MySQL 数据库的高可用性分析
MySQL数据库是目前开源应用最大的关系型数据库,有海量的应用将数据存储在MySQL数据库中。存储数据的安全性和可靠性是生产数据库的关注重点。本文分析了目前采用较多的保障MySQL可用性方案。
MySQL Replication
MySQL Replication是MySQL官方提供的主从同步方案,用于将一个MySQL实例的数据,同步到另一个实例中。Replication为保证数据安全做了重要的保证,也是现在运用最广的MySQL容灾方案。Replication用两个或以上的实例搭建了MySQL主从复制集群,提供单点写入,多点读取的服务,实现了读的scale out。
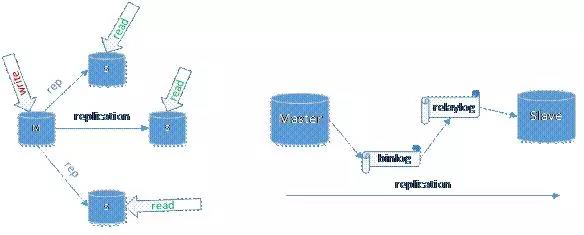
图1. MySQL Replication主从复制集群
如图一所示,一个主实例(M),三个从实例(S),通过replication,Master生成event的binlog,然后发给slave,Slave将event写入relaylog,然后将其提交到自身数据库中,实现主从数据同步。对于数据库之上的业务层来说,基于MySQL的主从复制集群,单点写入Master,在event同步到Slave后,读逻辑可以从任何一个Slave读取数据,以读写分离的方式,大大降低Master的运行负载,同时提升了Slave的资源利用。
对于高可用来说,MySQL Replication有个重要的缺陷:数据复制的时延。在通常情况下,MySQL Replication数据复制是异步的,即是MySQL写binlog后,发送给Slave并不等待Slave返回确认收到,本地事务就提交了。一旦出现网络延迟或中断,数据延迟发送到Slave侧,主从数据就会出现不一致。在这个阶段中,Master一旦宕机,未发送到Slave的数据就丢失了,无法做到数据的高可用。
为了解决这个问题,google提供了解决方案:半同步和同步复制。在数据异步复制的基础之上,做了一点修改。半同步复制是Master等待event写入Slave的relay后,再提交本地,保证Slave一定收到了需要同步的数据。同步复制不不仅是要求Slave收到数据,还要求Slave将数据commit到数据库中,从而保证每次的数据写入,主从数据都是一致的。
基于半同步和同步复制,MySQL Replication的高可用得到了质的提升,特别是同步复制。基于同步复制的MySQL Replication集群,每个实例读取的数据都是一致的,不会存在Slave幻读。同时,Master宕机后,应用程序切换到任何一个Slave都可以保证读写数据的一致性。但是,同步复制带来了重大的性能下降,这里需要做一个折衷。另外,MySQL Replication的主从切换需要人工介入判断,同时需要Slave的replaylog提交完毕,故障恢复时间会比较长。
MySQL Fabric
MySQL Fabric是MySQL社区提供的管理多个MySQL服务的扩展。高可用是它设计的主要特性之一。
Fabric将两个及以上的MySQL实例划分为一个HA Group。其中的一个是主,其余的都是从。HA Group保证访问指定HA Group的数据总是可用的。其基础的数据复制是基于MySQL Replication,然后,Fabric提供了更多的特性:
失效检测和恢复:Fabric监控HA Group中的主实例,一旦发现主实例失效,Fabric会从HA Group中剩余的从实例中选择一个,并将其提升为主实例。
读写均衡:Fabric可以自动的处理一个HA Group的读写操作,将写操作发送给主实例,而读请求在多个从实例之间做负载均衡。
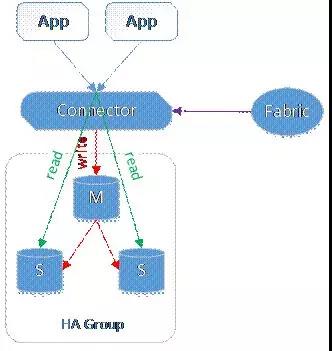
图2. Fabric
MHA
MHA(MySQL-master-ha)是目前广泛使用的MySQL主从复制的高可用方案。MHA设计目标是自动实现主实例宕机后,从机切换为主,并尽量降低切换时延(通常在10-30s内切换完成)。同时,由MHA保证在切换过程中的数据一致性。MHA对MySQL的主从复制集群非常友好,没有对集群做任何侵入性的修改。
