python3 基础二——基本的数据类型三
一.字符串str
1.创建字符串,为变量分配一个值
- word='字符串'
- sentence="字符串\n" #python中单引号和双引号使用完全相同
- paragraph="""这是一个段落
- 可以有多行组成""" #使用三引号('''或""")可以指定一个多行字符串
- print(word,sentence,paragraph)
- ----------------------------------------------------------------------------
- 字符串 字符串
- 这是一个段落
- 可以有多行组成
创建字符串
2.字符串不能改变,只是创建了一个新的字符串,又重新给变量赋值,原字符串并不会改变
3.没有单独的字符类型,一个字符就是长度为 1 的字符串
4.Python 不支持单字符类型,单字符也在Python也是作为一个字符串使用
5.Python2中普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,Python3所有的字符串都是Unicode字符串。
6.Python 访问子字符串,可以使用方括号来截取字符串
- # 字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始
- str='Runoob'
- print(str) # 输出字符串
- print(str[0]) # 输出字符串第一个字符R
- print(str[0:-1]) # 输出第一个到倒数第二个的所有字符,0<=内容<-1
- print(str[2:5]) # 输出从第三个开始到第五个的字符
- print(str[2:]) # 输出从第三个开始的后的所有字符
- print(str[0:]) # 输出所有字符等同于print(str[:])等同于print(str)
- print(str*2) # 输出字符串两次,用 * 运算符重复
- print(str+'你好') # 连接字符串,用 + 运算符连接在一起
- print(str[::2]) # 第一个冒号两侧的数字是指截取字符串的范围,第二个冒号后面是指截取的步长。
- ---------------------------------------------------------------------
- Runoob
- R
- Runoo
- noo
- noob
- Runoob
- RunoobRunoob
- Runoob你好
- Rno
字符串索引切片
7.转义字符以及使用r可以让反斜杠不发生转义
- str='Runoob\n' # 反斜杠 '\'可以用来转义,\n换行
- str2=r'Runoob\n' # 使用r可以让反斜杠不发生转义
- print(str) # 输出字符串
- print(str2)
- ------------------------------------------------------
- Runoob
- Runoob\n
转义
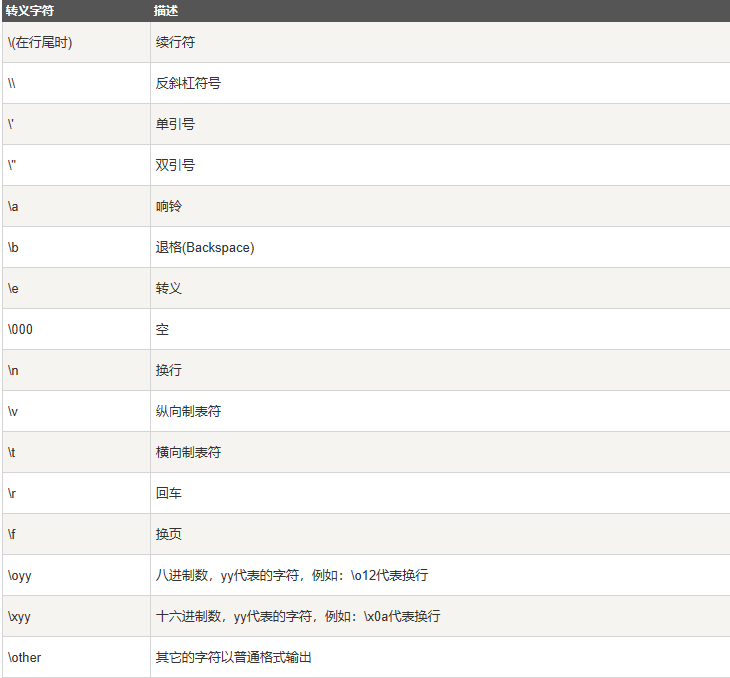
8.字符串运算符
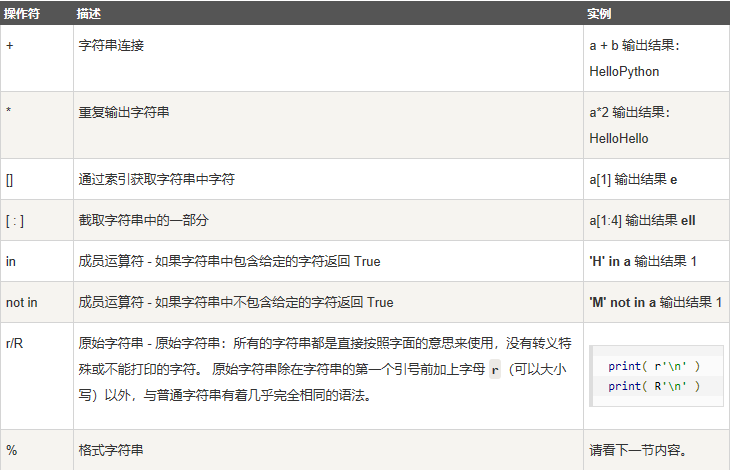
9.字符串格式化:将一个值插入到一个有字符串格式符 %s 的字符串中。还可以用format()进行格式化
- print("我叫 %s 今年 %d 岁"%('小明',10))
- ------------------------------------------
- 我叫 小明 今年 10 岁
字符串格式化
10.占位符
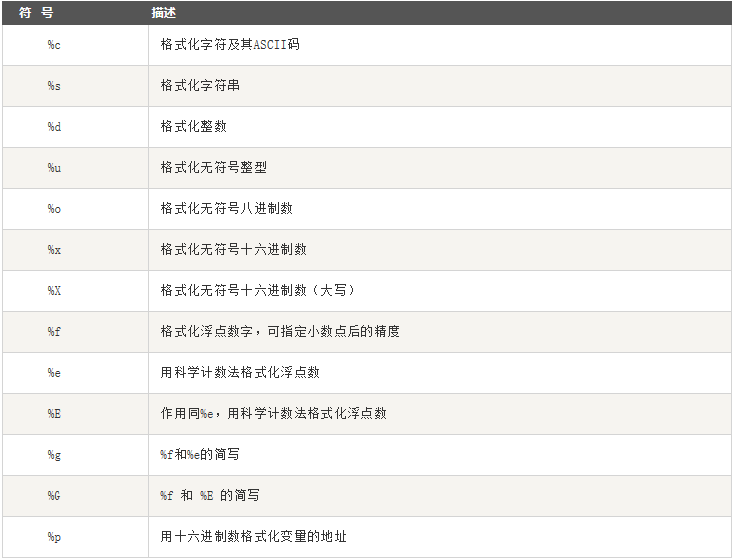
其他:%-左对齐、%+右对齐,%0用0补齐空格
10.编码解码bytes,bytes(在字符串前加b以区分)与str类型只有编码解码的方法不同
- name="李璐"
- for i in name:
- print(i)#for循环每一个元素是“字符”
- print(bytes(i,encoding='utf-8'))#把i转换为字节形式,以16进制表示,字符变字节
- for b in bytes(i,encoding='utf-8'):
- print(b)#for循环输出每一个元素(字节)是以十进制形式
- print(bin(b))#bin()把一个字节(十进制的数)用二进制表示
- #一个汉字三个字节,
- #bytes可以将字符串准换位字节
- #字节:用16进制表示的二进制
- ----------------------------------------------------
- 李
- b'\xe6\x9d\x8e'
- 230
- 0b11100110
- 157
- 0b10011101
- 142
- 0b10001110
- 璐
- b'\xe7\x92\x90'
- 231
- 0b11100111
- 146
- 0b10010010
- 144
- 0b10010000
编码
- #对于字符串只有encode编码功能,把字符串转换为bytes字节类型,16进制字节
- var1 = '你好,世界!'
- print(var1)
- #encode(encoding='UTF-8',errors='strict')以指定的编码格式编码字符串,默认utf-8和strict
