Hadoop(五)分布式集群中HDFS系统的各种角色
NameNode
学习目标
理解 namenode 的工作机制尤其是元数据管理机制,以增强对 HDFS 工作原理的 理解,及培养 hadoop 集群运营中“性能调优”、“namenode”故障问题的分析解决能力
问题场景
1、Namenode 服务器的磁盘故障导致 namenode 宕机,如何挽救集群及数据?
2、Namenode 是否可以有多个?namenode 内存要配置多大?namenode 跟集群数据存储能 力有关系吗?
3、文件的 blocksize 究竟调大好还是调小好?结合 mapreduce
NameNode的职责
1、负责客户端请求(读写数据 请求 )的响应
2、维护目录树结构( 元数据的管理: 查询,修改 )
3、配置和应用副本存放策略
4、管理集群数据块负载均衡问题
NameNode元数据的管理
WAL(Write ahead Log): 预写日志系统
在计算机科学中,预写式日志(Write-ahead logging,缩写 WAL)是关系数据库系统中 用于提供原子性和持久性(ACID 属性中的两个)的一系列技术。在使用 WAL 的系统中,所 有的修改在提交之前都要先写入 log 文件中。
Log 文件中通常包括 redo 和 undo 信息。这样做的目的可以通过一个例子来说明。假设 一个程序在执行某些操作的过程中机器掉电了。在重新启动时,程序可能需要知道当时执行 的操作是成功了还是部分成功或者是失败了。如果使用了 WAL,程序就可以检查 log 文件, 并对突然掉电时计划执行的操作内容跟实际上执行的操作内容进行比较。在这个比较的基础 上,程序就可以决定是撤销已做的操作还是继续完成已做的操作,或者是保持原样。
WAL 允许用 in-place 方式更新数据库。另一种用来实现原子更新的方法是 shadow paging, 它并不是 in-place 方式。用 in-place 方式做更新的主要优点是减少索引和块列表的修改。ARIES 是 WAL 系列技术常用的算法。在文件系统中,WAL 通常称为 journaling。PostgreSQL 也是用 WAL 来提供 point-in-time 恢复和数据库复制特性。
NameNode 对数据的管理采用了两种存储形式:内存和磁盘
首先是内存中存储了一份完整的元数据,包括目录树结构,以及文件和数据块和副本存储地 的映射关系;
1、内存元数据 metadata(全部存在内存中),其次是在磁盘中也存储了一份完整的元数据。
2、磁盘元数据镜像文件 fsimage_0000000000000000555
fsimage_0000000000000000555 等价于
edits_0000000000000000001-0000000000000000018
……
edits_0000000000000000444-0000000000000000555
合并之和
