九章算法系列(#2 Binary Search)-课堂笔记
前言
先说一些题外的东西吧。受到春跃大神的影响和启发,推荐了这个算法公开课给我,晚上睡觉前点开一看发现课还有两天要开始,本着要好好系统地学习一下算法,于是就爬起来拉上两个小伙伴组团报名了。今天听了第一节课,说真的很实用,特别是对于我这种算法不扎实,并且又想找工作,提高自己的情况。 那就不多说废话了,以后每周都写个总结吧,就趁着这一个月好好把算法提高一下。具体就从:课堂笔记、leetcode和lintcode相关习题、hdu和poj相关习题三个方面来写吧。希望自己能够坚持下来,给大家分享一些好的东西。
outline:
- 第一境界:会写程序
- Find First Position of Target
- Find Last Position of Target
- 第二境界:找到第一个/最后一个满足某个条件的位置/值
- Search a 2D Matrix
- Find Minimum in Rotated Sorted Array
- 第三境界:保留有解的那一半
- Find Peak Element
课堂笔记
二分查找这类题以前接触的也算是比较多的了,所以还算相对熟悉,但今天听老师讲过以后,还是觉得有了很多新的认识,最有印象的就是令狐老师讲的三个境界:
1. 第一境界:会写程序
这个境界我自认为在刷了那么多leetcode之后算是没有问题的了,套了不少模版,虽然还有一些边界问题考虑不周全,但是经过调试,应该没有什么问题,经过几次面试,也面到过Binary Seach。想必大家也有很好的基础。 正如老师说的,这个境界还是存在一些问题,比如解决二分程序的三大痛点、权衡递归与非递归。 对于第一个问题,其实就是start和end的位置选取,比如容易进入死循环,或者容易分不清楚到底应该是start = mid还是start = mid+ 1等。以下给出一个代码模版,这个也是我之前写二分问题经常会写的样子:
int start = , end = nums.size() - ;
while (start < end){
int mid = (start + end)/;
if (...) {...}
else if (...) {...}
else {...}
}
想必大家都会把循环条件写成start < end或者start <= end这样的,这样在一些情况下也确实没有问题(这里直接上一个题):
Find First Position of Target
http://www.lintcode.com/zh-cn/problem/first-position-of-target/
给定一个排序的整数数组(升序)和一个要查找的整数
target,用O(logn)的时间查找到target第一次出现的下标(从0开始),如果target不存在于数组中,返回-1。样例
在数组
[1, 2, 3, 3, 4, 5, 10]中二分查找3,返回2。
这个题应该是Binary Search最基础的题,直接套用模版就可以,以下是这个题的代码(Bug Free):
int binarySearch(vector<int> &array, int target) {
if (!array.size()) return -;
int start = , end = array.size() - ;
while (start < end) {
int mid = (start + end) >> ;
if (array[mid] < target) {
start = mid + ;
} else if (array[mid] > target) {
end = mid -;
} else {
end = mid;
}
}
if (array[start] == target) return start;
return -;
}
因为比较简单,就不再多说了,这里需要注意的几个点是,int mid = (start + end) >>1;其实就是int mid = (start + end)/2;因为在面试中如果会位运算的话,还是能够给面试官留下很好的印象。有的人说直接加起来除以2会溢出,其实start和end不会大到超过int的最大值的,因为一个vector也不会去开辟那么大的空间,但是写成`int mid = (end - start)/2 + start;`也能显得你比较不错。综上,两种方法都可以。 在这个题中因为是找第一个与target相等的值,所以用这种方法不会出问题,但是在考虑下面的题,就会出现问题:
Find Last Position of Target
http://www.lintcode.com/zh-cn/problem/last-position-of-target/
给一个升序数组,找到target最后一次出现的位置,如果没出现过返回
-1样例
给出 [1, 2, 2, 4, 5, 5].
target =
2, 返回2.target =
5, 返回5.target =
6, 返回-1.