MHA的一个重点特性是:在主实例宕机后,MHA可以自动的判断主从复制集群中哪个从实例的relaylog是最新的,并将最新从实例的差异log“应用”到其余的从实例中,从而保证每个实例的数据一致。通常情况下,MHA需要10s左右检测主实例异常,并将主实例关闭从而避免脑裂。然后再用10s左右将差异的log event同步,并启用新的Master。整个MHA的RTO时间大约在30s。
MySQL Cluster
MySQL Cluster是一个高度可扩展的,兼容ACID事务的实时数据库,基于分布式架构不存在单点故障,MySQL Cluster支持自动水平扩容,并能做自动的读写负载均衡。
MySQL Cluster使用了一个叫NDB的内存存储引擎来整合多个MySQL实例,提供一个统一的服务集群。如图三所示。
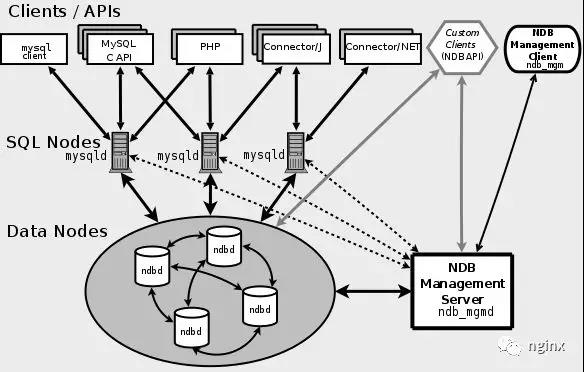
图3. MySQL Cluster组成
MySQL Cluster由SQL Nodes,DataNodes,和NDB Management Server组成。SQL Nodes是应用程序的接口,像普通的mysqld服务一样,接受用户的SQL输入,执行并返回结果。Data Nodes是数据存储节点,NDB Management Server用来管理集群中的每个node。
MySQL Cluster采用了新的数据分片和容错的方式来实现数据安全和高可用。其由Partition,Replica,Data Node,Node Group构成。
Partition:NDB一张表的一个数据分片,包含一张表的一部分数据。
Replica:一个Partition的拷贝。一个Partition可以有一个或多个Replica,一个Partition的所有Replica数据都是一致的。
Data Node:Replica的存储载体,每个Node存储一个或多个Replica。
Node Group:一个Data Node的集合。
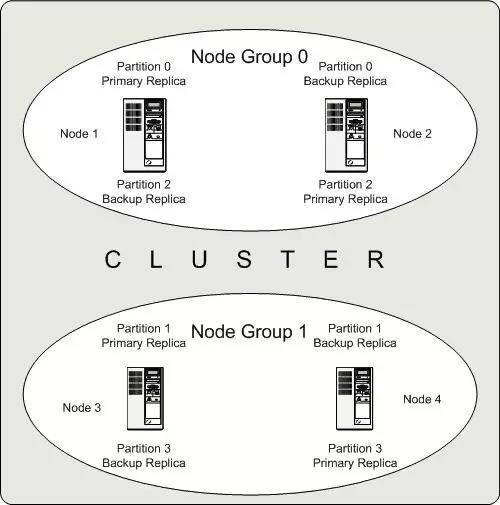
图4. MySQL Cluster数据高可用
一个MySQL Cluster有4个Node,被分为了两个Grou。Node1和2归属于Group0,Node3和4归属于Group1,。有一张表被分为4个Partition,并分别有两个Replica。Partition0和Partition2的两个Replica,分别存储在Node1和Node2上,Pratition1和Partition3的两个Replica分别存在Node3和Node4上。这样,对于一张表的一个Partition来说,在整个集群有两份数据,并分布在两个独立的Node上,实现了数据容灾。同时,每次对一个Partition的写操作,都会在两个Replica上呈现,如果Primary Replica异常,那么Backup Replica可以立即提供服务,实现数据的高可用。
小结
本文分析了目前MySQL使用较多的几种MySQL数据复制和高可用方案,从使用来看,MySQL Replication是使用最为广泛的数据复制方案,因为是MySQL原生支持,针对其在不同场景下的一些缺陷,衍生出了半同步复制,强同步复制等数据高可用的方案。
在此基础之上,为了运维方便,MySQL Fabric和MHA应运而生,从不同的方向解决了主从切换时数据一致性问题和流程自动化的问题。此外,随着分布式系统架构和方案的逐步成熟。MySQL Cluster设计了全新的分布式架构,采用多副本,Sharding等特性,支持水平扩展,做到了5个9的数据库服务质量保证。
MySQL 数据库的高可用性分析的更多相关文章
- MySQL数据库的高可用性分析
MySQL数据库是目前开源应用最大的关系型数据库,有海量的应用将数据存储在MySQL数据库中.存储数据的安全性和可靠性是生产数据库的关注重点.本文分析了目前采用较多的保障MySQL可用性方案. MyS ...
