Introduction to Big Data with Apache Spark 课程总结
课程主要实用内容:
a. 下载,安装visualbox
管理员身份运行;课程要求最新版4.3.28,如果c中遇到虚拟机打不开的,可以用4.2.12,不影响
b. 下载,安装vagrant,重启
管理员身份运行
c. 下载虚拟机
c1.将vagrant加入path,D:\HashiCorp\Vagrant\bin
c2.创建虚拟机存放的目录,比如myvagrant
c3.下载文件mooc-setup-master.zip,解压后,拷贝Vagrantfile到myvagrant
c4.打开visual box图形界面,进入cmd,cd到myvagrant,敲命令 vagrant up
开始下载虚拟机,并打开,如果下载完成,但是打开虚拟机出错;
可以到visual box 图形界面点击打开,碰到一下错误,可尝试用4.2.12版visual box
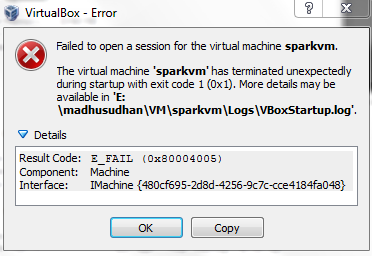
使用说明:i.打开关闭虚拟机:打开visual box 界面,cd进入myvagrant
vagrant up 打开虚拟机,vagrant halt 关闭虚拟机
ii.ipython notebook,进入http:\\localhost:8001
停止正在运行的notebook,点击running,停止
点某 .py文件,运行note book
iii.下载ssh软件,可登入虚拟机,地址为127.0.0.1,端口2222,用户名vagrant,密码vagrant
进入后,敲pyspark,可进入pyspark交互式界面
3.常用函数
Spark中Rdd的生命周期
创建RDD(parallelize、textFile等)
对RDD进行变换
(会创建新的RDD,不会改变原RDD,有
1.对每个元素进行操作-map,flatMap,mapValues
2.筛选 filter
3.排序 sortBy
3.合并结果 reduceByKey,groupByKey
4.合并两个rdd union,join,leftJoin,rightJoin)
以上步骤中rdd都只相当于一个操作手册,并没有真实地在内存中产生数据,称为lazy evaluation
缓存rdd到内存中 cache() ,判断是否cache,访问 .is_cached属性
触发evaluation(包括top,take,takeOrdered,takeSample,sum,count,distinct,reduce,collect,collectAsMap)
4.变量共享
spark有两种变量共享方式
a.广播 broadcast,broadcast后的变量每个partition都会存储一份,但是只能读取,不能修改
>>> b=sc.broadcast([1,2,3,4,5])
>>> sc.parallelize([0,0]).flatMap(lambdax:b.value)
b.累加器 accumulator,只能写,不能在worker被读取
如果累加器只是一个标量,使用很简单
>>> rdd = sc.parallelize([1,2,3])
>>> def f(x):
... global a
... a += x
>>> rdd.foreach(f)
>>> a.value
13
如果累加器是一个向量,需要定义AccumulatorParam,且zero方法和addInPlace都要实现
>>> from pyspark.accumulators import AccumulatorParam
>>> class VectorAccumulatorParam(AccumulatorParam):
... def zero(self, value):
... return [0.0] * len(value)
... def addInPlace(self, val1, val2):
... for i in xrange(len(val1)):
... val1[i] += val2[i]
... return val1
>>> va = sc.accumulator([1.0, 2.0, 3.0], VectorAccumulatorParam())
>>> va.value
[1.0, 2.0, 3.0]>>> defg(x):
... global va
... va += [x] * 3
>>> rdd.foreach(g)
>>> va.value
[7.0, 8.0, 9.0]
Introduction to Big Data with Apache Spark 课程总结的更多相关文章
- CS100.1x Introduction to Big Data with Apache Spark
CS100.1x简介 这门课主要讲数据科学,也就是data science以及怎么用Apache Spark去分析大数据. Course Software Setup 这门课主要介绍如何编写和调试Py ...
