webpack中bundler源码编写2
const fs = require('fs'); // 帮助我们获取一些文件的信息
const path = require('path'); // 打包的时候需要绝对路径,借助path这个模块
const parser = require('@babel/parser'); // 帮助我们分析代码,引入的文件
const traverse = require('@babel/traverse').default;// 因为是export出来的内容,必须加一个default属性才可以
const babel = require('@babel/core'); // babel的核心模块,转化代码,转化成浏览器认识的代码
// 分析模块
const moduleAnalyser = (filename) => {
// 读取文件内容
const content = fs.readFileSync(filename, 'utf-8');
// 利用parser.parse获取到ast,抽象语法树
const ast = parser.parse(content, {
sourceType: 'module' // 说明是es module的引入方式
});
// 利用traverse对代码进行一个分析
const dependencies = {};
traverse(ast, {
// 只要抽象语法树有ImportDeclaration就会进入这个方法,node是节点
ImportDeclaration({ node }){
// 拿到filename对应的文件夹路径
const dirname = path.dirname(filename);
// 对这个文件夹的路径进行一个转化,将引入的模块转化成相对于bundler的相对路径
const newFile = './' + path.join(dirname, node.source.value);
// 为了方便,把相对路径,绝对路径都存上,key是相对路径,value是绝对路径
dependencies[node.source.value] = newFile;
}
});
// 这个方法可以将抽象语法树转化成浏览器可以运行代码。
const { code } = babel.transformFromAst(ast, null, {
presets: ['@babel/preset-env'] // 把es6语法翻译成es5语法
});
// 返回入口文件和相对应的依赖,都可以分析出来了。
return {
filename,
dependencies,
code
}
}
// 依赖图谱函数,将所有分析好的模块放在这里
const makeDependenciesGraph = (entry) => {
const entryModule = moduleAnalyser(entry);
const graphArray = [entryModule];
// 循环入口文件
for(let i = 0; i < graphArray.length; i++) {
const item = graphArray[i];
const { dependencies } = item;
// 如果该模块有依赖文件,那么就对相应的依赖文件继续进行分析
if(dependencies) {
for(let j in dependencies) {
graphArray.push(moduleAnalyser(dependencies[j]));
}
}
}
// 打印出来,发现所有模块都分析好了。
console.log(graphArray);
}
const graphInfo = makeDependenciesGraph('./src/index.js');
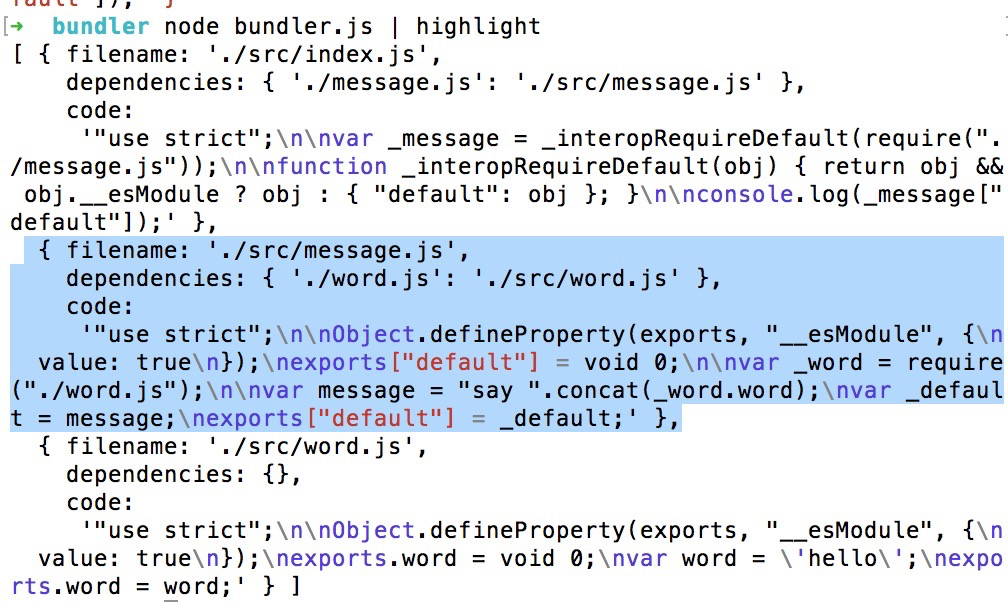
运行node bundler.js | highlight。发现所有模块的文件,依赖和翻译的代码都分析好了打印出来。这个就是我们的依赖图谱。
// 依赖图谱函数,将所有分析好的模块放在这里
const makeDependenciesGraph = (entry) => {
const entryModule = moduleAnalyser(entry);
const graphArray = [entryModule];
// 循环入口文件
for(let i = 0; i < graphArray.length; i++) {
const item = graphArray[i];
const { dependencies } = item;
// 如果该模块有依赖文件,那么就对相应的依赖文件继续进行分析
if(dependencies) {
for(let j in dependencies) {
graphArray.push(moduleAnalyser(dependencies[j]));
}
}
}
const graph = {};
graphArray.forEach(item => {
graph[item.filename] = {
dependencies: item.dependencies,
code: item.code
}
})
console.log(graph);
}

这个时候数组就编程了一个对象。
const fs = require('fs'); // 帮助我们获取一些文件的信息
const path = require('path'); // 打包的时候需要绝对路径,借助path这个模块
const parser = require('@babel/parser'); // 帮助我们分析代码,引入的文件
const traverse = require('@babel/traverse').default;// 因为是export出来的内容,必须加一个default属性才可以
const babel = require('@babel/core'); // babel的核心模块,转化代码,转化成浏览器认识的代码
// 分析模块
const moduleAnalyser = (filename) => {
// 读取文件内容
const content = fs.readFileSync(filename, 'utf-8');
// 利用parser.parse获取到ast,抽象语法树
const ast = parser.parse(content, {
sourceType: 'module' // 说明是es module的引入方式
});
// 利用traverse对代码进行一个分析
const dependencies = {};
traverse(ast, {
// 只要抽象语法树有ImportDeclaration就会进入这个方法,node是节点
ImportDeclaration({ node }){
// 拿到filename对应的文件夹路径
const dirname = path.dirname(filename);
// 对这个文件夹的路径进行一个转化,将引入的模块转化成相对于bundler的相对路径
const newFile = './' + path.join(dirname, node.source.value);
// 为了方便,把相对路径,绝对路径都存上,key是相对路径,value是绝对路径
dependencies[node.source.value] = newFile;
}
});
// 这个方法可以将抽象语法树转化成浏览器可以运行代码。
const { code } = babel.transformFromAst(ast, null, {
