Python入门,以及简单爬取网页文本内容
最近痴迷于Python的逻辑控制,还有爬虫的一方面,原本的目标是拷贝老师上课时U盘的数据。后来发现基础知识掌握的并不是很牢固。便去借了一本Python基础和两本爬虫框架的书。便开始了自己的入坑之旅
言归正传
前期准备
Import requests;我们需要引入这个包。但是有些用户环境并不具备这个包,那么我们就会在引入的时候报错

这个样子相信大家都不愿意看到那么便出现了一下解决方案
我们需要打开Cmd 然后进入到我们安装Python的Scripts目录下输入指令
pip install requests
当然还会出现下面的情况
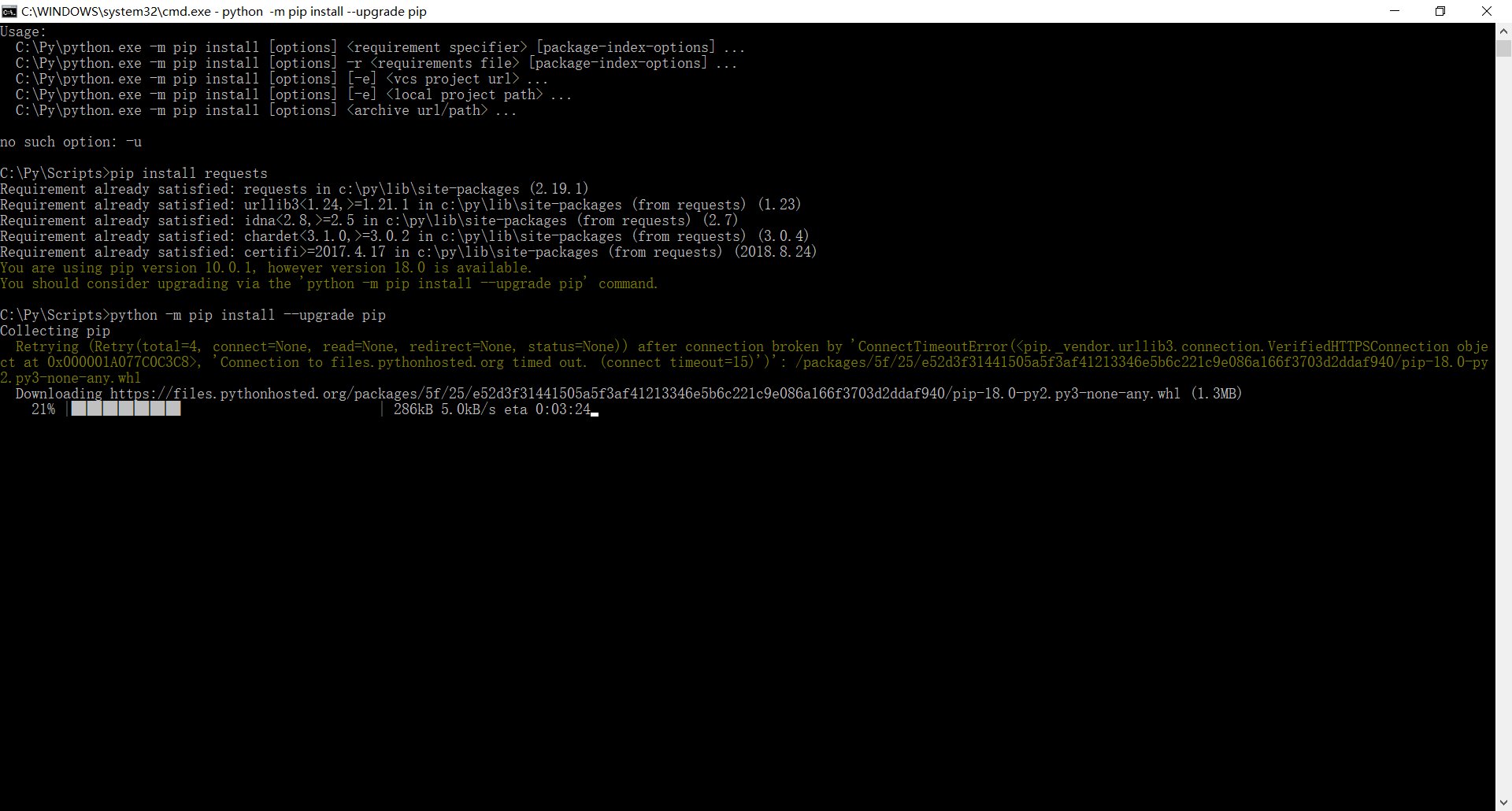
又是一个报错是不是很烦 那么我们按它的提示升级一下组件 输入命令 python -m pip install --upgrade pip 安装成功后我们便可以正常的导入 requests 那么我们是不是就可以做一下什么了?比如说爬取一个网站的所有信息爬取下来?
