ResNet详解(转)
本篇文章涉及到的文献
- Residual Network(ResNet)
- Deep Residual Learning for Image Recognition[arXiv:1512.03385]
- Identity Mappings in Deep Residual Networks[arXiv:1603.05027]
- 2016_tutorial_deep_residual_networks
- ResNet-50 Architecture
- KaimingHe/deep-residual-networks
- CS231n 2017 lecture9
- BIGBALLON/cifar-10-cnn
妹纸:昨天试了一下VGG19,训练时间挺久的,不过效果不错。
花花:呜呜,前几天我们都在讲很基本的网络架构,今天我们讲稍微难一丢丢的。
妹纸:好啊,好啊!我猜是ResNet!
花花:你猜得真准(23333orz)。
最原始的 Residual Network
Residual Network,简称 ResNet(残差网络),是MSRA 何凯明 团队设计的一种网络架构,在2015年的ILSVRC 和 COCO 上拿到了多项冠军,其发表的论文Deep Residual Learning for Image Recognition, 是 CVPR 2016 的最佳论文。
Residual Network的历史从这里开始。
卷积神经网络(Convolutional Neural Network)正不断朝着“Deep”这个方向发展,最早期的LeNet只有5层,后来VGG把深度增加到19层,而我们即将要介绍的ResNet,更是超过了100层。
人们不禁要问:
Is learning better networks as easy as stacking more layers?
不,事实并非如此
只是简单地增加网路的深度,不能得到很好的效果,甚至还会使误差增大:

