采集baidu搜索信息的java源代码实现(大部分转发,少量自己修改)(使用了htmlunit和Jsoup)(转发:https://blog.csdn.net/zhaohang_1/article/details/44731039)
1.maven依赖
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.zhaowu</groupId>
<artifactId>pachong01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.3</version>
</dependency> <!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.2</version>
</dependency> <!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency> <!-- https://mvnrepository.com/artifact/org.quartz-scheduler/quartz -->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.0</version>
</dependency> <!-- https://mvnrepository.com/artifact/cn.edu.hfut.dmic.webcollector/WebCollector -->
<dependency>
<groupId>cn.edu.hfut.dmic.webcollector</groupId>
<artifactId>WebCollector</artifactId>
<version>2.71</version>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.poi/poi -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.17</version>
</dependency> <!-- https://mvnrepository.com/artifact/net.sourceforge.htmlunit/htmlunit -->
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.29</version>
</dependency> </dependencies>
</project>
2.建立项目
3.观察网页内容




 ,pn=1(第二页),pn=2(第三页)...,并且其他的部分是相同的,也就是是说,直接替换掉数字就可以定位到该页。
,pn=1(第二页),pn=2(第三页)...,并且其他的部分是相同的,也就是是说,直接替换掉数字就可以定位到该页。4.好,来代码!
- package bdsearch;
- import java.io.BufferedReader;
- import java.io.IOException;
- import java.io.InputStreamReader;
- import java.net.MalformedURLException;
- import java.net.URL;
- import java.util.ArrayList;
- import org.jsoup.Jsoup;
- import org.jsoup.nodes.Element;
- import org.jsoup.select.Elements;
- import com.gargoylesoftware.htmlunit.BrowserVersion;
- import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
- import com.gargoylesoftware.htmlunit.WebClient;
- import com.gargoylesoftware.htmlunit.html.HtmlInput;
- import com.gargoylesoftware.htmlunit.html.HtmlPage;
- ///////////////关于htmlunit的相关资料,在此站上有些资料,参考了一下:http://www.cnblogs.com/cation/p/3933408.html
- public class HtmlUnitforBD {
- private static int N = 3;// 搜索页数
- private static String keyW = "习大大";// 搜索词
- private static HtmlPage firstBaiduPage;// 保存第一页搜索结果
- private static String format = "";// Baidu对应每个搜索结果的第一页第二页第三页等等其中包含“&pn=1”,“&pn=2”,“&pn=3”等等,提取该链接并处理可以获取到一个模板,用于定位某页搜索结果
- private static ArrayList<String> eachurl = new ArrayList<String>();// 用于保存链接
- public static void main(String[] args) throws Exception {
- mainFunction(N, keyW);
- }
- public static void mainFunction(final int n, final String keyWord) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
- Thread thread = new Thread(new Runnable() {
- @Override
- public void run() {
- int x = n;// 页数
- System.out.println("要提取百度关于“" + keyWord + "”搜索结果的前" + x + "页");
- /*
- * 1.获取并输出第一页百度查询内容
- */
- Elements firstPageURL = null;
- try {
- firstPageURL = getFirstPage(keyWord);
- } catch (FailingHttpStatusCodeException | IOException e) {
- e.printStackTrace();
- }// 定义firstPageURL作为第一个搜索页的元素集