- # errors参数可以指定不同的错误处理方案,默认为 'strict',意为编码错误引起一个UnicodeError。
- # 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace','backslashreplace'以及通过codecs.register_error()注册的任何值。
- print(var1.encode())#返回编码后的字符串,它是一个 bytes 对象
- #对于bytes字节类型只有解码功能,把bytes类型转换为字符串
- print(var1.encode().decode())
- --------------------------------------------------------------------------------
- 你好,世界!
- b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8c\xe4\xb8\x96\xe7\x95\x8c!'
- 你好,世界!
编码解码
11.函数
- a1='alex\tis Alph '
- print(len(a1)) #获取字符串长度
- print(a1.capitalize())#首字母变大写
- print(a1.center(20,"*"))#center(self, width, fillchar=None)内容居中,长度设定,其他填充设定
- print(a1.count('al',0,9))#count(self, sub, start=None, end=None)计算指定范围内子序列出现的次数
- print(a1.encode('utf-8'))#encoding 指定的编码格式解码 str
- print(a1.endswith('l',0,2))#endswith(self, suffix, start=None, end=None)指定范围内是否以XXX结尾
- print(a1.expandtabs())#将tab转换成空格,默认一个tab转换成8个空格
- print(a1.find('ex'))#find(self, sub, start=None, end=None)从左往右在指定范围寻找子序列位置,如果没找到,返回 -1
- print(a1.format())#字符串格式化,动态参数
- print(a1.index('a'))#在指定范围寻找子序列位置,子序列位置,如果没找到,报错
- print(a1.isalnum())#是否全是字母和数字
- print(a1.isalpha())#是否全是字母
- print(a1.isdigit())#是否全是数字
- print(a1.islower())#是否小写
- print(a1.isspace())#是否空格
- print(a1.istitle())#是否标题,首字母全大写
- print(a1.isupper())#是否全部大写
- print('-'.join(a1))#个个单位之间用符号连接
- print(a1.join(''))#字符串之间链接
- print(a1.ljust(20,'*'))#内容左对齐,右侧填充
- print(a1.lower())#变小写
- print(a1.strip())#去除两边空格
- print(a1.partition('s'))#分割,前,中,后三部分
- print(a1.replace('l','kb',2))#替换,从左往右几个
- print(a1.split('l',1))#分割,有几个分几部分,可以指定几个分割
- print(a1.startswith('a'))#startswith(self, prefix, start=None, end=None)是否起始
- print(a1.splitlines())#根据换行分割
- print(a1.swapcase())#大写变小写,小写变大写
- print(a1.title())#标题化
- print(a1.upper())#全大写
- --------------------------------------------------------------------------------------
- 13
- Alex is alph
- ***alex is Alph ****
- 1
- b'alex\tis Alph '
- True
- alex is Alph
- 2
- alex is Alph
- 0
- False
- False
- False
- False
- False
- False
- False
- a-l-e-x- -i-s- -A-l-p-h-
- 3alex is Alph 3alex is Alph 3alex is Alph 3alex is Alph 3alex is Alph 3
- alex is Alph *******
- alex is alph
- alex is Alph
- ('alex\ti', 's', ' Alph ')
- akbex is Akbph
- ['a', 'ex\tis Alph ']
- True
- ['alex\tis Alph ']
- ALEX IS aLPH
- Alex Is Alph
方法
12.str
(1)一般函数:startswith、endwith、count、find...
