基于tomcat的solr环境搭建(Linux)
♥♥ solr是基于lucene的一个全文检索服务器,提供了一些类似webservice的API接口,用户可以通过http请求solr服务器,进行索引的建立和索引的搜索。
索引建立的过程:用户提交的文本会经过分词器进行分词,分词后的关键字会存到索引库里,索引库是关键字和目标文档的映射集。
索引搜索的过程:用户提交的搜索文本也是会经过分析器,得到的关键字会去索引库查询对应的目标文档并返回给客户端,采用的是权重排序算法。
solr和lucene的区别:lucene是一些搜索工具包,任何应用可以引进这些jar包实现自己的搜索引擎系统,而solr是基于lucene的,封装好的搜索引擎系统。lucene需要自己维护索引文件。
solr几个重要的配置文件:solrconfig、schema.xml数据库配置文件、data-config(自定义,用于数据从数据库导入到solr)
Lucene专注于搜索底层的建设,而Solr专注于企业应用。
1.solr的安装

2.中文分词器的安装
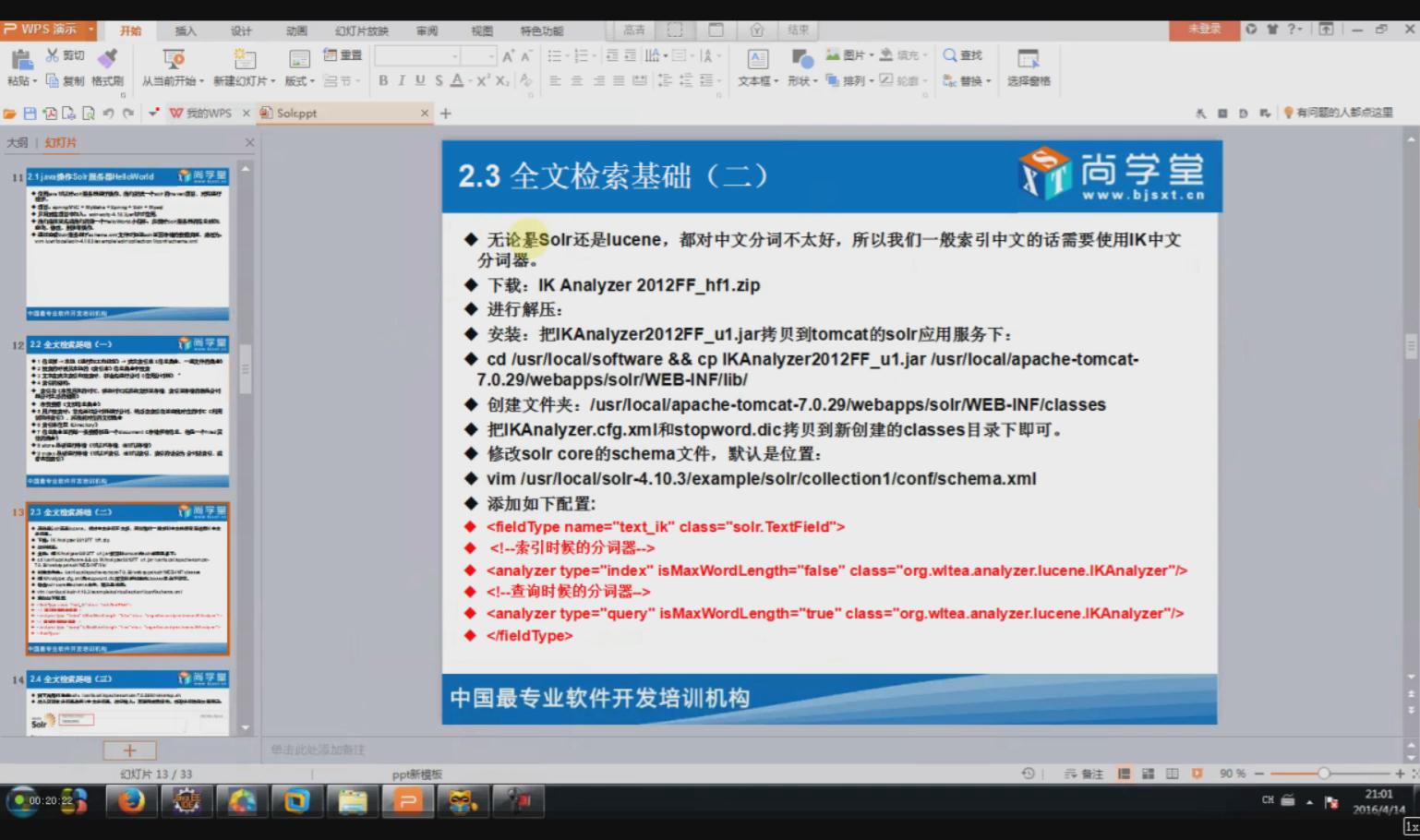
配置信息:
<!--中文分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
