爬取掌阅app免费电子书数据
主要介绍如何抓取app数据及抓包工具的使用,能看到这相信你已经有爬虫基础了
编不下去了,主要是我懒,直接开干吧!
一.使用环境和工具
windows + python3 + Jsonpath + Charles + MuMu模拟器
二.下载工具
Charles下载:https://www.charlesproxy.com/latest-release/download.do
MuMu模拟器:http://mumu.163.com/baidu/
三.安装及配置工具
Charles
安装,直接傻瓜式安装就行
配置:
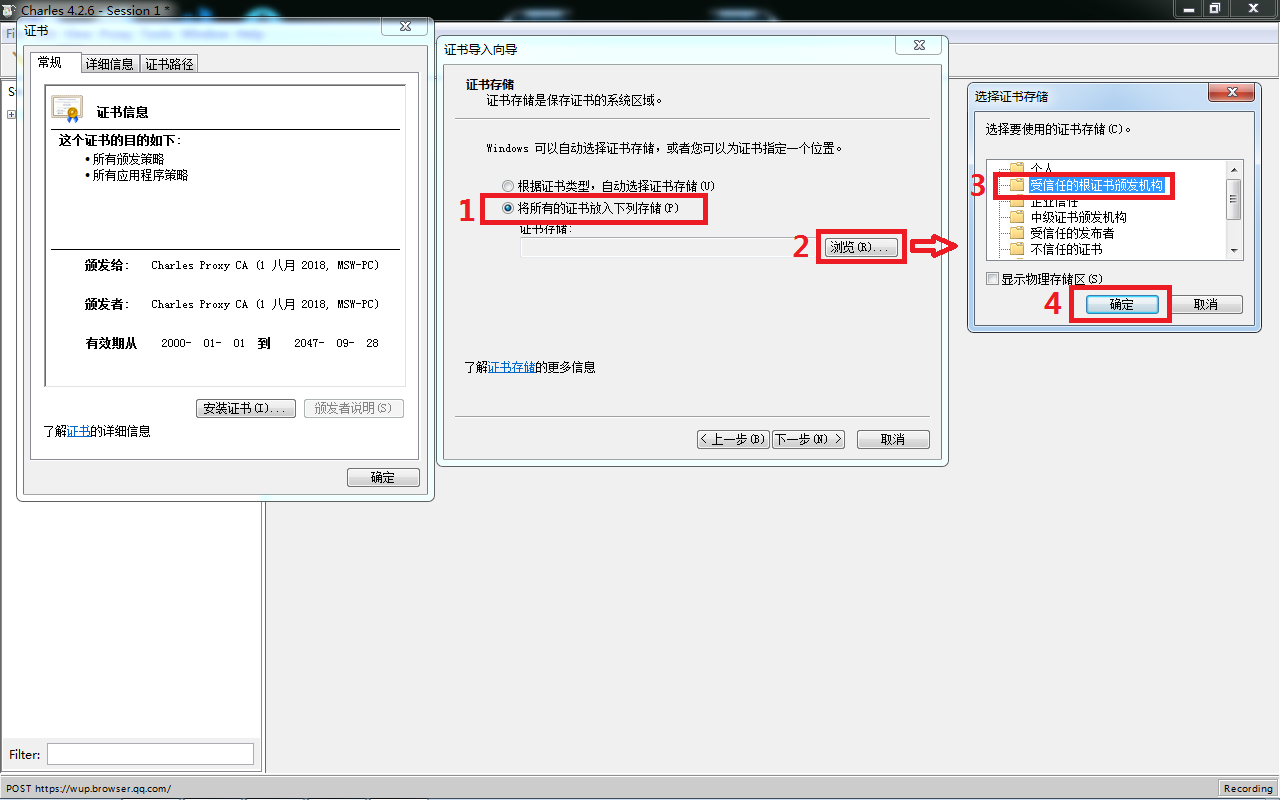
