Hadoop系列-HDFS基础
基本原理
HDFS(Hadoop Distributed File System)是Hadoop的一个基础的分布式文件系统,这个分布式的概念主要体现在两个地方:
数据分块存储在多台主机
数据块采取冗余存储的方式提高数据的可用性
针对于以上的分布式存储概念,HDFS采用了master/slave的主从结构来构建整个存储系统。之所以可以通过分散的机器组成一个整体式的系统,这其中机器之间的相互通讯必不可少。对于一个程序在不同机器上的通讯,主要是通过远程系统调用RPC(remote procedure call)实现,不同的语言有不同的实现方式,而HDFS是运行于JVM基础上的,那么这里的通讯就是指不同机器的JVM进程之间的通讯。当然,底层的网络通讯主要是socket协议,在实际的工业场景中使用对socket进一步封装的netty实现。接下来,进一步针对数据块、namenode、datanode等进行说明。
数据块
每个计算机的磁盘都有一个默认的数据块(block)大小,这是进行数据读写的最小单位,文件系统通过管理磁盘上的数据块来管理文件。HDFS的block默认大小为128MB,但是于一般单一的磁盘文件系统不同的是,HDFS中小于一个块大小的文件不会占用整个block空间。例如:一个大小为1MB的文件存储在HDFS中时,在默认数据块是128MB的情况下还是只占用1MB,而不是128MB。决定数据传输速度的因素主要是磁盘驱动器的传输速率和文件寻址效率,如果数据块设置的足够大,那么文件寻址的效率就会变高,但也不是无限大,具体block的大小还需要根据具体的业务逻辑进行考虑。对文件进行块抽象的一个明显优点就是文件的大小不受限于任何一台单独的主机的磁盘容量限制,也就使得HDFS更适合数据量比较大的大数据场景。
namenode
整个HDFS集群有管理节点(namenode)和工作节点(datanode)。namenode主要维持两层关系:
第一层:整个集群的目录树结构以及文件的数据块列表,这两部分又可以总称为Namespace管理;
第二层:数据块在各个datanode的存储位置,这一部分称作块管理,除此之外块管理还会维护blockid到block的映射关系。

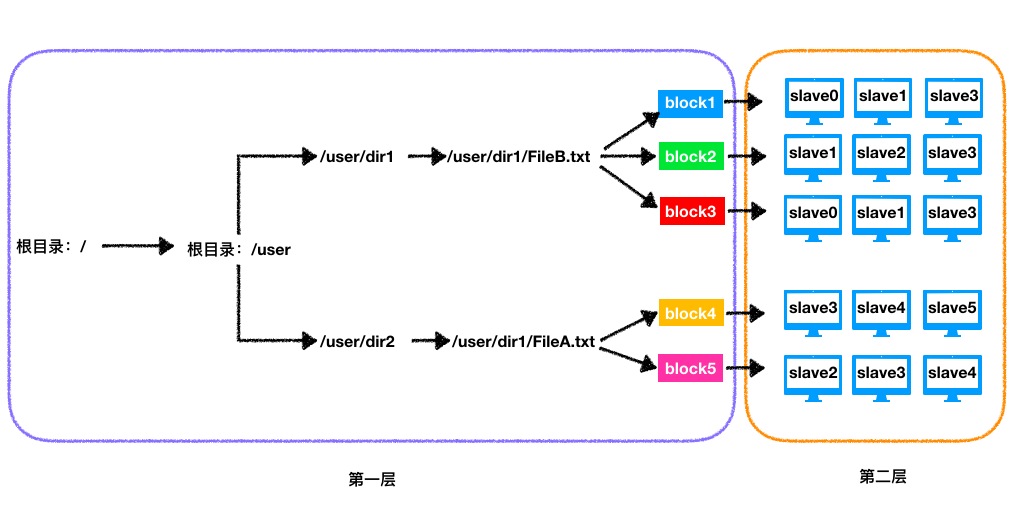
上图展示了namenode维持的两层关系,除了上述两层关系之外实际上namenode还会维持整个HDFS集群机架的拓扑信息以及所有datanode的信息(如主机名,版本等)。
为了使客户端访问的速度最快,以上的信息会保存在namenode主机的内存中。对于在内存中保存的数据,在断电后就会消失,这显然是不允许的,因此以上信息除了在内存中保存之外还需要在硬盘中保存一份,具体在硬盘中的保存形式为:
命名空间镜像文件(FSImage):某一时刻内存元数据的真实组织情况
编辑日志文件(EditsLog):该时刻后所有元数据的改动信息
需要说明的是,数据块与数据节点的信息虽然也会存储在namenode进程中,但是这个信息不会持久化到磁盘中,是在集群启动的时候namenode根据datanode上报的信息来构建的。
secondarynamenode
secondarynamenode主要是不定时的观察EditsLog、FSImage的情况,超过一定的阈值情况下对EditsLog和FSImage进行合并,形成新的FSImage文件。这样可以尽量减少namenode本身的负载。
datanode
datanode是主要的数据存储节点,这其中涉及了datanode与namenode的通讯情况。
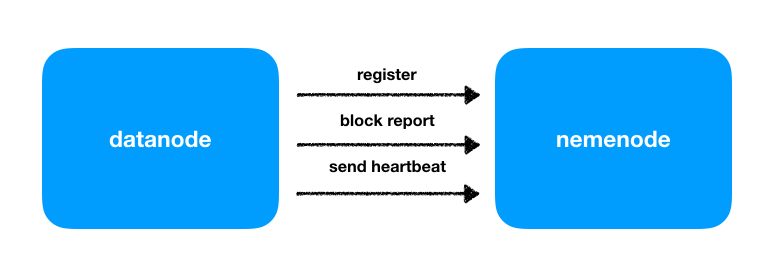


register:将datanode所在主机的信息(如主机名、内存、硬盘)告诉namenode,nemenode通过check相应的信息允许其称为集群中的一员;
block report:传输block信息给namenode,便于namenode可以维护数据块和数据节点之间的映射关系;
send heartbeat:
通过心跳机制保持与namenode的联系更新存储容量等信息
执行namenode通过heartbeat传输来的指令
federation
上文提到,namenode为了尽可能的使客户端的访问效率变高,会将所有的文件系统和数据块的引用信息保存在内存中,如果集群存储的文件量足够多,namenode内存的大小将限制集群的整个性能和可扩展能力。为此,在hadoop2.x中引入了federation机制,通过添加namenode实现扩展。
federation环境下,每隔namenode维护一个命名空间卷(namespace volume)由命名空间的元数据和数据块池组成,命名空间之间相互独立,互不通信。在这种情况下datanode被用作通用的数据存储设备,每个datanode要向集群中所有的namenode注册,且周期性的向所有namenode发送心跳和报告,并执行来自所有namenode的命令。但是,每个namenode只管理各自的block信息,如果一个namenode挂掉,虽然不会影响到其他的namenode,但是这个namenode管理的数据就不可访问,还是会存在SPOF(single point of failure,即单点故障问题)。