import requests;
//导入我们需要的库 def GetName(url):
//定义一个函数并且传入参数Url
resp=requests.get(url);
//获取网页上的所有信息 //以文本的模型返回
return resp.text; //定义一个字符串也就是我们要爬取的地址
url="https:xxxxxxxxxx"; //函数方法
def xieru():
//打开一个文本,以写入的方式写入二级制文本
fi=open('E://1.txt',"wb+");
//接受
con = GetName(url);
//返还的文本转换编码格式
ss=con.encode('utf-8')
//写入打开的文本中
fi.write(ss);
return 0; xieru(); 哈哈 上面的网址就打码了哦,大家自己脑补。
这是我爬取的内容

Python入门,以及简单爬取网页文本内容的更多相关文章
- java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度.谷歌他们的搜索引擎就是个爬虫. 现在大二.再次燃起对爬虫的热爱,查阅资料,知道常用java.python语言编程,这次我选择了 ...
- 【Python】python3 正则爬取网页输出中文乱码解决
爬取网页时候print输出的时候有中文输出乱码 例如: \\xe4\\xb8\\xad\\xe5\\x8d\\x8e\\xe4\\xb9\\xa6\\xe5\\xb1\\x80 #爬取https:// ...
- python爬取网页文本、图片
从网页爬取文本信息: eg:从http://computer.swu.edu.cn/s/computer/kxyj2xsky/中爬取讲座信息(讲座时间和讲座名称) 注:如果要爬取的内容是多页的话,网址 ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- python使用requests库爬取网页的小实例:爬取京东网页
爬取京东网页的全代码: #爬取京东页面的全代码 import requests url="https://item.jd.com/2967929.html" try: r=requ ...
- Python -- 网络编程 -- 简单抓取网页
抓取网页: urllib.request.urlopen(url).read().decode('utf-8') --- (百度是utf-8,谷歌不是utf-8,也不是cp936,ascii也不行 ...
- java实现多线程使用多个代理ip的方式爬取网页页面内容
项目的目录结构 核心源码: package cn.edu.zyt.spider; import java.io.BufferedInputStream; import java.io.FileInpu ...
- MVC爬取网页指定内容到数据库
控制器 //获取并插入 //XPath获取 public JsonResult Add(string url) { HtmlWeb web = new HtmlWeb(); HtmlDocument ...
- Python学习笔记之爬取网页保存到本地文件
爬虫的操作步骤: 爬虫三步走 爬虫第一步:使用requests获得数据: (request库需要提前安装,通过pip方式,参考之前的博文) 1.导入requests 2.使用requests.get ...
随机推荐
- 基于canvas的图片编辑合成器
在我们日常的前端开发中,经常会要给服务器上传图片,但是局限很大,图片只能是已有的,假设我想把多张图片合成一张上传就需要借助图片编辑器了,但是现在我们有了canvas合成就简单多了 首先我们看图片编辑器 ...
- react CRA antd 按需加载配置 lessloader
webpack配置 webpack.config.dev.js, webpack.config.prod同理. 'use strict'; const autoprefixer = require(' ...
- 使用showplan.sql分析sql Performance
在HelloDBA网站找到一个分析sql性能的工具-showplan,记录一下 showplan.sql下载路径:http://www.HelloDBA.com/Download/showplan.z ...
- PIP安装时报The repository located at pypi.douban.com is not a trusted or secure host and is being ignore
C:\WINDOWS\system32>pip install scrapyCollecting scrapy The repository located at pypi.douban.com ...
- [ python ] 购物系统
作业需求 1. 购物系统,能够注册登录,用户第一次登录后,让用户输入金额,然后打印商品列表2. 允许用户根据商品编号购买商品3. 用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒4. 购买完一 ...
- 转:google测试分享-SET和TE
原文: http://blog.sina.com.cn/s/blog_6cf812be0102vbnb.html 前端时间看了google测试之道,收获了一些,在此总结下并打算写一个系列blog,顺 ...
- Morris Traversal方法遍历
实现二叉树的遍历且只需要O(1)的空间. 参考:http://www.cnblogs.com/AnnieKim/archive/2013/06/15/MorrisTraversal.html
- P1084 疫情控制
Solution 二分答案, 尽量往上跳, 不能跳到根节点. 仍然能跳的拿出来.看剩下的点没有覆盖哪个? 贪心的分配一下. Code 70 #include<iostream> #incl ...
- 数据库连接池(c3p0与druid)
1.数据库连接池概念 其实就是一个容器(集合),存放数据库连接的容器.当系统初始化好后,容器被创建,容器中会申请一些连接对象,当用户来访问数据库时,从容器中获取连接对象,用户访问完之后,会将连接对象归 ...
- (三)Spring 之AOP 详解
第一节:AOP 简介 AOP 简介:百度百科: 面向切面编程(也叫面向方面编程):Aspect Oriented Programming(AOP),是软件开发中的一个热点,也是Spring框架中的一个 ...