Spark 源码分析 -- Stage
理解stage, 关键就是理解Narrow Dependency和Wide Dependency, 可能还是觉得比较难理解
关键在于是否需要shuffle, 不需要shuffle是可以随意并发的, 所以stage的边界就是需要shuffle的地方, 如下图很清楚
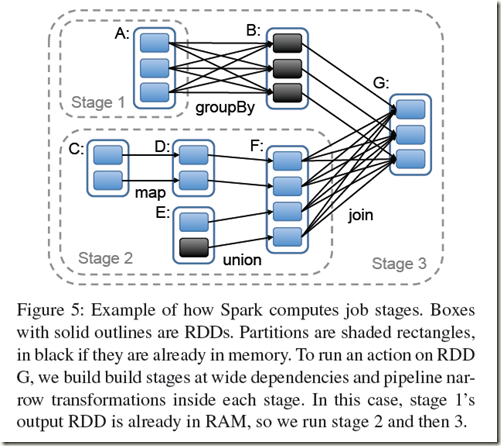
并且Stage分为两种,
shuffle map stage, in which case its tasks' results are input for another stage
其实就是,非最终stage, 后面还有其他的stage, 所以它的输出一定是需要shuffle并作为后续的输入
result stage, in which case its tasks directly compute the action that initiated a job (e.g. count(), save(), etc)
最终的stage, 没有输出, 而是直接产生结果或存储
1 stage class
这个注释写的很清楚
可以看到stage的RDD参数只有一个RDD, final RDD, 而不是一系列的RDD
因为在一个stage中的所有RDD都是map, partition不会有任何改变, 只是在data依次执行不同的map function
所以对于task scheduler而言, 一个RDD的状况就可以代表这个stage
/**
* A stage is a set of independent tasks all computing the same function that need to run as part
* of a Spark job, where all the tasks have the same shuffle dependencies. Each DAG of tasks run
* by the scheduler is split up into stages at the boundaries where shuffle occurs, and then the
* DAGScheduler runs these stages in topological order.
*
* Each Stage can either be a shuffle map stage, in which case its tasks' results are input for
* another stage, or a result stage, in which case its tasks directly compute the action that
* initiated a job (e.g. count(), save(), etc). For shuffle map stages, we also track the nodes
* that each output partition is on.
*
* Each Stage also has a jobId, identifying the job that first submitted the stage. When FIFO
* scheduling is used, this allows Stages from earlier jobs to be computed first or recovered
* faster on failure.
*/
private[spark] class Stage(
val id: Int,
val rdd: RDD[_], // final RDD
val shuffleDep: Option[ShuffleDependency[_,_]], // Output shuffle if stage is a map stage
val parents: List[Stage], // 父stage
val jobId: Int,
callSite: Option[String])
extends Logging { val isShuffleMap = shuffleDep != None // 是否是shuffle map stage, 取决于是否有shuffleDep
val numPartitions = rdd.partitions.size
val outputLocs = Array.fill[List[MapStatus]](numPartitions)(Nil) // 用于buffer每个shuffle中每个maptask的MapStatus
var numAvailableOutputs = 0 private var nextAttemptId = 0
def isAvailable: Boolean = {
if (!isShuffleMap) {
true
} else {
numAvailableOutputs == numPartitions
}
}}
2 newStage
如果是shuffle map stage, 需要在这里向mapOutputTracker注册shuffle
/**
* Create a Stage for the given RDD, either as a shuffle map stage (for a ShuffleDependency) or
* as a result stage for the final RDD used directly in an action. The stage will also be
* associated with the provided jobId.
*/
private def newStage(
rdd: RDD[_],
shuffleDep: Option[ShuffleDependency[_,_]],
jobId: Int,
callSite: Option[String] = None)
: Stage =
{
if (shuffleDep != None) {
// Kind of ugly: need to register RDDs with the cache and map output tracker here
// since we can't do it in the RDD constructor because # of partitions is unknown
logInfo("Registering RDD " + rdd.id + " (" + rdd.origin + ")")
mapOutputTracker.registerShuffle(shuffleDep.get.shuffleId, rdd.partitions.size)
}
val id = nextStageId.getAndIncrement()
val stage = new Stage(id, rdd, shuffleDep, getParentStages(rdd, jobId), jobId, callSite)
stageIdToStage(id) = stage
stageToInfos(stage) = StageInfo(stage)
stage
}
3 getMissingParentStages
可以根据final stage的deps找出所有的parent stage
private def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
visited += rdd
if (getCacheLocs(rdd).contains(Nil)) {
for (dep <- rdd.dependencies) {
dep match {
case shufDep: ShuffleDependency[_,_] => // 如果发现ShuffleDependency, 说明遇到新的stage
val mapStage = getShuffleMapStage(shufDep, stage.jobId) // check shuffleToMapStage, 如果该stage已经被创建则直接返回, 否则newStage
if (!mapStage.isAvailable) {
missing += mapStage
}
case narrowDep: NarrowDependency[_] => // 对于NarrowDependency, 说明仍然在这个stage中
visit(narrowDep.rdd)
}
}
}
}
}
visit(stage.rdd)
missing.toList
}
Spark 源码分析 -- Stage的更多相关文章
- Spark源码分析 – 汇总索引
http://jerryshao.me/categories.html#architecture-ref http://blog.csdn.net/pelick/article/details/172 ...