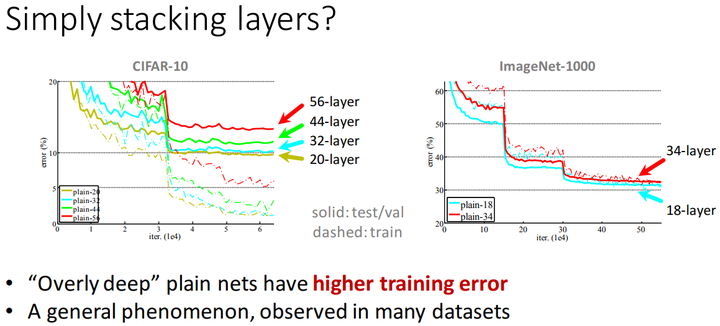
多个datasets的测试表明,仅仅只是简单地堆叠卷积层,并不能让网络训练得更好。
按理来说,如果网络加深,training acc应该增大,而testing acc减小,但是上图并不是这么回事,于是乎,Kaiming He提出了Deep Residual Learning的架构。
关于残差模块(residual block)
这里Kaiming聚聚首先引入了一个残差模块(residual block)的概念
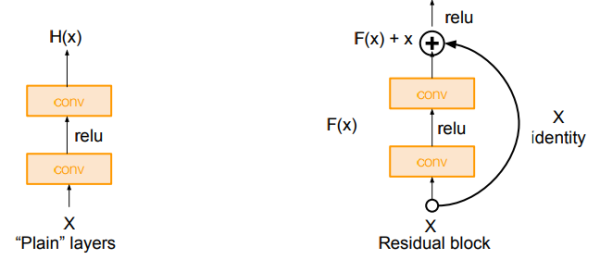
上图所示的Residual Block:
输入为 ,需要拟合的结果(输出)为
。
那么我们把输出差分为 ,也就是
再令 ,意思是
也是由
拟合而来,
那么最后的输出就变为 本来就是输入,
所以我们就只需要拟合 就好了。
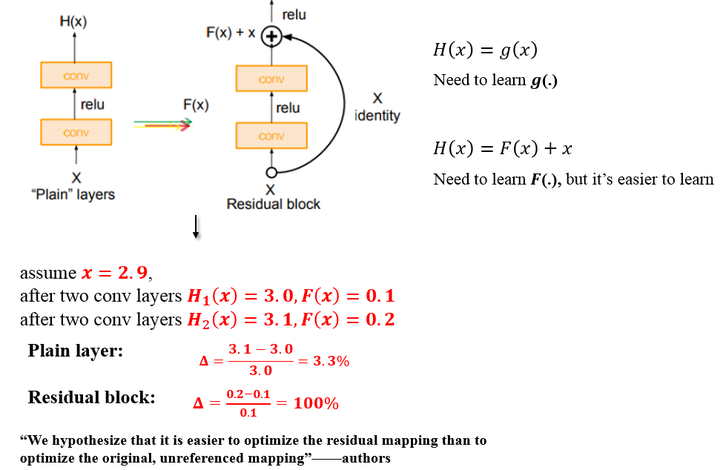
如上图,原始的plain架构,我们用两层卷积层来模拟函数 ,
而在residual block中,我们用两层卷积层来模拟函数
举个例子:
输入 , 经过拟合后的输出为
那么残差就是
如果拟合的是恒等变换,即输入 ,输出还是
那么残差就是
而如上图所示,假设 从
经过两层卷基层(conv)之后变为
,
平原网络的变化率
而残差模块的变化率为
残差的引入去掉了主体部分,从而突出了微小的变化。我想这是他们敢说
We hypothesize that it is easier to optimize the residual mapping than to optimize
the original, unreferenced mapping
的原因。
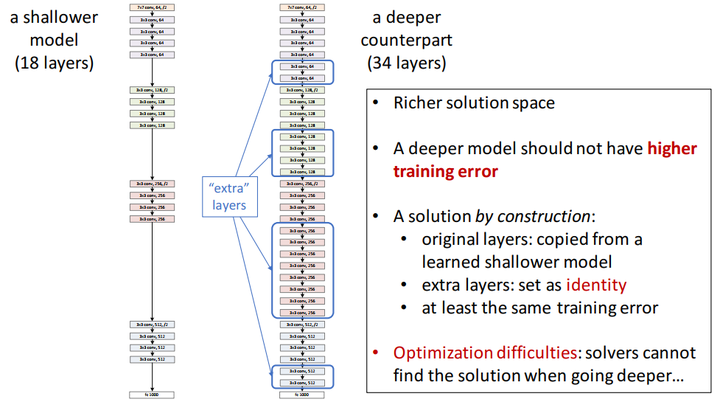
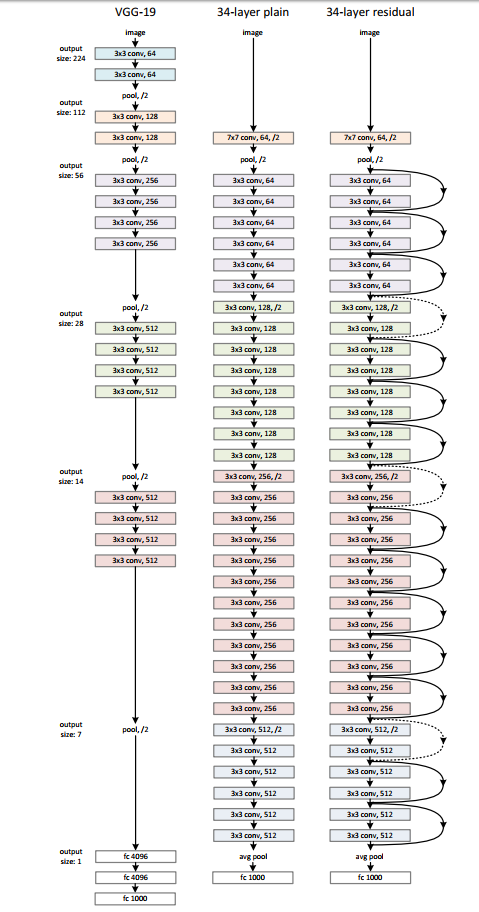
