python 数据合并
1. 数据合并
前言
一、横向合并
1. 基本合并语句
2. 键值名不一样的合并
3. “两个数据列名字重复了”的合并
二、纵向堆叠
统计师的Python日记【第6天:数据合并】
前言
根据我的Python学习计划:
Numpy → Pandas → 掌握一些数据清洗、规整、合并等功能 → 掌握类似与SQL的聚合等数据管理功能 → 能够用Python进行统计建模、假设检验等分析技能 → 能用Python打印出100元钱 → 能用Python帮我洗衣服、做饭 → 能用Python给我生小猴子......
前面我把一些基本内容都掌握了,从Python的安装到语句结构、从Numpy/Pandas的数据格式到基本的描述性统计,现在终于要进入一个“应用型”的学习——数据的合并。
其实,我对数据合并很有感情,当年我在某国家医学数据库里实习的时候,就经常用SAS对数据库进行各种合并,以查看受访者在不同数据库中的属性,可以说是使用率非常高的一个技能。
先复习一下几种数据合并方式:左连接(left join)、右连接(right join)、内连接(inner join)、全连接(full join)。
左连接(left join):以左边的表为基准表,将右边的数据合并过来。
右连接(right join):以右边的表为基准表,将左边的数据合并过来。
内连接(inner join):左边和右边都出现的数据才进行合并。
全连接(full join):不管左边还是右边,只要出现的数据都合并过来。
以上的几种合并,都是按照姓名来合并的,两个表姓名一样,即将这条数据合并,这个姓名被称为键值,反正叫什么也无所谓,有一个变量被用来作为合并参照就可以了。
OK,今天将学习Python/Pandas的数据合并,合并是基于Pandas这个库,因此首先我们要导入库:import pandas as pd
准备工作完成,开始学习~
一、横向合并
1. 基本合并语句
我有两个数据:
D1 为某洗发店的会员数据,包括会员编号id和会员姓名name。
生成语句为:D1 = pd.DataFrame({'id':[801, 802, 803,804, 805, 806, 807, 808, 809, 810], 'name':['Ansel', 'Wang', 'Jessica', 'Sak','Liu', 'John', 'TT','Walter','Andrew','Song']})
D2为该洗发店本月的初值情况,可以看出,本月只有三位会员进行了储值。
生成语句为:D2 = pd.DataFrame({'id':[803, 804, 808,901], 'save': [3000, 500, 1200, 8800]})
现在我想将这两个表合并起来,即 “id-name-save” 的表,键值为id,基本语句为:merge(D1, D2, on='id')
哎,我记得合并有左连接、右连接等等,这里我什么也没指定,默认的貌似就是内连接(inner),D1中的801等好几个、D2中的901都没有被合并上,只合并了两个数据中都存在的。
好下面我来左连接,基本语句为:merge(D1, D2, on='id', how='left')
D1都被合并进来了,D2的901则没有。
再来一个右连接,基本语句为:merge(D1, D2, on='id', how='right')

右边的所有数据都被合并进来了。
全合并的基本语句为:merge(D1, D2, on='id', how='outer')

2. 键值名不一样的合并
刚刚的D1和D2,他们都有一个变量id,假如这个键值的名字不一样怎么办?一个叫“id1”、一个叫“id2”。
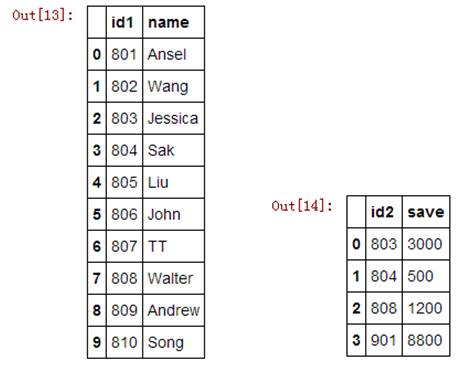
这种情况只要用 left_on= 和 right_on= 分别指定两个键的名字即可,基本语句为:merge(D1, D2, left_on='id1', right_on='id2')

我有一个比较变态的问题:如果数据1的键值是变量id,数据2的键值是一个索引,该怎么合并?像这样:

也很简单,使用 left_index=True 或 right_index=True,来声明某个数据的索引应该被当做键值,基本语句为:merge(D1, D2, left_on='id', right_index=True)

3. 两个数据的列名字重复了
如果两个数据有一样的变量名,那么合并会报错吗?举个例子,现在有803、804、808、901这四位会员3月的储值数据,数据名为D3Month。

生成语句为:D3Month= pd.DataFrame({'id':[803, 804, 808, 901], 'save': [3000, 500, 1200, 8800]})
以及四月的储值数据,数据名为D4Month:

生成语句为:D4Month= pd.DataFrame({'id':[803, 804, 808, 901], 'save': [0, 1500, 1000, 2000]})
现在想把两个表合并起来,但是两个数据都有save变量,合并之后会报错吗?来看一下吧~

没有报错,并且两个save自动打上了后缀,一个是_x,一个是_y,实际上,我们也可以自己加后缀,使用 suffixes=() 选项。比如,我将后缀变为:_3Month和_4Month,基本语句为:merge(D3Month, D4Month, on='id',how='left', suffixes=('_3Month', '_4Month’))

二、纵向堆叠
第一部分的内容学习的是将两个数据横向的合并,现在学习纵向合并——也叫做堆叠。比如,我们想象之前的会员数据,被分成了两个部分:
D1:

D2:

现在咱们再将这两个部分纵向的堆叠起来,注意对这类的堆叠问题,我在以后的日记中尽量不用“合并”这个词(而使用“堆叠”),以便和第一部分的merge区分开来。堆叠的基本语句为:concat([D1,D2])