- for (Element newlink : firstPageURL) {
- String linkHref = newlink.attr("href");// 提取包含“href”的元素成分,JSoup实现内部具体过程
- String linkText = newlink.text();// 声明变量用于保存每个链接的摘要
- if (linkHref.length() > 14 & linkText.length() > 2) {// 去除某些无效链接
- System.out.println(linkHref + "\n\t\t摘要:" + linkText);// 输出链接和摘要
- eachurl.add(linkHref);// 作为存储手段存储在arrayList里面
- // try {
- // String temp = "";
- // try {
- // transURLtoINFO.trans(linkHref, temp);
- // } catch (IOException e) {
- // // TODO Auto-generated catch block
- // e.printStackTrace();
- // }
- // } catch (FailingHttpStatusCodeException e) {
- // e.printStackTrace();
- // }
- }
- }
- /*
- * 2.读取第二页及之后页面预处理
- */
- nextHref(firstBaiduPage);// 以firstBaiduPage作为参数,定义format,即网页格式。
- /*
- * 3.获取百度第一页之后的搜索结果
- */
- for (int i = 1; i < x; i++) {
- System.out.println("\n************百度搜索“" + keyW + "”第" + (i + 1) + "页结果************");
- String tempURL = format.replaceAll("&pn=1", "&pn=" + i + "");// 根据已知格式修改生成新的一页的链接
- System.out.println("该页地址为:" + format.replaceAll("&pn=1", "&pn=" + i + ""));// 显示该搜索模板
- HtmlUnitforBD h = new HtmlUnitforBD();
- String htmls = h.getPageSource(tempURL, "utf-8");// 不知为何此处直接用JSoup的相关代码摘取网页内容会出现问题,所以采用新的编码来实现摘取网页源码
- org.jsoup.nodes.Document doc = Jsoup.parse(htmls);// 网页信息转换为jsoup可识别的doc模式
- Elements links = doc.select("a[data-click]");// 摘取该页搜索链接
- for (Element newlink : links) {// 该处同上getFirstPage的相关实现
- String linkHref = newlink.attr("href");
- String linkText = newlink.text();
- if (linkHref.length() > 14 & linkText.length() > 2) {// 删除某些无效链接,查查看可发现有些无效链接是不包含信息文本的
- System.out.println(linkHref + "\n\t\t摘要:" + linkText);
- eachurl.add(linkHref);// 作为存储手段存储在arrayList里面
- // try {
- // String temp = "";
- // try {
- // transURLtoINFO.trans(linkHref, temp);
- // } catch (IOException e) {
- // // TODO Auto-generated catch block
- // e.printStackTrace();
- // }
- // } catch (FailingHttpStatusCodeException e) {
- // e.printStackTrace();
- // }
- }
- }
- }
- System.out.println("\n\n\n输出所有地址");
- for (String xx : eachurl) {
- System.out.println(xx);
- }
- return;
- }
- });
- thread.start();
- }
- /*
- * 获取百度搜索第一页内容
- */
- public static Elements getFirstPage(String w) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
- // 创建Web Client
- String word = w;
- WebClient webClient = new WebClient(BrowserVersion.CHROME);
- webClient.getOptions().setJavaScriptEnabled(false);// HtmlUnit对JavaScript的支持不好,关闭之
- webClient.getOptions().setCssEnabled(false);// HtmlUnit对CSS的支持不好,关闭之
- HtmlPage page = (HtmlPage) webClient.getPage("http://www.baidu.com/");// 百度搜索首页页面
- HtmlInput input = (HtmlInput) page.getHtmlElementById("kw");// 获取搜索输入框并提交搜索内容(查看源码获取元素名称)
- input.setValueAttribute(word);// 将搜索词模拟填进百度输入框(元素ID如上)
- HtmlInput btn = (HtmlInput) page.getHtmlElementById("su");// 获取搜索按钮并点击
- firstBaiduPage = btn.click();// 模拟搜索按钮事件
- String WebString = firstBaiduPage.asXml().toString();// 将获取到的百度搜索的第一页信息输出
