HDFS初识
- 参看原文 【Hadoop】HDFS的运行原理
- 参看原文 还不懂HDFS的工作原理?快来扫扫盲
简介
HDFS(Hadoop Distributed File System) Hadoop分布式文件系统。是根据google发表的论文实现的。论文为GFS( Google File System ) Google文件系统。(中文,英文)
HDFS有很多特点:
- 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复、自动切换。副本默认存3份。
- 可以运行在廉价的机器上。
- 适合大数据的处理。多大?多小?HDFS默认会将文件分割为block,64M为一个Block的大小。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很重。

如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间(文件目录结构,权限等);HDFS启动时接收DataNode上报的block存储信息(每块位置,分块情况等)。
SecondaryNameNode: 是一个小弟,分担大哥NameNode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
DataNode: Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份: b是a的热备份,如果a坏掉。那么b马上代替a的工作。
冷备份: b是a的冷备份,如果a坏掉/那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage: 存储metadata的磁盘文件。
edits: 元数据的操作日志(针对于文件系统做的修改操作记录)。
namenode内存中存储的是=fsimage + edits
SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
工作原理
写操作
NameNode负责管理存储在HDFS上所有文件的元数据,它会确认客户端的请求,并记录下文件的名字和存储这个文件的DataNode集合。它把该信息存储在内存中的文件分配表里。
例如,客户端发送一个请求给NameNode,说它要将“zhou.log”文件写入到HDFS。那么,其执行流程如图1所示。具体为:
- 客户端发消息给NameNode,说要将“zhou.log”文件写入。(如图1中的1)
- NameNode发消息给客户端,交客户端写道DataNode A、B和D,并直接联系DataNode B。(如图1中的2)
- 客户端发消息给DataNode B,叫它保存一份“zhou.log”,并且发送一份副本给DataNode A和DataNode B。(如图1中的3)
- DataNode B 发消息给DataNode A ,叫它保存一份“zhou.log”文件,并且发送一份给副本给DataNode D。(如图1中的4)
- DataNode A 发消息给DataNode D,叫它保存一份“zhou.log”文件。(如图1中的5)
- DataNode D发确认消息给DataNode A。(如图1中的5)
- DataNode A发确认消息给DataNode B。(如图1中的4)
- DataNode B发确认消息给客户端,表示写入完成。(如图1中的6)
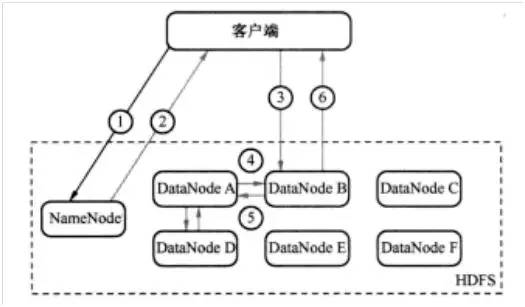
图1 HDFS写过程示意图
HDFS读过程
为了理解读的过程,可以认为一个文件是由存储在DataNode上的数据块组成的。客户端查看之前写入的内容的执行流程如图2所示,具体步骤为:
- 客户端询问NameNode它应该从哪里读取文件。(如图2中的1)
- NameNode发送数据块的信息给客户端。(数据块信息包含了保存着文件副本的DataNode的IP地址,以及DataNode在本地硬盘查找数据块所需要的数据块Id。)(如图2中的2)
- 客户端检查数据块信息,联系相关的DataNode,请求数据块。(如图2中的3)
- DataNode返回文件内容给客户端,然后关闭连接,完成读操作。(如图2中的4)
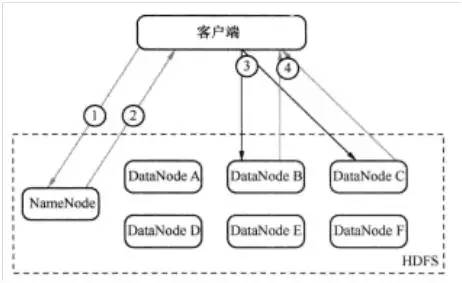
图2 HDFS读过程示意图
客户端并行从不同的DataNode中获取一个文件的数据块,然后联接这些数据块,拼成完整的文件。
通过副本快速恢复硬件故障
当一切运行正常时,DataNode会周期性发送心跳信息给NameNode(默认是每3秒钟一次)。如果NameNode在预定的时间内没有收到 心跳信息(默认是10分钟),它会认为DataNode出问题了,把它从集群中移除,并且启动一个进程去恢复数据。DataNode可能因为多种原因脱离 集群,如硬件故障、主板故障、电源老化和网络故障等。
对于HDFS来说,丢失一个DataNode意味着丢失了存储在它的硬盘上的数据块的副本。假如在任意时间总有超过一个副本存活,则故障就不会导致丢失数据。当一个硬盘故障时,HDFS会检测到存储在该硬盘的数据块的副本数量低于要求,然后主动创建需要的副本,以达到满副本数的状态。
跨多个DataNode切分文件
在HDFS里,文件被切分成数据块,通常每个数据块64MB~128MB,然后每个数据块被写到不同DataNode磁盘上。同一个文件中的不同数据块不一定保存在相同的DataNode上。这样做的好处是:当对这些文件执行运算时,能够通过并行方式读取和处理文件的不同部分。
当客户端准备写文件到HDFS时,会先向NameNode询问应该把文件写到哪里,NameNode会告诉客户端可以写入数据库的DataNode。
总结
- HDFS就是一个支持横向扩张的大硬盘,大的分布式文件管理系统。
- NameNode : 管家,管理HDFS文件。
- DataNode: 奴隶,存储和读取文件。
- SecondaryNameNode :NameNode的冷备份。
- 每个block默认3个副本,可调整。每个block 默认64M,可调整。
马士兵:HDFS就是“分冗展”的大印盘
- 分:分块
- 冗:冗余
- 展:支持动态扩展,只要向NameNode报告就行
HDFS初识的更多相关文章
- 【大数据系列】HDFS初识
一.HDFS介绍 HDFS为了做到可靠性(reliability)创建了多分数据块(data blocks)的复制(replicas),并将它们放置在服务集群的计算节点中(compute nodes) ...