有了残差模块(residual block)这个概念,我们再来设计网络架构,
架构很简单,基于VGG19的架构,我们首先把网络增加到34层,增加过后的网络我们叫做plain network,再此基础上,增加残差模块,得到我们的Residual Network
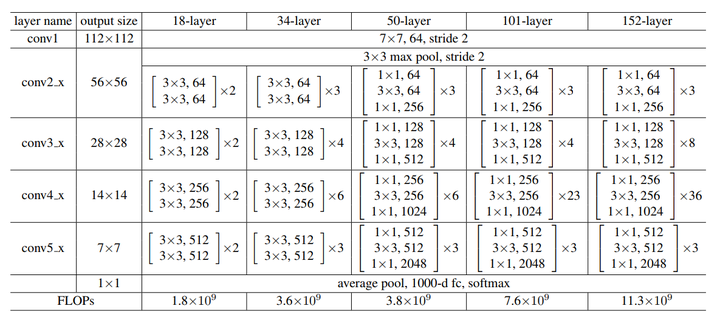
关于bottleneck
论文中有两种residual block的设计,如下图所示:
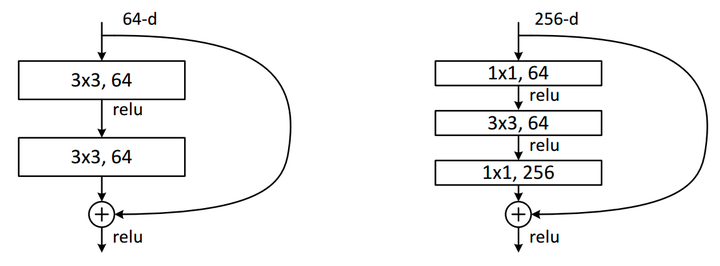
在训练浅层网络的时候,我们选用前面这种,而如果网络较深(大于50层)时,会考虑使用后面这种(bottleneck),这两个设计具有相似的时间复杂度。
同样举个例子:
对于ImageNet而言,进入到第一个residual block的input为
采用左侧的两个 的卷积层:
参数量为
化简一下:
采用右侧的bottleneck:
参数量为
化简一下:
可以看到它们的参数量属于同一个量级,
但是这里bottleneck占用了整个network的「三层」,而原本只有「两层」,
所以这样就节省了大量的参数,
在大于50层的resnet中,他们使用了bottleneck这种形式。
具体细节如图所示:
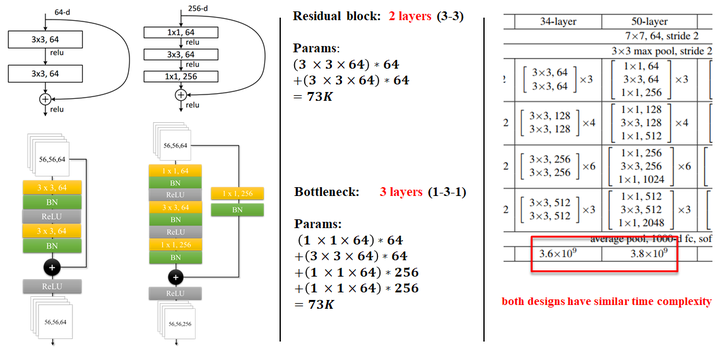
如果你还有问题,参考这里 ResNet之Deeper Bottleneck Architectures
Identity mapping 改进
Kaiming He最初的paper,就是上面介绍的部分,但很快,他们又对ResNet提出了进一步的改进,这便是我们接下来要提到的paper:
Identity Mappings in Deep Residual Networks[arXiv:1603.05027]
我们来仔细分析一下Residual Block, 在这篇paper中也被叫为Residual Unit.