presets: ['@babel/preset-env'] // 把es6语法翻译成es5语法
});
// 返回入口文件和相对应的依赖,都可以分析出来了。
return {
filename,
dependencies,
code
}
}
// 依赖图谱函数,将所有分析好的模块放在这里
const makeDependenciesGraph = (entry) => {
const entryModule = moduleAnalyser(entry);
const graphArray = [entryModule];
// 循环入口文件
for(let i = 0; i < graphArray.length; i++) {
const item = graphArray[i];
const { dependencies } = item;
// 如果该模块有依赖文件,那么就对相应的依赖文件继续进行分析
if(Object.getOwnPropertyNames(dependencies).length) {
for(let j in dependencies) {
graphArray.push(moduleAnalyser(dependencies[j]));
}
}
}
const graph = {};
graphArray.forEach(item => {
graph[item.filename] = {
dependencies: item.dependencies,
code: item.code
}
})
return graph;
}
const graphInfo = makeDependenciesGraph('./src/index.js');
console.log(graphInfo);
接下来我们就只要借助dependenciesGraph来生成真正可以在浏览器运行的代码。
const fs = require('fs'); // 帮助我们获取一些文件的信息
const path = require('path'); // 打包的时候需要绝对路径,借助path这个模块
const parser = require('@babel/parser'); // 帮助我们分析代码,引入的文件
const traverse = require('@babel/traverse').default;// 因为是export出来的内容,必须加一个default属性才可以
const babel = require('@babel/core'); // babel的核心模块,转化代码,转化成浏览器认识的代码
// 分析模块
const moduleAnalyser = (filename) => {
// 读取文件内容
const content = fs.readFileSync(filename, 'utf-8');
// 利用parser.parse获取到ast,抽象语法树
const ast = parser.parse(content, {
sourceType: 'module' // 说明是es module的引入方式
});
// 利用traverse对代码进行一个分析
const dependencies = {};
traverse(ast, {
// 只要抽象语法树有ImportDeclaration就会进入这个方法,node是节点
ImportDeclaration({ node }){
// 拿到filename对应的文件夹路径
const dirname = path.dirname(filename);
// 对这个文件夹的路径进行一个转化,将引入的模块转化成相对于bundler的相对路径
const newFile = './' + path.join(dirname, node.source.value);
// 为了方便,把相对路径,绝对路径都存上,key是相对路径,value是绝对路径
dependencies[node.source.value] = newFile;
}
});
// 这个方法可以将抽象语法树转化成浏览器可以运行代码。
const { code } = babel.transformFromAst(ast, null, {
presets: ['@babel/preset-env'] // 把es6语法翻译成es5语法
});
// 返回入口文件和相对应的依赖,都可以分析出来了。
return {
filename,
dependencies,
code
}
}
// 依赖图谱函数,将所有分析好的模块放在这里
const makeDependenciesGraph = (entry) => {
const entryModule = moduleAnalyser(entry);
const graphArray = [entryModule];
// 循环入口文件
for(let i = 0; i < graphArray.length; i++) {
const item = graphArray[i];
const { dependencies } = item;
// 如果该模块有依赖文件,那么就对相应的依赖文件继续进行分析
if(Object.getOwnPropertyNames(dependencies).length) {
for(let j in dependencies) {
graphArray.push(moduleAnalyser(dependencies[j]));
}
}
}
const graph = {};
graphArray.forEach(item => {
graph[item.filename] = {
dependencies: item.dependencies,
code: item.code
}
})
return graph;
}
// 这个函数结合dependenciesGraph来生成最后的代码
const generateCode = (entry) => {
// 拿到生成的 graph对象
const graph = JSON.stringify(makeDependenciesGraph(entry));
/**
* 1、避免污染全局,放在大的闭包里面
* 2、我们看到graph里面的源码有require,export这样的关键字,这个浏览器也是看不懂的,
* 所以如果想去直接去执行每个模块的代码,会报错的。所以首先需要在里面构建require
* 3、localRequire是相对路径转化的函数
*/
return `
(function(graph){
function require(module){
function localRequire(relativePath){
return require(graph[module].dependencies[relativePath])
}
var exports = {};
(function(require, exports, code){
eval(code);
})(localRequire, exports, graph[module].code);
return exports;
};
require('${entry}')
})(${graph});
`;
}
const code = generateCode('./src/index.js');
console.log(code);
webpack中bundler源码编写2的更多相关文章
- webpack中bundler源码编写
新建一个项目,再新建一个src文件夹,里面有三个文件,word.js,message.js,index.js word.js export const word = 'hello'; message. ...
