ng-深度学习-课程笔记-7: 优化算法(Week2)
1 Mini-batch梯度下降
在做梯度下降的时候,不选取训练集的所有样本计算损失函数,而是切分成很多个相等的部分,每个部分称为一个mini-batch,我们对一个mini-batch的数据计算代价,做完梯度下降,再对下一个mini-batch做梯度下降。比如500w个数据,一个mini-batch设为1000的话,我们就做5000次梯度下降(5000个mini-batch,每个mini-batch样本数为1000,总共500w个样本)。
对于batch梯度下降(每次计算所有的样本),随着迭代次数增加,代价不断减少。对于mini-batch梯度下降,mini-batch的迭代过程中,代价是震荡下降的(有时上升有时下降),因为每次下降时只考虑了部分样本,下降方向可能不正确。
mini-batch的size为m时就是batch梯度下降,它的弊端是m很大的时候单次训练需要花费很长的时间。
size为1时就是随机梯度下降(每次只计算一个样本),随机梯度下降在每次梯度下降可能会远离最优点,可能会接近最优点,平均来看会不断靠近最优点,但有时也会方向错误。随机梯度下降最终不会收敛,而是会在最优点附近波动。它的弊端就是失去了向量化带来的加速优势,因为每次只训练一个样本,要用m次循环去迭代。
所以实践中选取不大不小的mini-batch size,这样既利用了向量化的优势,也避免了m太大带来的训练时间太长的弊端。它也会震荡式地靠近最优点,但是相比于随机梯度下降要好很好,最终可能会在最优点附近波动,这个时候可以调整学习率来改善该问题。
数据集小的时候,比如m小于2000,一般直接用batch梯度下降;一般mini-batch的size在64,128,256,512这些值之间考虑(考虑到电脑的内存设置方式,设定为2的次方训练比较快);记得要确保mini-batch的大小要符合你的CPU/GPU大小。
2 指数加权平均(Exponentially weighted averages )
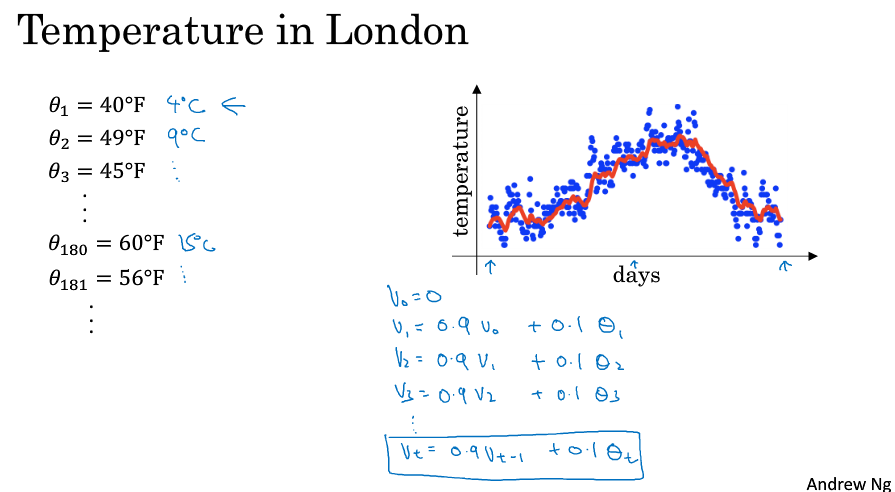