1.打开Charles->点击Help->SSL Procying->Install Charles Root Certificate,即可进入证书安装界面

2.安装证书->下一步->将所有的证书都放入下列存储(P)->浏览->受信任的根证书颁发机构->确定->下一步->完成

3.可设置端口号,一般为默认(如果系统没有其他软件与8888端口冲突,可忽略该步骤)

4.设置SSL代理(如果不设置,后面请求会是有很多443)
Proxy -> SSL Proxying Settings -> Add
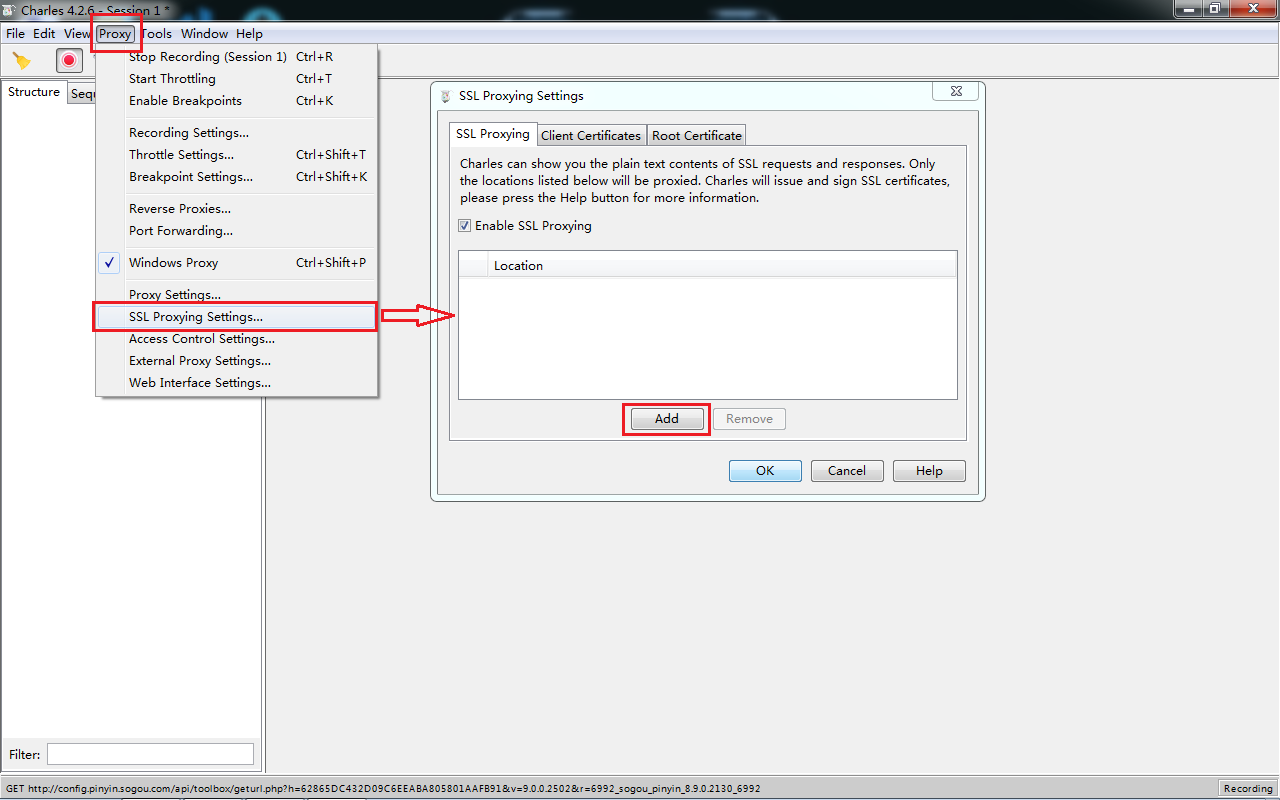
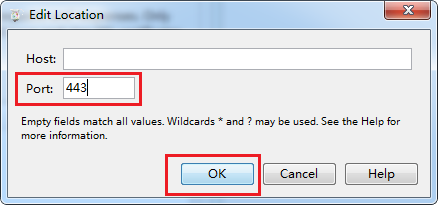
输入端口号443,点击OK
