storm(二) 事务机制
前言
为了保证tuple的强有序和exactly-once语义,storm提供了事务机制,为每个tuple提供一个id
设计方法1
为每个tuple设置一个事务id,在数据库保存事务id和当前处理的id做比较。
1.两个id不一样,由于事务的强有序特点,判断出该tuple没有出现过,所以更新id
2.id一样,重复出现,可以不用处理
问题:
这样做会导致新能很低,每个tuple都必须处理完后才能处理下一个tuple(否则会影响和下一个tuple的顺序),并且每个tuple还得至少访问一次数据库
设计方法2
单个性能慢,很自然的就想到了多个一起处理。多个tuple形成一个batch。这样也可以保证强有序性
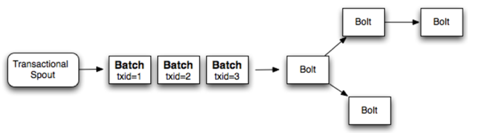
这样性能就提高了很多,如果一个batch处理了1000个tuples,那么性能就提高了1000倍。但是这还是没有更好的把资源利用充分。每个batch都是一个个处理,第二个batch必须等第一个batch完全处理完之后才能开始处理。

设计方法3
(storm选择的设计方法)
通过前两中设计方法,我们意识到了一个关键的思想,并不是所有的处理过程都需要保证强有序。只要保证最终执行完的那瞬间是强有序就ok。抽象出每次处理都需要两步。
1.计算一个batch的部分次数
2.在数据库更新该batch的部分次数
storm实现把对一个batch的计算分成了两块
1.处理。在此环节可以并发处理多个batch
2.提交。在此环节只能处理1个batch。这样就保证了强有序。
当这两块的其中某块出现问题,该事务都会被重新执行。
其实这跟设计方法二有点相似,都用了batch的思想。并结合分治思想,把整体尽可能的拆成许多小碎片,对每一个碎片都用最优的方法处理。
设计细节
1.storm把事务相关的信息存储在zookeeper中
2.storm会管理所有事务的处理或提交时机
3.关于容错。storm利用ack机制,会在合适的时候自动回放失败的事务。使用者不需要做任何acking
回放失败的事务需要一个tuple源的队列,比如kafka。
整体运行流程
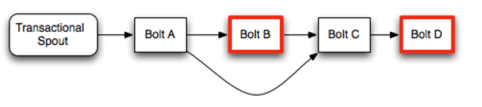
Processer必须等前一个Committer完成提交后才能调用finishBatch。
关于事务失败
由于事务框架屏蔽了Ack接口,提供了另一种方式,可以 throw FailedException.
关于配置
有两个重要配置
1.事务依赖的zookeeper,默认和storm集群依赖的一样,可以通过以下key修改
transactional.zookeeper.servers
2.同时处理batch的个数,默认是1,可以通过以下key修改
topology.max.spout.pending
参考资料
http://storm.apache.org/releases/1.1.1/Transactional-topologies.html
storm(二) 事务机制的更多相关文章
- Storm(三)Storm的原理机制
一.Storm的数据分发策略 1. Shuffle Grouping 随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同. 轮询,平均分配 2. ...
- Redis学习笔记~Redis事务机制与Lind.DDD.Repositories.Redis事务机制的实现
回到目录 Redis本身支持事务,这就是SQL数据库有Transaction一样,而Redis的驱动也支持事务,这在ServiceStack.Redis就有所体现,它也是目前最受业界认可的Redis ...
- 理解storm的ACKER机制原理
一.简介: storm中有一个很重要的特性: 保证发出的每个tuple都会被完整处理.一个tuple被完全处理的意思是: 这个tuple以及由这个tuple所产生的所有的子tuple都被成 ...
- Storm的ack机制在项目应用中的坑
正在学习storm的大兄弟们,我又来传道授业解惑了,是不是觉得自己会用ack了.好吧,那就让我开始啪啪打你们脸吧. 先说一下ACK机制: 为了保证数据能正确的被处理, 对于spout产生的每一个tup ...
