kNN进邻算法
一、算法概述
(1)采用测量不同特征值之间的距离方法进行分类
- 优点: 精度高、对异常值不敏感、无数据输入假定。
- 缺点: 计算复杂度高、空间复杂度高。
(2)KNN模型的三个要素
kNN算法模型实际上就是对特征空间的的划分。模型有三个基本要素:距离度量、K值的选择和分类决策规则的决定。
距离度量
距离定义为:
Lp(xi,xj)=(∑l=1n|x(l)i−x(l)j|p)1pLp(xi,xj)=(∑l=1n|xi(l)−xj(l)|p)1p一般使用欧式距离:p = 2的个情况
Lp(xi,xj)=(∑l=1n|x(l)i−x(l)j|2)12Lp(xi,xj)=(∑l=1n|xi(l)−xj(l)|2)12K值的选择
一般根据经验选择,需要多次选择对比才可以选择一个比较合适的K值。
如果K值太小,会导致模型太复杂,容易产生过拟合现象,并且对噪声点非常敏感。
如果K值太大,模型太过简单,忽略的大部分有用信息,也是不可取的。
分类决策规则
一般采用多数表决规则,通俗点说就是在这K个类别中,哪种类别最后就判别为哪种类型
二、实施kNN算法
2.1 伪代码
- 计算法已经类别数据集中的点与当前点之间的距离
- 按照距离递增次序排序
- 选取与但前点距离最小的k个点
- 确定前k个点所在类别的出现频率
- 返回前k个点出现频率最高的类别作为当前点的预测分类
2.2 实际代码
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]三、实际案例:使用kNN算法改进约会网站的配对效果
我的朋友阿J一直使用在线约会软件寻找约会对象,他曾经交往过三种类型的人:
- 不喜欢的人
- 感觉一般的人
- 非常喜欢的人
步骤:
- 收集数据
- 准备数据:也就是读取数据的过程
- 分析数据:使用Matplotlib画出二维散点图
- 训练算法
- 测试算法
- 使用算法
3.1 准备数据
样本数据共有1000个,3个特征值,共有4列数据,最后一列表示标签分类(0:不喜欢的人;1:感觉一般的人;2:非常喜欢的人)
特征
- 每年获得的飞行常客里程数
- 玩视频游戏所好的时间百分比
- 每周消费的冰淇淋公斤数
部分数据如下:
40920 8.326976 0.953952 3
14488 7.153469 1.673904 2
26052 1.441871 0.805124 1
75136 13.147394 0.428964 1
38344 1.669788 0.134296 1
72993 10.141740 1.032955 1
35948 6.830792 1.213192 3
42666 13.276369 0.543880 3
67497 8.631577 0.749278 1
35483 12.273169 1.508053 3读取数据(读取txt文件)
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector3.2 分析数据:使用Matplotlib创建散点图
初步分析
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1], datingDataMat[:,2])
ax.set_xlabel("玩视频游戏所耗时间百分比")
ax.set_ylabel("每周消费的冰淇淋公斤数")
plt.show()
因为有三种类型的分类,这样看的不直观,我们添加以下颜色
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1], datingDataMat[:,2])
ax.scatter(datingDataMat[:,1], datingDataMat[:,2], 15.0*array(datingLabels), 15.0*array(datingLabels))
ax.set_xlabel("玩视频游戏所耗时间百分比")
ax.set_ylabel("每周消费的冰淇淋公斤数")
plt.show()
通过都多次的尝试后发现,玩游戏时间和冰淇淋这个两个特征关系比较明显
具体的步骤:
- 分别将标签为1,2,3的三种类型的数据分开
- 使用matplotlib绘制,并使用不同的颜色加以区分
datingDataType1 = array([[x[0][0],x[0][1],x[0][2]] for x in zip(datingDataMat,datingLabels) if x[1]==1])
datingDataType2 = array([[x[0][0],x[0][1],x[0][2]] for x in zip(datingDataMat,datingLabels) if x[1]==2])
datingDataType3 = array([[x[0][0],x[0][1],x[0][2]] for x in zip(datingDataMat,datingLabels) if x[1]==3])
fig, axs = plt.subplots(2, 2, figsize = (15,10))
axs[0,0].scatter(datingDataType1[:,0], datingDataType1[:,1], s = 20, c = 'red')
axs[0,1].scatter(datingDataType2[:,0], datingDataType2[:,1], s = 30, c = 'green')