考虑时间和温度的散点关系图,每天的温度为$\Theta _1,\,\Theta _2,...$,对于V, 有$V_0 = 0,V(t) = 0.9 * V_{t-1} + 0.1 * \Theta_t$,即用(前一天的V乘以0.9)加上(当天的温度乘以0.1)。
对V绘制图,如下图中的红线所示,它大致表示了平均10天的温度。
更一般地,把0.9用β表示,0.1用( 1-β )表示,我们说这个V就是平均了$ \frac{1}{1-\beta } $天的温度。如下图所示,红线表示β为0.9,平均了10天;绿线β为0.98,平均了50天,黄线β为0.5,平均了2天。
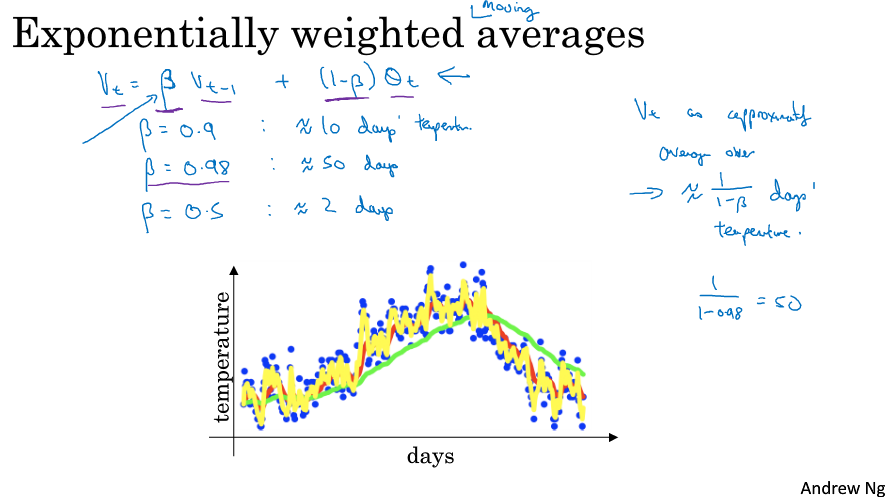
为什么会这样呢,如下图所示,展开了$V_{100}$,可以发现它是对每一天的温度赋予了一定的权重概率然后累加,越前面的天权重越低,实际上在做一个权重衰减。所以它是对温度的一个平均,平均了最近了x天,这个x是多少呢,有个计算方法就是β的x次方约等于$ \frac{1}{e} $,以此求出x,那其实这个x就是$ \frac{1}{1-\beta } $。
另外,ng指出,求指数加权平均并不是最好的,也不是精准的计算平均数的方法,不过它不需要保存最近的所有数据,占用更少内存,从效率上来讲是一个不错的办法。
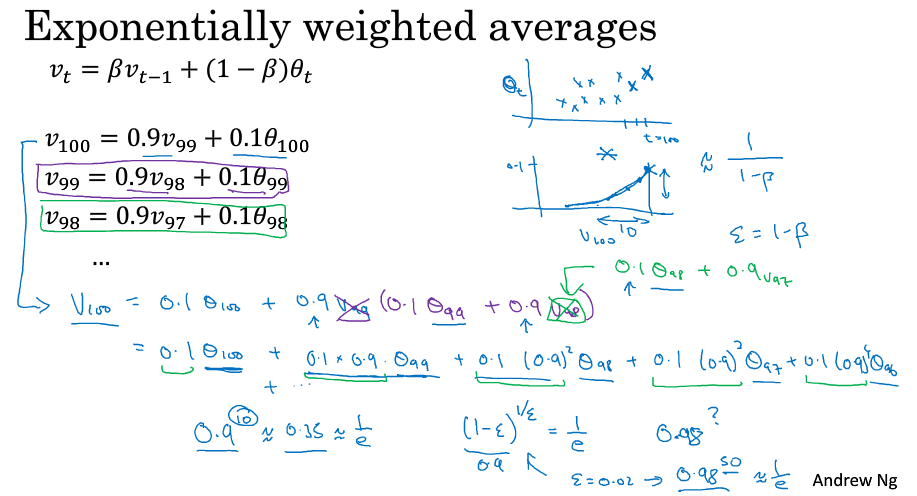
3 指数加权平均的偏差修正(Bias correction in exponentially weighted averages )
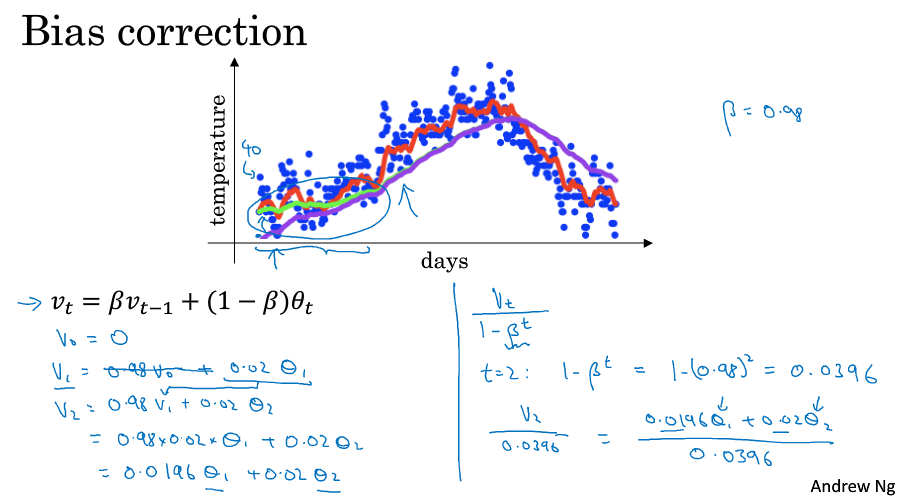
如下图所示,β=0.98时,实际执行上面的计算步骤我们会得到紫色的曲线,而不是绿色曲线,原因就是一开始的时候V=0,所以刚开始的几个点都会偏低,不能做出很好的估计,所以需要做一定的偏差修正,就是让$V_t$除以$( 1 - β^t )$ ,一开始的时候能够起到修正作用,到后面t增大,作为分母的$( 1 - β^t )$ 趋近于1,得到的就是原来的$V_t$了。