- Introduction to Big Data with PySpark
起因 大数据时代 大数据最近太热了,其主要有数据量大(Volume),数据类别复杂(Variety),数据处理速度快(Velocity)和数据真实性高(Veracity)4个特点,合起来被称为4V. ...
- Why Apache Spark is a Crossover Hit for Data Scientists [FWD]
Spark is a compelling multi-purpose platform for use cases that span investigative, as well as opera ...
- Introducing DataFrames in Apache Spark for Large Scale Data Science(中英双语)
文章标题 Introducing DataFrames in Apache Spark for Large Scale Data Science 一个用于大规模数据科学的API——DataFrame ...
- Using Apache Spark and MySQL for Data Analysis
What is Spark Apache Spark is a cluster computing framework, similar to Apache Hadoop. Wikipedia has ...
- Apache Spark : Introduction
看了一点<数据算法:Hadoop/Spark大数据处理技巧>,觉得有必要了解一下 Spark . 以上. Spark was introduced by Apache Software F ...
- 【译】Using .NET for Apache Spark to Analyze Log Data
.NET for Spark可用于处理成批数据.实时流.机器学习和ad-hoc查询.在这篇博客文章中,我们将探讨如何使用.NET for Spark执行一个非常流行的大数据任务,即日志分析. 1 什么 ...
- Apache Spark源码走读之5 -- DStream处理的容错性分析
欢迎转载,转载请注明出处,徽沪一郎,谢谢. 在流数据的处理过程中,为了保证处理结果的可信度(不能多算,也不能漏算),需要做到对所有的输入数据有且仅有一次处理.在Spark Streaming的处理机制 ...
- Spark(1) - Getting Started with Apache Spark
Introduction Apache Spark is a general-purpose cluster computing system to process big data workload ...
随机推荐
- 51 EEPROM操作模板
各个型号容量及扇区请查datasheet #include <reg52.h> #include "intrins.h" typedef unsigned char b ...
- [poj 1039]Pipes[线段相交求交点]
题意: 无反射不透明管子, 问从入口射入的所有光线最远能到达的横坐标. 贯穿也可. 思路: 枚举每一组经过 up [ i ] 和 down [ j ] 的直线, 计算最远点. 因为无法按照光线生成的方 ...
- Unix/Linux环境C编程入门教程(31) 数学函数带你战胜企业面试
1.函数介绍: abs()acos()asin()atan()atan2()ceil()cos()cosh()exp()frexp()ldexp()log()log10()pow()sin()sinh ...
- 2014元旦第1周三新的尝试&爬山丢失望远镜
2014元旦在早起中开始,起来后看了<逃出你的肖申克>系列文章,没有精度只是选择了里面的关键语句和方法论,没有多少意外的收获.然后看了些java系列文章,关于jvm参数配置.运行监控及性能 ...
- c++容器使用总结(转载)
目录 ==================================================== 第一章 容器 第二章 Vector和string 第三章 关联容器 第四章 迭代器 第五 ...
- postgresql基本语句
preface,熟悉pgsql sql Language article disorder; 1,pgsql数据库控制台Cli(command line interface) help mannual ...
- EasyMonkeyDevice vs MonkeyDevice&HierarchyViewer API Mapping Matrix
1. 前言 本来这次文章的title是写成和前几篇类似的<EasyMonkeyDevice API实践全记录>,内容也打算把每一个API的实践和建议给记录下来,但后来想了下认为这样子并非最 ...
- 2014年百度之星资格赛第二题Disk Schedule
Problem Description 有非常多从磁盘读取数据的需求,包含顺序读取.随机读取.为了提高效率,须要人为安排磁盘读取. 然而,在现实中,这样的做法非常复杂. 我们考虑一个相对简单的场景. ...
- Hibernate annotation多对多配置
角色(用户组),用户多对多. 角色实体配置: private Set<TAuthUser> users; @ManyToMany @JoinTable(name="t_auth_ ...
- 【贪心】【uva11520】 Fill the Square
填充正方形(Fill the Square, UVa 11520) 在一个n×n网格中填了一些大写字母,你的任务是把剩下的格子中也填满大写字母,使得任意两个相邻格子(即有公共边的格子)中的字母不同.如 ...