(2)判断字符串:islower、isupper、isdigit、isalpha...
(3)操作类函数:lower、upper、strip/rstrip/lstrip、swapcase(交换大小写)...
13.字符串函数分类:
(1).查找计算:len、find、rfind、index、rindex、count
(2).转换:replace、capitalize、title、lower、upper、
(3).填充压缩:ljust、rjust、center、lstrip、rstrip
(4).分割拼接:split、partition、rpartition、splitlines、join
(5).判定:isalpha、isdigit、isalnum、isspace、startswith、endswith、


二.序列
1.序列是Python中最基本的数据结构
2.序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。每个索引对应一个元素,最后一个索引是-1
3.Python包含6种内建的序列,包括列表、元组、字符串、Unicode字符串、buffer对象和xrange对象
4.序列通用操作:索引,切片,加,乘,成员检查,计算序列的长度,取序列中的最大、最小值
5.索引:获取单个元素[ ];切片:获取子序列[ : ];加:连接相同序列+;乘:重复序列中所有的元素*;成员检查in;计算长度len();取最大最小值max(),min()
6.索引和切片是不同的:比如list[0]返回第0个元素的值,list[0:1]返回一个只含第0个元素的列表
7.序列的遍历
(1)在字典中遍历时,关键字和对应的值可以使用 items() 方法同时解读出来
(2)在序列中遍历时,索引位置和对应值可以使用 enumerate() 函数同时得到,以0开始
(3)同时遍历两个或更多的序列,可以使用 zip() 组合
(4)要反向遍历一个序列,首先指定这个序列,然后调用 reversed() 函数
(5)要按顺序遍历一个序列,使用 sorted() 函数返回一个已排序的序列,并不修改原值
- #zip()遍历多个序列
- questions = ['name', 'quest', 'favorite color']
- answers = ['lancelot', 'the holy grail', 'blue']
- for q, a in zip(questions, answers):
- print('What is your {0}? It is {1}.'.format(q, a))
- #enumerate() 函数同时得到索引和值
- for i, v in enumerate(['tic', 'tac', 'toe']):
- print(i, v)
- #reversed() 函数反向遍历
- for i in reversed(range(1, 10, 2)):
- print(i)
- #sorted() 函数 顺序遍历
- basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
- for f in sorted(set(basket)):
- print(f)
- ------------------------------------------------------------------------------
- What is your name? It is lancelot.
- What is your quest? It is the holy grail.
- What is your favorite color? It is blue.
- 0 tic
- 1 tac
- 2 toe
- 9
- 7
- 5
- 3
- 1
- apple
- banana
- orange
- pear
遍历
8.序列的切片和拼接操作可以实现形式上的序列的更新和删除
三.列表
1.创建列表
- #列表,方括号内,逗号分隔
- # 创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可
- list1=['a','goole',1995,""]#列表可包含任何数据类型的元素,单个列表中的元素无须全为同一类型
- print(list1)
- --------------------------------------------------------------
- ['a', 'goole', 1995, '']
创建列表
2.列表作为一个序列,有序列的通用功能:索引,切片,加,乘,成员检查,计算序列的长度,取序列中的最大、最小值
- list1=['a','goole',1995,""]#列表可包含任何数据类型的元素,单个列表中的元素无须全为同一类型
- print(list1)
- print(list1[0]) #列表索引从0开始
- print(list1[1:5]) #使用方括号的形式截取字符成一个子列表,冒号使用和字符串中一样
- list1[2]=2001 #直接赋值对列表的数据项进行修改或更新,
- print(list1)
- del list1[2] #del语句删除列表的元素
- print(list1)
- print(len(list1)) #len()表示列表的长度
- print(list1+[1,2,3]) #+组合,拼接列表
- print(list1*2) #*重复
- print('a' in list1) #in元素是否存在于列表中
- for i in list1:
- print(i,end=' ') #迭代
- ------------------------------------------------------------------------------
- ['a', 'goole', 1995, '']
- a
- ['goole', 1995, '']
- ['a', 'goole', 2001, '']
- ['a', 'goole', '']
- 3
- ['a', 'goole', '', 1, 2, 3]
- ['a', 'goole', '', 'a', 'goole', '']
- True
- a goole 2000
序列通用功能
3.嵌套列表
- #嵌套
- a = ['a', 'b', 'c']
- n = [1, 2, 3]
- x = [a, n]
- print(x)
- print(x[0])
- print(x[0][1])
- ----------------------------------------
- [['a', 'b', 'c'], [1, 2, 3]]
- ['a', 'b', 'c']
- b
列表嵌套
4.列表元素可以通过直接赋值对列表的数据项进行修改或更新
5.列表末尾添加元素:append and extend,其中append(一个元素),extend(多个元素)(多个元素以列表显示)
- #append and extend
- list1=['google',1995,"Tabo"]
- list1.append('baidu') #调用append()方法向列表的尾部添加一个新的元素,只能一个元素
- print(list1) #输出更新后的list1
- list1.extend(['','baidu ']) #list.extend(seq), seq -- 元素列表
- list1.extend(range(5)) #只能是单个元素或单个列表
- print(list1) #调用extend()函数在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