错误代码如下:
while (start < end) {
int mid = ( start + end ) >>;
if (A[mid] < target) {
start = mid + ;
} else if ( A[mid] > target) {
end = mid -;
} else {
start = mid;
}
}
这里如果这样写的话,代码就会进入死循环,因为在求mid的时候是向左边取整的。考虑这样的一个情况[...,5,5],假设target为5,那么start就会一直向右靠近,最后到n-2的位置,而end此时为n-1,再次进入循环mid等于n-2,所以就进入了死循环。 根据课上老师所说的,建议大家写成start + 1 < end,最后再判断start和end(按照所需先后判断)即可,这种写法适用于所有的情况,不容易出现问题。 ps. 这里把条件写成如下也可行:
while (start + < end) {
int mid = (start + end)>>;
if (A[mid] > target) {
end = mid;
} else {
start = mid;
}
}
因为start和end不管是否包括mid值都不影响最后的结果。 这个境界需要理解一个重点: 二分法实际上就是把区间变小的问题,把一个长度为n的区间变为n/2,然后再变小,即:
T(n) = T(n/) + O() = O(logn)
通过O(1)的时间,把规模为n的问题变为n/2 当面试的时候,有O(n)的解,如果面试官需要你进一步优化,那么很大可能就是需要用二分O(logn)的方法来做。 实际上的步骤:
**区间缩小-> 剩下两个下标->判断两个下标**
**注:不要把缩小区间和得到答案放在一个循环里面,容易出问题,增加难度**
2. 第二境界:找到第一个/最后一个满足某个条件的位置/值
写出一个高效的算法来搜索 m × n矩阵中的值。
这个矩阵具有以下特性:
- 每行中的整数从左到右是排序的。
- 每行的第一个数大于上一行的最后一个整数。
样例
考虑下列矩阵:
[
[1, 3, 5, 7],
[10, 11, 16, 20],
[23, 30, 34, 50]
]
给出
target = 3,返回true
bool searchMatrix(vector<vector<int> > &matrix, int target) {
if (!matrix.size()||!matrix[].size()) return false;
int start = , end = matrix.size() - ;
while (start + < end) {
int mid = (end - start)/ + start;
if (matrix[mid][] < target) start = mid;
else end = mid;
}
int new_start = ,new_end = matrix[].size()-;
int index = matrix[end][] <= target ?end:start;
while (new_start + < new_end) {
int mid = (new_end - new_start)/ + new_start;
if (matrix[index][mid] > target) new_end = mid;
else if (matrix[index][mid] < target)
new_start = mid;
else return true;
}
if (matrix[index][new_end] == target) return true;
if (matrix[index][new_start] == target) return true;
return false;
}
bool searchMatrix(vector<vector<int> > &matrix, int target) {
if (!matrix.size()||!matrix[].size()) return false;
int m = matrix.size();
int n = matrix[].size();
int start = , end = n * m - ;
while (start + < end) {
int mid = (end - start)/ + start;
int x = mid / n;
int y = mid % n;
if (matrix[x][y] > target) {
end = mid;
} else {
start = mid;
}
}
int x = start / n;
int y = start % n;
if (matrix[x][y] == target) {
return true;
}
x = end / n;
y = end % n;
if (matrix[x][y] == target) {
return true;
}
return false;
}
假设一个旋转排序的数组其起始位置是未知的(比如0 1 2 4 5 6 7 可能变成是4 5 6 7 0 1 2)。
你需要找到其中最小的元素。
你可以假设数组中不存在重复的元素。
样例
给出[4,5,6,7,0,1,2] 返回 0
int findMin(vector<int> &num) {
if (!num.size()) return ;
int start = , end = num.size() - ;
int target = num[end];
while (start + < end) {
int mid = (end - start)/ + start;
if (num[mid] <= target) {
end = mid;
}
else {
start = mid;
}
}
if (num[start] <= target) {
return num[start];
}
else {
return num[end];
}
}
给出一个整数数组(size为n),其具有以下特点:
- 相邻位置的数字是不同的
- A[0] < A[1] 并且 A[n - 2] > A[n - 1]
假定P是峰值的位置则满足
A[P] > A[P-1]且A[P] > A[P+1],返回数组中任意一个峰值的位置。样例
给出数组
[1, 2, 1, 3, 4, 5, 7, 6]返回1, 即数值 2 所在位置, 或者6, 即数值 7 所在位置.