在做机器学习的时候,很多时候都不在乎偏差修正,大部分人选择熬过起始时期,如果你在乎起始时期,偏差修正能帮助你得到更好的估测。
4 动量梯度下降(Gradient descent with momentum )
我们把之前学的指数加权平均应用到梯度下降中可以改善问题。
考虑代价函数的等高线如下图所示,使用mini-batch时因为方向不一定是最优方向,所以可能在不断靠近最优点时候会上下波动(下图蓝线),这个时候我们希望在上下方向上用较小的学习步长,在往右方向上使用较大的学习步长,那么可以对求得的梯度做指数加权平均的运算得到一个平均值,这时上下波动求平均,一正一负平均为0,往右前进平均还是往右,在抵达最优点的路上我们减少了动荡,能够以理想的步长去靠近最优点(下图红线)。
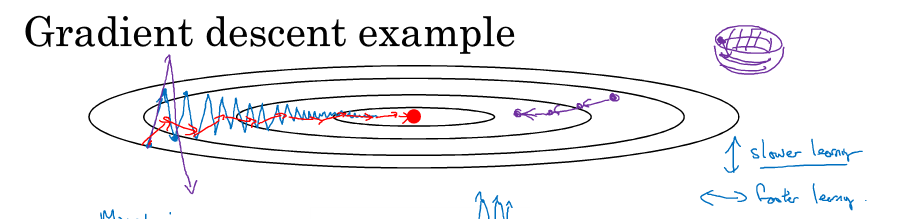
具体怎么做呢?见下图左侧公式,每次做梯度下降时,求一下指数加权平均,用这个平均值来做梯度下降。
这就是加了动量的梯度下降法,它不像之前的梯度下降(每次下降都是独立于之前的步骤),这个时候就有两个超参数,α和β,β一般设为0.9,表示平均了最近10次的迭代速度。
对于动量的理解:把微分dW理解成球往山下滚的加速度,momentum项v理解成速度,球因为加速度越滚越快,β稍小于1可以理解为摩擦力的阻碍,所以球不会无限加速下去。
关于偏差修正,实际上一般不用,因为10次迭代后就不需要修正了,我们平时的学习一般都不会少于10次。
有另一个版本的公式,见下图右侧公式,就是把(1-β)去掉了,缩小了(1-β)倍,ng更喜欢左边的公式,因为右边的公式没那么自然,因为下降时α要根据(1-β)做相应变化。

5 RMSProp(root mean square )
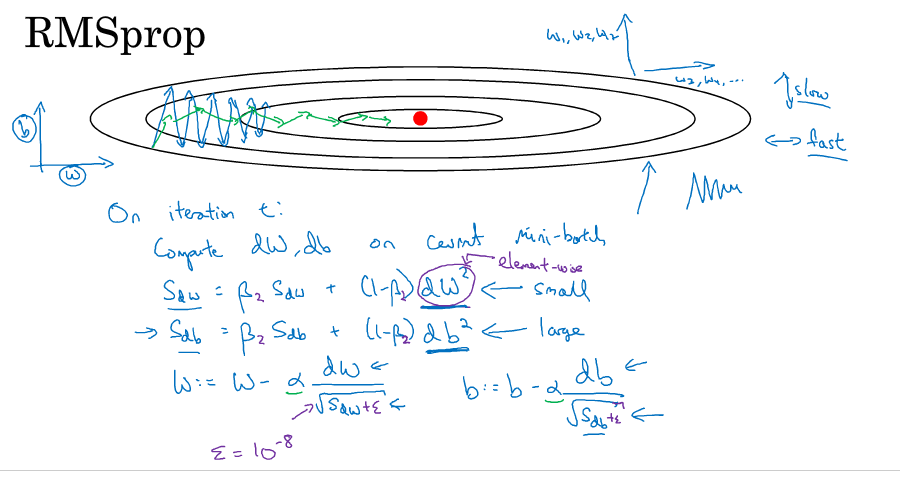
还有一种算法叫RMSProp也可以用来加速mini-batch梯度下降,它是在momentuam的基础上做了修改,公式如下图所示,dW变成dW的平方,在下降的时候多除以了一个根号项。可以理解成竖直方向的微分项比较大,所以除以一个比较大的数,水平方向的微分项比较小,所以除以一个比较小的数,这样就可以消除下降中的摆动,可以采用较大的学习率快速学习。为了确保除以的分母不会为0,在实操上会加上一个很小的数ε。