- # 列表是以类的形式实现的。"创建"列表实际上是将一个类实例化。因此,列表有多种方法可以操作。
- # extend()方法只接受一个列表作为参数,并将该参数的每个元素都添加到原有的列表中。
- -------------------------------------------------------------------------------------
- ['google', 1995, 'Tabo', 'baidu']
- ['google', 1995, 'Tabo', 'baidu', '', 'baidu ', 0, 1, 2, 3, 4]
append and extend
6.在指定位置插入元素insert
- age=[1,2,3,5,6,7]
- age.insert(3,4)
- #本来序号 3 的位置是5
- #插入 4
- #后面的元素向后移
- print(age)
- ----------------------------------------------------
- [1, 2, 3, 4, 5, 6, 7]
insert
7.删除元素:pop and remove,其中pop(按索引弹出列表中的某个值),remove(根据值删除第一个指定的元素,如果要删除的元素有多个,可以使用循环)
- #移除pop and remove
- list1=['google',1995,"Tabo",'','baidfu',3332]
- list1.pop() #pop()函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
- print(list1)
- list1.remove(1995)#remove()函数用于移除列表中某个值的第一个匹配项
- print(list1) #该方法没有返回值但是会移除列表中的某个值的第一个匹配项。
- --------------------------------------------------------------------------------------------
- ['google', 1995, 'Tabo', '', 'baidfu']
- ['google', 'Tabo', '', 'baidfu']
pop and remove
8.永久性组织列表:reverse and sort,其中reverse反转列表,sort排序列表(默认数字从小到大,字符串首字母从a到z)
- #排序reverse and sort
- list1=['google','',"Tabo",'','baidfu','']
- list1.reverse() #reverse() 函数用于反向列表中元素
- print(list1) #该方法没有返回值,但是会对列表的元素进行反向排序。
- list1.sort() #sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。
- print(list1) #sort排序必须列表中的元素要是同一类型
- ------------------------------------------------------------------------------
- ['', 'baidfu', '', 'Tabo', '', 'google']
- ['', '', '', 'Tabo', 'baidfu', 'google']
排序reverse and sort
补充:
- #sort(self, key=None, reverse=False)
- #sort默认从小到大(reverse=False)
- #reverse=True则改为从大到小
- l=[2,4,5,7,3,5,9,2,4]
- l.sort(reverse=True)#从大到小
- print(l)
- ---------------------------------------------
- [9, 7, 5, 5, 4, 4, 3, 2, 2]
sort(reverse=True)
*sorted函数:临时排序,不改变列表的排序顺序
- a1=[5,6,5,91,1,64,]
- print(a1)
- a2=sorted(a1)#sorted函数排序列表,但不改变列表
- print(a2)#排序后的列表
- print(a1)#列表本身没有改变
- ------------------------------------------------------------------
- [5, 6, 5, 91, 1, 64]
- [1, 5, 5, 6, 64, 91]
- [5, 6, 5, 91, 1, 64]
sorted
9.复制copy(创建新列表并引用,相当于所有切片[:]+赋值=)和赋值(引用原来的对象)
- # 使用=直接赋值,是引用赋值,更改一个,另一个同样会变, 例子中的a,b改变两次都影响到了对方
- # copy() 则顾名思义,复制一个副本,原值和新复制的变量互不影响 「a,c」
- a=[0,1,2,3,4,5]
- b=a
- c=a.copy()
- del a[1]
- print(id(a),id(b),id(c))#copy后内存地址不同
- print(a,b,c)
- b.remove(4)
- print(a,b,c)
- c.append(9)
- print(a,b,c)
- ---------------------------------------------------
- 91198088 91198088 91198528
- [0, 2, 3, 4, 5] [0, 2, 3, 4, 5] [0, 1, 2, 3, 4, 5]
- [0, 2, 3, 5] [0, 2, 3, 5] [0, 1, 2, 3, 4, 5]
- [0, 2, 3, 5] [0, 2, 3, 5] [0, 1, 2, 3, 4, 5, 9]
copy
补充:
- a=[2,4,5,7,3,5,9,2,4]
- a2=a[:]#把列表重新拷贝一份,再把它赋值a2,a2和a不一样
- a3=a #把a3指向a,相当于给a指向的列表又贴上a3这个标签,a3和a完全一样
- print(a,a2,a3,sep='\n')
- print(id(a),id(a2),id(a3))
- a.sort()
- print(a,a2,a3,sep='\n')
- ---------------------------------------------
- [2, 4, 5, 7, 3, 5, 9, 2, 4]
- [2, 4, 5, 7, 3, 5, 9, 2, 4]
- [2, 4, 5, 7, 3, 5, 9, 2, 4]
- 89328216 89329256 89328216
- [2, 2, 3, 4, 4, 5, 5, 7, 9]
- [2, 4, 5, 7, 3, 5, 9, 2, 4]
- [2, 2, 3, 4, 4, 5, 5, 7, 9]
拷贝
10.其他
- list1=['google',1995,"Tabo",'','baidfu',3332]
- print(list1.count('')) #count()方法用于统计某个元素在列表中出现的次数。
- print(list1.index(1995)) #index()函数用于从列表中c从左往右找出某个值第一个匹配项的索引位置。
- # print(list1.index(7)) 如果没有找到对象则抛出异常
