HashMap的底层结构和原理
http://youzhixueyuan.com/the-underlying-structure-and-principle-of-hashmap.html
HashMap是Java程序员使用频率最高的用于映射(键值对)处理的数据类型。
Java为数据结构中的映射定义了一个接口java.util.Map,此接口主要有四个常用的实现类,分别是HashMap、Hashtable、LinkedHashMap和TreeMap(还有ConcurrentHashMap),类继承关系如下图所示:

HashMap最多只允许一条记录的键为null,允许多条记录的值为null。
LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap。在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。
Hashtable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable
从结构实现来讲,HashMap是:数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下如所示。
HashMap数据底层具体存储的是什么?这样的存储方式有什么优点呢?
从源码可知,HashMap类中有一个非常重要的字段,就是 Node[] table,即哈希桶数组。
Node是HashMap的一个内部类,实现了Map.Entry接口,本质是就是一个映射(键值对),除了K,V,还包含hash和next。
HashMap就是使用哈希表来存储的。哈希表为解决冲突,采用链地址法来解决问题,链地址法,简单来说,就是数组加链表的结合。在每个数组元素上都一个链表结构,当数据被Hash后,得到数组下标,把数据放在对应下标元素的链表上。
如果哈希桶数组很大,即使较差的Hash算法也会比较分散,如果哈希桶数组数组很小,即使好的Hash算法也会出现较多碰撞,所以就需要在空间成本和时间成本之间权衡,其实就是在根据实际情况确定哈希桶数组的大小,并在此基础上设计好的hash算法减少Hash碰撞。那么通过什么方式来控制map使得Hash碰撞的概率又小,哈希桶数组(Node[] table)占用空间又少呢?答案就是好的Hash算法和扩容机制。
在理解Hash和扩容流程之前,我们得先了解下HashMap的几个字段。从HashMap的默认构造函数源码可知,构造函数就是对下面几个字段进行初始化,源码如下:
int threshold; // 所能容纳的key-value对极限,超过这个数目就重新resize(扩容)
final float loadFactor; // 负载因子,默认的负载因子0.75是对空间和时间效率的一个平衡选择,建议大家不要修改
int modCount; //记录HashMap内部结构发生变化的次数
int size; //实际存在的键值对数量
在HashMap中,哈希桶数组table的长度length大小必须为2的n次方.
这里存在一个问题,即使负载因子和Hash算法设计的再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,则会严重影响HashMap的性能。于是,在JDK1.8版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能,其中会用到红黑树的插入、删除、查找等算法。
HashMap的内部功能实现很多,本文主要从:
1).根据key获取哈希桶数组索引位置
2).put方法的详细执行
3).扩容过程三个具有代表性的点深入展开讲解。
1. 确定哈希桶数组索引位置
不管增加、删除、查找键值对,定位到哈希桶数组的位置都是很关键的第一步。前面说过HashMap的数据结构是数组和链表的结合,所以我们当然希望这个HashMap里面的元素位置尽量分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,不用遍历链表,大大优化了查询的效率。
HashMap的Hash算法本质上就是三步:取key的hashCode值、高位运算、取模运算。
2. 分析HashMap的put方法
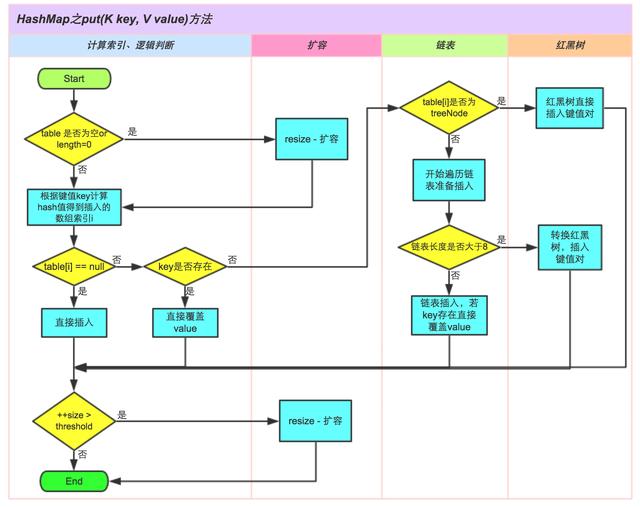
3. 扩容机制
扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。
这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。
HashMap中,如果key经过hash算法得出的数组索引位置全部不相同,即Hash算法非常好,那样的话,getKey方法的时间复杂度就是O(1),如果Hash算法技术的结果碰撞非常多,假如Hash算极其差,所有的Hash算法结果得出的索引位置一样,那样所有的键值对都集中到一个桶中,或者在一个链表中,或者在一个红黑树中,时间复杂度分别为O(n)和O(lgn)。
小结
(1) 扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
(2) 负载因子是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况非常特殊。
(3) HashMap是线程不安全的,不要在并发的环境中同时操作HashMap,建议使用ConcurrentHashMap。
(4) JDK1.8引入红黑树大程度优化了HashMap的性能。
HashMap的底层结构和原理的更多相关文章
- HashMap底层结构、原理、扩容机制
https://www.jianshu.com/p/c1b616ff1130 http://youzhixueyuan.com/the-underlying-structure-and-princip ...