6 Adam
在深度学习领域,经常有很多新的优化算法被提到然后又遭到质疑。adam和RMSProp是少有的经得起考验的两种优化算法,已经被证明适用于不同的深度学习结构,被用来很好地解决了很多问题。
adam算法基本就是结合了momentum和RMSProp。如下图所示,基本的计算公式和偏差修正不变,V按原来momentum的方法计算,S按原来RMSProp的方法计算,在做梯度下降的时候减去的那一项做了点变动,结合了V和S。
这个方法有比较多的超参数,比如学习率α需要自己调整,β1一般为0.9,β2的话adam的论文作者推荐0.999,ε的话adam的论文作者推荐10的-8次方。在使用adam的时候一般β和ε使用缺省值就可以了。
adam表示adaptive moment estimate,β1用于计算dw微分的平均,称为first moment,β2用于计算dw的平方的平均,称为second moment,adam由此而来。

7 学习率衰减( Learning rate decay )
做学习率衰减的原因很简单,就是梯度下降早期离最优点很远,可以用较大的步长靠近,到了后期,离最优点很近的时候就要小心了,因为你跨一大步可能会跨过头,远离最优点,所以到后面步长要变小,也就是学习率要进行衰减。
学习率衰减的公式如下图所示,$\alpha = \frac{1}{1\;+\;decay\;rate\;*\;epoch\_num}*\;\alpha _0$,衰减率作为新的超参,epoch_num表示迭代了第几轮。
学习率衰减还有其它的一些运算方法,见下图,k是某常数,t表示mini-batch的第几个batch。有些人还会选择手动衰减。
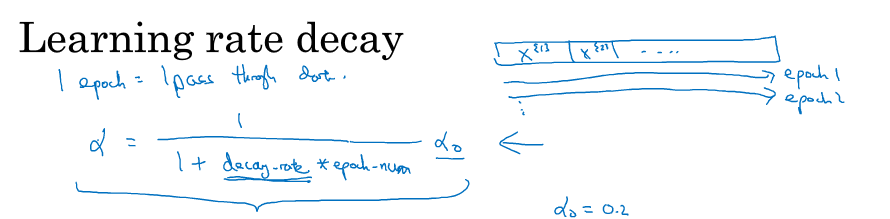

8 局部最优的问题( the problem of local optima )
在深度学习的早期,人们总是担心优化问题会陷入局部最优。随着深度学习理论的发展,我们对局部最优的理解也发生了改变,我们对它的理解也还在不断发展中。