- list1.insert(1,'baidu') #insert()函数用于将指定对象插入列表的指定位置。
- print(list1)
- list1.copy() #copy() 函数用于复制列表,类似于 a[:]。
- print(list1)
- list1.clear() #clear()函数用于清空列表,类似于 del a[:]。
- print(list1) #返回空列表
- #d=a[:] 对于单一列表一般情况下复制得到一个新列表并改变新列表内元素而不影响原列表。
- list_empty = [None]*10
- print(list_empty)
- -------------------------------------------------------
- 0
- 1
- ['google', 'baidu', 1995, 'Tabo', '', 'baidfu', 3332]
- ['google', 'baidu', 1995, 'Tabo', '', 'baidfu', 3332]
- []
- [None, None, None, None, None, None, None, None, None, None]
其他
(列表推导式(列表解析):各语句之间是嵌套关系,左边第二个语句是最外层,依次往右进一层)[有关A的表达式 for A in B]
- # i=list()/i=[]创建空列表
- print([i for i in range(10)])
- #输出一个列表,对于range(10)中的每一个元素i,输出i,添加到列表
- print([i*i for i in range(10)])
- ##输出一个列表,对于range(10)中的每一个元素i,把i平方,添加到列表
- print([i*i for i in range(10)if i%2==0])
- #输出一个列表,对于range(10)中的每一个满足条件是偶数的元素i,把i平方,添加到列表
- print([1 if x%2==0 else -1 for x in range(10)])
- #输出一个列表,列表满足:对于在range(10)中的每一个元素x,判断是否是偶数,如果是输出1,否则输出-1
- #相当于print([i for i in range(10)])
- # for j in range(10):
- # i.append(j)
- # print(i)
- --------------------------------------------------------------------
- [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
- [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
- [0, 4, 16, 36, 64]
- [1, -1, 1, -1, 1, -1, 1, -1, 1, -1]
其他
11.补充
(1)标准的python中列表保存一组值,实际上保存的是对象的指针,可以指向任何对象,即列表的元素可以是任何对象
(2)将列表当做堆栈使用,append添加,pop移除
(3)可以把列表当做队列用,只是在队列里第一加入的元素,第一个取出来,append添加,popleft移除
12.列表
(1).增:append、extend、insert
(2).删:del语句、pop、remove
(3).改:直接赋值改
(4).查:index、count
(5).其他:排序:sorted、反转:reverse
四.元组
1.Python 的元组与列表类似,不同之处在于元组的元素不能添加、删除或修改,但元素的元素可变
2.元组也是一组逗号隔开的序列,一般使用小括号()括起来或直接用逗号隔开,表现出来的形式都是用小括号括起的序列;当仅有一个元素表示元组时,必须加逗号,否则括号会被当做运算符使用
- a1=1#只有一个元素,表示创建一个int类型(或str类型)的元素
- print(a1,type(a1))
- a2=1,#不仅有一个元素,还有逗号,表示创建的是元组类型
- print(a2,type(a2))
- a3=(1)#虽然用括号括起,但只有一个元素,表示创建一个int类型(或str类型)的元素
- print(a3,type(a3))
- a4=(1,)#不但用括号括起,还有逗号,表示创建的是元组类型
- print(a4,type(a4))
- a5=2,3,4#虽然没有用括号括起,但它是用逗号隔开的一组元素,默认创建一个元组
- print(a5,type(a5))
- a6=(2,3,4)#既用括号括起,括号中又包含逗号,表示创建的是源自
- print(a6,type(a6))
- a7=()#创建空元组,用空括号表示
- print(a7,type(a7))
- -----------------------------------------------------------------------------------
- 1 <class 'int'>
- (1,) <class 'tuple'>
- 1 <class 'int'>
- (1,) <class 'tuple'>
- (2, 3, 4) <class 'tuple'>
- () <class 'tuple'>
元组的创建
3.元组
- tuple1=('google')
- print(type(tuple1))#不加逗号,被当成字符串或整型
- tuple2=('google',)
- print(type(tuple2))#元组中只包含一个元素时,需要在元素后面添加逗号
- tup1=('goole',1997,'',"runboon")
- print(tup1[2]) #元组可以使用下标索引来访问元组中的值
- print(tup1[1:3])#切片
- #元组中的元素值是不允许修改的,比如赋值是不可操作的,但我们可以对元组进行连接组合,del删除,
- tup2=(12,33)
- print(tup1+tup2) #+拼接
- del tup2 #del删除
- #count(计数) index(索引查找)
- --------------------------------------------------------------------
- <class 'str'>
- <class 'tuple'>
- 1203
- (1997, '')
- ('goole', 1997, '', 'runboon', 12, 33)
元组
4.元组仅有两个方法:count()和index()
- tup1=('goole',1997,'',"runboon",1997,1997)
- #计算并返回指定元素的数量
- print(tup1.count(1997))
- #寻找并返回参数索引值
- print(tup1.index(1997))
- ----------------------------------------
- 3
- 1
count和index
5.元组与列表相互转换
- aTuple=(123,'goole',"taobaoo")
- print(aTuple)
- print(list(aTuple)) #将元组转换为列表,元素相对应
- str="hello world"
- print(list(str)) #将字符串转换为列表,元素相对应
- ----------------------------------------------------------------------------
- (123, 'goole', 'taobaoo')
- [123, 'goole', 'taobaoo']