axs[1,0].scatter(datingDataType3[:,0], datingDataType3[:,1], s = 40, c = 'blue')
type1 = axs[1,1].scatter(datingDataType1[:,0], datingDataType1[:,1], s = 20, c = 'red')
type2 = axs[1,1].scatter(datingDataType2[:,0], datingDataType2[:,1], s = 30, c = 'green')
type3 = axs[1,1].scatter(datingDataType3[:,0], datingDataType3[:,1], s = 40, c = 'blue')
axs[1,1].legend([type1, type2, type3], ["Did Not Like", "Liked in Small Doses", "Liked in Large Doses"], loc=2)
axs[1,1].set_xlabel("玩视频游戏所耗时间百分比")
axs[1,1].set_ylabel("每周消费的冰淇淋公斤数")
plt.show()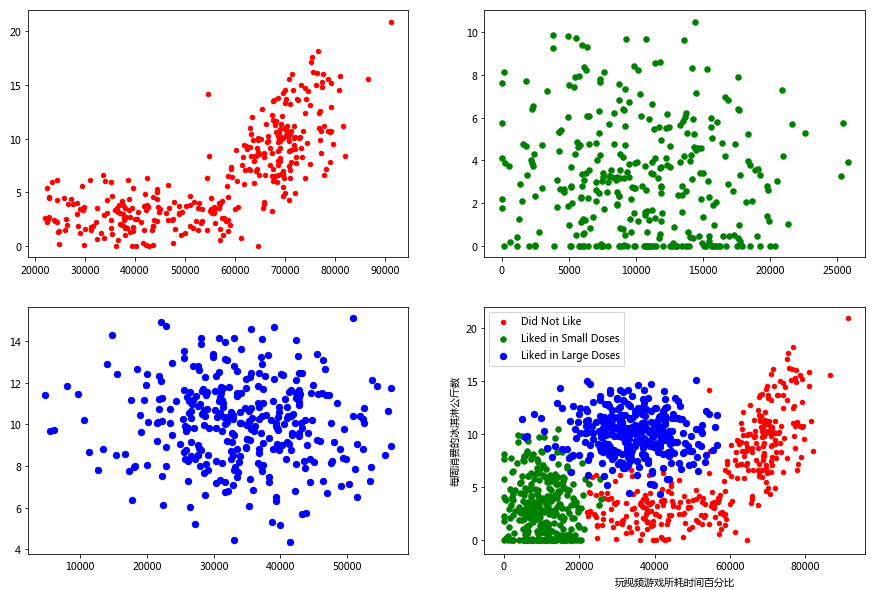
3.3 准备数据:数据归一化
通过上面的图形绘制,发现三个特征值的范围不一样,在使用KNN进行计算距离的时候,数值大的特征值就会对结果产生更大的影响。
数据归一化:就是将几组不同范围的数据,转换到同一个范围内。
公式: newValue = (oldValue - min)/(max - min)
def autoNorm(dataSet):
minVals = dataSet.min(0) # array([[1,20,3], [4,5,60], [7,8,9]]) min(0) = [1, 5, 3]
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normData = zeros(shape(dataSet))
m = dataSet.shape[0]
normData = (dataSet - tile(minVals, (m,1)))/tile(ranges,(m,1))
return normData3.4 测试算法
我们将原始样本保留20%作为测试集,剩余80%作为训练集
def datingClassTest():
hoRatio = 0.20
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
normMat = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:,:],datingLabels[numTestVecs:],3)
if (classifierResult != datingLabels[i]):
errorCount += 1.0
print ("the total error rate is: %f" % (errorCount/float(numTestVecs)))
print (errorCount)运行结果
the total error rate is: 0.080000
16.0四、源代码
from numpy import *
import operator
from os import listdir
import matplotlib
import matplotlib.pyplot as plt
## KNN function
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
# read txt data
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
def autoNorm(dataSet):
minVals = dataSet.min(0) # array([[1,20,3], [4,5,60], [7,8,9]]) min(0) = [1, 5, 3]
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normData = zeros(shape(dataSet))
m = dataSet.shape[0]
normData = (dataSet - tile(minVals, (m,1)))/tile(ranges,(m,1))
return normData
def drawScatter1(datingDataMat, datingLabels):
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1], datingDataMat[:,2])
ax.set_xlabel("玩视频游戏所耗时间百分比")
ax.set_ylabel("每周消费的冰淇淋公斤数")
plt.show()
def drawScatter2(datingDataMat, datingLabels):
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1], datingDataMat[:,2])