如下图左侧,我们很自然的理解是一个优化问题可能会出现多个局部最优点,我们会担心算法会不会陷入局部最优而无法做出正确的求解。
但这些理解并不正确,事实上,如果你要创建一个神经网络,通常梯度为0的点不会是下图左侧的那些局部最优点,而是下图右侧的这个鞍点。鞍点可以理解为在某一方向上是极大值点,在另一方向上是极小值点,可以想象成马背上的马鞍。
在高维空间中梯度为0的点,在每个方向上可能是凸函数,也可能是凹函数。比如你在2w维空间中你想得到局部最优,所有的2w个方向都需要是这样的,这样的概率太小了。我们更有可能遇到的是有些方向向上弯曲,而另一些方向向下弯曲,如下图右侧,因此在高维空间我们更有可能碰到的是鞍点。
我们从深度学习的历史中了解到,我们在低维空间上的直觉,如下图左侧,并不能应用到高维空间,如下图右侧。
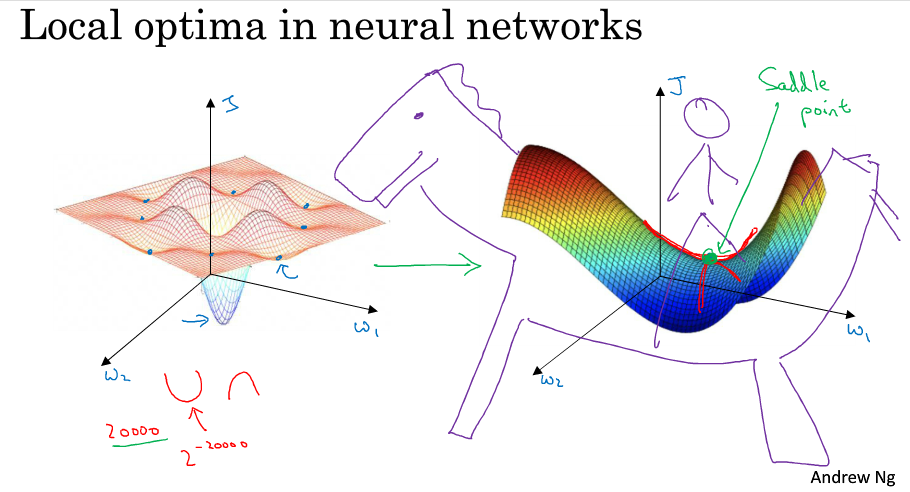
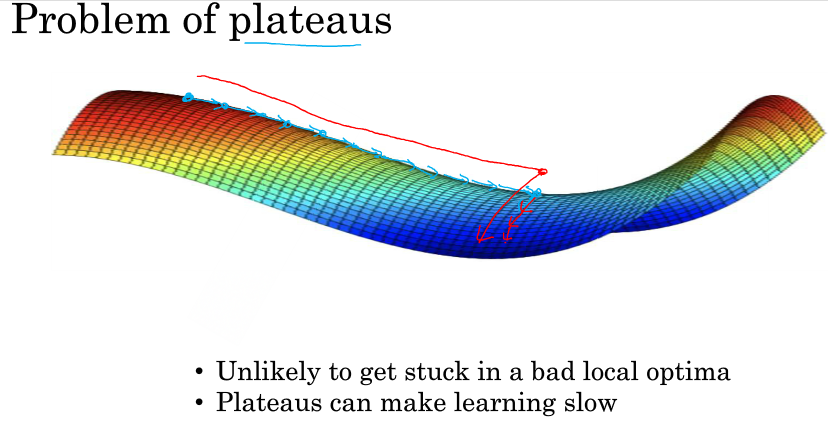
所以在深度学习中(假设你有大量参数,代价函数被定义在高维空间)你不太可能陷入局部极值点,但是位于鞍点这样的平稳地段你可能学习的非常慢,所以才有了momentum,RMSProp,adam这样的算法来加快运算。
ng-深度学习-课程笔记-7: 优化算法(Week2)的更多相关文章
- 深度学习课程笔记(三)Backpropagation 反向传播算法
深度学习课程笔记(三)Backpropagation 反向传播算法 2017.10.06 材料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS1 ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
- 深度学习课程笔记(十五)Recurrent Neural Network
深度学习课程笔记(十五)Recurrent Neural Network 2018-08-07 18:55:12 This video tutorial can be found from: Yout ...
