Solr-全文检索工具简介
一.Solr的简介
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务。Solr可以独立运行在Jetty、Tomcat等这些Servlet容器中。都是Web服务器,Servlet容器,报文 ,JSON 格式字符串, XML格式字符串。Solr是一个可以独立运行的搜索服务器,使用solr进行全文检索服务的话,只需要通过http请求访问该服务器即可。
使用Solr 进行创建索引和搜索索引的实现方法很简单,如下:
- 创建索引:客户端(可以是浏览器可以是Java程序)用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr服务器根据xml文档添加、删除、更新索引 。
- 搜索索引:客户端(可以是浏览器可以是Java程序)用 GET方法向 Solr 服务器发送请求,然后对 Solr服务器返回Xml、json等格式的查询结果进行解析。Solr不提供构建页面UI的功能。Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
二.Solr和Lucene的区别
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索应用。Lucene仅提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索应用。
Solr的目标是打造一款企业级的搜索引擎系统,它是基于Lucene一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
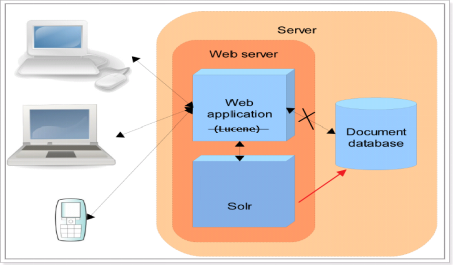
三.Solr的单机与集群概念
1.Solr的单机版
概念:HttpSolrServer
2.Solr的集群版
概念:SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
结构:SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud需要由多台服务器组成,由zookeeper来进行协调管理。
- 整个集群的配置信息可以集中配置
- 对于搜索自动负载均衡、出现故障时可以自动切换
- 集成了ZooKeeper,负责集群的协调和配置
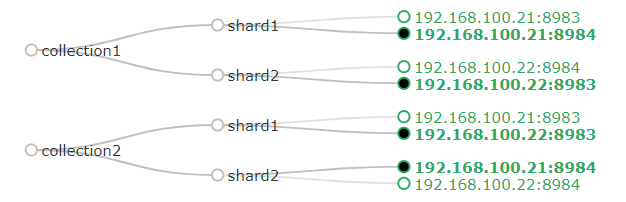
- HA:High Availability
- Node:一个服务器、或虚拟服务器节点,每个node对应一个port向外提供服务。对应于一个JVM。
- Collection:一个SolrCloud实例,负责对一批数据建立一个索引,并提供基于这个索引的搜索服务
- Shard:一个SolrCloud中的索引可以被拆分存放到多个shard中
- Replica:一个shard中的数据,可以有多个副本,就是Replica,其中有一个被推选出来的leader
- Core:负责处理一个Replica,跟一个node对应
- Cluster:由ZooKeeper管理的多个Node的集合,对solr的请求可以发送给一个cluster
- 如果文档被送到一个replica中,那么这个replica会把这些文档发送给这个shard的leader
- 当一个leader接收到文档的时候,SolrCloud会决定这些文档应该分配到哪个shard,然后把它们发生给这个shard的leader、建立索引、并把索引发送给这个shard中所有的replica

package com.xyg.solrj; import java.util.List;
import java.util.Map;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrQuery.ORDER;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.junit.Test; /**
* <p>Title:SolrjDemo</p>
* @Description:solrj的入门程序
* @Param:
* @Return:
* @Author:Administrator
* @Date:2017年11月3日上午12:32:42
*/
public class SolrjDemo {
//添加 修改
@Test
public void testCreateAndUpdateIndex() throws Exception {
// 1. 创建HttpSolrServer对象
// 设置solr服务接口,浏览器客户端地址http://127.0.0.1:8080/solr/#/
String baseURL = "http://127.0.0.1:8080/solr";
//String baseURL = "http://localhost:8080/solr/collection2";
SolrServer solrServer = new HttpSolrServer(baseURL);
// 2. 创建SolrInputDocument对象
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "100");
document.addField("name", "Hello world!");
// 3. 把SolrInputDocument对象添加到索引库中
solrServer.add(document); //httpSolrServer.add(document,1000);
// 4. 提交
solrServer.commit();
}
//删除
@Test
public void testDeleteIndex() throws Exception {
String baseURL = "http://127.0.0.1:8080/solr";
SolrServer solrServer = new HttpSolrServer(baseURL);
// 根据id删除索引数据
//solrServer.deleteById("100");
// 根据条件删除(如果是*:*就表示全部删除,慎用)