3、数据历史操作日志文件 edits:edits_0000000000000000001-0000000000000000018 (可通过日志运算出元数据,全部存在磁盘中)
4、数据预写操作日志文件 edits_inprogress_0000000000000000556 (存储在磁盘中)
metadata = 最新 fsimage_0000000000000000555 + edits_inprogress_0000000000000000556
metadata = 所有的 edits 之和(edits_001_002 + …… + edits_444_555 + edits_inprogress_556)
VERSION(存放 hdfs 集群的版本信息)文件解析:
#Sun Jan 06 20:12:30 CST 2017 ## 集群启动时间
namespaceID=844434736 ## 文件系统唯一标识符
clusterID=CID-5b7b7321-e43f-456e-bf41-18e77c5e5a40 ## 集群唯一标识符
cTime=0 ## fsimage 创建的时间,初始为 0,随 layoutVersion 更新
storageType=NAME_NODE ##节点类型
blockpoolID=BP-265332847-192.168.123.202-1483581570658 ## 数据块池 ID,可以有多个
layoutVersion=-60 ## hdfs 持久化数据结构的版本号
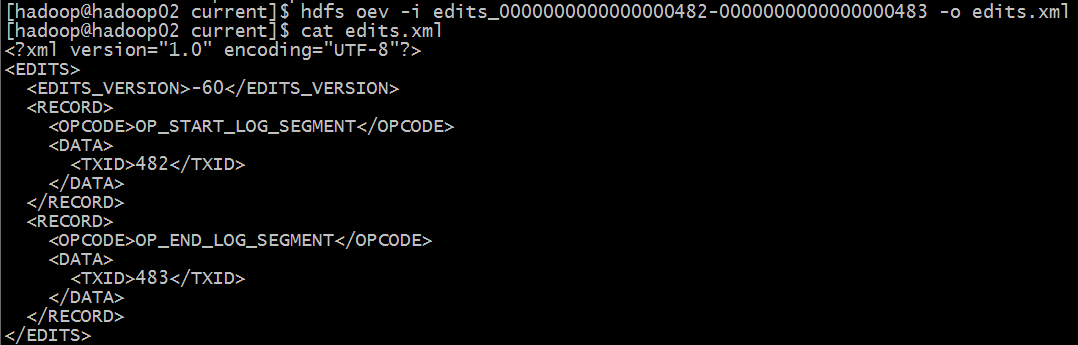
查看 edits 文件信息:
hdfs oev -i edits_0000000000000000482-0000000000000000483 -o edits.xml
cat edits.xml
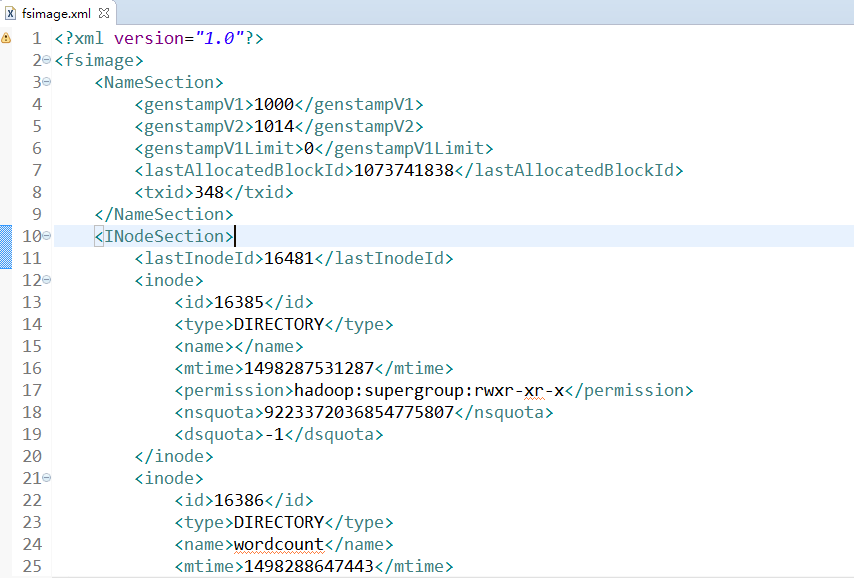
查看 fsimage 镜像文件信息:
hdfs oiv -i fsimage_0000000000000000348 -p XML -o fsimage.xml
cat fsimage.xml
NameNode 元数据存储机制
A、内存中有一份完整的元数据(内存 metadata)
B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在 namenode 的工作目录中)
C、用于衔接内存 metadata 和持久化元数据镜像 fsimage 之间的操作日志(edits 文件)
(PS:当客户端对 hdfs 中的文件进行新增或者修改操作,操作记录首先被记入 edits 日志 文件中,当客户端操作成功后,相应的元数据会更新到内存 metadata 中)
DataNode
问题场景
1、集群容量不够,怎么扩容?
2、如果有一些 datanode 宕机,该怎么办?
3、datanode 明明已启动,但是集群中的可用 datanode 列表中就是没有,怎么办?