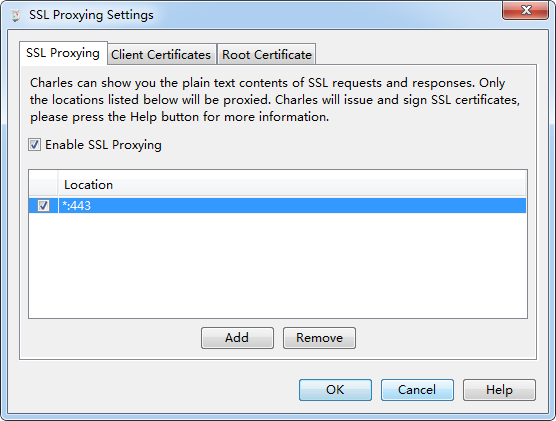
出现下面界面就添加成功了
MuMu模拟器
安装:同样是傻瓜式
配置:
1.设置代理

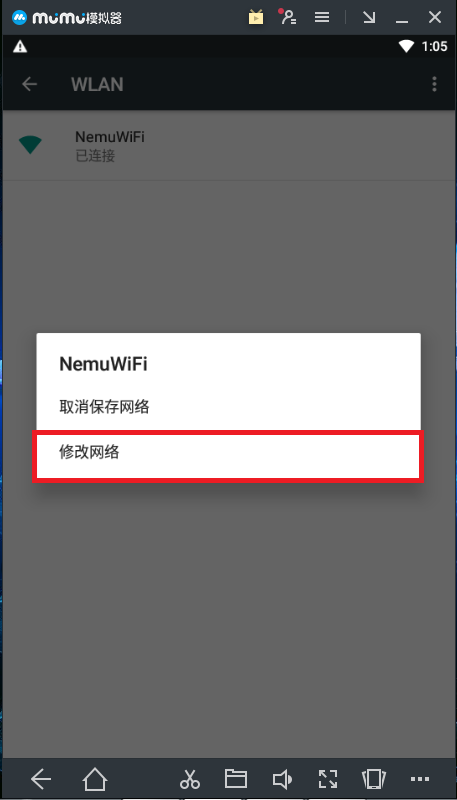

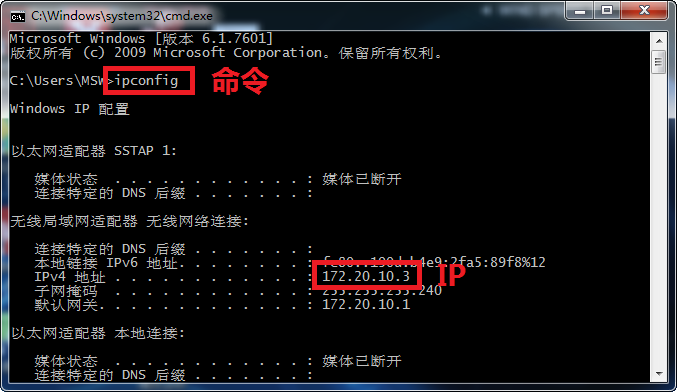
2.获取电脑ip , win + r -> 输入cmd -> 回车
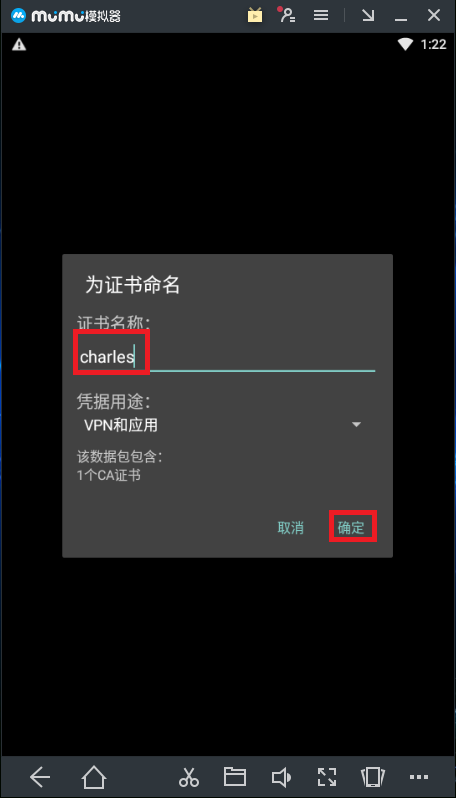
3.安装证书
在虚拟器打开浏览器,输入cals.pro/ssl自动下载证书,下载完成后,点击打开
不出意外的话,工具安装和配置到这里就可以编写爬虫代码了
四.测试及找数据api接口
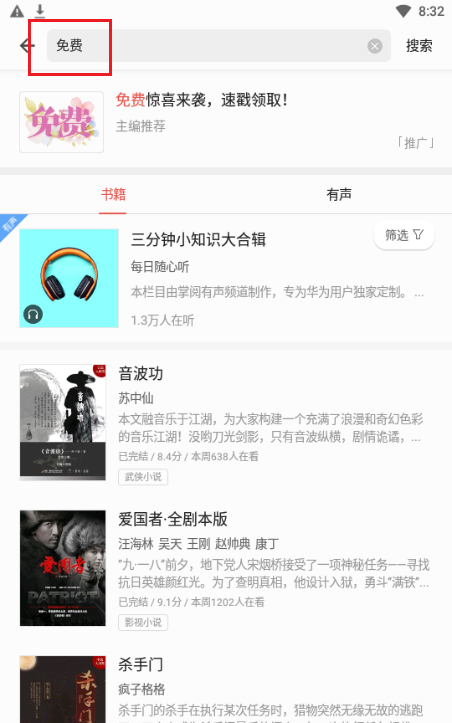