对于原始的 Residual Unit(block),我们有如下计算:
表示 第
个Residual Unit的输入,
则代表 第
个Residual Unit的输出
代表的某个变换,在这里是恒等变换,
代表residual function,
代表某种操作,在这里是ReLU
所以可以写成如下形式:
也就是Residual Unit一开始的做法了。
那如果,我们 是恒等变换呢,即
,那么有:
对于任意一层,我们都能用这个公式来表示:
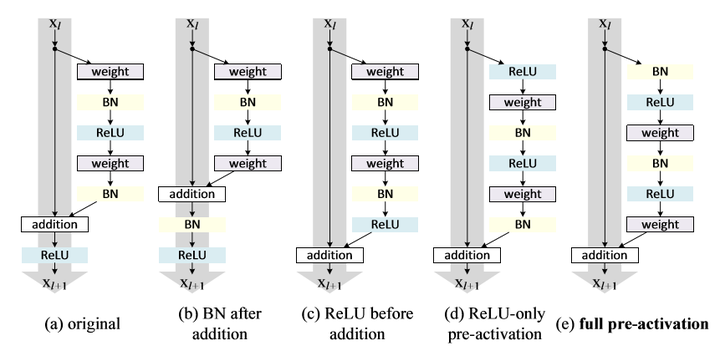
这便是这篇paper的改进,把原本的ReLU,放到Residual Unit的conv前面去,而不是放在addition之后。
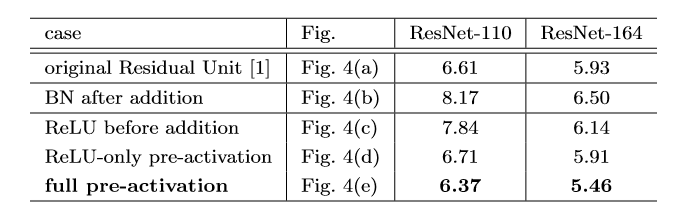
可以看到,在上图作者对cifar10进行的多组实验中,使用full pre-activation这种Residul Unit效果最佳,个人认为这张表格还是挺重要的,我们简单分析一下!
- (a)original:原始的结构
- (b)BN after addition:这是在做相反的实验,本来我们的目的是把ReLU移到旁路上去,这里反而把BN拿出来,这进一步破坏了主路线上的恒等关系,阻碍了信号的传递,从结果也很容易看出,这种做法不ok
- (c)ReLU before addition:将
变为恒等变换,最容易想到的方法就是将ReLU直接移动到BN后面,但这会出现一个问题,一个
(残差函数)的输出应该可以是
,但是经过ReLU之后就会变为
,这种做法的结果,也比(a)要差。
直接提上来似乎不行,但是问题反过来想, 在addition之后做ReLU,不是相当于在下一次conv之前做ReLU吗?
- (d)ReLU-only pre-activation:根据刚才的想法,我们把ReLU放到前面去,然而我们得到的结果和(a)差不多,原因是什么呢?因为这个ReLU层不与BN层连接使用,因此无法共享BN所带来的好处。
- (e)full pre-activation:啊,那要不我们也把BN弄前面去,惊喜出现了,我们得到了相当可观的结果,是的,这便是我们最后要使用的Unit结构!!!
代码实现
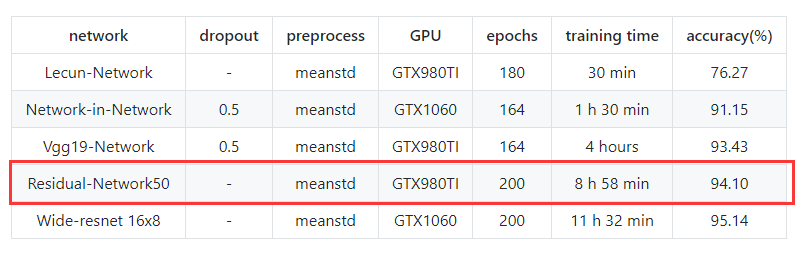
终于到了可以写代码的时候了,
还是放在我的 Github,测试只是用了50层,
使用GTX980TI,训练时间为 8 h 58 min
最后testing accuracy:94.10%
妹纸:哇,ResNet的residual block好帅气啊,何凯明简直是我男神!
花花:喔,他是所有人心中的男神!
妹纸:要训练9个小时啊,我周末试一下啊
花花:你的是1080TI,训练个毛9小时,我980TI才要9小时啊!!
妹纸:啊,反正是学长给配的
花花:啊,2333
ResNet详解(转)的更多相关文章
- ResNet详解与分析
目录 Resnet要解决的是什么问题 Residual Block的设计 ResNet 网络结构 error surface对比 Residual Block的分析与改进 小结 参考 博客:博客园 | ...
- 【转载】NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩、机器学习及最优化算法
原文:NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩.机器学习及最优化算法 导读 AI领域顶会NeurIPS正在加拿大蒙特利尔举办.本文针对实验室关注的几个研究热点,模型压缩.自 ...