- org.jsoup.nodes.Document doc = Jsoup.parse(WebString);// 转换为Jsoup识别的doc格式
- System.out.println("************百度搜索“" + word + "”第1页结果************");// 输出第一页结果
- Elements links = doc.select("a[data-click]");// 返回包含类似<a......data-click=" "......>等的元素,详查JsoupAPI
- return links;// 返回此类链接,即第一页的百度搜素链接
- }
- /*
- * 获取下一页地址
- */
- public static void nextHref(HtmlPage p) {
- // 输入:HtmlPage格式变量,第一页的网页内容;
- // 输出:format的模板
- WebClient webClient = new WebClient(BrowserVersion.CHROME);
- webClient.getOptions().setJavaScriptEnabled(false);
- webClient.getOptions().setCssEnabled(false);
- p = firstBaiduPage;
- String morelinks = p.getElementById("page").asXml();// 获取到百度第一页搜索的底端的页码的html代码
- org.jsoup.nodes.Document doc = Jsoup.parse(morelinks);// 转换为Jsoup识别的doc格式
- Elements links = doc.select("a[href]");// 提取这个html中的包含<a href=""....>的部分
- boolean getFormat = true;// 设置只取一次每页链接的模板格式
- for (Element newlink : links) {
- String linkHref = newlink.attr("href");// 将提取出来的<a>标签中的链接取出
- if (getFormat) {
- format = "http://www.baidu.com" + linkHref;// 补全模板格式
- getFormat = false;
- }
- }
- }
- public String getPageSource(String pageUrl, String encoding) {
- // 输入:url链接&编码格式
- // 输出:该网页内容
- StringBuffer sb = new StringBuffer();
- try {
- URL url = new URL(pageUrl);// 构建一URL对象
- BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), encoding));// 使用openStream得到一输入流并由此构造一个BufferedReader对象
- String line;
- while ((line = in.readLine()) != null) {
- sb.append(line);
- sb.append("\n");
- }
- in.close();
- } catch (Exception ex) {
- System.err.println(ex);
- }
- return sb.toString();
- }
- }
- package bdsearch;
- import java.io.BufferedReader;
- import java.io.ByteArrayInputStream;
- import java.io.IOException;
- import java.io.InputStream;
- import java.io.InputStreamReader;
- import java.net.ConnectException;
- import java.net.MalformedURLException;
- import java.util.ArrayList;
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- import com.gargoylesoftware.htmlunit.BrowserVersion;
- import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
- import com.gargoylesoftware.htmlunit.WebClient;
- import com.gargoylesoftware.htmlunit.html.HtmlPage;
- public class transURLtoINFO {
- /*
- * 匹配消除html元素
- */
- // 定义script的正则表达式
- private static final String regEx_script = "<script[^>]*?>[\\s\\S]*?<\\/script>";
- // 定义style的正则表达式
- private static final String regEx_style = "<style[^>]*?>[\\s\\S]*?<\\/style>";
- // 定义HTML标签的正则表达式
- private static final String regEx_html = "<[^>]+>";
- // 定义空格回车换行符
- private static final String regEx_space = "\\s*|\t|\r|\n";
- public static void main(String[] args) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
- String temp = null;
- trans("http://www.baidu.com/", temp);
- System.out.println("over");
- }
- public static String trans(String url, String info) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
- ArrayList<String> hrefList = new ArrayList<String>();