- 大数据-hadoop生态之-HDFS
一.HDFS初识 hdfs的概念: HDFS,它是一个文件系统,用于存储文件,通过目录树定位文件,其次,他是分布式的,由很多服务器联合起来 实现功能,集群中的服务器各有各自的角色 HDFS设计适合一次 ...
- 初识hadoop之分布式文件系统(HDFS)
Hadoop常用发行版: Apache Hadoop CDH Cloudera Distributed Hadoop HDP Hortonworks Data Platfrom 分布式文件系统(H ...
- 初识HDFS原理及框架
目录 HDFS是什么 HDFS的优缺点 HDFS的框架 HDFS的读写流程 HDFS命令 HDFS参数 1. HDFS是什么 HDFS(Hadoop Distributed File System)是 ...
- 初识HDFS(10分钟了解HDFS、NameNode和DataNode)
概览 首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通 ...
- 大数据系列1:一文初识Hdfs
最近有位同事经常问一些Hadoop的东西,特别是Hdfs的一些细节,有些记得不清楚,所以趁机整理一波. 会按下面的大纲进行整理: 简单介绍Hdfs 简单介绍Hdfs读写流程 介绍Hdfs HA实现方式 ...
- 初识Hadoop
第一部分: 初识Hadoop 一. 谁说大象不能跳舞 业务数据越来越多,用关系型数据库来存储和处理数据越来越感觉吃力,一个查询或者一个导出,要执行很长 ...
- 初识Hadoop入门介绍
初识hadoop入门介绍 Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不适用我们的项目,但是我会继续研究下去,技多不压身. < ...
- hadoop初识
搞什么东西之前,第一步是要知道What(是什么),然后是Why(为什么),最后才是How(怎么做).但很多开发的朋友在做了多年项目以后,都习惯是先How,然后What,最后才是Why,这样只会让自己变 ...
随机推荐
- 实例——简单的Samba共享
服务端配置 # 临时停止iptables service iptables stop # 临时禁用SELinux setenforce 0 # 禁止iptables开机自动启动 chkconfig i ...
- Codeforces Round #402 (Div. 2) A B C sort D二分 (水)
A. Pupils Redistribution time limit per test 1 second memory limit per test 256 megabytes input stan ...
- Desert King 最小比率生成树 (好题)
Description David the Great has just become the king of a desert country. To win the respect of his ...
- ACM1881 01背包问题应用
01背包问题动态规划应用 acm1881毕业bg 将必须离开的时间限制看作背包容量,先将他们由小到大排序,然后在排完序的数组中对每个实例都从它的时间限制开始(背包容量)到它的延长时间进行遍历: #in ...
- Codeforces Round #201 (Div. 2)C,E
数论: C. Alice and Bob time limit per test 2 seconds memory limit per test 256 megabytes input standar ...
- Qt ------ 内存回收机制、new对象的回收
写在前面的总结: 建议:对于不能指定父对象的对象(对象通过moveToThread()移入其他线程.没有继承QObject的类产生的对象),在其他线程通过deleteLater()内存回收,其他通过指 ...
- SSH客户端,FinalShell服务器管理,远程桌面加速软件,支持Windows,Mac OS X,Linux,版本2.6.3.1
FinalShell是一体化的的服务器,网络管理软件,不仅是ssh客户端,还是功能强大的开发,运维工具,充分满足开发,运维需求. 用户QQ群 342045988 Windows版下载地址:http:/ ...
- git版本回退与撤销操作
场景1:当你改乱了工作区某个文件的内容,想直接丢弃工作区的修改时,用命令git checkout -- file. 场景2:当你不但改乱了工作区某个文件的内容,还添加到了暂存区时,想丢弃修改,分两步, ...
- [技巧篇]08.Struts2拦截器中获取Servlet API方法
讲课中遇到的解决Session拦截器的后腿问题,还有如何在拦截器中获取Servlet API,这里留一个备注,方便学生查找
- PowerDesigner16 活动图
活动是某件事情正在进行的状态.活动在状态机中表现为一个由一系列动作组成 的非原子的执行过程. 活动图是一种描述系统行为的图,它用于展现 参与行为的实体所进行的各种活动的顺序关系.活动图(Activit ...