sizeof 在计算变量所占空间大小时,括号可以省略,而计算类型(模子)大小时不能省略。一般情况下,咱也别偷这个懒,乖乖的写上括号,继续装作一个“函数”,做一个“披着函数皮的关键字”。
sizeof(int)*p 表示什么意思?
留几个问题(讲解指针与数组时会详细讲解),32 位系统下:
int *p = NULL;
sizeof(p)的值是多少?
sizeof(*p)呢?int a[100];
sizeof (a) 的值是多少?
sizeof(a[100])呢?//请尤其注意本例。
sizeof(&a)呢?
sizeof(&a[0])呢?
int b[100];
void fun(int b[100])
{
sizeof(b);// sizeof (b) 的值是多少?
}
答案:4*p;4;4(NULL在程序中被定义为int型的0);400;4(第100个元素);4;4;4;
1.4signed、unsigned 关键字
1),按照我们上面的解释,那-0 和+0 在内存里面分别怎么存储?
2),int i = -20;
unsigned j = 10;
i+j 的值为多少?为什么?
3), 下面的代码有什么问题?
unsigned i ;
for (i=9;i>=0;i--)
{
printf("%u\n",i);
}
答案:0000 0000(反码的时候改变符号位);
当int型和unsigned int型相互运算时,int型自动转化为unsigned int型(低向高转化)。因此i+j的值不是-10;而是一个非常大的数。
但是这里需要注意使用printf显示时选择%u和%d的区别:
当以%d输出时会认为是有符号符,这样把最高为1当成符号输出结果为-10;当以%u输出时,会认为是无符号数,这样他会将符号位看成数的本身所以会输出一个很大的数;
当i=0时printf输出0;然后i--;因为unsigned int型的范围是(0~2^16),所以0再减就溢出了,又得从高处减。
1.6if、else 组合
a.bool
if(bTestFlag); if(!bTestFlag);
b.float
if((fTestVal >= -EPSINON) && (fTestVal <= EPSINON)); //EPSINON 为定义好的精度。
同样的也不要在很大的浮点数和很小的浮点数之间进行运算,比如:100 0000 0000.00 + 0.000 0000 0001这样计算后的结果可能会让你大吃一惊。
100 0000 0000.000 000(从左到右依次,最后溢出的不要。类似于float和double是有有效数的个数)
c.指针
if(NULL == p); if(NULL != p);
1.7.2,case 关键字后面的值有什么要求吗?
case 后面只能是整型或字符型的常量或常量表达式(想想字符型数据在内存里
是怎么存的)。
1.8.1,break 与 continue 的区别
break :关键字很重要,表示终止本层循环。
continue: 表示终止本次(本轮)循环。进入下一轮循环。
return:结束函数,返回值。
留一个问题:在 switch case 语句中能否使用 continue 关键字?为什么?
不能。continue只能用在循环语句中;break可以用在循环语句和switch语句。
1.10.1,void a?
void 真正发挥的作用在于:
(1) 对函数返回的限定;
(2) 对函数参数的限定。
void *则不同,任何类型的指针都可以直接赋值给它,无需进行强制类型转换:
(把任何类型赋给void*时,void*会转变为所接受的类型)
void *p1;
int *p2;
p1 = p2;
void*不能赋值给任何值:
下面的语句编译出错:
void *p1;
int *p2;
p2 = p1;
提示“'=' : cannot convert from 'void *' to 'int *'”。
1.10.3,void 指针
不能对 void 指针进行算法操作,
即下列操作都是不合法的:
void * pvoid;
pvoid++; //ANSI:错误
pvoid += 1; //ANSI:错误
ANSI 标准之所以这样认定,是因为它坚持:进行算法操作的指针必须是确定知道其指
向数据类型大小的。也就是说必须知道内存目的地址的确切值。
1.10.4,void 不能代表一个真实的变量
void 不能代表一个真实的变量。因为定义变量时必须分配内存空间,定义 void 类型变量,编译器到底分配多大的内存呢。
1.10,return 关键字
return 用来终止一个函数并返回其后面跟着的值。
return (Val);//此括号可以省略。但一般不省略,尤其在返回一个表达式的值时。
return 可以返回些什么东西呢?看下面例子:
char * Func(void)
{
char str[30];
…
return str;
}
str 属于局部变量,位于栈内存中,在 Func 结束的时候被释放,所以返回 str 将导致错误。
【规则 1-38】return 语句不可返回指向“栈内存”的“指针”,因为该内存在函数体结束时被自动销毁。
c语言可以返回局部变量,而不能返回局部指针和数组。因为函数在结束时,函数会把函数堆栈的数据都销毁。return返回时,局部变量直接返回一个值(可以使用),而指针数组返回时,返回的是地址。函数销毁时,销毁了地址所指的内存。
留个问题:
return ;
这个语句有问题吗?如果没有问题,那返回的是什么?