- 深度学习基础(CNN详解以及训练过程1)
深度学习是一个框架,包含多个重要算法: Convolutional Neural Networks(CNN)卷积神经网络 AutoEncoder自动编码器 Sparse Coding稀疏编码 Rest ...
- [Network Architecture]DPN(Dual Path Network)算法详解(转)
https://blog.csdn.net/u014380165/article/details/75676216 论文:Dual Path Networks 论文链接:https://arxiv.o ...
- 转载:DenseNet算法详解
原文连接:http://blog.csdn.net/u014380165/article/details/75142664 参考连接:http://blog.csdn.net/u012938704/a ...
- DenseNet算法详解——思路就是highway,DneseNet在训练时十分消耗内存
论文笔记:Densely Connected Convolutional Networks(DenseNet模型详解) 2017年09月28日 11:58:49 阅读数:1814 [ 转载自http: ...
- 官网实例详解-目录和实例简介-keras学习笔记四
官网实例详解-目录和实例简介-keras学习笔记四 2018-06-11 10:36:18 wyx100 阅读数 4193更多 分类专栏: 人工智能 python 深度学习 keras 版权声明: ...
- 训练技巧详解【含有部分代码】Bag of Tricks for Image Classification with Convolutional Neural Networks
训练技巧详解[含有部分代码]Bag of Tricks for Image Classification with Convolutional Neural Networks 置顶 2018-12-1 ...
- 全卷积神经网络FCN详解(附带Tensorflow详解代码实现)
一.导论 在图像语义分割领域,困扰了计算机科学家很多年的一个问题则是我们如何才能将我们感兴趣的对象和不感兴趣的对象分别分割开来呢?比如我们有一只小猫的图片,怎样才能够通过计算机自己对图像进行识别达到将 ...
随机推荐
- html5标签---不常用新标签的整理
状态标签 meter 用来显示已知范围的标量值或者分数值. value:当前的数值. min:值域的最小边界值.如果设置了,它必须比最大值要小.如果没设置,默认为0 max:值域的上限边界值.如果设置 ...
- java GC机制(转)
http://blog.csdn.net/zsuguangh/article/details/6429592 1. 垃圾回收的意义 在C++中,对象所占的内存在程序结束运行之前一直被占用,在明确释放之 ...
- mdb
计划开发高性能KV数据库, 学习MongoDB leveldb innodb, 练手贴+日记贴: http://bbs.chinaunix.net/thread-4244870-1-1.html 超高 ...
- SVN错误:Attempted to lock an already-locked dir及不能提交.so文件
当使用svn提交代码时,如果中断提交,就会进入工作拷贝的锁定状态. 这是需要用svn cleanup上次关闭时的锁定 如果没有Tortises,则直接进入到上面的文件夹下的.svn目录,删除lock文 ...
- Redis缓存相关
Redis缓存服务搭建及实现数据读写 RedisHelper帮助类 /// <summary> /// Redis 帮助类文件 /// </summary> public cl ...
- 团体程序设计天梯赛L1-022 奇偶分家 2017-03-22 17:48 81人阅读 评论(0) 收藏
L1-022. 奇偶分家 时间限制 400 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 给定N个正整数,请统计奇数和偶数各有多少个? 输入格式 ...
- [转发]Oauth 1.0 1.0a 和 2.0 的之间的区别有哪些?
原文地址:http://www.zhihu.com/question/19851243
- Wait--查看等待
--清除等待统计 --===================================================== --清除等待统计 DBCC SQLPERF (N'sys.dm_os_ ...
- C# winfrom 存取图片到数据库(二进制,image)
1.读取本地图片到PictureBox public void InageShow(PictureBox PB) { OpenFileDialog openfile = new OpenFileDia ...
- 使用SqlBulkCopy进行批量插入数据时踩过的坑
之前一直都没用过SqlBulkCopy关键字进行数据插入,更没了解过. 事因:因业务需要在数据表中添加两列,然后将数据插入进表中 之前都是这样写的 dt.Columns.Add(new DataCol ...