1.首先要打开Charles,再打开模拟器,下载掌阅app,打开模拟器,搜索免费
2.再看Charles软件,会发现左边的选项框中多了,一堆请求地址,随便点击一个,发现这个返回的数据和看到的好像不一样

3.再点下一个,再看看,哎,这个返回的数据好像挺多的,但是有编码问题看不出来是什么
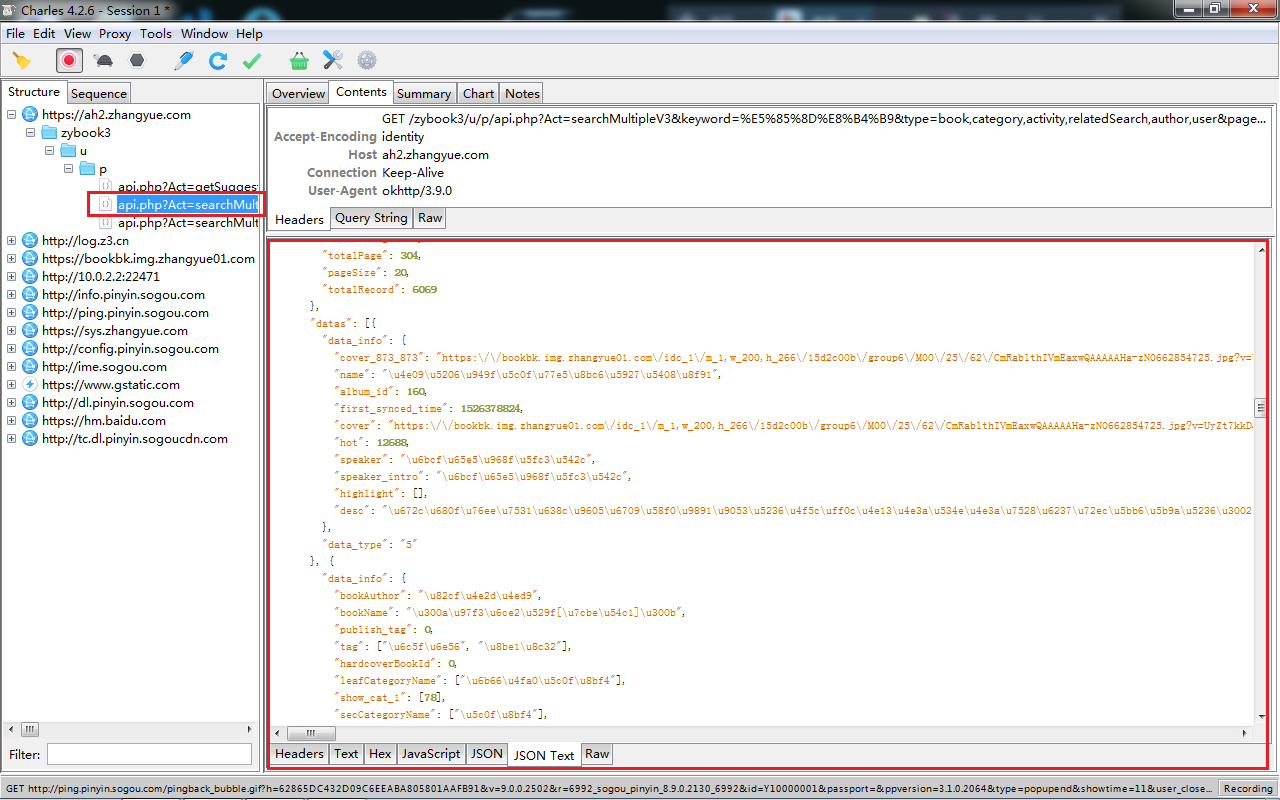
4.复制请求地址
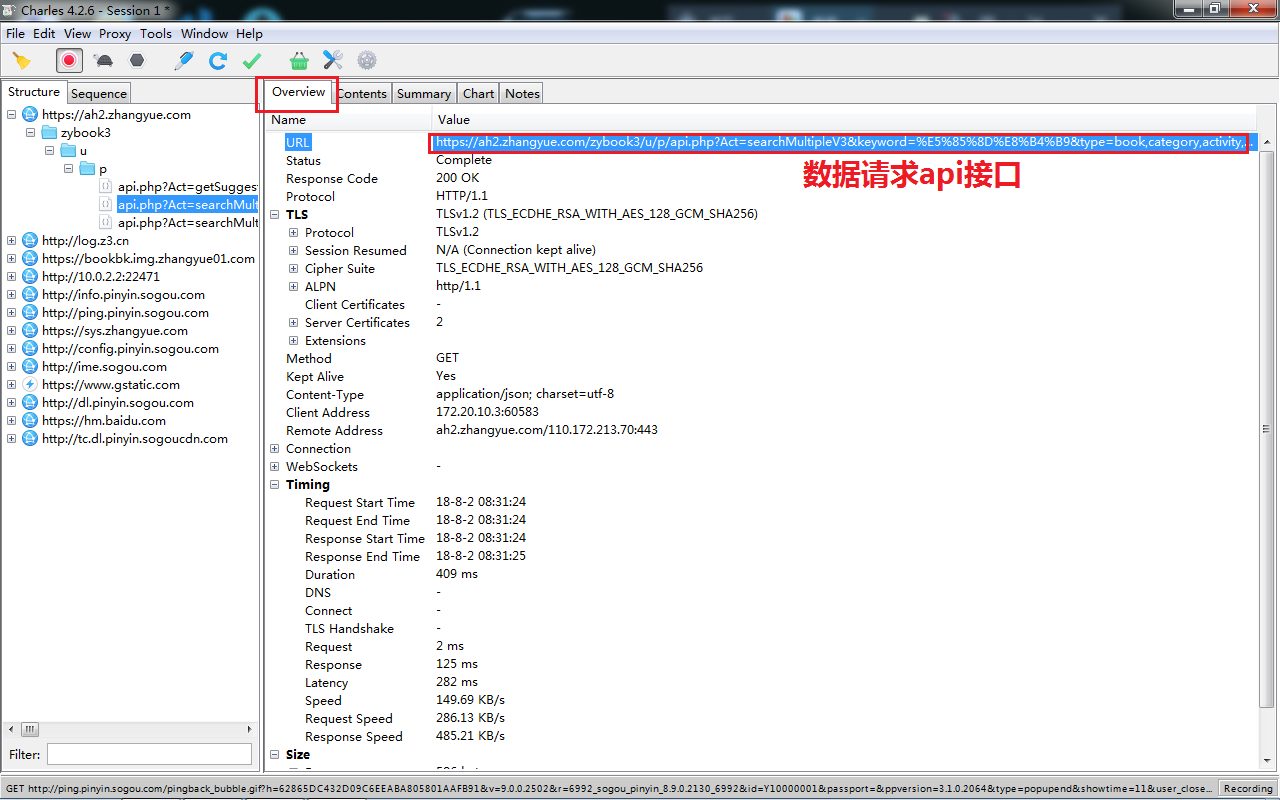
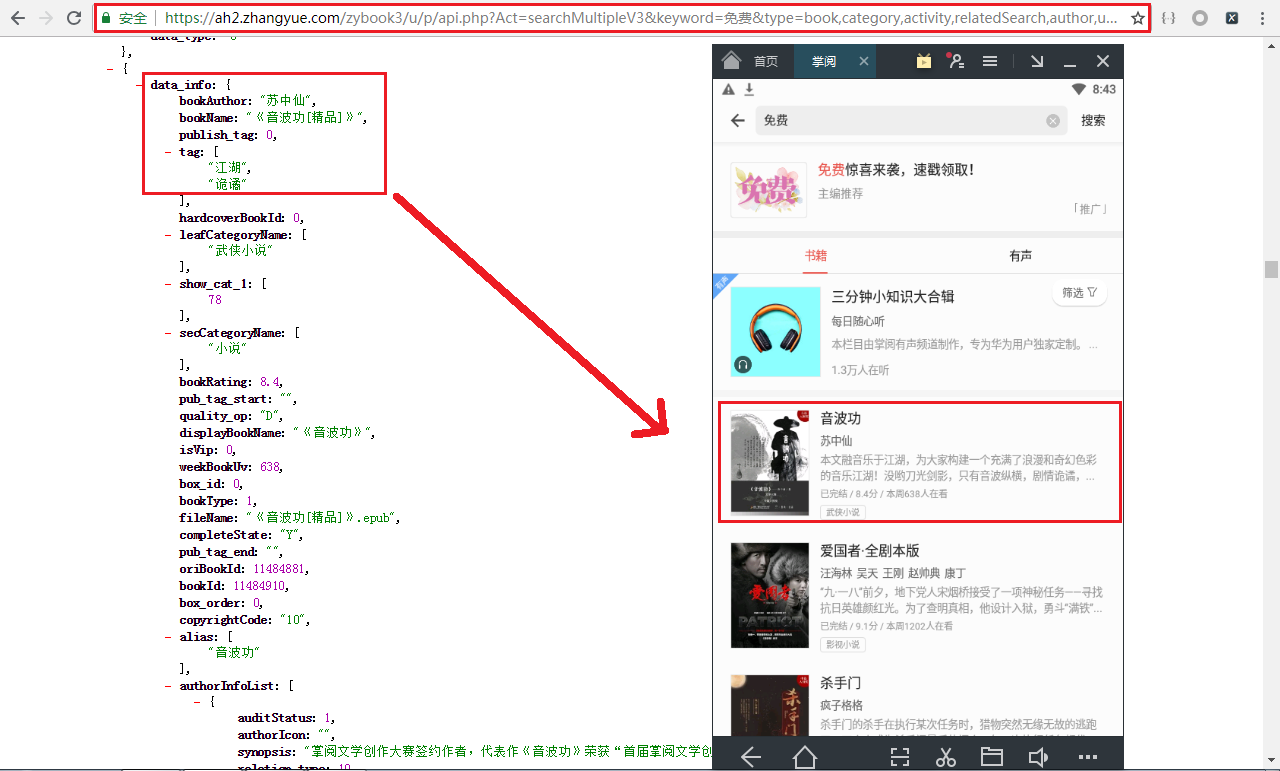
5.将请求地址在浏览器中打开,现在就可以看出来是什么了,会发现这些数据就是我们想要的数据
