SPSS Clementine 数据挖掘入门1
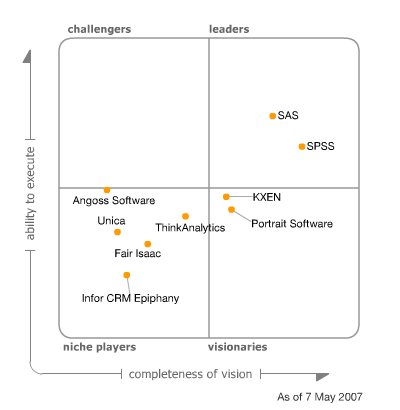
SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技术创新方面遥遥领先。
SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。下面就是clementine客户端的界面。

一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。是否以跃跃欲试了呢,别急,精彩的还在后面 ^_’
顾名思义,是对项目的管理,提供了两种视图。其中CRISP-DM (Cross Industry Standard Process for Data Mining,数据挖掘跨行业标准流程)是由SPSS、DaimlerChrysler(戴姆勒克莱斯勒,汽车公司)、NCR(就是那个拥有Teradata的公司)共同提出的。Clementine里通过组织CRISP-DM的六个步骤完成项目。在项目中可以加入流、节点、输出、模型等。
工具栏总包括了ETL、数据分析、挖掘模型工具,工具可以加入到数据流设计区中,跟SSIS中的数据流非常相似。Clementine中有6类工具。
源工具(Sources)
相当SSIS数据流中的源组件啦,clementine支持的数据源有数据库、平面文件、Excel、维度数据、SAS数据、用户输入等。
记录操作(Record Ops)和字段操作(Field Ops)
相当于SSIS数据流的转换组件,Record Ops是对数据行转换,Field Ops是对列转换,有些类型SSIS的异步输出转换和同步输出转换(关于SSIS异步和同步输出的概念,详见拙作:http://www.cnblogs.com/esestt/archive/2007/06/03/769411.html)。
图形(Graphs)
用于数据可视化分析。
输出(Output)
Clementine的输出不仅仅是ETL过程中的load过程,它的输出包括了对数据的统计分析报告输出。