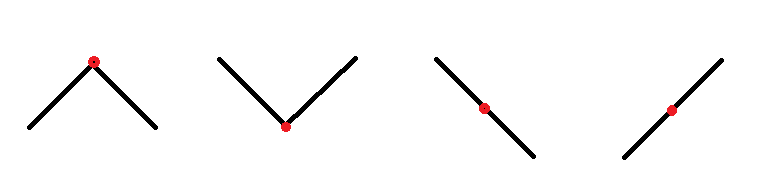
第一种情况:当前点就是峰值,直接返回当前值。
第二种情况:当前点是谷点,不论往那边走都可以找到峰值。
第三种情况:当前点处于下降的中间,往左边走可以到达峰值。
第四种情况:当前点处于上升的中间,往右边走可以达到峰值。
分析了四种情况,那么就容易把有答案的一半保留下来了,接下来就判断是否能够找到峰值即可。代码如下(Bug Free):
int findPeak(vector<int> A) {
if (!A.size()) return ;
int start = ;
int end = A.size() -;
while (start + < end) {
int mid = (end - start)/ + start;
if (A[mid] > A[mid - ] && A[mid] > A[mid + ]) {
return mid;
} else if (A[mid] <= A[mid+] && A[mid] >= A[mid -]) {
start = mid;
} else if (A[mid] >= A[mid+] && A[mid] <= A[mid -]) {
end = mid;
} else {
start = mid;
}
}
if (start >= && A[start] > A[start - ] && A[start] > A[start + ]) return start;
if (end <= A.size()- && A[end] > A[end-] && A[end] > A[end+]) return end;
}
这道题的难点其实就是把各种情况考虑一下,然后把有答案的部分保留下来,基本上就没有问题了。
总结
本文只是挑选了一些比较好的课上的题进行了讲解,还有部分题没有写出来,也会在后续的博客中。
对于我个人而言,二分法算是比较熟悉的一个方法,之前在做微软校招第一题的时候用的就是二分的方法。在面试中也是比较常用到的一种方法,因为总有那么一种说法嘛:比0(n)还要快的算法复杂度,那必须就是0(logn)了(这里说的是在一般的面试情况下)那么O(logn)就必然要考虑二分的方法来做了。一般都会与一些排序的序列、在一段有规则的序列等情况中找到符合某个条件的位置/值。这个模块还是需要多练习,然后就能够很好上手了,如果想要能够在算法面试中有更好的突破,还是需要去解决一些难一点的题,诸如poj或者hdu这样的应用场景的题。
这也是本人第一次认真写一个技术长文,虽然也没有什么特别深奥的东西,读到这里说明你也是很给我面子的了,之后还会继续更新一些自己的想法和一些好的题目,希望大家多多支持!
九章算法系列(#2 Binary Search)-课堂笔记的更多相关文章
- 九章算法系列(#3 Binary Tree & Divide Conquer)-课堂笔记
前言 第一天的算法都还没有缓过来,直接就进入了第二天的算法学习.前一天一直在整理Binary Search的笔记,也没有提前预习一下,好在Binary Tree算是自己最熟的地方了吧(LeetCode ...
- 九章算法系列(#5 Linked List)-课堂笔记
前言 又是很长时间才回来发一篇博客,前一个月确实因为杂七杂八的事情影响了很多,现在还是到了大火燃眉毛的时候了,也应该开始继续整理一下算法的思路了.Linked List大家应该是特别熟悉不过的了,因为 ...
- 九章算法系列(#4 Dynamic Programming)-课堂笔记
前言 时隔这么久才发了这篇早在三周前就应该发出来的课堂笔记,由于懒癌犯了,加上各种原因,实在是应该反思.好多课堂上老师说的重要的东西可能细节上有一些急记不住了,但是幸好做了一些笔记,还能够让自己回想起 ...