- WebClient webClient = new WebClient(BrowserVersion.CHROME);
- webClient.getOptions().setJavaScriptEnabled(false);
- webClient.getOptions().setCssEnabled(false);
- try {
- HtmlPage page = null;
- try {
- page = (HtmlPage) webClient.getPage(url);
- } catch (ConnectException e) {
- }
- InputStream temp = new ByteArrayInputStream(page.asText().getBytes());
- InputStreamReader isr = new InputStreamReader(temp);
- BufferedReader br = new BufferedReader(isr);
- String str = null, rs = null;
- while ((str = br.readLine()) != null) {
- rs = str;
- if (rs != null)
- hrefList.add(rs);
- }
- System.out.println("从该网址" + url + "查找的可能相关文本如下:");
- for (int i = 0; i < hrefList.size(); i++) {
- String string = hrefList.get(i);
- string = getTextFromHtml(string);
- if (string.length() >= 50) {
- info += "\n" + string;
- System.out.println(string);
- }
- }
- } catch (IOException e) {
- }
- return info;
- }
- /*
- * 从一行开始清除标签
- *
- * @return
- */
- public static String delHTMLTag(String htmlStr) {
- Pattern p_space = Pattern.compile(regEx_space, Pattern.CASE_INSENSITIVE);
- Matcher m_space = p_space.matcher(htmlStr);
- htmlStr = m_space.replaceAll(""); // 过滤空格回车标签
- Pattern p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE);
- Matcher m_script = p_script.matcher(htmlStr);
- htmlStr = m_script.replaceAll(""); // 过滤script标签
- Pattern p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE);
- Matcher m_style = p_style.matcher(htmlStr);
- htmlStr = m_style.replaceAll(""); // 过滤style标签
- Pattern p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE);
- Matcher m_html = p_html.matcher(htmlStr);
- htmlStr = m_html.replaceAll(""); // 过滤html标签
- return htmlStr.trim(); // 返回文本字符串
- }
- public static String getTextFromHtml(String htmlStr) {
- htmlStr = delHTMLTag(htmlStr);
- htmlStr = htmlStr.replaceAll(" ", "");
- return htmlStr;
- }
- }
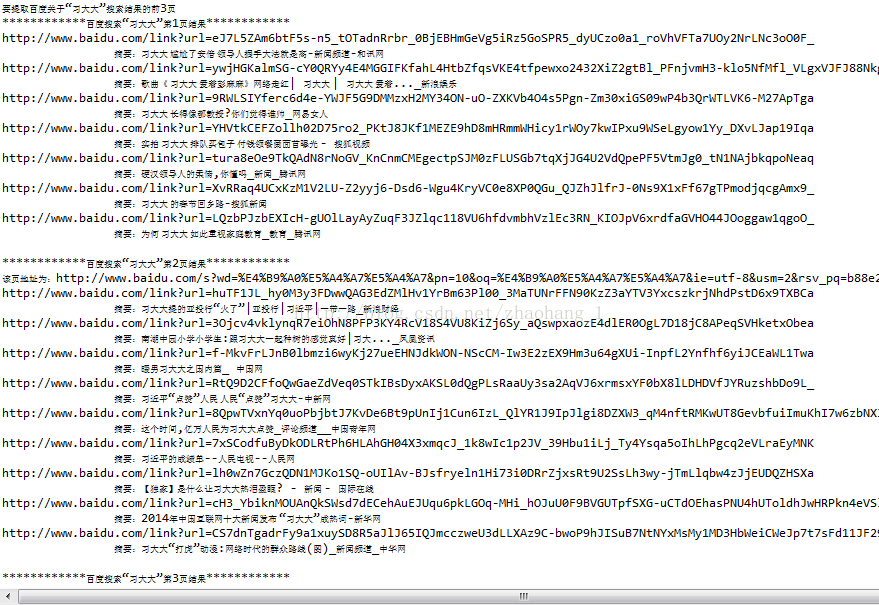
运行结果:


采集baidu搜索信息的java源代码实现(大部分转发,少量自己修改)(使用了htmlunit和Jsoup)(转发:https://blog.csdn.net/zhaohang_1/article/details/44731039)的更多相关文章
- Java类和对象 详解(一)---写的很好通俗易懂---https://blog.csdn.net/wei_zhi/article/details/52745268
https://blog.csdn.net/wei_zhi/article/details/52745268
- 转-java编译时error: illegal character '\ufeff' 的解决办法-https://blog.csdn.net/t518vs20s/article/details/80833061
原文链接:https://blog.csdn.net/shixing_11/article/details/6976900 最近开发人员通过SVN提交了xxx.java文件,因发布时该包有问题需要回退 ...
- java之比较两个日期大小----https://blog.csdn.net/dongfangbaiyun/article/details/51225469
https://blog.csdn.net/dongfangbaiyun/article/details/51225469 java之比较两个日期大小 最近又用到两个日期大小的比较,因此记录在此,方便 ...
- java 生成20位唯一ID,生成不会重复的20位数字----https://blog.csdn.net/weixin_36751895/article/details/70331781
java 生成20位唯一ID,生成不会重复的20位数字----https://blog.csdn.net/weixin_36751895/article/details/70331781
- java定时器的使用(Timer)(转发:https://blog.csdn.net/ecjtuxuan/article/details/2093757)
1.在应用开发中,经常需要一些周期性的操作,比如每5分钟执行某一操作等. 对于这样的操作最方便.高效的实现方式就是使用java.util.Timer工具类. private java.util.Tim ...