- php中foreach源码分析(编译原理)
php中foreach源码分析(编译原理) 一.总结 编译原理(lex and yacc)的知识 二.php中foreach源码分析 foreach是PHP中很常用的一个用作数组循环的控制语句.因为它 ...
- vue打包时,assets目录 和static目录下文件的处理区别(nodeModule中插件源码修改后,打包后的文件应放在static目录)
为了回答这个问题,我们首先需要了解Webpack如何处理静态资产.在 *.vue 组件中,所有模板和CSS都会被 vue-html-loader 及 css-loader 解析,并查找资源URL.例如 ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- 【原】 Spark中Worker源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Worker源码分析(一)http://www.cnblogs.com/yourarebest/p/5300202.html 4.receive方法, r ...
- Django缓存机制--rest_framework中节流源码使用的就是django提供的缓存api
一.配置缓存 https://www.jb51.net/article/124434.htm 二.缓存全站.页面.局部 三.自我控制的简单缓存API API 接口为:django.core.c ...
- 深入理解 Node.js 中 EventEmitter源码分析(3.0.0版本)
events模块对外提供了一个 EventEmitter 对象,即:events.EventEmitter. EventEmitter 是NodeJS的核心模块events中的类,用于对NodeJS中 ...
- 从 sourcemap 中获取源码
使用 paazmaya/shuji: Reverse engineering JavaScript and CSS sources from sourcemaps 可以从 sourcemap 中获取源 ...
随机推荐
- 【JS新手教程】JS修改css样式的几种方法
本文试验了几种JS修改css样式的方法,方法1:元素.style.样式=样式值.方法2:元素.style.cssText=样式:样式值方法3:元素.style[样式]=样式值 .cssText这种,可 ...
- SpringBoot学习笔记:Redis缓存
SpringBoot学习笔记:Redis缓存 关于Redis Redis是一个使用ANSI C语言编写的免费开源.支持网络.可基于内存亦可以持久化的日志型.键值数据库.其支持多种存储类型,包括Stri ...
- 最新 博盾习言java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿. 博盾习言等10家互联网公司的校招Offer,因为某些自身原因最终选择了 博盾习言.6.7月主要是做系统复习.项目复盘.Le ...
- Google BERT
概述 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不 ...
- 根据SNP的位置从基因组提取上下游序列
代码如下: #!/usr/bin/perl -w use strict; die "perl $0 <vcf> <genome>" if(@ARGV = ...
- poj3348(求凸包面积)
题目链接:https://vjudge.net/problem/POJ-3348 题意:转换题意后即是求凸包的面积. 思路: 套模板,求凸包面积即转换为多个三角形面积之和,用叉积求,然后除2,因为本题 ...
- Python04之数据类型
Python的数据类型主要有四类:整型.浮点型.字符串类型.布尔类型 整型:所有整数都属于整型(长整型和整型) 如:-121,0,765,89,12306 浮点型:数字上有小数点的数 ...
- matplotlib实例笔记
下面的图型是在一幅画布上建立的四个球员相关数据的极坐标图 关于这个图的代码如下: #_*_coding:utf-8_*_ import numpy as np import matplotlib.py ...
- k8s部署nacos
如果是在centos7上直接启动nacos 注意修改启动命令 sh startup.sh -m standalone 访问路径 http://********:8848/nacos/index.h ...
- csredis
源码地址:https://github.com/2881099/csredis 1.增加了 CSRedisClient 现实集群与连接池管理,和 RedisHelper 静态类快速上手 //普通模式 ...