//solrServer.deleteByQuery("name:Hello");
solrServer.deleteByQuery("*:*"); //删除所有
solrServer.commit(); // 提交
}
//查询
@Test
public void testSearchIndex1() throws Exception {
String baseURL = "http://127.0.0.1:8080/solr";
SolrServer solrServer = new HttpSolrServer(baseURL);
// 创建搜索对象
SolrQuery query = new SolrQuery();
// 设置搜索条件
query.setQuery("*:*");
// 发起搜索请求
QueryResponse response = solrServer.query(query);
// 处理搜索结果
SolrDocumentList docs = response.getResults();
System.out.println("搜索到的结果总数:" + docs.getNumFound());
// 遍历搜索结果
for (SolrDocument doc : docs) {
System.out.println("----------------------------------------------------");
System.out.println("id:" + doc.get("id"));
System.out.println("name:" + doc.get("name"));
}
}
//复杂查询索引
@Test
public void queryIndex2() throws Exception {
//创建连接
SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr");
//创建一个query对象
SolrQuery solrQuery = new SolrQuery();
//设置关键词查询条件
solrQuery.setQuery("钻石"); //solrQuery.set("q","钻石");
//过滤条件
solrQuery.setFilterQueries("product_catalog_name:幽默杂货");
//排序条件
solrQuery.setSort("product_price", ORDER.asc);
//分页处理
solrQuery.setStart(0);
solrQuery.setRows(10);
//结果中域的列表 solrQuery.setFields("id","product_name","product_price","product_catalog_name","product_picture");
//设置默认搜索域
solrQuery.set("df", "product_keywords");
//高亮显示
solrQuery.setHighlight(true);
//高亮显示的域
solrQuery.addHighlightField("product_name");
//高亮显示的前缀
solrQuery.setHighlightSimplePre("<font color='red'>");
//高亮显示的后缀
solrQuery.setHighlightSimplePost("</font>");
//执行查询
QueryResponse queryResponse = solrServer.query(solrQuery);
//取查询结果
SolrDocumentList solrDocumentList = queryResponse.getResults();
//共查询到商品数量
System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound());
//遍历查询的结果
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get("id"));
//取高亮显示
String productName = "";
Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();
List<String> list = highlighting.get(solrDocument.get("id")).get("product_name");
//判断是否有高亮内容
if (null != list) {
productName = list.get(0);
} else {
productName = (String) solrDocument.get("product_name");
}
System.out.println(productName);
System.out.println(solrDocument.get("product_price"));
System.out.println(solrDocument.get("product_catalog_name"));
System.out.println(solrDocument.get("product_picture"));
}
}
}
Solr-全文检索工具简介的更多相关文章
- Lucene:基于Java的全文检索引擎简介
Lucene:基于Java的全文检索引擎简介 Lucene是一个基于Java的全文索引工具包. 基于Java的全文索引/检索引擎--Lucene Lucene不是一个完整的全文索引应用,而是是一个用J ...
- solr全文检索实现原理
本文转自:https://blog.csdn.net/u014209975/article/details/53263642 https://blog.csdn.net/lihang_1994/ ...
- lucene 全文检索工具的介绍
Lucene:全文检索工具:这是一种思想,使用的是C语言写出来的 1.Lucene就是apache下的一个全文检索工具,一堆的jar包,我们可以使用lucene做一个谷歌和百度一样的搜索引擎系统 2. ...