- 腾讯云数据库团队:MySQL数据库的高可用性分析
作者介绍:易固武,腾讯高级工程师,参与腾讯账号安全建设,腾讯数据仓库(TDW)优化改造,腾讯云数据库等项目,对大规模分布式存储和计算系统有浓厚的兴趣和经历 MySQL数据库是目前开源应用最大的关系型数 ...
- mysql数据库SQL执行分析,优化前必备分析
概述 一般我们在对mysql数据库做优化,肯定需要对慢sql去做分析才能开始优化,那么有什么分析的方法呢?下面通过对sql执行时间和执行情况来做分析. 一.SQL 执行时间分析 通过找到执行时间长的 ...
- MySQL数据库的性能分析 ---图书《软件性能测试分析与调优实践之路》-手稿节选
1 .MySQL数据库的性能监控 1.1.如何查看MySQL数据库的连接数 连接数是指用户已经创建多少个连接,也就是MySQL中通过执行 SHOW PROCESSLIST命令输出结果中运行着的线程 ...
- 分布式MySQL数据库TDSQL架构分析
摘要:腾讯计费平台部为了解决基于内存的NoSQL解决方式HOLD平台在应对多种业务接入时的不足.结合团队在MySQL领域多年应用和优化经验,终于在MySQL存储引擎基础上,打造一套分布式SQL系统TD ...
- postgresql数据库和mysql数据库的对比分析
1.Posgresql是进程模式,多进程,单线程,类似的还有Oracle.而MYSQL采用的是线程模式,单进程,多线程,对此,大家在运行数据库的时候可以查看任务管理器,SQL Server也是如此. ...
- 005 -- Mysql数据库引擎特点分析
常用的数据库引擎的特点: ISAM: ISAM是一个定义明确且历经时间考验的数据表格管理方法,它在设计之时就考虑到数据库查询次数要远大于更新次数.因此,ISAM执行读取操作的速度很快,而且不占用大量的 ...
- 【转载】MySQl 数据库插入加锁分析
http://yeshaoting.cn/article/database/mysql%20insert%E9%94%81%E6%9C%BA%E5%88%B6/
- Mysql数据库事务隔离级别
事务(transaction)是数据库管理系统的执行单位,可以是一个数据库操作(如Select操作)或者是一组操作序列.事务ACID属性,即原子性(Atomicity).一致性(Consistency ...
随机推荐
- 文件描述符FD的含义/文件句柄
使用sudo lsof -nP -iTCP -sTCP:LISTEN查看占用端口的程序;因为 lsof 需要访问核心内存和各种文件,所以必须以 root 用户的身份运行它才能够充分地发挥其功能 概念 ...
- centos7下使用yum安装mysql5.7.10
原文地址:http://www.mamicode.com/info-detail-503994.html CentOS7的yum源中默认好像是没有mysql的.为了解决这个问题,我们要先下载mysql ...
- Django_静态文件的配置(STATIC_URL)
静态文件,常用在head中,可动态的去检索settings里面的STATIC_URL = '/static/',然后做拼接settings.py中 STATIC_URL = '/static9/' # ...
- 微信小程序中的事件绑定
前言: 微信小程序中的事件绑定和Vue中的事件绑定其实有很多的相似之处,所以如果有过Vue相关的经验,学起来的话还是比较容易的. js代码: // 页面级的js文件必须调用Page函数来注册页面, / ...
- Head First Design Patterns HeadFirst 设计模式
OO原则是我们的目标,而设计模式是我们的做法. 策略模式 (Strategy) 在软件开发上,一直不变的真理是"change".不管软件设计的多好,一段时间之后,总是要成长与改变, ...
- 2019.12.12 Java的多线程&匿名类
Java基础(深入了解概念为主) 匿名类 定义 Java匿名类很像局部或内联系,只是没有明细.我们可以利用匿名类,同时定义并实例化一个类.只有局部类仅被使用一次时才应该这么做. 匿名类不能有显式定义的 ...
- 伸缩布局 Flex
其中在webkit内核的浏览器中使用时,必须加上-webkit-前缀,采用Flex布局的元素,称为Flex容器(flex container),简称”容器”.它的所有子元素自动成为容器成员,称为Fle ...
- 《ucore lab8》实验报告
资源 ucore在线实验指导书 我的ucore实验代码 练习1: 完成读文件操作的实现(需要编码) 题目 首先了解打开文件的处理流程,然后参考本实验后续的文件读写操作的过程分析,编写在sfs_inod ...
- box-shadow 用法总结
一.基础知识 box-shadow 属性向框添加一个或多个阴影. 语法 box-shadow: offset-x offset-y blur spread color inset; box-shado ...
- SecureCRT系列:生成公私钥
SecureCRT下载地址:http://www.portablesoft.org/securecrt-securefx-legacy-versions/1.打开我们的SecureCRT客户端,点击t ...