答案:没有问题,用于void型函数,返回空。
1.11,const 关键字也许该被替换为 readolny
只读变量
1.11.1,const 修饰的只读变量
结合c语言495个问题 11.9。
1.11.5,修饰指针
const int *p; // p 可变,p 指向的对象不可变
int const *p; // p 可变,p 指向的对象不可变
int *const p; // p 不可变,p 指向的对象可变
const int *const p; //指针 p 和 p 指向的对象都不可变
1.12,最易变的关键字----volatile
volatile 是易变的、不稳定的意思。
int i=10;
int j = i;//(1)语句
int k = i;//(2)语句
这时候编译器对代码进行优化,因为在(1)、(2)两条语句中,i 没有被用作左值。这时候编译器认为 i 的值没有发生改变,所以在(1)语句时从内存中取出 i 的值赋给 j 之后,这个值并没有被丢掉,而是在(2)语句时继续用这个值给 k 赋值。编译器不会生成出汇编代码重新从内存里取 i 的值,这样提高了效率。但要注意:(1)、(2)语句之间 i 没有被用作左值才行。
再看另一个例子:
volatile int i=10;
int j = i;//(3)语句
int k = i;//(4)语句
volatile 关键字告诉编译器 i 是随时可能发生变化的,每次使用它的时候必须从内存中取出 i的值,因而编译器生成的汇编代码会重新从 i 的地址处读取数据放在 k 中。这样看来,如果 i 是一个寄存器变量或者表示一个端口数据或者是多个线程的共享数据,就容易出错,所以说 volatile 可以保证对特殊地址的稳定访问。
留一个问题:const volatile int i=10;这行代码有没有问题?如果没有,那 i 到底是什么属性?
答案:没问题。const修饰i,所以i在本程序中可以当做常量一般使用。但volatile要求从外面读入i,外面的i是可变的。每次读入后则不可变。
1.14.1,空结构体多大?
空结构体的大小就定位 1 个 byte。
1.14.2,柔性数组
结构体中的最后一个元素允许是未知大小的数组,这就叫做柔性数组成员,但结构中的柔性数组成员前面必须至少一个其他成员。
sizeof 返回的这种结构大小不包括柔性数组的内存。柔性数组只是编外人员,不占结构体的编制。
1.14.3,struct 与 class 的区别
truct 的成员默认情况下属性是 public 的,而 class 成员却是 private 的。
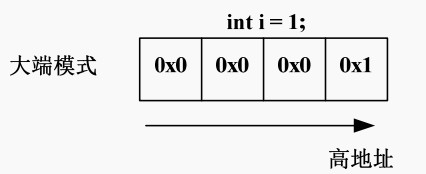
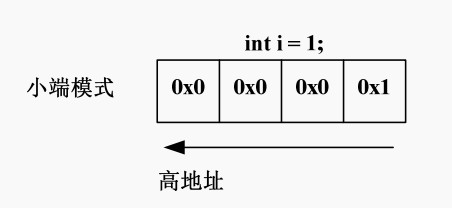
1.15.1,大小端模式对 union 类型数据的影响
下面再看一个例子:
union
{
int i;
char a[2];
}*p, u;
p = &u;
p->a[0] = 0x39;
p->a[1] = 0x38;
p.i 的值应该为多少呢?
