【机器学习】Learning to Rank 简介
Learning to Rank 简介
去年实习时,因为项目需要,接触了一下Learning to Rank(以下简称L2R),感觉很有意思,也有很大的应用价值。L2R将机器学习的技术很好的应用到了排序中,并提出了一些新的理论和算法,不仅有效地解决了排序的问题,其中一些算法(比如LambdaRank)的思想非常新颖,可以在其他领域中进行借鉴。鉴于排序在许多领域中的核心地位,L2R可以被广泛的应用在信息(文档)检索,协同过滤等领域。
本文将对L2R做一个比较深入的介绍,主要参考了刘铁岩、李航等人的几篇相关文献[1,2,3],我们将围绕以下几点来介绍L2R:现有的排序模型,为什么需要使用机器学习的方法来进行排序,L2R特征的选取,L2R训练数据的获取,L2R训练和测试,L2R算法分类和简介,L2R效果评价等。
1.现有的排序模型
排序(Ranking)一直是信息检索的核心研究问题,有大量的成熟的方法,主要可以分为以下两类:相关度排序模型和重要性排序模型。
1.1 相关度排序模型(Relevance Ranking Model)
相关度排序模型根据查询和文档之间的相似度来对文档进行排序。常用的模型包括:布尔模型(Boolean Model),向量空间模型(Vector Space Model),隐语义分析(Latent Semantic Analysis),BM25,LMIR模型等等。
1.2 重要性排序模型(Importance Ranking Model)
重要性排序模型不考虑查询,而仅仅根据网页(亦即文档)之间的图结构来判断文档的权威程度,典型的权威网站包括Google,Yahoo!等。常用的模型包括PageRank,HITS,HillTop,TrustRank等等。
2. 为什么需要使用机器学习的方法来进行排序
对于传统的排序模型,单个模型往往只能考虑某一个方面(相关度或者重要性),所以只是用单个模型达不到要求。搜索引擎通常会组合多种排序模型来进行排序,但是,如何组合多个排序模型来形成一个新的排序模型,以及如何调节这些参数,都是一个很大的问题。
使用机器学习的方法,我们可以把各个现有排序模型的输出作为特征,然后训练一个新的模型,并自动学得这个新的模型的参数,从而很方便的可以组合多个现有的排序模型来生成新的排序模型。
3. L2R的特征选取
与文本分类不同,L2R考虑的是给定查询的文档集合的排序。所以,L2R用到的特征不仅仅包含文档d本身的一些特征(比如是否是Spam)等,也包括文档d和给定查询q之间的相关度,以及文档在整个网络上的重要性(比如PageRank值等),亦即我们可以使用相关性排序模型和重要性排序模型的输出来作为L2R的特征。
1). 传统排序模型的输出,既包括相关性排序模型的输出f(q,d),也包括重要性排序模型的输出。
2). 文档本身的一些特征,比如是否是Spam等。
4. L2R训练数据的获取
L2R的训练数据可以有三种形式:对于每个查询,各个文档的绝对相关值(非常相关,比较相关,不相关,等等);对于每个查询,两两文档之间的相对相关值(文档1比文档2相关,文档4比文档3相关,等等);对于每个查询,所有文档的按相关度排序的列表(文档1>文档2>文档3)。这三种形式的训练数据之间可以相互转换,详见[1]。
训练数据的获取有两种主要方法:人工标注[3]和从日志文件中挖掘[4]。
人工标注:首先从搜索引擎的搜索记录中随机抽取一些查询,将这些查询提交给多个不同的搜索引擎,然后选取各个搜索引擎返回结果的前K个,最后由专业人员来对这些文档按照和查询的相关度进行标注。
从日志中挖掘:搜索引擎都有大量的日志记录用户的行为,我们可以从中提取出L2R的训练数据。Joachims提出了一种很有意思的方法[4]:给定一个查询,搜索引擎返回的结果列表为L,用户点击的文档的集合为C,如果一个文档di被点击过,另外一个文档dj没有被点击过,并且dj在结果列表中排在di之前,则di>dj就是一条训练记录。亦即训练数据为:{di>dj|di属于C,dj属于L-C,p(dj)<p(di)},其中p(d)表示文档d在查询结果列表中的位置,越小表示越靠前。
5. L2R模型训练
L2R是一个有监督学习过程。
对与每个给定的查询-文档对(query document pair),抽取相应的特征(既包括查询和文档之间的各种相关度,也包括文档本身的特征以及重要性等),另外通过或者人工标注或者从日志中挖掘的方法来得到给定查询下文档集合的真实序列。然后我们使用L2R的各种算法来学到一个排序模型,使其输出的文档序列和真实序列尽可能相似。