- sysbench压力测试工具简介和使用(一)
sysbench压力测试工具安装和参数介绍 一.sysbench压力测试工具简介: sysbench是一个开源的.模块化的.跨平台的多线程性能测试工具,可以用来进行CPU.内存.磁盘I/O.线程.数据 ...
- SOLR (全文检索)
SOLR (全文检索) http://sinykk.iteye.com/ 1. 什么是SOLR 官方网站 http://wiki.apache.org/solr http://wiki.apach ...
- JS内存泄漏 和Chrome 内存分析工具简介(摘)
原文地址:http://web.jobbole.com/88463/ JavaScript 中 4 种常见的内存泄露陷阱 原文:Sebastián Peyrott 译文:伯乐在线专栏作者 - AR ...
- SQL Profiler工具简介
一.SQL Profiler工具简介 SQL Profiler是一个图形界面和一组系统存储过程,其作用如下: 图形化监视SQL Server查询: 在后台收集查询信息: 分析性能: 诊断像死锁之类的问 ...
- sed 工具简介
sed 工具简介sed 可以分析 Standard Input (STDIN) 的数据, 然后将数据经过处理后,再将他输出到 standrad out (STDOUT) 的一个工具. 至于处理呢?可以 ...
- 全文检索工具推荐FileLocator
全文检索工具推荐FileLocator https://www.baidu.com/link?url=_vaDZaJ_OePrAX-BTUD5hjTymnvN7_1oIAnWyS25hqxAg0nUH ...
- redis redis常用命令及内存分析总结(附RedisClient工具简介
redis常用命令及内存分析总结(附RedisClient工具简介 by:授客 QQ:1033553122 redis-cli工具 查看帮助 连接redis数据库 常用命令 exists key se ...
随机推荐
- Go语言之高级篇beego框架之请求数据处理
1.Controller中数据参数处理 获取参数:我们经常需要获取用户传递的数据,包括 Get.POST 等方式的请求,beego 里面会自动解析这些数据,你可以通过如下方式获取数据: GetStri ...
- 3、Python的应用
Python的应用 Google 实现Web爬虫和搜索引擎中的很多组件. Yahoo Yahoo使用它(包括其他技术)管理讨论组. NASA NASA在它的几个系统中既用了Python开发,又将其作为 ...
- WebMagic编译时提示Failure to transfer org.apache.maven.plugins:maven-surefire-plugin:pom:2.18的解决方法
问题描述: 从http://git.oschina.net/flashsword20/webmagic 下载最新代码,按照http://webmagic.io/docs/zh/posts/ch3 ...
- 服务 AIDL 定向tag IPC Parcelable 案例 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- Android Studio下加入百度地图的使用 (一)——环境搭建
最近有学生要做毕业设计,会使用到定位及地图信息的功能,特此研究了一下,供大家参考,百度定位SDK已经更新到了5.0,地图SDK已经更新到了3.5,但是在AndroidStudio中使用还是存在一些不稳 ...
- Android HandlerThread 源代码分析
HandlerThread 简单介绍: 我们知道Thread线程是一次性消费品,当Thread线程运行完一个耗时的任务之后.线程就会被自己主动销毁了.假设此时我又有一 个耗时任务须要运行,我们不得不又 ...
- 动态库DLL中类的使用
一.DLL中类的导出 在类名称前添加 _declspec(dllexport)定义,比如: class _declspec(dllexport) CMath{ .... }; 通常使用预编译开关切换类 ...
- 我的第一个HTML5应用
直接贴代码: 源代码: <?xml version="1.0" encoding="UTF-8"?> <div xmlns="htt ...
- eclipse plugin development -menu
org.eclipse.ui.menus locationURI MenuContribution locationURI = "[Scheme]:[id]?[argument-list]& ...
- wine qq 2013 for linux deb包 Ubuntu 64位兼容
2013-08-08 Wine 1.6,如果您想体验下该版本的wine,目前可以通过ppa进行安装: sudo add-apt-repository ppa:ubuntu-wine/ppa ...