这里需要考虑存储模式:大端模式和小端模式。
大端模式(Big_endian):字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中。
小端模式(Little_endian):字数据的高字节存储在高地址中,而字数据的低字节则存放在低地址中。
对 union 型的成员的存取都是相对于该联合体基地址的偏移量为 0 处开始
大端:0x3938
小端:0x3839
1.16.1, 枚举类型的使用方法
成员都是常量,平时所说的枚举常量(常量一般用大写)。
1.16.2,枚举与#define 宏的区别
下面再看看枚举与#define 宏的区别:
1),#define 宏常量是在预编译阶段进行简单替换。枚举常量则是在编译的时候确定其值。
2),一般在编译器里,可以调试枚举常量,但是不能调试宏常量。
3),枚举可以一次定义大量相关的常量,而#define 宏一次只能定义一个。
留两个问题:
A),枚举能做到事,#define 宏能不能都做到?如果能,那为什么还需要枚举?
enum Color
{
GREEN = 1,
RED,
BLUE,
GREEN_RED = 10,
GREEN_BLUE
}ColorVal;
B),sizeof(ColorVal)的值为多少?为什么?
答案:4 枚举变量为int型。
1.17.3,typedef 与#define 的区别
a.#define在预处理的时候就被处理,而typedef则不会
E), #define INT32 int
unsigned INT32 i = 10;
F),typedef int int32;
unsigned int32 j = 10;
其中 F)编译出错,为什么呢?E)不会出错,这很好理解,因为在预编译的时候 INT32被替换为 int,而 unsigned int i = 10;语句是正确的。但是,很可惜,用 typedef 取的别
名不支持这种类型扩展。
另外,想想 typedef static int int32 行不行?为什么?
答案:auto,extern,typedef,static,register不能同时使用两个。
b.#define是简单替换,而typedef不是(能更好的处理指针)
G),#define PCHAR char*
PCHAR p3,p4;
H),typedef char* pchar;
pchar p1,p2;
两组代码编译都没有问题,但是,这里的 p4 却不是指针,仅仅是一个 char 类型的字符。这种错误很容易被忽略,所以用#define 的时候要慎之又慎。
2.1.3.1,安息吧,路德维希.凡.贝多芬
汇编程序的注释是以分号开头。
2.2,接续符和转义符
注意:反斜杠之后不能有空格,反斜杠的下一行之前也不能有空格。
反斜杠除了可以被用作接续符,还能被用作转义字符的开始标识。
2.3,单引号、双引号
这两个列子还好理解,再看看这三个:
1,‘1‘,“1”。
第一个是整形常数,32 位系统下占 4 个 byte;
第二个是字符常量,占 1 个 byte;
第三个是字符串常量,占 2 个 byte。 ('\0')
2.5.1,左移和右移
注意:对于有符号数,在右移时,符号位将随同移动。当为正数时, 最高位补 0;而为负数时,符号位为 1,最高位是补 0 或是补 1 取决于编译系统的规定。
2.5.2,0x01<<2+3 的值为多少?
0x01<<2+3;
结果为 7 吗?测试一下。结果为 32?别惊讶,32 才是正确答案。因为“+”号的优先级比移位运算符的优先级高
左移和右移的位数不能大于数据的长度,不能小于 0。
2.7.1,++i+++i+++i
上面的例子很简单,那我们把括号去掉看看:
int i = 3;
++i+++i+++i;
天啦!这到底是什么东西?好,我们先看看这个:a+++b 和下面哪个表达式想当:
A),a++ +b;
B),a+ ++b;
答案:++i++ + i++ + i;A对;解析(见下贪心法)
2.7.2,贪心法
语言有这样一个规则:每一个符号应该包含尽可能多的字符。也就是说,编译器将程序分解成符号的方法是,从左到右一个一个字符地读入,如果该字符可能组成一个符号,
那么再读入下一个字符,判断已经读入的两个字符组成的字符串是否可能是一个符号的组成部分;如果可能,继续读入下一个字符,重复上述判断
2.9.2,一些容易出错的优先级问题
== 和!=高于位操作
3.1.1,数值宏常量
const 修饰的只读变量不能用来作为定义数组的维数,也不能放在 case 关键字后面。
3.1.3,用 define 宏定义注释符号?