- (lintcode全部题目解答之)九章算法之算法班题目全解(附容易犯的错误)
--------------------------------------------------------------- 本文使用方法:所有题目,只需要把标题输入lintcode就能找到.主要是 ...
- 7九章算法强化班全解--------Hadoop跃爷Spark
------------------------------------------------------------第七周:Follow up question 1,寻找峰值 寻找峰值 描述 笔记 ...
- [Data Structure] 二叉搜索树(Binary Search Tree) - 笔记
1. 二叉搜索树,可以用作字典,或者优先队列. 2. 根节点 root 是树结构里面唯一一个其父节点为空的节点. 3. 二叉树搜索树的属性: 假设 x 是二叉搜索树的一个节点.如果 y 是 x 左子树 ...
- 算法导论学习-binary search tree
1. 概念: Binary-search tree(BST)是一颗二叉树,每个树上的节点都有<=1个父亲节点,ROOT节点没有父亲节点.同时每个树上的节点都有[0,2]个孩子节点(left ch ...
- 九章算法:BAT国内班 - 课程大纲
第1章 国内笔试面试风格及准备方法 --- 分享面试经验,通过例题分析国内面试的风格及准备方法 · 1) C/C++部分: 实现 memcpy 函数 STL 中 vector 的实现原理 · 2)概率 ...
- 【算法模板】Binary Search 二分查找
模板:(通用模板,推荐) 给定一个排序的整数数组(升序)和一个要查找的整数target,用O(logn)的时间查找到target第一次出现的下标(从0开始),如果target不存在于数组中,返回-1. ...
随机推荐
- MVC WEB api 自动生成文档
最近在一直在用webapi做接口给移动端用.但是让我纠结的时候每次新加接口或者改动接口的时候,就需要重新修改文档这让我很是苦恼.无意中发现.webapi居然有自动生成文档的功能....真是看见了救星啊 ...
- WPF中XAML中使用String.Format格式化字符串示例
货币格式 <TextBlock Text="{Binding Price, StringFormat={}{0:C}}" /> // $123.46 货币格式,一位小数 ...
- 分布式文件系统MooseFS安装步骤
1. 安装 1.1 准备安装环境 首先选择一台比较好的服务器做master,如果可以在选择一台做为master的备份服务器最好.然后其他的服务器当chunkserver. 为了方便说明问题,我这 ...
- Linux下,连接器ld链接顺序的总结
原来ld对于链接一系列的库的顺序是很敏感的,不然会报undefined referenced 的函数符号错误,意思就是未找到函数定义.实际上库是能正确打开的.如果库libA.a依赖于库libB.a,那 ...
- Android自定义View——自定义搜索框(SearchView)
Android自定义View——自定义搜索框(SearchView) http://www.apkbus.com/android-142064-1-1.html
- hash_map和map的区别
hash_map和map的区别 分类: STL2008-10-15 21:24 5444人阅读 评论(0) 收藏 举报 class数据结构编译器存储平台tree 这里列几个常见问题,应该对你理解和使用 ...
- mvc和三层架构到底有什么区别
原文地址:http://zhidao.baidu.com/question/82001542.html?qbl=relate_question_3&word=MVC%20%CA%FD%BE%D ...
- 百度地图LV1.5实践项目开发工具类bmap.util.jsV1.1
/** * 百度地图使用工具类-v1.5 * * @author boonya * @date 2013-7-7 * @address Chengdu,Sichuan,China * @email b ...
- POJ22230 Watchcow (欧拉回路)
Watchcow Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 6477 Accepted: 2823 Specia ...
- fourinone分布式缓存研究和Redis分布式缓存研究
最近在写一个天气数据推送的项目,准备用缓存来存储数据.下面分别介绍一下fourinone分布式缓存和Redis分布式缓存,然后对二者进行对比,以供大家参考. 1 fourinone分布式缓存特性 1 ...