6. L2R算法分类和简介
L2R算法主要包括三种类别:PointWise,PairWise,ListWise。
1). PointWise L2R
PointWise方法只考虑给定查询下,单个文档的绝对相关度,而不考虑其他文档和给定查询的相关度。亦即给定查询q的一个真实文档序列,我们只需要考虑单个文档di和该查询的相关程度ci,亦即输入数据应该是如下的形式:

Pointwise方法主要包括以下算法:Pranking (NIPS 2002), OAP-BPM (EMCL 2003), Ranking with Large Margin Principles (NIPS 2002), Constraint Ordinal Regression (ICML 2005)。
Pointwise方法仅仅使用传统的分类,回归或者Ordinal Regression方法来对给定查询下单个文档的相关度进行建模。这种方法没有考虑到排序的一些特征,比如文档之间的排序结果针对的是给定查询下的文档集合,而Pointwise方法仅仅考虑单个文档的绝对相关度;另外,在排序中,排在最前的几个文档对排序效果的影响非常重要,Pointwise没有考虑这方面的影响。
2). Pairwise L2R
Pairwise方法考虑给定查询下,两个文档之间的相对相关度。亦即给定查询q的一个真实文档序列,我们只需要考虑任意两个相关度不同的文档之间的相对相关度:di>dj,或者di<dj。

Pairwise方法主要包括以下几种算法:Learning to Retrieve Information (SCC 1995), Learning to Order Things (NIPS 1998), Ranking SVM (ICANN 1999), RankBoost (JMLR 2003), LDM (SIGIR
2005), RankNet (ICML 2005), Frank (SIGIR 2007), MHR(SIGIR 2007), Round Robin Ranking (ECML 2003), GBRank (SIGIR 2007), QBRank (NIPS 2007), MPRank (ICML 2007), IRSVM (SIGIR 2006) 。
相比于Pointwise方法,Pairwise方法通过考虑两两文档之间的相对相关度来进行排序,有一定的进步。但是,Pairwise使用的这种基于两两文档之间相对相关度的损失函数,和真正衡量排序效果的一些指标之间,可能存在很大的不同,有时甚至是负相关,如下图所示(pairwise的损失函数和NDCG之呈现出负相关性):
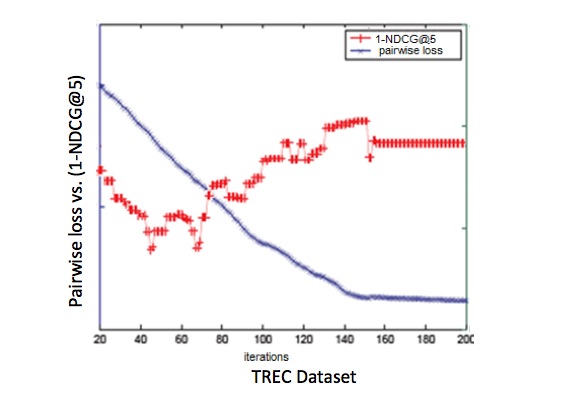
另外,有的Pairwise方法没有考虑到排序结果前几名对整个排序的重要性,也没有考虑不同查询对应的文档集合的大小对查询结果的影响(但是有的Pairwise方法对这些进行了改进,比如IR SVM就是对Ranking SVM针对以上缺点进行改进得到的算法)。
3). Listwise L2R
与Pointwise和Pairwise方法不同,Listwise方法直接考虑给定查询下的文档集合的整体序列,直接优化模型输出的文档序列,使得其尽可能接近真实文档序列。
Listwise算法主要包括以下几种算法:LambdaRank (NIPS 2006), AdaRank (SIGIR 2007), SVM-MAP (SIGIR 2007), SoftRank (LR4IR 2007), GPRank (LR4IR 2007), CCA (SIGIR 2007), RankCosine
(IP&M 2007), ListNet (ICML 2007), ListMLE (ICML 2008) 。
相比于Pointwise和Pairwise方法,Listwise方法直接优化给定查询下,整个文档集合的序列,所以比较好的解决了克服了以上算法的缺陷。Listwise方法中的LambdaMART(是对RankNet和LambdaRank的改进)在Yahoo Learning to Rank Challenge表现出最好的性能。
7. L2R效果评价
L2R是用机器学习的方法来进行排序,所以评价L2R效果的指标就是评价排序的指标,主要包括一下几种:
1) WTA(Winners take all) 对于给定的查询q,如果模型返回的结果列表中,第一个文档是相关的,则WTA(q)=1,否则为0.