3.1 DIH全量同步
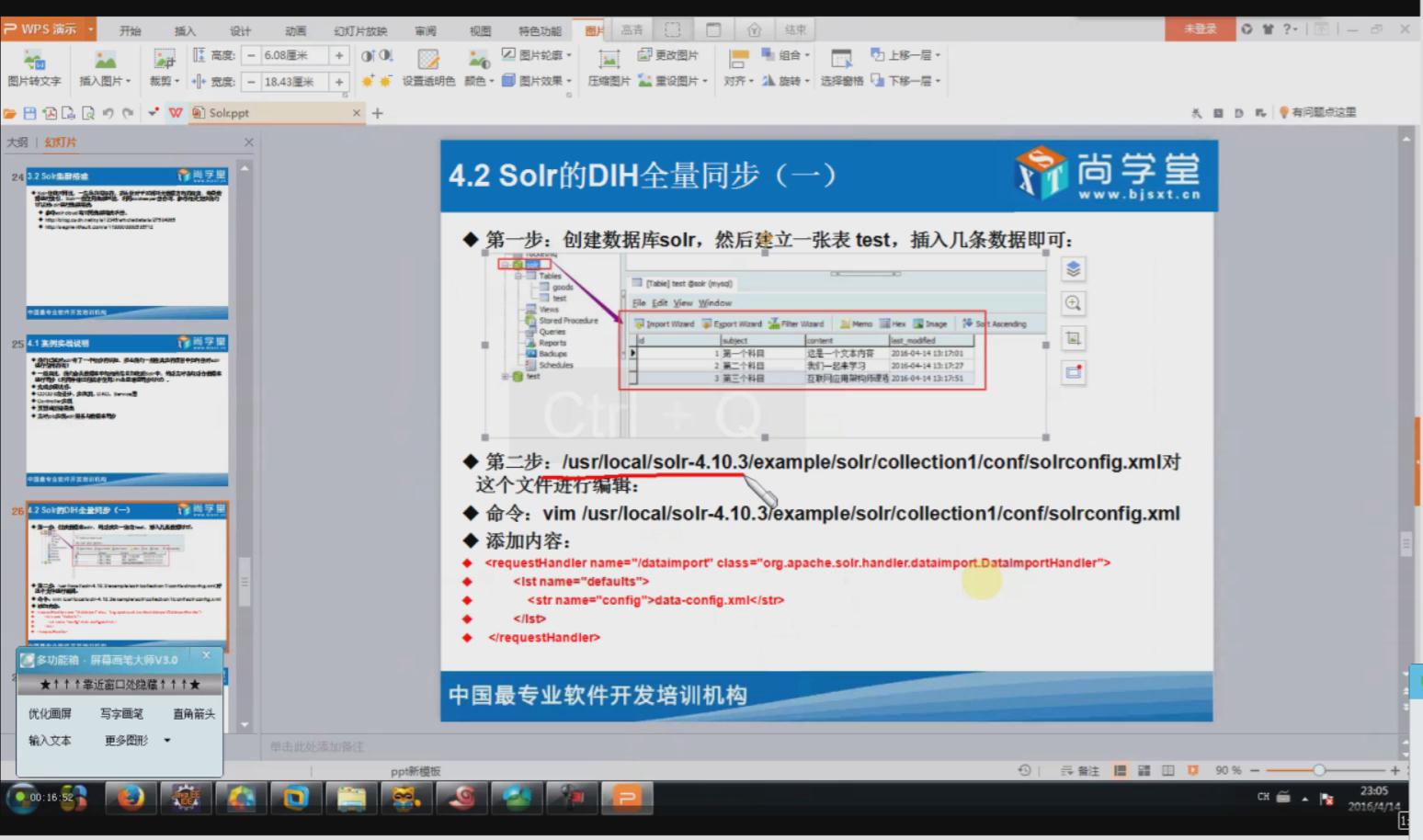
相关配置信息:
<!-- 数据导入配置 -->
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
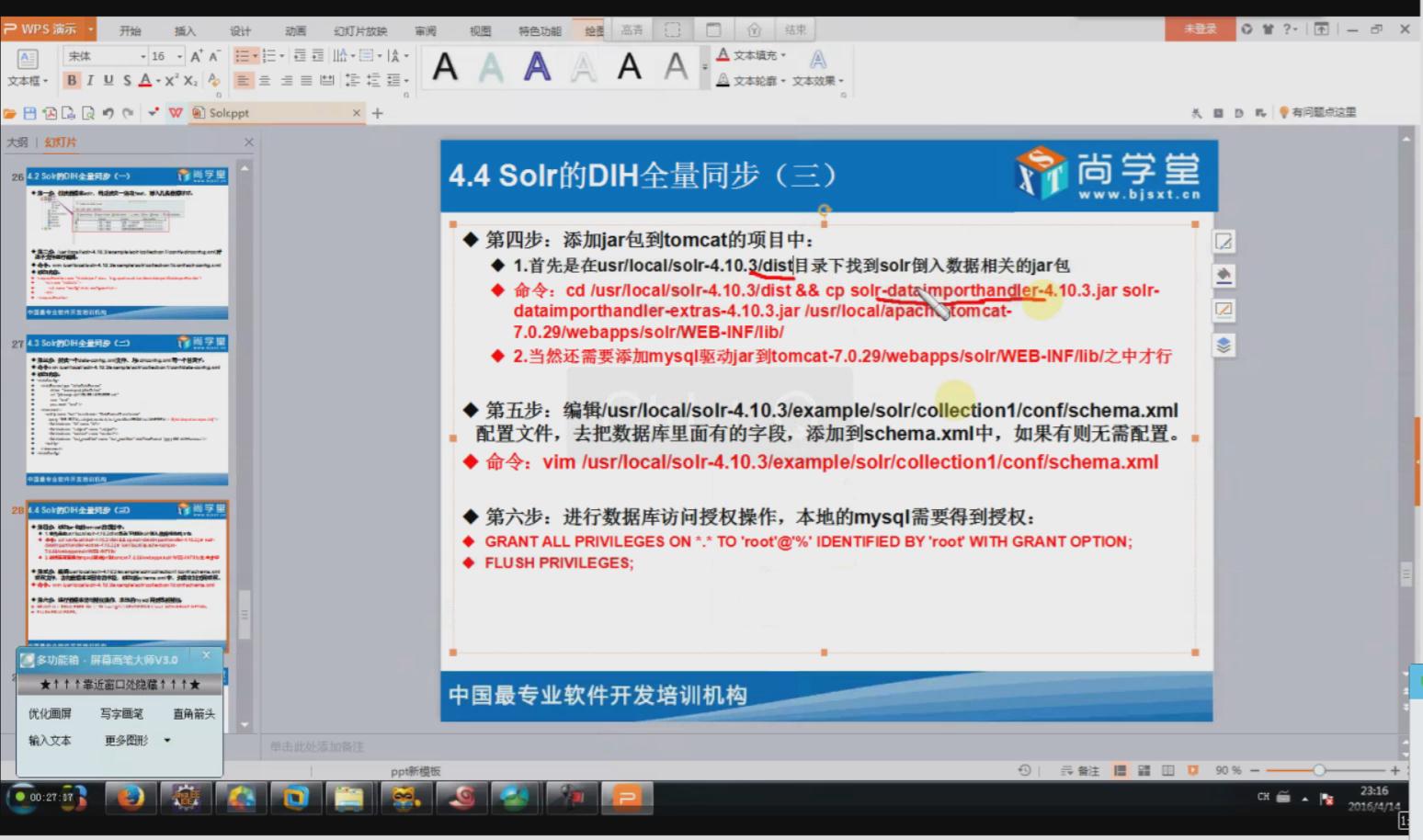
3.2

相关配置信息:
3.3 schema.xml同步字段配置
相关配置信息:
<!-- 同步mysql爬虫表的字段 -->
<field name="create_date" type="date" indexed="true" stored="true"/>
<field name="update_date" type="date" indexed="true" stored="true"/>
<field name="news_url" type="text_general" indexed="true" stored="true"/>
<field name="news_origin" type="text_general" indexed="true" stored="true"/>
<field name="key_word" type="text_general" indexed="true" stored="true"/>