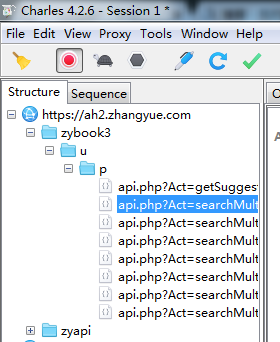
6.在验证一下,打开掌阅往下滑,会发现Charles中多了好多长的差不多的请求地址,这就证明猜测是正确的
五.编写爬虫程序
这里我用的是requests模块,只是开了个头
import requests
import jsonpath
import json # 经分析得知
# pageSize:表示的是每页返回多少条数据,currentPage:表示的是页数
url = 'https://ah2.zhangyue.com/zybook3/u/p/api.php?Act=searchMultipleV3&keyword=%E5%85%8D%E8%B4%B9&type=book,category,activity,relatedSearch,author,user&pageSize=500¤tPage=1'
# 请求头
head= {
"Host": "ah2.zhangyue.com",
"Connection": "Keep-Alive",
"Accept-Encoding": "gzip",
"User-Agent": "okhttp/3.9.0"
}
# 携带请求头请求数据
response = requests.get(url,headers = head)
# 将json数据转为字典
content = json.loads(response.text)
# 使用jsonpath查找元素
res = jsonpath.jsonpath(content,'$.body.book.datas')
