【week3】词频统计 单元测试
使用Eclipse 集成的Junit进行单元测试。单元测试的核心包括断言、注解。
测试代码如下:
@BeforeClass
// 针对所有测试,只执行一次,且必须为static void
public static void setUpBeforeClass() throws Exception {
System.out.println("in BeforeClass================");
} @AfterClass
// 针对所有测试,只执行一次,且必须为static void
public static void tearDownAfterClass() throws Exception {
System.out.println("in AfterClass=================");
} @Before
// 初始化资源
public void before() {
System.out.println("in Before");
} @After
// 释放资源
public void after() {
System.out.println("in After");
} @Test
public void testMain() {
System.out.println("请输入要统计的文件路径");
Scanner sc = new Scanner(System.in);
String road = sc.nextLine();
FileInputStream fis = new FileInputStream(road);// 要读的文件路径
File f = new File(road);
File s[] = f.listFiles();
for (int i = 0; i < s.length; i++) {
String fileName = s[i].getName();
if (fileName.endsWith(".txt")) {
sortAndOutput(road);
}
}
System.out.println("测试main");
fail("Not yet implemented");
}
运行结果:

一个测试类单元测试的执行顺序为:
@BeforeClass –> @Before –> @Test –> @After –> @AfterClass
每一个测试方法的调用顺序为:
@Before –> @Test –> @After
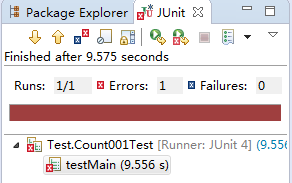
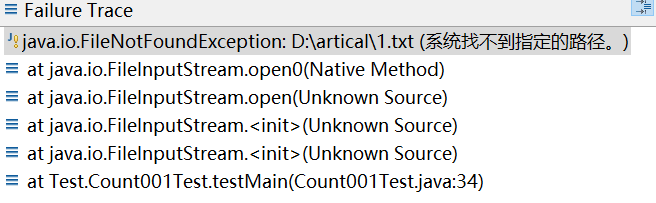
出现程序运行正确但是测试结果出现错误的情况。
创建一个hashmap存储预期答案
static Map<String, Integer> map = new HashMap<String, Integer>();
@Parameters
//指定测试类的测试数据集合
map.put("my", 1);
map.put("english", 1);
map.put("is", 1);
map.put("very", 2);
map.put("poor", 2);
return Arrays.asList(new Object[][] {
{ "D:\1.txt", map },
});
}
代码覆盖率就是所写的单元测试所测试到的代码比例。
PSP:

单元测试感受:确定期待的输出结果,与运行结果对比,使自己直观的感受到正确与错误是很好的方法。
由于自己的代码没有分功能写成不同的函数,单元测试效果不好,有待进一步学习。
git:git.coding.net/yumiaomiao/WordCountJunit.git
ssh: git@git.coding.net:yumiaomiao/WordCountJunit.git
【week3】词频统计 单元测试的更多相关文章
- Java实现的词频统计——单元测试
前言:本次测试过程中发现了几个未知字符,这里将其转化为十六进制码对其加以区分. 1)保存统计结果的Result文件中显示如图: 2)将其复制到eclipse环境下的切分方法StringTokenize ...
- java词频统计——改进后的单元测试
测试项目 博客文章地址:[http://www.cnblogs.com/jx8zjs/p/5862269.html] 工程地址:https://coding.net/u/jx8zjs/p/wordCo ...
- USTC《现代软件工程》春季学期——第一次个人作业:词频统计
截止日期 2018年3月29日23:59 要求 1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数. ...
- 软工结对项目之词频统计update
队友 胡展瑞 031602215 作业页面 GitHub 具体分工 111500206 赵畅:负责WordCount的升级,添加新的命令行参数支持(自定义输入输出文件,权重词频统计,词组统计等所有新功 ...