- 深度学习课程笔记(十二) Matrix Capsule
深度学习课程笔记(十二) Matrix Capsule with EM Routing 2018-02-02 21:21:09 Paper: https://openreview.net/pdf ...
- 深度学习课程笔记(七):模仿学习(imitation learning)
深度学习课程笔记(七):模仿学习(imitation learning) 2017.12.10 本文所涉及到的 模仿学习,则是从给定的展示中进行学习.机器在这个过程中,也和环境进行交互,但是,并没有显 ...
- 深度学习课程笔记(十一)初探 Capsule Network
深度学习课程笔记(十一)初探 Capsule Network 2018-02-01 15:58:52 一.先列出几个不错的 reference: 1. https://medium.com/ai% ...
- 深度学习课程笔记(四)Gradient Descent 梯度下降算法
深度学习课程笔记(四)Gradient Descent 梯度下降算法 2017.10.06 材料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS1 ...
- 深度学习课程笔记(二)Classification: Probility Generative Model
深度学习课程笔记(二)Classification: Probility Generative Model 2017.10.05 相关材料来自:http://speech.ee.ntu.edu.tw ...
- 深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE
深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE 201 ...
随机推荐
- Nginx(一)-- 初体验
1.概念 Nginx ("engine x") 是一个高性能的 HTTP 和反向代理服务器,也是一个 IMAP/POP3/SMTP 服务器. Nginx提供基本http服务,可以作 ...
- /etc/rc.d/rc.local
/etc/rc.d/rc.local 用于用户自定义开机启动程序,可以往里写开机要执行的命令或脚本,线上的配置如下: [root@localhost ~]$ cat /etc/rc.d/rc.loca ...
- WebSphere和IHS的安装
环境:CentOS6.5, IP :192.168.0.91 hostname: IHS 1.下载Installation Manage安装包 URL:http://www.ibm.com/devel ...
- Nginx遇上Access Denied提示怎么解决
这几天在摆弄linux下面的各种服务器,对nginx非常有兴趣. 于是把phpmyadmin传上去了,先是phpmyadmin配了半天,结果配好之后发现phpmyadmin一些logo.css.js文 ...
- mysql concat
CONCAT_WS() 代表 CONCAT With Separator ,是CONCAT()的特殊形式. 第一个参数是其它参数的分隔符.分隔符的位置放在要连接的两个字符串之间. 分隔符可以是一个字符 ...
- Swift-属性、方法、下标
存储属性和计算属性 类.结构和枚举都能够定义存储属性和计算属性.其中存储属性就是常见的形式,又分为变量属性和常量属性,如: struct Point { var x = 0.0, y = 0.0 } ...
- 免费在线的web性能测试网站
由于需要测试网站并发,所以去百度搜了搜,最开始找了个webkaka结果告知,已下线,好像是个很好的在线网站.现在只有网站速度诊断的http://pagespeed.webkaka.com/
- java基础---->多线程之synchronized(六)
这里学习一下java多线程中的关于synchronized的用法.我来不及认真地年轻,待明白过来时,只能选择认真地老去. synchronized的简单实例 一. synchronized在方法上的使 ...
- css基础---->学习html(一)
这里零散的总结一下观看css权威指南书的知识.生命中的诸多告别,比不辞而别更让人难过的,是说一句再见,就再也没见过. 一.首字母与首行的伪类 <dvi> <p>I love y ...
- javascript构造函数及原型对象
/** @ javascript中没有类的概念,所以基在对象创建方面与面向对象语言有所不同* @ 对象创建的常用方法及各自的局限性* @ 使用Object或对象字面量创建对象* @ 工厂模式创建对象* ...