ax.scatter(datingDataMat[:,1], datingDataMat[:,2], 15.0*array(datingLabels), 15.0*array(datingLabels))
ax.set_xlabel("玩视频游戏所耗时间百分比")
ax.set_ylabel("每周消费的冰淇淋公斤数")
plt.show()
def drawScatter3(datingDataMat, datingLabels):
datingDataType1 = array([[x[0][0],x[0][1],x[0][2]] for x in zip(datingDataMat,datingLabels) if x[1]==1])
datingDataType2 = array([[x[0][0],x[0][1],x[0][2]] for x in zip(datingDataMat,datingLabels) if x[1]==2])
datingDataType3 = array([[x[0][0],x[0][1],x[0][2]] for x in zip(datingDataMat,datingLabels) if x[1]==3])
fig, axs = plt.subplots(2, 2, figsize = (15,10))
axs[0,0].scatter(datingDataType1[:,0], datingDataType1[:,1], s = 20, c = 'red')
axs[0,1].scatter(datingDataType2[:,0], datingDataType2[:,1], s = 30, c = 'green')
axs[1,0].scatter(datingDataType3[:,0], datingDataType3[:,1], s = 40, c = 'blue')
type1 = axs[1,1].scatter(datingDataType1[:,0], datingDataType1[:,1], s = 20, c = 'red')
type2 = axs[1,1].scatter(datingDataType2[:,0], datingDataType2[:,1], s = 30, c = 'green')
type3 = axs[1,1].scatter(datingDataType3[:,0], datingDataType3[:,1], s = 40, c = 'blue')
axs[1,1].legend([type1, type2, type3], ["Did Not Like", "Liked in Small Doses", "Liked in Large Doses"], loc=2)
axs[1,1].set_xlabel("玩视频游戏所耗时间百分比")
axs[1,1].set_ylabel("每周消费的冰淇淋公斤数")
plt.show()
def datingClassTest():
hoRatio = 0.20
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
normMat = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:,:],datingLabels[numTestVecs:],3)
if (classifierResult != datingLabels[i]):
errorCount += 1.0
print ("the total error rate is: %f" % (errorCount/float(numTestVecs)))
print (errorCount)
datingDataMat, datingLabels = file2matrix("datingTestSet2.txt")
drawScatter1(datingDataMat, datingLabels)
drawScatter2(datingDataMat, datingLabels)
drawScatter3(datingDataMat, datingLabels)
datingClassTest()
kNN进邻算法的更多相关文章
- [机器学习笔记]kNN进邻算法
K-近邻算法 一.算法概述 (1)采用测量不同特征值之间的距离方法进行分类 优点: 精度高.对异常值不敏感.无数据输入假定. 缺点: 计算复杂度高.空间复杂度高. (2)KNN模型的三个要素 kNN算 ...
- [机器学习实战]K-近邻算法
1. K-近邻算法概述(k-Nearest Neighbor,KNN) K-近邻算法采用测量不同的特征值之间的距离方法进行分类.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近 ...
- python机器学习实现K-近邻算法(KNN)
机器学习 K-近邻算法(KNN) 关注公众号"轻松学编程"了解更多. 以下命令都是在浏览器中输入. cmd命令窗口输入:jupyter notebook 后打开浏览器输入网址htt ...
- (转)K-近邻算法(KNN)
K-近邻算法(KNN)概述 KNN是通过测量不同特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别 ...