- 软工之词频统计器及基于sketch在大数据下的词频统计设计
目录 摘要 算法关键 红黑树 稳定排序 代码框架 .h文件: .cpp文件 频率统计器的实现 接口设计与实现 接口设计 核心功能词频统计器流程 效果 单元测试 性能分析 性能分析图 问题发现 解决方案 ...
- 论文爬取 & 词频统计2.0
一.Github地址 课程项目要求 队友博客 二.具体分工 031602225 林煌伟 :负责C++部分主要功能函数的编写,算法的设计以及改进优化 031602230 卢恺翔 : 爬虫 ...
- 词频统计 ——Java
github地址 :https://github.com/NSDie/personal-project 一.计划表 PSP2.1 Personal Software Process Stages 预估 ...
- 词频统计小程序-WordCount.exe
一. 背景 最近顶哥为了完成学历提升学业中的小作业,做了一个词频统计的.exe小程序.因为当时做的时候网上的比较少,因此顶哥决定把自己拙略的作品发出来给需要的人提供一种思路,希望各位看官不要dis ...
- 现代软件工程HW1:词频统计
作业详细要求:http://www.cnblogs.com/denghp83/p/8627840.html 基本功能 1. 统计文件的字符数(只需要统计Ascii码,汉字不用考虑,换行符不用考虑,'\ ...
随机推荐
- 使用NPOI将数据导出Excel
NPOI.HSSF.UserModel.HSSFWorkbook book = new NPOI.HSSF.UserModel.HSSFWorkbook(); NPOI.SS.UserModel.IS ...
- day 24 内置模块re
1.正则表达式,匹配字符串 正则表达式是对字符串操作的一种逻辑公式.我们一般使用正则表达式对字符串镜子那个匹配和过滤,使用正则的优缺点: 优点: 灵活,功能性强,逻辑性强 缺点: 上手难.一旦上手,会 ...
- Struts2+EasyUI+Hibernate小实例
概述 这个实例主要是前台数据到后台数据的传递和后台数据到前台数据的传递,完成数据的新增,以及对新增数据的展示.下面是详细的过程: Hibernate(数据库部分) 这里只是数据库的连接和数据库实体与物 ...
- 第7章 YARN HA配置
目录 7.1 yarn-site.xm文件配置 7.2 测试YARN自动故障转移 ResourceManager (RM)负责跟踪集群中的资源,以及调度应用程序(例如,MapReduce作业).在Ha ...
- django的response-8
视图函数在处理请求后,必须返回一个 HttpResponse 对象,或者 HttpResponse对象的子对象. 1. HttpResponse 可以通过 django.http.HttpRespon ...
- Go语言入门(二)Go语言中的变量、常量、数据类型、流程控制以及函数
Go语言中的变量 通常用var关键声明变量,有常规方式和简化方式. 常规方式: var name1 type1 name1 = value1 //赋值 简化方式: var name2 = value1 ...
- Tomcat7 调优及 JVM 参数优化
Tomcat 的缺省配置是不能稳定长期运行的,也就是不适合生产环境,它会死机,让你不断重新启动,甚至在午夜时分唤醒你.对于操作系统优化来说,是尽可能的增大可使用的内存容量.提高CPU 的频率,保证 ...
- POJ2505 A multiplication game(博弈)
题意 开始时$p = 1$,每次可以乘$2 - 9$,第一个使得$p \geqslant n$的人赢 问先手是否必胜 $1 <n <4294967295$ Sol 认真的推理一波. 若当前 ...
- netty之粘包分包的处理
1.netty在进行字节数组传输的时候,会出现粘包和分包的情况.当个数据还好,如果数据量很大.并且不间断的发送给服务器,这个时候就会出现粘包和分包的情况. 2.简单来说:channelBuffer在接 ...
- quartz与Spring整合
1.创建maven工程,导入spring和quartz相关依赖 2.创建任务类 3.在spring配置文件中配置任务类 4.在spring配置文件中配置JobDetail 5.在spring配置文件中 ...