Adam作者大革新, 联合Hinton等人推出全新优化方法Lookahead
Adam作者大革新, 联合Hinton等人推出全新优化方法Lookahead

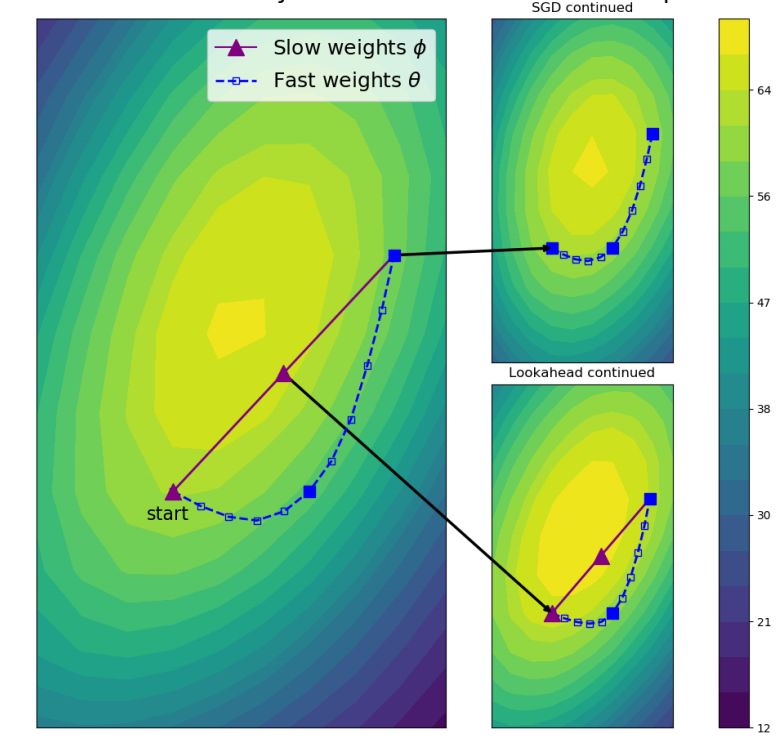


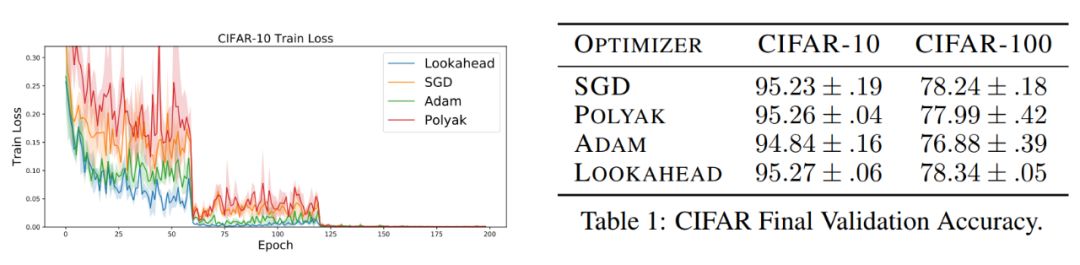


Adam作者大革新, 联合Hinton等人推出全新优化方法Lookahead的更多相关文章
- DevExpress ChartControl大数据加载时有哪些性能优化方法
DevExpress ChartControl加载大数据量数据时的性能优化方法有哪些? 关于图表优化,可从以下几个方面解决: 1.关闭不需要的可视化的元素(如LineMarkers, Labels等) ...
- 大数据量高并发访问SQL优化方法
保证在实现功能的基础上,尽量减少对数据库的访问次数:通过搜索参数,尽量减少对表的访问行数,最小化结果集,从而减轻网络负担:能够分开的操作尽量分开处理,提高每次的响应速度:在数据窗口使用SQL时,尽量把 ...
- 深度学习常见的优化方法(Optimizer)总结:Adam,SGD,Momentum,AdaGard等
机器学习的常见优化方法在最近的学习中经常遇到,但是还是不够精通.将自己的学习记录下来,以备不时之需 基础知识: 机器学习几乎所有的算法都要利用损失函数 lossfunction 来检验算法模型的优劣, ...
- Hinton等人最新研究:大幅提升模型准确率,标签平滑技术到底怎么用?
Hinton等人最新研究:大幅提升模型准确率,标签平滑技术到底怎么用? 2019年07月06日 19:30:55 AI科技大本营 阅读数 675 版权声明:本文为博主原创文章,遵循CC 4.0 B ...
- Hinton等人新研究:如何更好地测量神经网络表示相似性
Hinton等人新研究:如何更好地测量神经网络表示相似性 2019年05月22日 08:39:15 喜欢打酱油的老鸟 阅读数 177更多 分类专栏: 人工智能 https://www.toutia ...
- 光环国际联合阿里云推出“AI智客计划”
2018阿里巴巴云栖大会深圳峰会3月28日.29日在大中华喜来登酒店举行,阿里云全面展示智能城市.智能汽车.智能生活.智能制造等产业创新. 3月28日下午,以"深化产教融合,科技赋能育人才& ...
- 移动终于hold不住了 联合微信正式推出流量红包业务
微信的迅猛发展终于让中移动hold不住了,今日移动广东分公司联合微信正式推出流量红包业务,流量红包分为1元10M(10个整售).3元50M(5个整售)两种.广东的微信朋友有福了,赶紧去抢红包吧!微信& ...
- 机器学习优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
SGD: 此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mi ...
- 优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam)