# 遍历取出每本书的详细信息
for book in res[0]:
print(book)
返回数据结果:
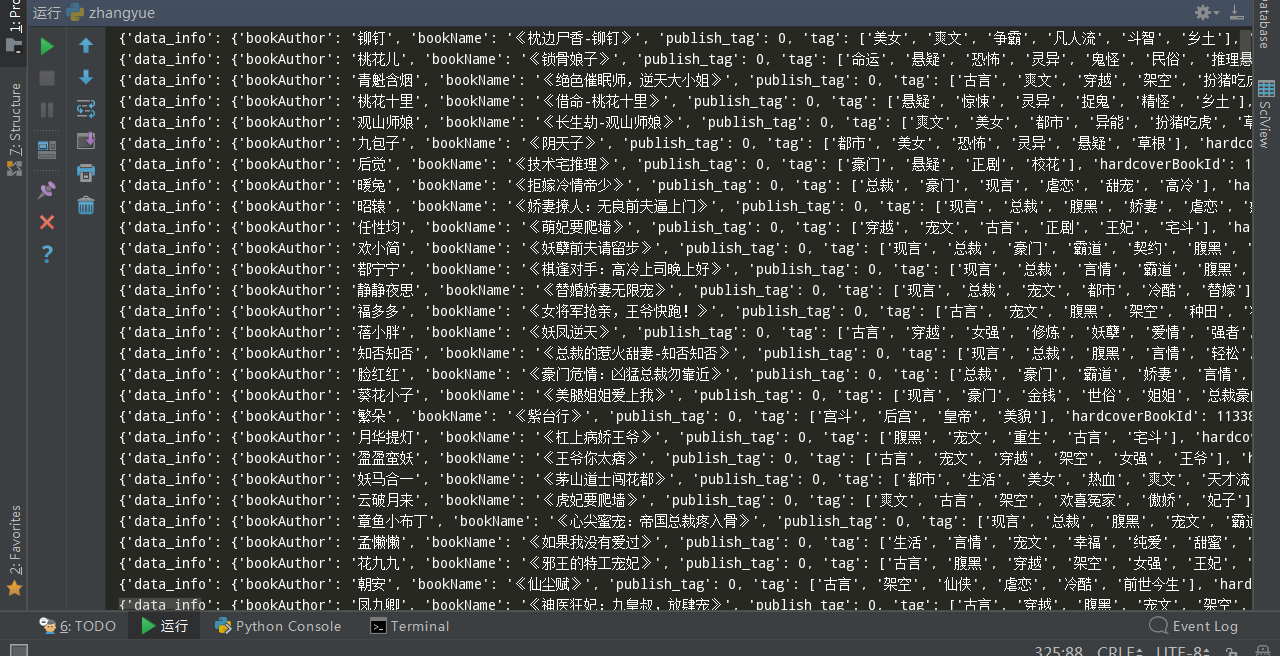
到这里,就可以爬取大部分app数据了
如有问题,欢迎交流
爬取掌阅app免费电子书数据的更多相关文章
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- python爬取抖音APP视频教程
本文讲述爬取抖音APP视频数据(本文未完,后面还有很多地方优化总结) 公众号回复:抖音 即可获取源码 1.APP抓包教程,需要用到fiddler fiddler配置和使用查看>>王者荣耀盒 ...