Datanode 工作职责
1、存储管理用户的文件块数据
2、定期向 namenode 汇报自身所持有的 block 信息(通过心跳信息上报)
(PS:这点很重要,因为,当集群中发生某些 block 副本失效时,集群如何恢复 block 初始 副本数量的问题)
<property>
<!—HDFS 集群数据冗余块的自动删除时长,单位 ms,默认一个小时 -->
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
Datanode 掉线判断时限参数
datanode 进程死亡或者网络故障造成 datanode 无法与 namenode 通信,namenode 不会立即 把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS 默认的超时时长 为 10 分钟+30 秒。如果定义超时时间为 timeout,则超时时长的计算公式为: t
imeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
而默认的 heartbeat.recheck.interval 大小为 5 分钟,dfs.heartbeat.interval 默认为 3 秒。 需要注意的是 hdfs-site.xml 配置文件中的 heartbeat.recheck.interval 的单位为毫秒, dfs.heartbeat.interval 的单位为秒。 所以,举个例子,如果 heartbeat.recheck.interval 设置为 5000(毫秒),dfs.heartbeat.interval 设置为 3(秒,默认),则总的超时时间为 40 秒。
<property>
<name>heartbeat.recheck.interval</name>
<value>5000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
SecondaryNameNode
SecondaryNamenode 工作机制
SecondaryNamenode 的作用就是分担 namenode 的合并元数据的压力。所以在配置 SecondaryNamenode 的工作节点时,一定切记,不要和 namenode 处于同一节点。但事实上, 只有在普通的伪分布式集群和分布式集群中才有会 SecondaryNamenode 这个角色,在 HA 或 者联邦集群中都不再出现该角色。在 HA 和联邦集群中,都是有 standby namenode 承担。
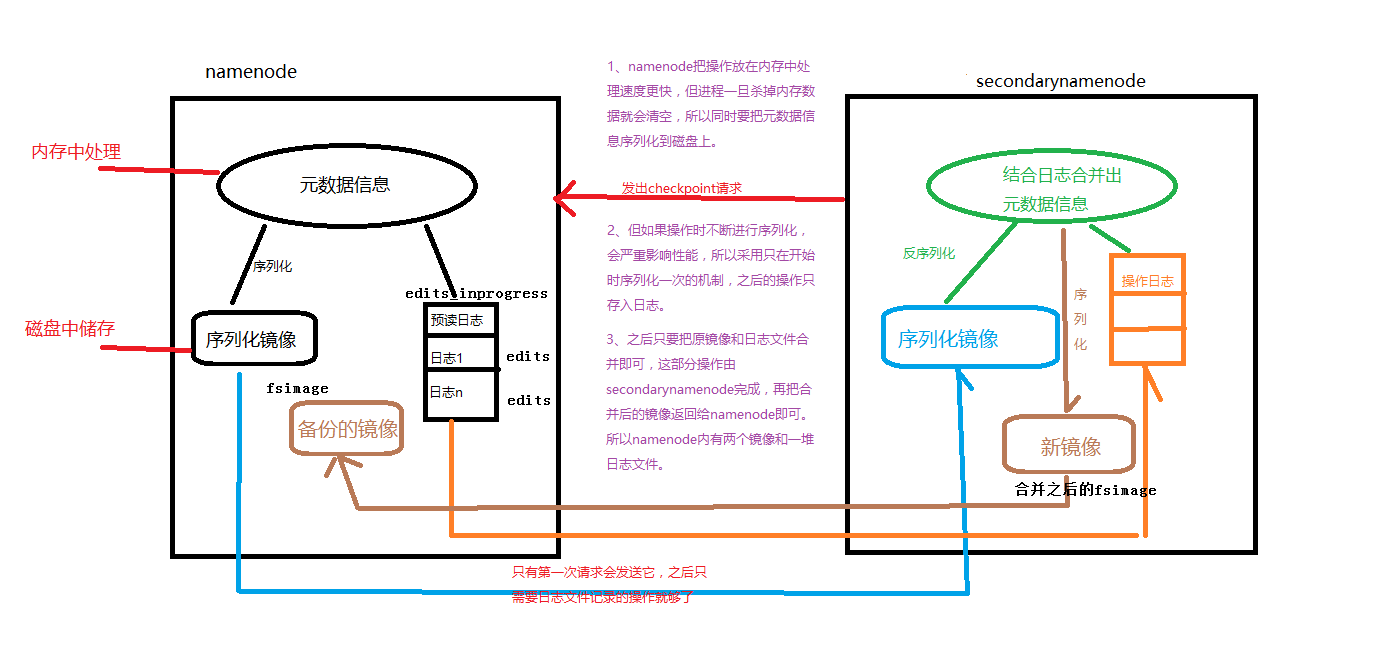
元数据的 CheckPoint
每隔一段时间,会由 secondary namenode 将 namenode 上积累的所有 edits 和一个最新的 fsimage 下载到本地,并加载到内存进行 merge(这个过程称为 checkpoint) CheckPoint 详细过程图解:
CheckPoint 触发配置
dfs.namenode.checkpoint.check.period=60 ##检查触发条件是否满足的频率,60 秒
dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary
##以上两个参数做 checkpoint 操作时,secondary namenode 的本地工作目录
dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir}
dfs.namenode.checkpoint.max-retries=3 ##最大重试次数
dfs.namenode.checkpoint.period=3600 ##两次 checkpoint 之间的时间间隔 3600 秒
dfs.namenode.checkpoint.txns=1000000 ##两次 checkpoint 之间最大的操作记录
CheckPoint 附带作用
Namenode 和 SecondaryNamenode 的工作目录存储结构完全相同,所以,当 Namenode 故障 退出需要重新恢复时,可以从SecondaryNamenode的工作目录中将fsimage拷贝到Namenode 的工作目录,以恢复 namenode 的元数据
Hadoop(五)分布式集群中HDFS系统的各种角色的更多相关文章
- Hadoop学习之路(十二)分布式集群中HDFS系统的各种角色
NameNode 学习目标 理解 namenode 的工作机制尤其是元数据管理机制,以增强对 HDFS 工作原理的 理解,及培养 hadoop 集群运营中“性能调优”.“namenode”故障问题的分 ...
- hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接 1.集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点 2.解压tar.gz包 [root@node01 ~]# ...
- Hadoop学习笔记—13.分布式集群中节点的动态添加与下架
开篇:在本笔记系列的第一篇中,我们介绍了如何搭建伪分布与分布模式的Hadoop集群.现在,我们来了解一下在一个Hadoop分布式集群中,如何动态(不关机且正在运行的情况下)地添加一个Hadoop节点与 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- 『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现
『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现 1.基本设定和软件版本 主机名 ip 对应角色 mas ...
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop(三)搭建Hadoop全分布式集群
原文地址:http://www.cnblogs.com/zhangyinhua/p/7652686.html 阅读目录(Content) 一.搭建Hadoop全分布式集群前提 1.1.网络 1.2.安 ...
- 基于Hadoop伪分布式集群搭建Spark
一.前置安装 1)JDK 2)Hadoop伪分布式集群 二.Scala安装 1)解压Scala安装包 2)环境变量 SCALA_HOME = C:\ProgramData\scala-2.10.6 P ...
随机推荐
- Emgu.CV.CvInvoke”的类型初始值设定项引发异常
http://zhidao.baidu.com/link?url=VHkw3qZxp7HumQX_r-4ljPiy-N4A7yNK1Xn5q6tjPb16WvBGy6RFKrmKEhtgJ2PACAk ...
- 使用Java解析XML文件或XML字符串的例子
转: 使用Java解析XML文件或XML字符串的例子 2017年09月16日 11:36:18 inter_peng 阅读数:4561 标签: JavaXML-Parserdom4j 更多 个人分类: ...
- selenium - webdriver - 定位一组元素
八种方法: find_elements_by_id() find_elements_by_name() find_elements_by_class_name() find_elements_by_t ...
- 洛谷P1199 三国游戏
题目描述 小涵很喜欢电脑游戏,这些天他正在玩一个叫做<三国>的游戏. 在游戏中,小涵和计算机各执一方,组建各自的军队进行对战.游戏中共有 N 位武将(N为偶数且不小于 4),任意两个武将之 ...
- Messenger 进程间通信
Messenger 使用 Messenger 可以在进程间传递数据, 实现一对多的处理. 其内部实现, 也是基于 aidl 文件, 这个aidl位于: frameworks/base/core/jav ...
- 题解 P2762 【太空飞行计划问题】
P2762 太空飞行计划问题 题目描述 W 教授正在为国家航天中心计划一系列的太空飞行.每次太空飞行可进行一系列商业性实验而获取利润.现已确定了一个可供选择的实验集合E={E1,E2,-,Em},和进 ...
- CSS3实现文本垂直排列
最近的一个项目中要使文字垂直排列,也就是运用了CSS的writing-mode属性. writing-mode最初时ie中支持的一个属性,后来在CSS3中增添了这一新的属性,所以在ie中和其他浏览器中 ...
- javascript 实现 A-star 寻路算法
在游戏开发中,又一个很常见的需求,就是让一角色从A点走到B点,而我们期望所走的路是最短的,最容易想到的就是两点之间直线最短,我们可以通过勾股定理来求出两点之间的距离,但这个情况只能用于两点之间没有障碍 ...
- LeetCode-Max Points on a Line[AC源码]
package com.lw.leet3; import java.util.HashMap; import java.util.Iterator; import java.util.Map; imp ...
- Order By 问题集合
问题(一):Order By 多个参数排序 在做多字段的排序的时候我们经常会会用到该语句. 所以多参数排序是从左到右的局部排序,修改的范围只有前面参数(几个参数)相同的情况下在排序. select * ...