这种情况我在之前的工作中也经常遇到,而且,常常会有这样的需求:堆叠起来的数据,能不能给个标志,标出哪部分来自D1,哪部分来自D2?
肯定可以,用 keys=[ , ] 来标识出来,基本语句为:concat([D1,D2], keys=['D1', 'D2'] )
当然我们也可以横向堆叠,指定 axis=1,注意喽,虽然是横向,但不是合并(merge),仍然是堆叠,横向堆叠就是粗暴的将两个数据横向堆在一起,请看:
仍然可以用 keys=[] 来标识出那边来自D1、哪边来自D2,基本语句为:concat([D1,D2], axis=1, keys=['D1', 'D2'] )
python 数据合并的更多相关文章
- python 数据清洗之数据合并、转换、过滤、排序
前面我们用pandas做了一些基本的操作,接下来进一步了解数据的操作, 数据清洗一直是数据分析中极为重要的一个环节. 数据合并 在pandas中可以通过merge对数据进行合并操作. import n ...
- Python数据科学手册-Pandas:合并数据集
将不同的数据源进行合并 , 类似数据库 join merge . 工具函数 concat / append pd.concat() 简易合并 合并高维数据 默认按行合并. axis=0 ,试试 axi ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- R︱高效数据操作——data.table包(实战心得、dplyr对比、key灵活用法、数据合并)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 由于业务中接触的数据量很大,于是不得不转战开始 ...
- Python数据预处理:机器学习、人工智能通用技术(1)
Python数据预处理:机器学习.人工智能通用技术 白宁超 2018年12月24日17:28:26 摘要:大数据技术与我们日常生活越来越紧密,要做大数据,首要解决数据问题.原始数据存在大量不完整.不 ...
- Python数据整合与数据准备-BigGorilla应用
一.前言 要应用BigGorilla框架对应数据进行数据的处理与匹配,那么首先要下载Anaconda安装,下载地址:https://www.continuum.io/downloads Anacond ...
- python书籍推荐:Python数据科学手册
所属网站分类: 资源下载 > python电子书 作者:today 链接:http://www.pythonheidong.com/blog/article/448/ 来源:python黑洞网 ...
- Python 数据科学-Numpy
NumPy Numpy :提供了一个在Python中做科学计算的基础库,重在数值计算,主要用于多维数组(矩阵)处理的库.用来存储和处理大型矩阵,比Python自身的嵌套列表结构要高效的多.本身是由C语 ...
- 100天搞定机器学习|day45-53 推荐一本豆瓣评分9.3的书:《Python数据科学手册》
<Python数据科学手册>共五章,每章介绍一到两个Python数据科学中的重点工具包.首先从IPython和Jupyter开始,它们提供了数据科学家需要的计算环境:第2章讲解能提供nda ...
随机推荐
- eclipse 创建一个java项目 运行
五.使用Eclipse 1)第一次打开需要设置工作环境,你可以指定工作目录,或者使用默认的C盘工作目录,点击 ok 按钮. 2)创建一个项目 3)输入项目名称,比如我输入Orz_Jlx,然后点击fin ...
- 网络网关TCP/IP
vmware中的4种网络连接模式 2008-11-13 11:11:21 分类: 系统运维 很多朋友都用vmware来测试不同的系统,我结合自己的经验谈一下对网络设置的理解,不对的地方请指正. bri ...
- 20181103_C#线程初探, BeginInvoke_EndInvoke
在C#中学习多线程之前, 必须要深刻的理解委托; 基本上所有的多线程都在靠委托来完成 一. 进程和线程: a) 进程和线程都是计算机的概念, 跟程序语言没有任何关系 b) 进程和线程都属于计算机操 ...
- 第七章 HTTP流量管理(二) URL 重写
URL 重定向功能: 浏览器中输入 http://<host_name>:31380/v1/service-A/XXXX 经过下面的重定向,实际调用的是serviceA的/v1/XXXX ...
- http的含义
HTTP是超文本传输协议,是客户端浏览器或其他程序与Web服务器之间的应用层通信协议.在Internet上的Web服务器上存放的都是 超文本信息,客户机需要通过HTTP协议传输所要访问的超文本信息.H ...
- java死锁及解决方案
死锁是两个甚至多个线程被永久阻塞时的一种运行局面,这种局面的生成伴随着至少两个线程和两个或者多个资源.避免死锁方针:a:避免嵌套封锁:这是死锁最主要的原因的,如果你已经有一个资源了就要避免封锁另一个资 ...
- win系统主机上的虚拟机NAT模式可修改3389端口做远程登录
当你只有一个公网IP的时候,那么这个IP基本上是要分给物理主机的,那么本机的虚拟机就只能选NAT网络模式了,那么想在外网直接远程虚拟机的话,修改虚拟机的远程登录端口(不修改也可以,主要是主机的3389 ...
- redis改密码
一. 如何初始化redis的密码? 总共2个步骤: a.在配置文件中有个参数: requirepass 这个就是配置redis访问密码的参数. 比如 requirepass test123 b.配置 ...
- JVM常用参数设置
堆内存设置 示例: java -Xmx4550m -Xms4550m -Xss128k -XX:NewRatio=5 -XX:SurvivorRatio=5 -Xmx4550m:设置JVM最大可用内存 ...
- 使用JAVA爬取去哪儿网入住信息
昨天帮一个商科同学爬取去哪儿网站的所有广州如家快捷酒店的所有入住信息. 就是上面的商务出行 xxx年入住这些东西 然而去哪儿的前端很强,在获取所有如家快捷酒店的时候就遇到了问题. 他显示的酒店列表是j ...