优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam) 2019年05月29日 01:07:50 糖葫芦君 阅读数 455更多 ...
随机推荐
- 「CSA Round #41」BFS-DFS
题目链接 戳我 \(Description\) 给出一个图的\(bfs\)序和\(dfs\)序,构造出一个满足条件的图,边的扫描顺序为读入顺序 \(Solution\) 这个题还是很简单的. 先来看看 ...
- canvas基础知识点(一)
给canvas设置宽高: canvas标签的宽高默认是300*150,是一个行内块元素 可以在canvas标签上通过width,height来设置 可以在js中给dom对象设置: mycanvas.w ...
- 小程序web-view利用url给内嵌的网页传值
这个方法跟网页上的一样,直接通过截取url中传过来的参数来取值 <web-view src="https://www.baidu.com/test.html?url=http://ww ...
- vue图片的处理技巧
我们想用 post 向后台发送字符串类型的数据:我们可以不适用 data 来进行数据传输,而是用 params 来进行数据传输 代码的简洁之道:分模块化书写: vue 里面提供对图片的监听事件:loa ...
- RF框架自定义测试库开发
静态库 方法(methods)直接映射为关键字名称.关键字接受和方法相同的参数, 通过抛异常来 报告错误, 通过往标准输出里写入来写 log, 同时可以通过return 来返回结果. 创建步骤: ▲ ...
- Cortex-M3 咬尾中断 与 晚到中断
[咬尾中断]在处理器在响应某些异常时,如果又发生其他异常,但它们优先级不够高,则它们会被阻塞. 那么,在当前的异常执行返回后,系统处理悬起的异常时,倘若还是先POP,然后又把POP处理的内容PUSH回 ...
- sptringboot2.0实现aop
题记:在项目需要对请求日志情形管理. 声明:参考博客https://blog.csdn.net/bombsklk/article/details/79143145 1.在pom.xml中加入依赖 &l ...
- OpenStack 对接 Ceph 环境可以创建卷但不能挂载卷的问题
问题 环境:Nova.Cinder.Glance 都对接了 Ceph RBD 后端存储. 以往的操作包括上传镜像.创建卷.挂载卷都是一切正常的,但突然出现了无法挂载卷的问题,而且还是因为 Ceph 客 ...
- jinja2渲染使用
说明:通过jinja2渲染后只能打印出来效果,目前无法保存 例1:渲染 .j2 文件 1.安装jinja2模块 pip3 install jinja2 2.定义模板 说明:变量必须是小写,大写有的情况 ...
- 使用docker-client创建NFS挂载
docker命令行挂载NFS如下: docker volume create --driver local --opt type=nfs --opt o=addr=192.168.11.129,rw ...