爬虫框架YayCrawler
各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品——YayCrawler,其在GitHub上的网址是:https://github.com/liushuishang/YayCrawler,欢迎大家关注和反馈。
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们知道目前爬虫框架很多,有简单的,也有复杂的,有轻量型的,也有重量型的。您也许会问:你这个爬虫框架的优势在哪里呢?额,这个是一个很重要的问题!在这个开篇中,我先简单的介绍一下我这个爬虫框架的特点,后面的章幅会详细介绍并讲解它的实现,一图胜千言:
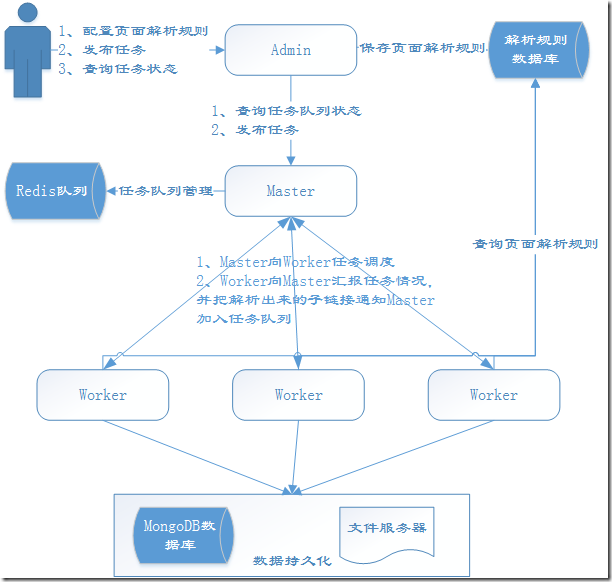
1、分布式:YayCrawler就是一个大哥(Master)多个小弟(Worker)的架构(这种结构才是宇宙的真理),当然大哥还有一个小秘(Admin)和外界交往。
2、通用性:我们很多时候需要爬取不同网站的数据,各个网站的结构和内容都有很大的差别,基本上大部分人都是遇到一个网站写一份代码,没法做到工具的复用。YayCrawler就是想改变这种情况,把不同的部分抽象出来,用规则来指导爬虫做事。也就是说用户可以在界面上配置如何抓取某个页面的数据的规则,等爬虫在爬取这个页面的时候就会用这个事先配置好的规则来解析数据,然后把数据持久化。
3、可扩展的任务队列:任务队列由Redis实现,根据任务的状态有四种不同的任务队列:初始、执行中、成功、失败。您也可以扩展不同的任务调度算法,默认是公平调度。
4、可定义持久化方式:爬取结果中,属性数据默认持久化到MongoDB,图片会被下载到文件服务器,当然您可以扩展更多的存储方式。
5、稳定和容错:任何一个失败的爬虫任务都会重试和记录,只有任务真正成功了才会被移到成功队列,失败会有失败的原因描述。
6、反监控组件:网站为了防止爬虫也是煞费苦心,想了一系列的监控手段来反爬虫。作为对立面,我们自然也要有反监控的手段来保障我们的爬虫任务,目前主要考虑的因素有:cookie失效(需要登陆)、刷验证码、封IP(自动换代理)。
7、可以对任务设置定时刷新,比如隔一天更新某个网站的数据。
……
上面说了一大堆优点的目的只有一个:希望您能有兴趣继续看下去,哈哈。
言归正传,本文作为开篇,只是一个总览,现在我们来整理一下后续文章的结构安排:
- 开源通用爬虫框架YayCrawler-框架的运行机制
- 开源通用爬虫框架YayCrawler-页面的抽取规则定义
- 开源通用爬虫框架YayCrawler-任务队列详解
- 开源通用爬虫框架YayCrawler-页面下载器详解
- 开源通用爬虫框架YayCrawler-规则解析器详解
- 开源通用爬虫框架YayCrawler-数据持久化详解
- 开源通用爬虫框架YayCrawler-反监控组件详解
- 开源通用爬虫框架YayCrawler-案例演示
- 开源通用爬虫框架YayCrawler-待完善的功能
爬虫框架YayCrawler的更多相关文章
- 开源通用爬虫框架YayCrawler-开篇
各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品--YayCrawler,其在GitHub上的网址是:https://github.com/liushuishang/YayCraw ...