<field name="news_html" type="text_ik" indexed="true" stored="true"/>
<field name="is_publish" type="int" indexed="true" stored="true"/>
<field name="is_del" type="int" indexed="true" stored="true"/>
<field name="flag_number" type="text_general" indexed="true" stored="true"/>
<field name="out_line" type="text_ik" indexed="true" stored="true"/>
<field name="state" type="int" indexed="true" stored="true"/>
<!-- 同步mysql爬虫表的字段end -->
4.1DIH的增量同步(其实就是修改data-config.xml配置文件)
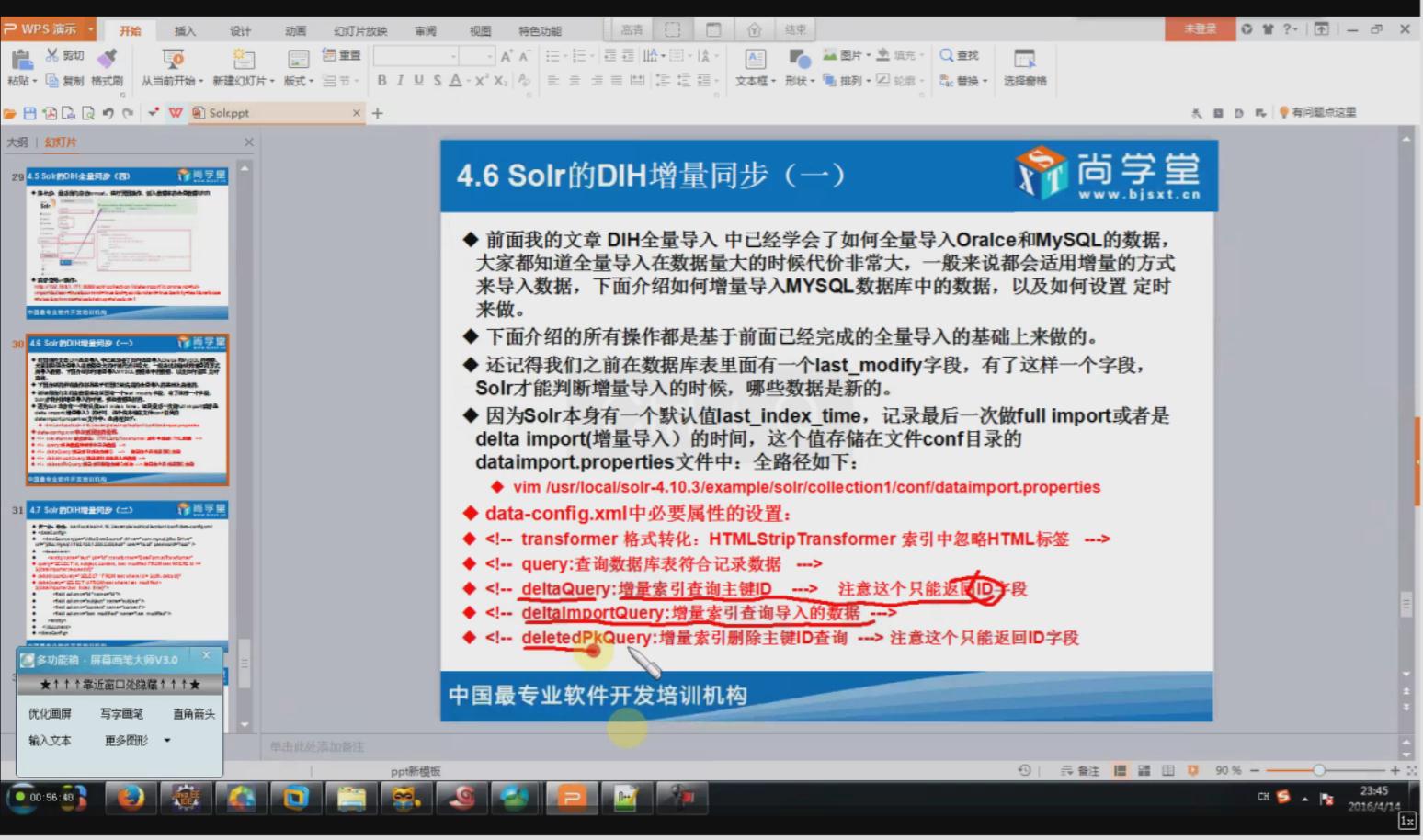
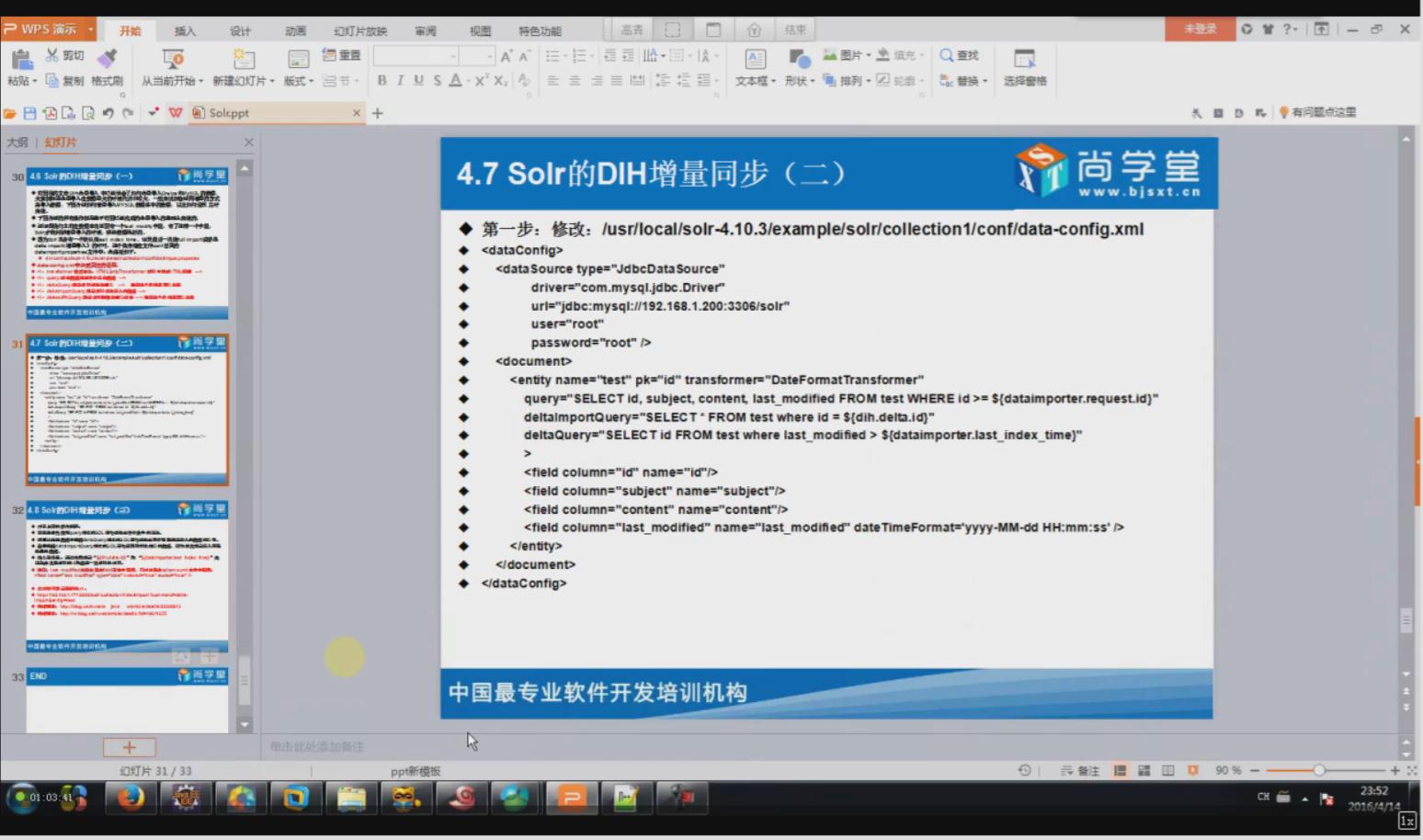