- ['h', 'e', 'l', 'l', 'o', ' ', ' ', 'w', 'o', 'r', 'l', 'd']
相互转换
6.元组的‘更新’和‘元组元素的删除’,实质上删除了整个元组,又重新创建了一个元组
- a=('xi','',14324,'')
- print(a,id(a))
- a=a[:2]+('s',)+a[2:]
- #元组的元素不能删除或修改
- #序列有切片和拼接操作
- #实质上是:先把a的前两位拿出来,再把a的后面元素拿出来,
- #再与要插入的元组进行拼接,形成一个新的元组,并把它赋值给a
- #a本来指向远离的元组,操作后让a指向一个新元组,实现形式上的更新
- print(a,id(a))
- -----------------------------------------------------
- ('xi', '', 14324, '') 81034384
- ('xi', '', 's', 14324, '') 80194368
’更新‘
- #元组可以用del函数来删除整个元组,但元组中的元素不能直接删除
- #类似元组的更新,元组中的元素也可以使用切片拼接操作进行形式上的删除
- a=('xi','',14324,'')
- print(a,id(a))
- a=a[:1]+a[1:]
- print(a,id(a))
- ----------------------------------------------------------
- ('xi', '', 14324, '') 46759056
- ('xi', '', 14324, '') 82679008
’元组元素的删除‘
7.元组和列表
希望内容不被轻易改写时,用元组;当我们需要频繁修改数据,我们使用列表
8.元组的可以直接赋值给多个变量,但变量数必须与元素数量一致
五.字典
1.字典是另一种可变容器模型,且可存储任意类型对象,字典不是序列
2.字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中
3.键必须是唯一的,但值则不必,值可以取任何数据类型,但键必须是不可变的数据类型,如字符串,数字或元组
4.字典,添加和更新都通过赋值来操作
- dict1={
- 'Alice':'',#键必须是唯一的,但值则不必。
- 'Celf':8, #值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
- 333:('sc','ss'),
- }
- print(dict1)
- print(dict1['Alice'])#把相应的键放入熟悉的方括弧,访问字典里的值
- # print(dict1['s'])如果用字典里没有的键访问数据,会输出错误
- dict1['name']='alex' #赋值添加信息
- dict1['Celf']=100 #赋值更新
- print(dict1)
- del dict1['name'] # 删除键 'name'
- print(dict1)
- dict1.clear() # 清空字典
- print(dict1)
- # del dict1 # 删除字典,可能会引发异常
- ------------------------------------------------------------------------------------
- {'Alice': '', 'Celf': 8, 333: ('sc', 'ss')}
- 2341
- {'Alice': '', 'Celf': 100, 333: ('sc', 'ss'), 'name': 'alex'}
- {'Alice': '', 'Celf': 100, 333: ('sc', 'ss')}
- {}
字典
5.字典内置函数
- # 字典内置函数len()(计算键总数) str(dict) type(variable)
- dict1={
- 'Name': 'Runoob',
- 'Age': 7,
- 'Class': 'First'
- }
- print(dict1)
- print(len(dict1)) #计算字典元素个数,即键的总数
- print(str(dict1)) #输出字典,以可打印的字符串表示。
- print(type(dict1)) #返回输入的变量类型,
- ---------------------------------------------------------
- {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
- 3
- {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
- <class 'dict'>
字典内置函数
6.字典键和值的特性
(1)字典键必须是可哈希(Hash)的对象,不能是可变类型,必须为不可变对象
(2)键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
(3)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住
(4)字典值可以是任何的 python 对象,既可以是标准的对象,也可以是用户定义的
(5)字典的键值是"只读"的,所以不能对键和值分别进行初始化
7.dict函数
- #dict函数
- dict1={
- 'Name': 'Runoob',
- 'Age': 7,
- 'Class': 'First'
- }
- print(dict1.copy()) #Python 字典 copy() 函数返回一个字典的浅复制。
- print(dict1.fromkeys(('name','age','sex','s'),10))#创建一个新字典,改变键和值,旧字典不变
- print(dict1.get('name')) #get() 函数返回指定键的值,如果值不在字典中返回默认值
- if 'Age' in dict1: # in 操作符用于判断键是否存在于字典中
- print('zai')
- print(dict1.setdefault('age'))#如果键不存在于字典中,将会添加键并将值设为默认值。相当于get()
- print(dict1.items()) #items() 方法以列表返回可遍历的(键, 值) 元组数组。
- for i,j in dict1.items():
- print(i, ":\t", j)
- print(dict1.keys()) # keys()方法以列表返回一个字典所有的键
- print(list(dict1.keys())) #若要返回列表值还需调用list函数。
- print(dict1.values()) #values()方法以列表返回字典中的所有值。
- dict1.update({'Sex':'female'})#update()函数把字典dict2的键/值对更新到dict里。
- print(dict1)
- dict1.pop('Name') #pop()删除字典给定键key所对应的值,返回值为被删除的值。key值必须给出。
- print(dict1)
- print(dict1.popitem()) #popitem()随机返回并删除字典中的一对键和值(一般删除末尾对)
- print(dict1)
- ------------------------------------------------------------------------------
- {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
