道运行时是如何为动态数据结构(如链表 ...
- 详解linux io flush
通过本文你会清楚知道 fsync().fdatasync().sync().O_DIRECT.O_SYNC.REQ_PREFLUSH.REQ_FUA的区别和作用. fsync() fdatasync( ...
- Redis persistence demystified - part 1
关于Redis我的一部分工作是阅读博客,论坛以及twitter时间线(time line).对于开发者来说,能够了解用户社区,非用户社区如果理解他正在开发的产品是非常重要的.据我所知,持久化特性是最易 ...
- KVM几种缓存模式
原文在这里: http://pic.dhe.ibm.com/infocenter/lnxinfo/v3r0m0/index.jsp?topic=%2Fliaat%2Fliaatbpkvmguestca ...
随机推荐
- this和引用变量的地址值是同一个---------new后面的是构造方法
/*全局变量和构造方法及this和引用变量的关系 引用变量在栈里面对象在堆中this你可以理解为在堆里面this就是这个对象自己 */ public class Person {/* * 定义属性 ...
- 《剑指offer》-数据流中的中位数
如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值.如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值. 最开始的思路 ...
- 【C++ Primer | 10】STL算法
第一部分 find(beg, end, val) equal(beg1, end, beg2) min(val1, val2) max(val1, val2) min_element(beg, end ...
- WebApi的调用-1.前端调用
前端调用 html <div class="row"> <form id="queryForm"> <input name=&qu ...
- java / android int类型如何判空?
/** TextUtils.isEmpty() 方法的实现 * Returns true if the string is null or 0-length. * @param str the str ...
- Servlet的多线程和线程安全
线程安全 首先说明一下对线程安全的讨论,哪种情况我们可以称作线程安全?网上对线程安全有很多描述,我比较喜欢<Java并发编程实战>给出的定义,“当多个线程访问某个类时,不管运行时环境采用何 ...
- Linux 僵尸进程的筛选和查杀
一.筛选 ps -A -o stat,ppid,pid,cmd | grep -e '^[Zz]' 二.查杀 ps -A -o stat,ppid,pid,cmd | grep -e '^[Zz]' ...
- 微信小程序开发--第一个项目
一:Hello World 1.AppId 2.打开开发者工具 3.显示效果 二:
- python日期与时间
1.介绍 Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间. 时间间隔是以秒为单位的浮点小数. 每个时间戳都以自从1970年1月1日午夜(历元)经过了多长时间来表 ...
- 针对mysql delete删除表数据后占用空间不变小的问题
开发环境 Yii1版本 MySQL PHP5.6.27 前言 物流规则匹配日志表记录订单匹配规则相关日志信息,方便管理员维护和查阅不匹配的订单,四个月时间,该日志表数据就有174G,当前,这么大的数据 ...