相关配置信息:
<dataConfig>
<dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://192.168.40.1:3306/shanghang" user="root" password="root" />
<document>
<entity name="consensus_data2" pk="id" transformer="DateFormatTransformer" query="select * from consensus_data2 where id >= '${dataimporter.request.id}'"
deltaImportQuery="select * from consensus_data2 where id = '${dih.delta.id}'"
deltaQuery="select id from consensus_data2 where create_date > '${dataimporter.last_index_time}'">
<field column="id" name="id" />
<field column="create_date" name="create_date" dateTimeFormat='yyyy-MM-dd HH:mm:ss'/>
<field column="update_date" name="update_date" dateTimeFormat='yyyy-MM-dd HH:mm:ss' />
<field column="news_url" name="news_url" />
<field column="news_origin" name="news_origin" />
<field column="keyWord" name="key_word" />
<field column="news_html" name="news_html" />
<field column="is_publish" name="is_publish" />
<field column="is_del" name="is_del" />
<field column="flag_number" name="flag_number" />
<field column="out_line" name="out_line" />
<field column="state" name="state" />
</entity>
</document>
</dataConfig>

基于tomcat的solr环境搭建(Linux)的更多相关文章
- jdk、tomcat、solr环境搭建
环境概述 1)操作系统:windows7旗舰版(64位) 2)jdk:jdk-8u131-windows-x64: 3)tomcat:apache-tomcat-9.0.0.M21 4)solr:so ...
- solr环境搭建
介绍摘自百度百科:Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口.用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引:也可以通过 ...
- Ubuntu 基于Docker的TensorFlow 环境搭建
基于Docker的TensorFlow 环境搭建 基于(ubuntu 16.04LTS/ubuntu 14.04LTS) 一.docker环境安装 1)更新.安装依赖包 sudo apt-get up ...
- EOS Dapp开发(1)-基于Docker的开发环境搭建
随着EOS主网的上线,相信基于EOS的Dapp开发会越来越多,查阅了很多资料相关的开发资料都不是很多,只能自己摸索,按照网上仅有的几篇教程,先git clonehttps://github.com/E ...