上面对 define 的使用都很简单,再看看下面的例子:
#define BSC //
#define BMC /*
#define EMC */
D),BSC my single-line comment
E),BMC my multi-line comment EMC
D)和 E)都错误,为什么呢?因为注释先于预处理指令被处理,当这两行被展开成//…或/*…*/时,注释已处理完毕,此时再出现//…或/*…*/自然错误.因此,试图用宏开始或结束一段注释是不行的。
3.1.4,用 define 宏定义表达式
留四个问题:
A),上述宏定义中“SUM”、“SQR”是宏吗?
B),#define EMPTY
这样定义行吗?
C),打印上述宏定义的值:printf(“SUM (x)”);结果是什么?
D), “#define M 100”是宏定义吗?
答案:是;行,只是EMPTY什么都不是;(x)+(x);是
4.3,指针与数组之间的恩恩怨怨
指针变量在 32 位系统下,永远占 4 个 byte
4.3.1.1,以指针的形式访问和以下标的形式访问指针
1),以指针的形式:*(p+4)。先取出 p 里存储的地址值,假设为 0x0000FF00,然后加上 4 个字符的偏移量,得到新的地址 0x0000FF04。然后取出 0x0000FF04 地址上的值。
2),以下标的形式:p[4]。编译器总是把以下标的形式的操作解析为以指针的形式的操作。p[4]这个操作会被解析成:先取出 p 里存储的地址值,然后加上中括号中 4 个元素的偏
移量,计算出新的地址,然后从新的地址中取出值。
也就是说以下标的形式访问在本质上与以指针的形式访问没有区别,只是写法上不同罢了。
4.3.1.2,以指针的形式访问和以下标的形式访问数组
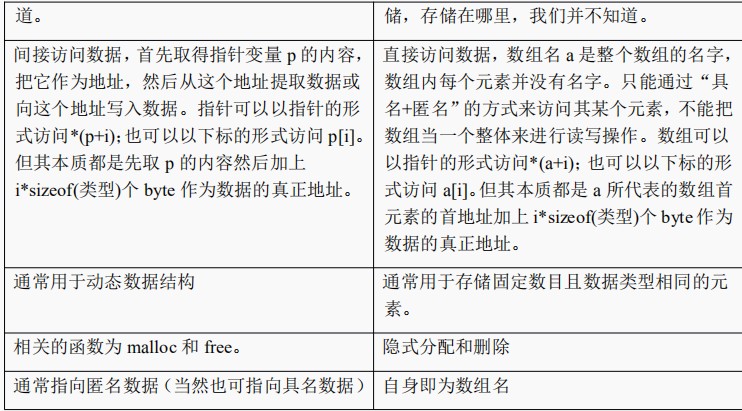
指针:是完全的匿名访问,
数组:是典型的具名+匿名访问。
4.3.2,a 和&a 的区别
通过上面的分析,相信你已经明白数组和指针的访问方式了,下面再看这个例子:
main()
{
int a[5]={1,2,3,4,5};
int *ptr=(int *)(&a+1);
printf("%d,%d",*(a+1),*(ptr-1));
}
打印出来的值为多少呢? 这里主要是考查关于指针加减操作的理解。
&a + 1: 取数组 a 的首地址,该地址的值加上 sizeof(a) 的值,即 &a + 5*sizeof(int),也就是下一个数组的首地址,显然当前指针已经越过了数组的界限。
(int *)(&a+1): 则是把上一步计算出来的地址,强制转换为 int * 类型,赋值给 ptr。
*(a+1): a,&a 的值是一样的,但意思不一样,
a 是数组首元素的首地址,也就是 a[0]的首地址,
&a 是数组的首地址,a+1 是数组下一元素的首地址,即 a[1]的首地址,&a+1 是下一个数组的首地址。所以输出 2
a 在这里代表是的数组首元素的地址即 a[0]的首地址,其值为 0x0012ff6c。
&a 代表的是数组的首地址,其值为 0x0012ff6c。
4.3.3,指针和数组的定义与声明
定义和声明之间的区别,定义分配的内存,而声明没有。
4.3.4,指针和数组的对比

4.4,指针数组和数组指针
4.4.1,指针数组和数组指针的内存布局
指针数组:首先它是一个数组,数组的元素都是指针,数组占多少个字节由数组本身决定。它是“储存指针的数组”的简称。
数组指针:首先它是一个指针,它指向一个数组。在 32 位系统下永远是占 4 个字节,至于它指向的数组占多少字节,不知道。它是“指向数组的指针”的简称。
下面到底哪个是数组指针,哪个是指针数组呢:
A),int *p1[10];
B),int (*p2)[10];
“[]”的优先级比“*”要高。p1 先与“[]”结合,构成一个数组的定义,数组名为 p1,int *修饰的是数组的内容,即数组的每个元素。那现在我们清楚,这是一个数组,其包含 10