※在ver 11,Output中的ETL数据目的工具被分到了Export的工具栏中。

模型(Model)
Clementine中包括了丰富的数据挖掘模型。

这个没什么好说的,看图就知道了,有向的箭头指明了数据的流向。Clementine项目中可以有多个数据流设计区,就像在PhotoShop中可以同时开启多个设计图一样。
比如说,我这里有两个数据流:Stream1和Stream2。通过在管理区的Streams栏中点击切换不同的数量流。
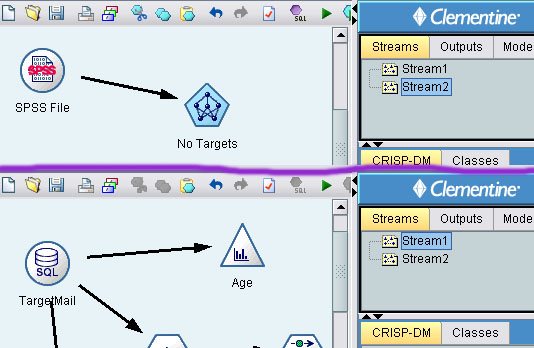
管理区包括Streams、Outputs、Models三栏。Streams上面已经说过了,是管理数据流的。
Outputs
不要跟工具栏中的输出搞混,这里的Outputs是图形、输出这类工具产生的分析结果。例如,下面的数据源连接到矩阵、数据审查、直方图工具,在执行数据流后,这个工具产生了三个输出。在管理区的Outputs栏中双击这些输出,可看到输出的图形或报表。
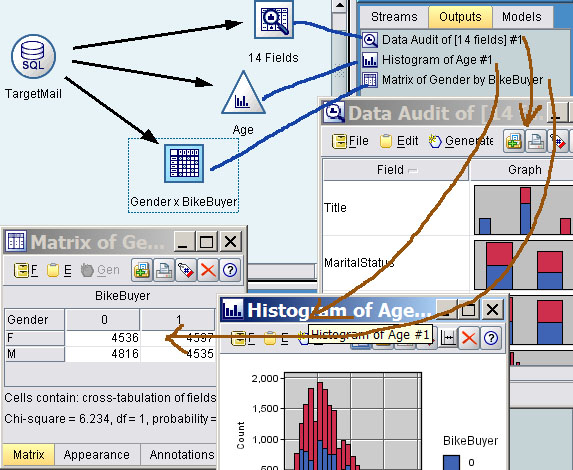
Models
经过训练的模型会出现在这一栏中,这就像是真表(Truth Table)的概念那样,训练过的模型可以加入的数据流中用于预测和打分。另外,模型还可以导出为支持PMML协议的XML文件,但是PMML没有给定所有模型的规范,很多厂商都在PMML的基础上对模型内容进行了扩展,Clementine除了可以导出扩展的SPSS SmartScore,还可以导出标准的PMML 3.1。
SPSS Clementine 数据挖掘入门1的更多相关文章
- SPSS Clementine 数据挖掘入门3
转摘:http://www.cnblogs.com/dekevin/archive/2012/04/27/2473683.html 了解SPSS Clementine的基本应用后,再对比微软的SSAS ...
- SPSS Clementine 数据挖掘入门2
下面使用Adventure Works数据库中的Target Mail作例子,通过建立分类树和神经网络模型,决策树用来预测哪些人会响应促销,神经网络用来预测年收入. Target Mail数据在SQL ...
- SPSS Modeler数据挖掘项目实战(数据挖掘、建模技术)
SPSS Modeler是业界极为著名的数据挖掘软件,其前身为SPSS Clementine.SPSS Modeler内置丰富的数据挖掘模型,以其强大的挖掘功能和友好的操作习惯,深受用户的喜爱和好评, ...
- SPSS Modeler数据挖掘:回归分析
SPSS Modeler数据挖掘:回归分析 1 模型定义 回归分析法是最基本的数据分析方法,回归预测就是利用回归分析方法,根据一个或一组自变量的变动情况预测与其相关的某随机变量的未来值. 回归分析是研 ...
- 数据挖掘入门系列教程(二)之分类问题OneR算法
数据挖掘入门系列教程(二)之分类问题OneR算法 数据挖掘入门系列博客:https://www.cnblogs.com/xiaohuiduan/category/1661541.html 项目地址:G ...
- 数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例)
数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例) 简介 scikit-learn 估计器 加载数据集 进行fit训练 设置参数 预处理 流水线 结尾 数据挖掘入门系 ...
- 数据挖掘入门系列教程(四)之基于scikit-lean实现决策树
目录 数据挖掘入门系列教程(四)之基于scikit-lean决策树处理Iris 加载数据集 数据特征 训练 随机森林 调参工程师 结尾 数据挖掘入门系列教程(四)之基于scikit-lean决策树处理 ...
- 数据挖掘入门系列教程(四点五)之Apriori算法
目录 数据挖掘入门系列教程(四点五)之Apriori算法 频繁(项集)数据的评判标准 Apriori 算法流程 结尾 数据挖掘入门系列教程(四点五)之Apriori算法 Apriori(先验)算法关联 ...
- 数据挖掘入门系列教程(五)之Apriori算法Python实现
数据挖掘入门系列教程(五)之Apriori算法Python实现 加载数据集 获得训练集 频繁项的生成 生成规则 获得support 获得confidence 获得Lift 进行验证 总结 参考 数据挖 ...
随机推荐
- HTML canvas fillText()与measureText()方法
HTML5 canvas fillText() 方法 实例 使用 fillText(),在画布上写文本 "你好!word!" 和 "我是w3c": JavaSc ...
- 【UOJ】#79. 一般图最大匹配
题解 板子!我相信其实没人来看我的板子!但是为了防止我忘记,我还是要写点什么 我们考虑二分图,为什么二分图就能那么轻松地写出匹配的代码呢?因为匹配只会发生在黑点和白点之间,我们找寻增广路,必然是一黑一 ...
- 遍历datatable的几种方法
方法一: DataTable dt = dataSet.Tables[]; ; i < dt.Rows.Count ; i++) { string strName = dt.Rows[i][&q ...
- 解决centOS7的IP为127.0.0.1,无法用Xshll链接问题
对于linux不熟悉的我, 安装完centOS7后好多坑,走一步卡一步,记得之前安装其他版本没这么多事.安装完后用ifconfig查看IP,竟然是127.0.0.1,这我就不知道怎么用Xshell链接 ...
- 配置自己的ubuntu
终端 zsh 安装zsh apt install zsh 3 安装oh-my-zsh bash -c "$(wget https://raw.githubusercontent.com/ro ...
- 洛谷P4782 【模板】2-SAT问题 [2-SAT]
题目传送门 [模板]2-SAT问题 题目背景 2-SAT 问题 模板 题目描述 有n个布尔变量 $x_1/~x_n$ ,另有$m$个需要满足的条件,每个条件的形式都是“ $x_i$ 为$true/f ...
- UVA10298 Power Strings [KMP]
题目传送门 Power Strings 格式难调,题面就不放了. 一句话题意,求给定的若干字符串的最短循环节循环次数. 输入样例#1: abcd aaaa ababab . 输出样例#1: 1 4 3 ...
- 深入理解Java引用类型
深入理解Java引用类型 在Java中类型可分为两大类:值类型与引用类型.值类型就是基本数据类型(如int ,double 等),而引用类型,是指除了基本的变量类型之外的所有类型(如通过 class ...
- java getenv getProperties区别
网上很多使用的是getProperties.说获得系统变量,但是其实不正确.getProperties中所谓的"system properties"其实是指"java s ...
- 【Python】闭包Closure
原来这就是闭包啊... 还是上次面试,被问只不知掉js里面的闭包 闭包,没听过啊...什么是闭包 回来查了下,原来这货叫闭包啊...... —————————————————————————————— ...