- Kafka设计解析(八)- Exactly Once语义与事务机制原理
原创文章,首发自作者个人博客,转载请务必将下面这段话置于文章开头处. 本文转发自技术世界,原文链接 http://www.jasongj.com/kafka/transaction/ 写在前面的话 本 ...
- 学习RabbitMQ(三):AMQP事务机制
本文转自:http://m.blog.csdn.net/article/details?id=54315940 在使用RabbitMQ的时候,我们可以通过消息持久化操作来解决因为服务器的异常奔溃导致的 ...
- MQ确认机制之事务机制------tx
一:介绍 1.介绍 在前面的说的模式中会出现一个问题. 就是生产者将消息发送出去到底有没有到达rabbitMq,默认情况下是不知道. 有两种解决方式. AMQP实现事务机制 Confirm机制. 这里 ...
- {Django基础六之ORM中的锁和事务}一 锁 二 事务
Django基础六之ORM中的锁和事务 本节目录 一 锁 二 事务 一 锁 行级锁 select_for_update(nowait=False, skip_locked=False) #注意必须用在 ...
- Kafka设计解析(八)Exactly Once语义与事务机制原理
转载自 技术世界,原文链接 Kafka设计解析(八)- Exactly Once语义与事务机制原理 本文介绍了Kafka实现事务性的几个阶段——正好一次语义与原子操作.之后详细分析了Kafka事务机制 ...
随机推荐
- linux使用http代理连接服务器设置方法
连接腾讯的额cvm服务器官方给出的也有个方法,详细可以看这里:http://wiki.open.qq.com/wiki/%E4%BB%8E%E6%9C%AC%E5%9C%B0linux%E6%9C%B ...
- flask中current_app._get_current_object()与current_app有什么区别?
https://segmentfault.com/q/1010000005865632/a-1020000005865704
- js Ajax 跨域请求
一.使用jsonp的方式(只支持get请求) 二.使用cors的方式(支持HTTP的大部分请求方式) 三.apache的转发(修改服务器配置) 没有试验,暂时不详细写!
- Jumpserver使用
堡垒机介绍 在一个特定网络环境下,为了保障网络和数据不受外界入侵和破坏,而运用各种技术手段实时收集和监控网络环境中每一个组成部分的系统状态.安全事件.网络活动,以便集中报警.及时处理及审计定责. 我们 ...
- replace未全局替换的坑
今天是名副其实的周六.悠闲了一早上(太阳). 真是人在家中坐,BUG自天上来.哈哈其实也不是自天上来,还是自己之前埋下的雷. 所以修复完线上的bug,我脑中立刻浮现出两件还需要做的事情: 一,就是我现 ...
- Win32调试API原理
在Win32中自带了一些API函数,它们提供了相当于一般调试器的大多数功能,这些函数统称为Win32调试API(Win32 Debug API).利用这些API可以做到加载一个程序或捆绑到一个正在运行 ...
- django组件之ContentType
ContentTyep组件: 帮助我们关联所有数据库的表 帮助我们反向查询关联数据表中的所有策略信息 GenericForeignkey(帮助我们快速插入数据) GenericRelation(用于反 ...
- 前端 javascript 定时器
setInterval("执行的代码",间隔时间)毫秒单位 每5秒一次会提示出弹框 <!DOCTYPE html> <html lang="en&quo ...
- SharePoint 2013 附加内容数据库后出现404错误
本文讲述怎样解决SharePoint 2013 加内容数据库(Content DataBase)后出现404错误. 笔者依照http://technet.microsoft.com/en-us/lib ...
- 15.遇到window leaked的解决方法
遇到这个可能是android:configChanges没有配置好 可以试试配置为这个 mcc|mnc|locale|touchscreen|keyboard|keyboardHidden|navig ...