2) MRR(Mean Reciprocal Rank) 对于给定查询q,如果第一个相关的文档的位置是R(q),则MRR(q)=1/R(q)。
3) MAP(Mean Average Precision) 对于每个真实相关的文档d,考虑其在模型排序结果中的位置P(d),统计该位置之前的文档集合的分类准确率,取所有这些准确率的平均值。
4) NDCG(Normalized Discounted Cumulative Gain) 是一种综合考虑模型排序结果和真实序列之间的关系的一种指标,也是最常用的衡量排序结果的指标,详见Wikipedia。
5) RC(Rank Correlation) 使用相关度来衡量排序结果和真实序列之间的相似度,常用的指标是Kendall's
Tau。
参考文献:
[1]. Learning to Rank for Information Retrieval. Tie-yan Liu.
[2]. Learning to Rank for Information Retrieval and Natural Language Processing. Hang Li.
[3]. A Short Introduction to Learning to Rank. Hang Li.
[4]. Optimizing Search Engines using Clickthrough Data. Thorsten Joachims. SIGKDD,2002.
[5]. Learning
to Rank小结
【机器学习】Learning to Rank 简介的更多相关文章
- Learning to Rank 简介
转自:http://www.cnblogs.com/kemaswill/archive/2013/06/01/3109497.html,感谢分享! 本文将对L2R做一个比较深入的介绍,主要参考了刘铁岩 ...
- Learning to Rank简介
Learning to Rank是采用机器学习算法,通过训练模型来解决排序问题,在Information Retrieval,Natural Language Processing,Data Mini ...
- 搜索排序-learning to Rank简介
Learning to Rank pointwise \[ L\left(f ; x_{j}, y_{j}\right)=\left(y_{j}-f\left(x_{j}\right)\right)^ ...
- 【机器学习】Learning to Rank之Ranking SVM 简介
Learning to Rank之Ranking SVM 简介 排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning t ...
- [Machine Learning] Learning to rank算法简介
声明:以下内容根据潘的博客和crackcell's dustbin进行整理,尊重原著,向两位作者致谢! 1 现有的排序模型 排序(Ranking)一直是信息检索的核心研究问题,有大量的成熟的方法,主要 ...
- Learning to Rank之Ranking SVM 简介
排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank简 ...
- Learning to Rank之RankNet算法简介
排序一直是信息检索的核心问题之一, Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank ...
- 芝麻HTTP: Learning to Rank概述
Learning to Rank,即排序学习,简称为 L2R,它是构建排序模型的机器学习方法,在信息检索.自然语言处理.数据挖掘等场景中具有重要的作用.其达到的效果是:给定一组文档,对任意查询请求给出 ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
随机推荐
- 题解 【NOIP2010】关押罪犯
[NOIP2010]关押罪犯 Description S城现有两座监狱,一共关押着N名罪犯,编号分别为1~N.他们之间的关系自然也极不和谐.很多罪犯之间甚至积怨已久,如果客观条件具备则随时可能爆发冲突 ...
- 【Wince-ListView】Wince中的 ListView怎么显示网格?
using System.Runtime.InteropServices; using System.Windows.Forms; namespace CETEST { public class Co ...
- Dapper源码学习
序言 资料 https://github.com/StackExchange/Dapper
- monkeyrunner操作多个设备的例子
# -*- coding: utf-8 -*- from com.android.monkeyrunner import MonkeyRunner,MonkeyDevice from com.an ...
- BZOJ 4814 Luogu P3699 [CQOI2017]小Q的草稿 (计算几何、扫描线、set)
题目链接 (BZOJ) http://lydsy.com/JudgeOnline/problem.php?id=4814 (Luogu) https://www.luogu.org/problem/P ...
- HDU 5810 Balls and Boxes ——(数学,概率,方差)
官方题解看不太懂,参考了一些人的博客以后自己证明如下: 其中D(X)和E(X)的公式如下(参考自百度百科): 其中 p = 1 / m .(这是每一个单独事件发生的概率期望,在这里单独事件指的是一个球 ...
- React Redux 与胖虎
这是一篇详尽的 React Redux 扫盲文. 对 React Redux 已经比较熟悉的同学可以直接看 <React Redux 与胖虎他妈>. 是什么 React Redux 是 R ...
- 【好书推荐】9、安卓Andorid编程吐血整理100+本
点开即可
- 黑马vue---14、v-model双向绑定
黑马vue---14.v-model双向绑定 一.总结 一句话总结: 1.v-bind 只能实现数据的单向绑定,从 M 自动绑定到 V, 无法实现数据的双向绑定 2.v-model 指令,可以实现 表 ...
- Python中列表操作进阶及元组
列表高级操作 一.遍历列表 >>> ls=['a','d','it'] >>> for val in ls: ... print (val) ... a d it ...