个指向 int 类型数据的指针,即指针数组。至于 p2 就更好理解了,在这里“()”的优先级比“[]”高,“*”号和 p2 构成一个指针的定义,指针变量名为 p2,int 修饰的是数组的内容,
即数组的每个元素。数组在这里并没有名字,是个匿名数组。那现在我们清楚 p2是一个指针,它指向一个包含 10 个 int 类型数据的数组,即数组指针
4.4.3,再论 a 和&a 之间的区别
既然这样,那问题就来了。前面我们讲过 a 和&a 之间的区别,现在再来看看下面的代码:
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[5] = &a;
char (*p4)[5] = a;
return 0;
}
上面对 p3 和 p4 的使用,哪个正确呢?p3+1 的值会是什么?p4+1 的值又会是什么?
p3 和 p4 都是数组指针,指向的是整个数组。&a 是整个数组的首地址,a是数组首元素的首地址,其值相同但意义不同。在 C 语言里,赋值符号“=”号两边的数据
类型必须是相同的,如果不同需要显示或隐式的类型转换。p3 这个定义的“=”号两边的数据类型完全一致,而 p4 这个定义的“=”号两边的数据类型就不一致了。左边的类型是指
向整个数组的指针,右边的数据类型是指向单个字符的指针。
既然现在清楚了 p3 和 p4 都是指向整个数组的,那 p3+1 和 p4+1 的值就很好理解了。但是如果修改一下代码,会有什么问题?p3+1 和 p4+1 的值又是多少呢?
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[3] = &a;
char (*p4)[3] = a;
return 0;
}
甚至还可以把代码再修改:
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[10] = &a;
char (*p4)[10] = a;
return 0;
}
这个时候又会有什么样的问题?p3+1 和 p4+1 的值又是多少?
答案:数组大小改变,都会编译不通过。
4.4.4,地址的强制转换
先看下面这个例子:
struct Test
{
int Num;
char *pcName;short sDate;
char cha[2];
short sBa[4];
}*p;
假设 p 的值为 0x100000。 如下表表达式的值分别为多少?
p + 0x1 = 0x___ ?
(unsigned long)p + 0x1 = 0x___?
(unsigned int*)p + 0x1 = 0x___?
指针变量与一个整数相加减并不是用指针变量里的地址直接加减这个整数。这个整数的单位不是byte 而是元素的个数。所以: p + 0x1 的值为 0x100000+sizof(Test)*0x1。
(unsigned long)p + 0x1 的值呢?这里涉及到强制转换,将指针变量 p 保存的值强制转换成无符号的长整型数。任何数值一旦被强制转换,其类型就改变了。所以这个表达式其实就
是一个无符号的长整型数加上另一个整数。所以其值为:0x100001。
(unsigned int*)p + 0x1 的值呢?这里的 p 被强制转换成一个指向无符号整型的指针。所以其值为:0x100000+sizof(unsigned int)*0x1,等于 0x100004。
4.5.1.2,内存与尺子的对比
下面就看一个题:
#include <stdio.h>
int main(int argc,char * argv[])
{
int a [3][2]={(0,1),(2,3),(4,5)};
int *p;
p=a [0];
printf("%d",p[0]);
}
问打印出来的结果是多少?