- {'name': 10, 'age': 10, 'sex': 10, 's': 10}
- None
- zai
- None
- dict_items([('Name', 'Runoob'), ('Age', 7), ('Class', 'First'), ('age', None)])
- Name : Runoob
- Age : 7
- Class : First
- age : None
- dict_keys(['Name', 'Age', 'Class', 'age'])
- ['Name', 'Age', 'Class', 'age']
- dict_values(['Runoob', 7, 'First', None])
- {'Name': 'Runoob', 'Age': 7, 'Class': 'First', 'age': None, 'Sex': 'female'}
- {'Age': 7, 'Class': 'First', 'age': None, 'Sex': 'female'}
- ('Sex', 'female')
- {'Age': 7, 'Class': 'First', 'age': None}
dict函数
8.字典推导式
- # 字典生成式
- zifu='beijing'
- print({letter:zifu.count(letter) for letter in zifu})
- #对于zifu中的元素letter,生成一个字典,键是letter元素,只是出现的个数
- -----------------------------------------------------------------------------------
- {'b': 1, 'e': 1, 'i': 2, 'j': 1, 'n': 1, 'g': 1}
字典生成式
9.列表中字典按键排序
- #适用于列表中字典都存在某一键
- a=[{'xuhao':34,'age':27},
- {'xuhao':21,'age':62},
- {'xuhao':2,'age':19},
- {'xuhao':35,'age':66}]
- a.sort(key=lambda x:x['xuhao'])
- print(a)
- -----------------------------------------------
- [{'xuhao': 2, 'age': 19}, {'xuhao': 21, 'age': 62}, {'xuhao': 34, 'age': 27}, {'xuhao': 35, 'age': 66}]
sort
10.把两个列表变成一个字典
- a=[1,2,3,4,5]
- b=['a','b','c','d']
- c=dict(zip(a,b))
- print(c)
- ----------------------------------------
- {1: 'a', 2: 'b', 3: 'c', 4: 'd'}
合并列表为字典
11.和list相比,dict的特点:(1)查找和插入的速度极快,不会随着key的增加而变慢;(2)需要占用大量的内存,内存浪费多。
12.嵌套:(1)字典列表(2)字典中存储列表(值)(3)字典中存储字典(值)
13.总结字典的操作
(1).增:dict[key]=value(赋值)
(2).删:del语句、pop、popitem、clear
(3).改:(只能改值)赋值改、updata
(4).查:get、setdefault、values、keys、items
六.集合
1.集合是一个无序不重复元素的集合
2.可以使用大括号 { } 或者 set() 函数创建集合
3.set()可变集合、frozenset()不可变集合
4.创建空集合时,使用set()或frozenset()不能使用s={},因为 { } 是用来创建一个空字典
5.基本功能是进行成员关系测试和删除重复元素;元素为不可变类型,不能修改,
6.集合和字典的存储方式一样,集合中的元素必须是可哈希的值,如果元素重复出现,则会合并为一个
7.集合可以通过for in进行遍历,可以通过迭代器进行访问
8.成员关系测试和集合运算
- student = {'Tom', 'Jim', 'Mary', 'Tom', 'Jack', 'Rose'}
- print(student) # 输出集合,重复的元素被自动去掉
- #成员测试
- if('Rose' in student) :
- print('Rose 在集合中')
- else :
- print('Rose 不在集合中')
- ----------------------------------------------------------------------------
- {'Rose', 'Tom', 'Mary', 'Jack', 'Jim'}
- Rose 在集合中
成员测试
- # set可以进行集合运算
- a = set('abracadabra')
- b = set('alacazam')
- print(a)
- print(a - b) # a和b的差集
- print(a | b) # a和b的并集
- print(a & b) # a和b的交集
- print(a ^ b) # a和b中不同时存在的元素
- ---------------------------------------------------------------------------------
- {'r', 'b', 'd', 'c', 'a'}
- {'d', 'r', 'b'}
- {'r', 'b', 'm', 'd', 'c', 'a', 'z', 'l'}
- {'c', 'a'}
- {'r', 'z', 'm', 'b', 'l', 'd'}
集合运算
9.集合对比字典:集合相当于一组key的集合,但不存储value。由于key不能重复,所以在set中,没有重复的key
10.集合的函数
add增加;discard删除;remove删除;pop随机删除;clear清空集合;intersection交集;union并集;updata更新;difference差集;difference_updata差集;
isdisjoint不相交;issuperset包含;issubset包含于

七.Python数据类型转换

八.可变对象和不可变对象
1.python中一切都是对象,通过变量标识来引用一个对象,对象为数据时,由于python中定义了数据的类型,所以可以称某种数据类型的对象,
2.对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,保证了不可变对象本身永远是不可变的。
对于可变对象来说,调用对象自身的任意方法,会改变该对象自身的内容
3.python中的不可变数据类型:整型、浮点型、布尔值、字符串、元组。
python中的可变数据类型:列表、字典
4.Python中的字符串不能改变;列表中的元素是可以改变的;元组的元素不能修改,但它可以包含可变的对象,比如list列表;字典可以被修改
5.对于可变数据类型,a=a+a和a+=a的不同:前一个是生成(赋值)一个新的内存,后一个在原有的基础上修改
python3 基础二——基本的数据类型三的更多相关文章
- python3 基础二——基本的数据类型二
一.数字(Number) 1.Python支持三种不同的数值类型:整型(int),浮点型(float),复数(complex) 2.Python数字数据类型用于存储数值 3.数据类型是不允许改变的,这 ...