- HashMap的存储结构及原理
1.HashMap的数据结构(HashMap通过hashcode对其内容进行高速查找,是无序的) 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端. 数组 :数组的存储区是连续的,占 ...
- V7000存储数据恢复_底层结构原理拆解及Mdisk磁盘掉线数据恢复方法
Storwize V7000(也就是我们常说的V7000)是新推出的一款中端存储系统,这款系统的定位虽然在中端,但是Storwize V7000提供有存储管理功能,这一功能以前只有高端存储才拥有(例如 ...
- HashMap的底层实现原理
HashMap的底层实现原理1,属性static final int MAX_CAPACITY = 1 << 30;//1073741824(十进制)0100000000000000000 ...
- HashMap底层实现及原理
注意:文章的内容基于JDK1.7进行分析.1.8做的改动文章末尾进行讲解. 一.先来熟悉一下我们常用的HashMap: 1.HashSet和HashMap概述 对于HashSst及其子类而 ...
- HashMap的底层原理(jdk1.7.0_79)
前言 在Java中我们最常用的集合类毫无疑问就是Map,其中HashMap作为Map最重要的实现类在我们代码中出现的评率也是很高的. 我们对HashMap最常用的操作就是put和get了,那么你知道它 ...
- Map实现之HashMap(结构及原理)(转)
java.util包中的集合类包含 Java 中某些最常用的类.最常用的集合类是 List 和 Map.List 的具体实现包括 ArrayList 和 Vector,它们是可变大小的列表,比较适合构 ...
- 牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- HashMap的底层原理 cr:csdn:zhangshixi
1. HashMap概述: HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射操作,并允许使用null值和null键.此类不保证映射的顺序,特别是它不保证该顺序恒久不变 ...
随机推荐
- idea .gitignore模板
IDEA 创建的项目,需要搞个.gitignore文件,文件内容可以参考插件的. # Created by .ignore support plugin (hsz.mobi) ### JetBrain ...
- PAT-1107 Social Clusters (30 分) 并查集模板
1107 Social Clusters (30 分) When register on a social network, you are always asked to specify your ...
- HTTP无状态协议理解
TTP协议是无状态协议. 无状态是指协议对于事务处理没有记忆能力.缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大.另一方面,在服务器不需要先前信息时它的应 ...
- C#Modbus Rtu的实现
Modbus Rtu的实现与Modbus Tcp的实现类似 C#ModBus Tcp的学习及Master的实现 我们还是需要借用一个开源库NModbus4,在vs中.打开NuGet管理器.安装NMod ...
- python路径相关处理
一.绝对路径 import os path1=os.path.abspath('.') #表示当前所处的文件夹的绝对路径 print(path1) path2=os.path.abspath('..' ...
- JavaScript获取页面元素的常用方法
1.通过标签获取元素,返回一个数组 var li = document.getElementsByTagName('li');//标签获取元素 li[0].innerHTML;// 查看获取元素的内容 ...
- laravel登录后其他页面拿不到登录信息
登录本来是用表单的,我自作聪明的使用ajax提交 public function login(Request $request){ $data = $request->input(); $dat ...
- 【OF框架】在Visual Studio中启用Docker支持,编译生成,并在容器运行项目
准备 本地已经安装Docker 一.添加Docker支持 第一步:查看本地Docker服务状态 第二步:项目添加Docker支持 第三步:选择Linux容器 第四步:点击启动 第五步:确认Docker ...
- 每日一题-——LeetCode(111)二叉树的最小深度
题目描述: 给定一个二叉树,找出其最小深度. 最小深度是从根节点到最近叶子节点的最短路径上的节点数量. 思路一: 把每一层的结点加入到队列,每一层i+1,到下一层时,把上一层在队列中的结点都弹出,按从 ...
- 2. 软件有很多种,也有各种分类办法: ShrinkWrap (在包装盒子里面的软件,软件在CD/DVD上); Web APP (基于网页的软件); Internal Software (企业或学校或某组织内部的软件); Games (游戏); Mobile Apps (手机应用); Operating Systems (操作系统); Tools
选取对你最相关的一类软件, 请回答:(web app) 1) 此类软件是什么时候开始出现的, 这些软件是怎么说服你(陌生人)成为他们的用户的? 他们的目标都是盈利么? 他们的目标都是赚取用户 ...