- python3 爬取汽车之家所有车型数据操作步骤(更新版)
题记: 互联网上关于使用python3去爬取汽车之家的汽车数据(主要是汽车基本参数,配置参数,颜色参数,内饰参数)的教程已经非常多了,但大体的方案分两种: 1.解析出汽车之家某个车型的网页,然后正则表 ...
- python3 爬取boss直聘职业分类数据(未完成)
import reimport urllib.request # 爬取boss直聘职业分类数据def subRule(fileName): result = re.findall(r'<p cl ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- Python爬虫入门教程 42-100 爬取儿歌多多APP数据-手机APP爬虫部分
1. 儿歌多多APP简单分析 今天是手机APP数据爬取的第一篇案例博客,我找到了一个儿歌多多APP,没有加固,没有加壳,没有加密参数,对新手来说,比较友好,咱就拿它练练手,熟悉一下Fiddler和夜神 ...
- 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家.. 1.楼主首先使用Fiddler4来抓取手机抖音app这 ...
- mitdump爬取当当网APP图书目录
因为mitmproxy没办法连接数据库所以,只能先把结果保存为txt文件,再读取到数据库中. 在滑动APP界面时,对代码进行分析 import requests import re import ur ...
- Python 爬取 热词并进行分类数据分析-[数据修复]
日期:2020.02.01 博客期:140 星期六 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
随机推荐
- JS----文档对象模型
DOM: document object model 文档对象模型提供了一套可以访问和修改HTML文档内容的方法 访问:获取 修改:设置 1 JS要去操作HTML元素,必须要先用JS找到他,转换为JS ...
- js正则表达式子校验
//正则表达式校验new RegExp(/^[1-9]\d{4,8}$/,"g").test(1234);//执行一个字符串所表达的方法 eval(this['字符串']) 正则表 ...
- js 统计数组中元素的个数
var all = "02 06 11 12 19 29 09 10 12 19 22 29 08 11 13 19 28 31 07 08 09 15 22 27 10 18 19 29 ...
- Bootstrap 导航元素(标签页)
[Bootstrap 导航元素] 1.基本的导航元素:标签导航.基于ul.li而来,给ul添加 class="nav nav-tabs" 即可.选中的li添加 class=&quo ...
- C#单例和Unity单例
单例是一种设计模式 单例:不管在项目中的任何模块,当需要使用某个对象的时候,获取到的始终是同一个对象 在C#中 public class InstanceDemo{ private static In ...
- Java基础学习笔记(三)
18.2.1无参无返回值的方法 18.2.1.1定义方法的语法格式 public static void 方法名称(){ 方法体 } 方法调用 类名.方法名称(); 注意:在Java中,同一个类中的方 ...
- python全栈 字典数据类型相关知识及操作
python 全栈开发 一.字典 1. 字典的概念: 字典 : dict 用 {} 来表示, 键位值数据. { key , value } 具有唯一性. 键:都必须是可哈希的 不可变 ...
- JMeter调试工具--Debug Sampler(转载)
转载自 http://www.cnblogs.com/fengpingfan Debug Sampler添加路径:[添加 / Sampler / Debug Sampler],面板设置如下: 打开JM ...
- 全国高校绿色计算大赛 预赛第一阶段(C++)第3关:旋转数组
挑战任务 在计算机中,一张数字图像,可以被看做是一个矩阵或者说数组. 学过线性代数的同学对矩阵肯定不陌生.一般来说,图像是一个标准的矩形,有着宽度(width)和高度(height).而矩阵有着行(r ...
- pta7-20 畅通工程之局部最小花费问题(Kruskal算法)
题目链接:https://pintia.cn/problem-sets/15/problems/897 题意:给出n个城镇,然后给出n×(n-1)/2条边,即每两个城镇之间的边,包含起始点,终点,修建 ...