答案应该是 1。
如果你也认为是 0,那你实在应该好好看看这个题。花括号里面嵌套的是小括号,而不是花括号!这里是花括号里面嵌套了逗号表达式!其实这个赋值就相当于 int a [3][2]={ 1, 3,
5};(","运算符先计算左边,在计算右边。右边操作数作为整个表达式的结果)
4.5.2.1,二级指针的内存布局
一级指针保存的是数据的地址,二级指针保存的是一级指针的地址
4.6.1.2,无法向函数传递一个数组
C 语言中,当一维数组作为函数参数的时候,编译器总是把它解析成一个指向其首元素首地址的指针。
4.6.2.1,能否把指针变量本身传递给一个函数
main 函数内的变量不是全局变量,而是局部变量,只不过它的生命周期和全局变量一样长而已。
5.2,栈、堆和静态区
内存分为三个部分:静态区,栈,堆。
静态区:保存自动全局变量和 static 变量(包括 static 全局和局部变量)。静态区的内容在总个程序的生命周期内都存在,由编译器在编译的时候分配。
栈:保存局部变量。栈上的内容只在函数的范围内存在,当函数运行结束,这些内容也会自动被销毁。其特点是效率高,但空间大小有限。
堆:由 malloc 系列函数或 new 操作符分配的内存。其生命周期由 free 或 delete 决定。在没有释放之前一直存在,直到程序结束。其特点是使用灵活,空间比较大,但容易出错。
5.3.1.1,结构体成员指针未初始化
struct student
{
char *name;
nt score;
}stu,*pstu;
int main()
{
strcpy(stu.name,"Jimy");
stu.score = 99;
return 0;
}
这里定义了结构体变量 stu,但是他没想到这个结构体内部 char *name 这成员在定义结构体变量 stu 时,只是给 name 这个指针变量本身分配了 4 个字节。name 指针并没有指向一个合法的地址,这时候其内部存的只是一
些乱码。所以在调用 strcpy 函数时,会将字符串"Jimy"往乱码所指的内存上拷贝,而这块内存 name 指针根本就无权访问,导致出错。解决的办法是为 name 指针 malloc 一块空间。
5.3.2,为指针分配的内存太小
为指针分配了内存,但是内存大小不够,导致出现越界错误。
char *p1 = “abcdefg”;
char *p2 = (char *)malloc(sizeof(char)*strlen(p1));
strcpy(p2,p1);
p1 是字符串常量,其长度为 7 个字符,但其所占内存大小为 8 个 byte。初学者往往忘了字符串常量的结束标志“\0”。这样的话将导致 p1 字符串中最后一个空字符“\0”没有被
拷贝到 p2 中。解决的办法是加上这个字符串结束标志符:
char *p2 = (char *)malloc(sizeof(char)*strlen(p1)+1*sizeof(char));
这里需要注意的是,只有字符串常量才有结束标志符。比如下面这种写法就没有结束标志符了:
char a[7] = {‘a’,’b’,’c’,’d’,’e’,’f’,’g’};
另外,不要因为 char 类型大小为 1 个 byte 就省略 sizof(char)这种写法。这样只会使你的代码可移植性下降。
5.3.5.2,如何使用 malloc 函数
malloc 函数的返回值是一个 void 类型的指针,参数为 int 类型数据,即申请分配的内存大小,单位是 byte。
malloc 函数申请的是连续的一块内存。
5.3.5.3,用 malloc 函数申请 0 字节内存
另外还有一个问题:用 malloc 函数申请 0 字节内存会返回 NULL 指针吗?
申请 0 字节内存,函数并不返回 NULL,而是返回一个正常的内存地址。但是你却无法使用这块大小为 0 的内存。
值得一眼的书。附pdf
链接:https://pan.baidu.com/s/1xfaqMYmU1oRhQRV99tcjpA
提取码:eow6