- python3 基础二——基本的数据类型一
一.基本的数据类型 Python3 中有六个标准的数据类型Number(数字). String(字符串). List(列表) .Tuple(元组). Sets(集合) .Dictionary(字典) ...
- Java基础(二) 基本类型数据类型、包装类及自动拆装箱
我们知道基本数据类型包括byte, short, int, long, float, double, char, boolean,对应的包装类分别是Byte, Short, Integer, Long ...
- python3基础(二)
loops循环语句 一 if语句,if语句配合else使用,可以没有else. 单分支if语句 age = input('Age:') password = '67' if age == passwo ...
- python开发基础(二)-运算符以及数据类型
##运算符 算数运算符: ---> 赋值运算符 >>>返回结果为值 + # 加 - # 减 * # 乘 / # 除以 ** # 幂运算 % # 取余数 // # 取商 #### ...
- Python3基础 二、八、十、十六进制数的定义
Python : 3.7.3 OS : Ubuntu 18.04.2 LTS IDE : pycharm-community-2019.1.3 ...
- Python3基础 二、八、十、十六进制转换
Python : 3.7.3 OS : Ubuntu 18.04.2 LTS IDE : pycharm-community-2019.1.3 ...
- redis基础二----操作set数据类型
set集合是无序的,不能存在重复元素 bbb吃重复元素,是不能添加成功的 2 接下来分析zset,是有序的,你在添加的时候要指定元素的序列号 上面的 3 4 5 6 就是指定的元素的序列号 withs ...
- python开发基础(二)运算符以及数据类型之bool(布尔值))
# encoding: utf-8 # module builtins # from (built-in) # by generator 1.147 """ Built- ...
随机推荐
- spring boot 2.x版本:java.lang.ClassNotFoundException: org.springframework.boot.bind.RelaxedDataBinder
标题 ##搭建spring boot 2.0.3版本 使用alibaba的druid数据库连接池,com.github.pagehelper的分页插件,启动项目报错. 错误提示:java.lang.C ...
- python中传统除法、真除法和Floor除法
1.python2.6及其之前,x/y是传统除法,对于整数会省去小数部分,对于浮点数会保持小数部分. 2.python3中x/y表示真除法,无论任何数据类型都会保留小数部分. 3.python2和3中 ...
- JVM OOM异常会导致JVM退出吗?
出处: https://mp.weixin.qq.com/s/8j8YTcr2qhVActLGzOqe7Q https://blog.csdn.net/h2604396739/article/de ...
- S04_CH01_搭建工程移植LINUX/测试EMMC/VGA
S04_CH01_搭建工程移植LINUX/测试EMMC/VGA 1.1概述: 本章内容是在已经提供安装了VIVADO2015.4 的ubuntu系统下,进行.大家可以下周我们已经提供的虚拟机镜像,我们 ...
- LOJ6583 ICPC World Finals 2019何以伊名始(广义后缀自动机)
对trie建SAM,询问串倒过来跑到的节点的|right|即为答案. #include<bits/stdc++.h> using namespace std; #define ll lon ...
- hdu 2647 还是逆向拓扑
Problem Description Dandelion's uncle is a boss of a factory. As the spring festival is coming , he ...
- hdu 4496 其实还是并查集
Problem Description Luxer is a really bad guy. He destroys everything he met. One day Luxer went to ...
- (三)easyUI之树形组件
一.同步树 1.1 概念 所有节点一次性加载完成 1.2 案例 1.2.1 数据库设计 1.2.2 编码 index.jsp <%@ page language="java" ...
- Asp.Net Core 2.0 之旅---@Html.Action
原文:Asp.Net Core 2.0 之旅---@Html.Action 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https: ...
- 使用IP代理初体验
在很多时候我们需要用到IP代理,比如爬虫.投票等 封IP是一种很常用的办法,所谓道高一尺.魔高一丈,IP代理应运而生 最简单的一段代码 static void Main(string[] args) ...