- Spark源码分析 – DAGScheduler
DAGScheduler的架构其实非常简单, 1. eventQueue, 所有需要DAGScheduler处理的事情都需要往eventQueue中发送event 2. eventLoop Threa ...
- Spark源码分析之四:Stage提交
各位看官,上一篇<Spark源码分析之Stage划分>详细讲述了Spark中Stage的划分,下面,我们进入第三个阶段--Stage提交. Stage提交阶段的主要目的就一个,就是将每个S ...
- Spark源码分析之三:Stage划分
继上篇<Spark源码分析之Job的调度模型与运行反馈>之后,我们继续来看第二阶段--Stage划分. Stage划分的大体流程如下图所示: 前面提到,对于JobSubmitted事件,我 ...
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...
- spark 源码分析之十九 -- Stage的提交
引言 上篇 spark 源码分析之十九 -- DAG的生成和Stage的划分 中,主要介绍了下图中的前两个阶段DAG的构建和Stage的划分. 本篇文章主要剖析,Stage是如何提交的. rdd的依赖 ...
- Spark源码分析:多种部署方式之间的区别与联系(转)
原文链接:Spark源码分析:多种部署方式之间的区别与联系(1) 从官方的文档我们可以知道,Spark的部署方式有很多种:local.Standalone.Mesos.YARN.....不同部署方式的 ...
- Spark 源码分析 -- task实际执行过程
Spark源码分析 – SparkContext 中的例子, 只分析到sc.runJob 那么最终是怎么执行的? 通过DAGScheduler切分成Stage, 封装成taskset, 提交给Task ...
- Spark源码分析 – Shuffle
参考详细探究Spark的shuffle实现, 写的很清楚, 当前设计的来龙去脉 Hadoop Hadoop的思路是, 在mapper端每次当memory buffer中的数据快满的时候, 先将memo ...
随机推荐
- CentOS 6.2修改主机名
写在前面的话:因为服务器要统一主机名,但是在安装的时候忘记设置了,所以需要修改主机名 需要修改两处:一处是/etc/sysconfig/network,另一处是/etc/hosts,只修改任一处会 ...
- db2 连接报错connect。 ERRORCODE=-4499, SQLSTATE=08001(转载)
在使用data studio连接远程DB2数据库时报错如下: [jcc][Thread:main][SQLException@5b775b77] java.sql.SQLException [jcc] ...
- RP2837 OUT1-OUT2 对应关系 2路DO
RP2837 OUT1-OUT2 对应关系: OUT1 AD2 PD22 继电器1 OUT2 AD4 PD24 继电器2 root@sama5d3-linux:~ echo 11 ...
- keepalived管理LVS文件详解
#全局设置,只设置一个 全局路由就可以,全局路由不能重复唯一标识. global_defs { router_id LVS_01 #全局路由ID,唯一不能重复 } #实例 vrrp_instance ...
- CRC16
http://www.stmcu.org/chudonganjin/blog/12-08/230184_515e6.html 1.循环校验码(CRC码): 是数据通信领域中最常用的一种差错校验码,其特 ...
- 数论 + 容斥 - HDU 4059 The Boss on Mars
The Boss on Mars Problem's Link Mean: 给定一个整数n,求1~n中所有与n互质的数的四次方的和.(1<=n<=1e8) analyse: 看似简单,倘若 ...
- 二分图匹配 + 最小点覆盖 - Vertex Cover
Vertex Cover Problem's Link Mean: 给你一个无向图,让你给图中的结点染色,使得:每条边的两个顶点至少有一个顶点被染色.求最少的染色顶点数. analyse: 裸的最小点 ...
- mongodb和redis设计原理简析
转自:http://blog.csdn.net/yangbutao/article/details/8309539 redis: 1.NIO通信 因都在内存操作,所以逻辑的操作非常快,减少 ...
- VC++中CEdit控件实现回车换行
1.通过回车Enter换行: 这里要有两个设置 <1>.将控件的属性设置为Mutilines->true; <2>.将控件的另一个属性设置为Want return-> ...
- hdu 4715(打表)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4715 思路:先打个素数表,然后判断一下就可以了. #include<iostream> # ...