- jeecms 强大的采集功能优化 转载 https://blog.csdn.net/jeff06143132/article/details/7099003
========================================================= 没办法附件上传不了,AcquisitionSvcImpl.java类: //---- ...
- 极大极小搜索思想+(α/β)减枝 【转自-----https://blog.csdn.net/hzk_cpp/article/details/79275772】
极大极小搜索,即minimax搜索算法,专门用来做博弈论的问题的暴力. 多被称为对抗搜索算法. 这个搜索算法的基本思想就是分两层,一层是先手,记为a,还有一层是后手,记为b. 这个搜索是认为这a与b的 ...
- 转:Java面试题集(51-70) http://blog.csdn.net/jackfrued/article/details/17403101
Java面试题集(51-70) Java程序员面试题集(51-70) http://blog.csdn.net/jackfrued/article/details/17403101 摘要:这一部分主要 ...
- maven 依赖文件 pom.xml 编译 mvn compile 运行 不用mvn exec:java -Dexec.mainClass="hello.HelloWorld" 打成jar包 mvn package mvn install http://blog.csdn.net/yaya1943/article/details/48464371
使用maven编译Java项目 http://blog.csdn.net/yaya1943/article/details/48464371 使用"mvn clean"命令清除编 ...
随机推荐
- 浅谈HTTPS协议和SSL、TLS之间的区别与关系
HTTP可能是我们见到过最多的一个字符串了,应该没有之一,而对于HTTPS到来和趋势,我们又开始看到SSL/TLS,所以对于一般不只做技术的人来说这或许还是一个疑问,那么子凡就趁最近在折腾这方面来给大 ...
- Unity3D中简单的C#异步Socket实现
Unity3D中简单的C#异步Socket实现 简单的异步Socket实现..net框架自身提供了很完善的Socket底层.笔者在做Unity3D小东西的时候需要使用到Socket网络通信.于是决定自 ...
- Taxi Cab Scheme UVALive - 3126 最小路径覆盖解法(必须是DAG,有向无环图) = 结点数-最大匹配
/** 题目:Taxi Cab Scheme UVALive - 3126 最小路径覆盖解法(必须是DAG,有向无环图) = 结点数-最大匹配 链接:https://vjudge.net/proble ...
- Hadoop项目实战
这个项目是流量经营项目,通过Hadoop的离线数据项目. 运营商通过HTTP日志,分析用户的上网行为数据,进行行为轨迹的增强. HTTP数据格式为: 流程: 系统架构: 技术选型: 这里只针对其中的一 ...
- 爬虫 (3)- lxml库和贴吧图片下载案例
lxml库 lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据. lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解 ...
- Java 的数组
几乎所有程序设计语言都支持数组.在C和 C++里使用数组是非常危险的,因为那些数组只是内存块.若程 序访问自己内存块以外的数组,或者在初始化之前使用内存(属于常规编程错误),会产生不可预测的后果 (注 ...
- 【BZOJ】2017: [Usaco2009 Nov]硬币游戏(dp+神题+博弈论)
http://www.lydsy.com/JudgeOnline/problem.php?id=2017 这题太神了,我想了一个中午啊 原来是看错题一直没理解题解说的,一直以为题解是错的QAQ “开始 ...
- TCP/IP协议族-----15、传输控制协议(TCP)
- 视觉slam闭环检测之-DBoW2 -视觉词袋构建
需要准备的知识点:http://www.cnblogs.com/zjiaxing/p/5616653.html http://www.cnblogs.com/zjiaxing/p/56166 ...
- 努比亚Z18mini多点对焦
25点对焦 分为了中心对焦.中间对焦.边缘对焦三个区域 [参考文献] 手机上感受单反的“多点对焦”努比亚Z18mini给你想象 https://baijiahao.baidu.com/s?id=160 ...