以上主要是个人对HDFS的一些基本概念的初步理解,如有错误还请各位大大们指正。
Hadoop系列-HDFS基础的更多相关文章
- 每天收获一点点------Hadoop之HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- Hadoop(1): HDFS基础架构
1. What's HDFS? Hadoop Distributed File System is a block-structured file system where each file is ...
- Hadoop系列-MapReduce基础
由于在学习过程中对MapReduce有很大的困惑,所以这篇文章主要是针对MR的运行机制进行理解记录,主要结合网上几篇博客以及视频的讲解内容进行一个知识的梳理. MapReduce on Yarn运行原 ...
- Hadoop系列-zookeeper基础
目前是刚刚初学完zookeeper,这篇文章主要是简单的对一些基本的概念进行梳理强化. zookeeper基础概念的理解 有时候计算机领域很多名词都是从一长串英文提取首字母缩写而来,但很不幸zooke ...
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop 系列文章(二) Hadoop配置部署启动HDFS及本地模式运行MapReduce
接着上一篇文章,继续我们 hadoop 的入门案例. 1. 修改 core-site.xml 文件 [bamboo@hadoop-senior hadoop-2.5.0]$ vim etc/hadoo ...
- hadoop - hdfs 基础操作
hdfs --help # 所有参数 hdfs dfs -help # 运行文件系统命令在Hadoop文件系统 hdfs dfs -ls /logs # 查看 hdfs dfs -ls /user/ ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- 深入理解Hadoop之HDFS架构
Hadoop分布式文件系统(HDFS)是一种分布式文件系统.它与现有的分布式文件系统有许多相似之处.但是,与其他分布式文件系统的差异是值得我们注意的: HDFS具有高度容错能力,旨在部署在低成本硬件上 ...
随机推荐
- 1.bootstrap基础简介
一·基础简介 1.Bootstrap,来自 Twitter,是一个用于快速开发 Web 应用程序和网站的前端框架,是目前最受欢迎的前端框架. Bootstrap 是基于 HTML.CSS.JavaSc ...
- SQLServer2008或SQLServer2008 R2没有智能提示解决方法
如果没有智能提示,需要安装SqlcompletefreeSQL Server智能提示
- C#中IL, CTS, CLR, CLS, JIT含义
1. IL/MSIL (Microsoft Intermediate Language) 微软中间语言 (IL是MSIL的缩写,译为中间语言) 2. CTS (Common Type System ...
- vs 编译error1083
1)右键查看该项目的属性 2)点击配置属性——〉 C/C++ ——〉 常规 ——〉 附加包含目录——〉将报错文件所在目录添加进去 3) 将项目的本地路径替换为工程相对路径 一般来说,打不开文件 ...
- linux 下crontab相关定时触发的配置规则
linux 下crontab相关定时触发的配置规则: 1.基本格式 :* * * * * command(分 时 日 月 周 命令)2.取值范围:分钟1-59 每分钟用*或者 */1表示小时1-23( ...
- 申请MVP奖励时的小Tips
大家新年好,今天MSPrecious为大家带来一些申请MVP奖励时的小Tips. 本文分为三个部分 MVP是什么 如何申请MVP 申请MVP需要注意的事项 MVP是什么? 我想,点进来看这篇文章的 ...
- C#预定义类型、引用类型
一.预定义的值类型 一个字节(1Byte)=8位(8Bit) BitArarry类可以管理位Bit. 1.整型 所有的整形变量都能用十进制或十六进制表示:long a=0x12AB 对一个整形值如未指 ...
- 转一篇shell中关于各种括号的讲解
shell中各种括号的作用().(()).[].[[]].{} 一.小括号,圆括号()1.单小括号 () ①命令组.括号中的命令将会新开一个子shell顺序执行,所以括号中的变量不能够被脚本余下的 ...
- Webserver管理系列:12、开启关闭Ping命令
有些时候站点打开速度会非常慢,我们要排查故障所在.须要用到Ping命令.可是Windows Server 2008防火墙默认是关闭Ping的 我们能够通过下面方法开启Ping 打开防火墙->高级 ...
- mysql 数据增删改查基本语句
增: insert insert into 表名(字段1,字段2,字段3......字段N) values(值1,值2,值3): 如果不申明插入那些字段,则默认所有字段. 如果一次可以插入多条数据 可 ...