- centos LAMP第一部分-环境搭建 Linux软件删除方式,mysql安装,apache,PHP,apache和php结合,phpinfo页面,ldd命令 第十九节课
centos LAMP第一部分-环境搭建 Linux软件删除方式,mysql安装,apache,PHP,apache和php结合,phpinfo页面,ldd命令 第十九节课 打命令之后可以输入: e ...
- 基于Python的Appium环境搭建合集
自动化一直是测试圈中的热聊,也是大家追求的技术方向.在测试中,往往回归测试也是测试人员的“痛点”.对于迭代慢.变更少的功能,就能用上自动化来替代人工回归,减轻工作量. 问题 在分享环境搭建之前,先抛出 ...
- [精华]Hadoop,HBase分布式集群和solr环境搭建
1. 机器准备(这里做測试用,目的准备5台CentOS的linux系统) 1.1 准备了2台机器,安装win7系统(64位) 两台windows物理主机: 192.168.131.44 adminis ...
- Solr环境搭建过程中遇到的问题
Solr下载地址:http://www.apache.org/dyn/closer.lua/lucene/solr/6.3.0 Solr搭建步骤转自:http://blog.csdn.net/wbcg ...
- Java部署环境搭建(Linux)
环境搭建必须jdk.tomcat.mysql(基础) 额外的软件包项目中可能用到 jdk:它包含jre和开发所需完整类库. tomcat:它是一个web容器,项目通常往webapps下扔,便于外界访问 ...
随机推荐
- MVC003之调用BLL层方法(BLL层调用了WebService)
项目又BLL类库,在类库中引用了webservice.在web层调用BLL的方法时 错误如下: 在 ServiceModel 客户端配置部分中,找不到引用协定“OAService.IntranetSe ...
- 解题1(Suduku)
题目描述 问题描述:数独(Sudoku)是一款大众喜爱的数字逻辑游戏.玩家需要根据9X9盘面上的已知数字,推算出所有剩余空格的数字,并且满足每一行.每一列.每一个粗线宫内的数字均含1-9,并且不重复. ...
- FileReader.FileWriter 执行文本复制
//导包动作必须做,否则会出现大片错误提示 import java.io.*; class FileReaderDemo { publicstatic void main(String[] args) ...
- TOJ3216 我要4444
传送门 http://acm.tzc.edu.cn/acmhome/problemdetail.do?&method=showdetail&id=3216 时间限制(普通/Java) ...
- PHP连接数据库(mysql)
前端链接后台,数据库几乎必不可少.所以本文总结了PHP链接数据库的常用方法步骤. 首先 链接数据库:mysqli_connect参数①主机地址 ②mysql用户名③nysql密码④选择连接的数据库⑤端 ...
- .py文件右键添加Edit with IDLE
1.打开注册表(regedit) 2.找到这个目录:HKEY_CLASSES_ROOT\SystemFileAssociations 3.找到.py的项,逐层新建 4.shell和edit,默认值改为 ...
- Disruptor并发框架简介
Martin Fowler在自己网站上写一篇LMAX架构的文章,在文章中他介绍了LMAX是一种新型零售金额交易平台,它能够以很低的延迟产生大量交易.这个系统是建立在JVM平台上,其核心是一个业务逻辑处 ...
- EOJ Monthly 2018.7 B.锐角三角形(数学几何+思维)
描述 是否存在面积为S/2的整点锐角三角形?存在输出Yes并输出三个整点坐标,否则输出No. 注意如果存在输出的坐标必须在long long范围内. Input 第一行一个整数S(1<=S< ...
- UVa 536 Tree Recovery(二叉树后序遍历)
Little Valentine liked playing with binary trees very much. Her favorite game was constructing rando ...
- [剑指Offer]58-翻转字符串
题目一 翻转单词顺序 题意 输入一个英文句子,翻转句子中的单词的顺序,但单词内自负的顺序不变.标点符号和普通字母一样处理. 例: 输入:"I am a student." 输出:& ...