- 机器学习:K-近邻算法(KNN)
机器学习:K-近邻算法(KNN) 一.KNN算法概述 KNN作为一种有监督分类算法,是最简单的机器学习算法之一,顾名思义,其算法主体思想就是根据距离相近的邻居类别,来判定自己的所属类别.算法的前提是需 ...
- k-近邻算法(kNN)
1.算法工作原理 存在一个训练样本集,我们知道样本集中的每一个数据与所属分类的对应关系,输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应特征进行比较,然后算法提取样本集中特征最相似的数据( ...
- 9,K-近邻算法(KNN)
导引: 如何进行电影分类 众所周知,电影可以按照题材分类,然而题材本身是如何定义的?由谁来判定某部电影属于哪 个题材?也就是说同一题材的电影具有哪些公共特征?这些都是在进行电影分类时必须要考虑的问 题 ...
- 【机器学习实战】第2章 K-近邻算法(k-NearestNeighbor,KNN)
第2章 k-近邻算法 KNN 概述 k-近邻(kNN, k-NearestNeighbor)算法主要是用来进行分类的. KNN 场景 电影可以按照题材分类,那么如何区分 动作片 和 爱情片 呢? 动作 ...
- 【机器学习实战】第2章 k-近邻算法(kNN)
第2章 k-近邻算法 KNN 概述 k-近邻(kNN, k-NearestNeighbor)算法主要是用来进行分类的. KNN 场景 电影可以按照题材分类,那么如何区分 动作片 和 爱情片 呢? 动作 ...
随机推荐
- wmware虚拟化的启动问题
2019-05-09,14点14 vmware出现VMware提示:已将该虚拟机配置为使用 64 位客户机操作系统.但是,无法执行 64 位操作.解决方案 进入bios里面intel 虚拟化技术 先设 ...
- Linux文件系统之目录清单
挂载点:挂载:将设备关联到当前文件系统目录 文件系统:rootfs:根文件系统/boot:系统启动相关文件,如内核.initrd.以及grub(bootleader:引导加载器)/dev:设备文件, ...
- [MySQL优化] -- 如何定位效率较低的SQL
一般通过以下两种方式定位执行效率较低的 SQL 语句. 通过慢查询日志定位那些执行效率较低的 SQL 语句,用 --log-slow-queries[=file_name] 选项启动时, mysqld ...
- 牛客练习赛3 贝伦卡斯泰露——队列&&爆搜
题目 链接 题意:给出一个长度为 $n$ 的数列 $A_i$,问是否能将这个数列分解为两个长度为n/2的子序列,满足: 两个子序列不互相重叠(是值不能有共同元素,但位置可以交错). 两个子序列中的数要 ...
- Ubuntu本地软件源制作
操作 获取需要的deb包 #执行安装后,安装的包会保存在/var/cache/apt/archives 目录下 apt-get install vim #查看 正在处理用于 man-db (2.8.7 ...
- 原型模式(Prototype)---创建型
1 基础知识 定义:原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象.特征:不需要知道任何创建的细节,不调用构造方法.本质:克隆生成对象. 原型模式会要求对象实现一个可以“克隆”自身的接口 ...
- Java项目出现的问题--实际项目01
1 从Excel中导入指纹图谱数据异常 在导入指纹图谱时对Excel的规范是有限制的,有时候报空指针异常是因为虽然有些地方看起来没有内容但是可能有空格键:解决方法是新建一个Excel表,把要用到的 ...
- 部署自己的聊天系统 DuckChat(鸭信)
之前在找一款能自己部署的聊天系统,要求含有手机端APP,最好部署过程能简单点的.看了几款稍嫌麻烦,有的还没有app.今天无意间发现了这款DuckChat,开源免费,有手机APP,部署非常简单.直接上传 ...
- jQuery的入口函数
原生的JS的入口函数指的是:window.onload = function(){}: 如下所示: //原生js的入口函数.页面上所有内容加载完毕, 才执行.//不仅要等文本加载完毕, 而且要等图片也 ...
- Java基础_线程的使用及创建线程的三种方法
线程:线程是操作系统能够进行运算调度的最小单位.它被包含在进程之中,是进程中的实际运作单位.一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务. 进程:进 ...