- 爬虫框架--webmagic
官方有详细的使用文档:http://webmagic.io/docs/zh/ 简介:这只是个java爬虫框架,具体使用需要个人去定制,没有图片验证,不能获取js渲染的网页,但简单易用,可以通过xpat ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- [开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 为什么要造轮子 同学们可以去各大招聘网站查看一下爬虫工程师的要求,大多是招JA ...
- 使用Scrapy爬虫框架简单爬取图片并保存本地(妹子图)
初学Scrapy,实现爬取网络图片并保存本地功能 一.先看最终效果 保存在F:\pics文件夹下 二.安装scrapy 1.python的安装就不说了,我用的python2.7,执行命令pip ins ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- 再次分享 pyspider 爬虫框架 - V2EX
再次分享 pyspider 爬虫框架 - V2EX block
- Cola:一个分布式爬虫框架 - 系统架构 - Python4cn(news, jobs)
Cola:一个分布式爬虫框架 - 系统架构 - Python4cn(news, jobs) Cola:一个分布式爬虫框架 发布时间:2013-06-17 14:58:27, 关注:+2034, 赞美: ...
随机推荐
- Effective Java实作Comparator - 就是爱Java
如果集合或数组内的对象,有1个以上不同的排序逻辑时,那该如何处理呢?尤其是当已经实现了Comparable,又不能变动原本的逻辑时,Mix会采用Comparator来处理. 阅读全文>>
- POJ 1755 Triathlon
http://poj.org/problem?id=1755 题意:铁人三项,每个人有自己在每一段的速度,求有没有一种3条路线长度都不为0的设计使得某个人能严格获胜? 我们枚举每个人获胜,得到不等式组 ...
- HTTP发送请求模拟
using System; using System.Collections.Generic; using System.Text; using System.Data; using System.I ...
- 【转】Ubuntu命令行下安装、卸载、管理软件包的方法
原文网址:http://oss.org.cn/html/47/n-67447.html 一.Ubuntu中软件安装方法 1.APT方式 (1)普通安装:apt-get install softname ...
- 3D objects key rendering steps
Key steps of Rendering objects: 1 Create objects’ meshes, which we can use C++’s vector container to ...
- 百度Clouda的初步探索
最近一直比较关注百度Clouda,参加了数次百度Clouda团队举办的技术沙龙,也利用了一些时间读了开发文档,下面谈谈我对这个框架的初步理解: 1. 轻应用和Clouda的区别和联系: ...
- Spring中给Bean注入集合
Spring中如果一个Bean里含有集合元素,需要给Bean里的集合元素注入元素时,可以采用如下方法,一个是构造器注入,一个是setter注入 JavaBean源代码: import java.uti ...
- html5 750 REM JS换算方法
在安卓手机低版本浏览器,如果进页面快速执行的话会出现计算宽度不正确的情况,解决方法是放在onload方法里面执行,但这种解决方式在一些高版本浏览器中会出现页面闪动,所以使用判断浏览器版本的方式来解决, ...
- Linux中输入命令按tab提示后会自动转义解决方案(xjl456852原创)
linux在命令行输入命令时,如果有$字符,按tab键时会自动在前面加入转义字符,反而达不到自己需要的效果. 例如: 在Centos7下,我要进入一个环境变量,并编辑一个文件: 比如我要进入$JAVA ...
- python calendar标准库基础学习
# -*- coding: utf-8 -*-# 作者:新手__author__ = 'Administrator'#标准库:日期时间基础学习:calendar:处理日期#例1import calen ...