Softmax vs. Softmax-Loss VS cross-entropy损失函数 Numerical Stability(转载)
http://freemind.pluskid.org/machine-learning/softmax-vs-softmax-loss-numerical-stability/
卷积神经网络系列之softmax,softmax loss和cross entropy的讲解
我们知道卷积神经网络(CNN)在图像领域的应用已经非常广泛了,一般一个CNN网络主要包含卷积层,池化层(pooling),全连接层,损失层等。虽然现在已经开源了很多深度学习框架(比如MxNet,Caffe等),训练一个模型变得非常简单,但是你对这些层具体是怎么实现的了解吗?你对softmax,softmax loss,cross entropy了解吗?相信很多人不一定清楚。虽然网上的资料很多,但是质量参差不齐,常常看得眼花缭乱。为了让大家少走弯路,特地整理了下这些知识点的来龙去脉,希望不仅帮助自己巩固知识,也能帮到他人理解这些内容。
这一篇主要介绍全连接层和损失层的内容,算是网络里面比较基础的一块内容。先理清下从全连接层到损失层之间的计算。来看下面这张图,来自参考资料1(自己实在懒得画图了)。
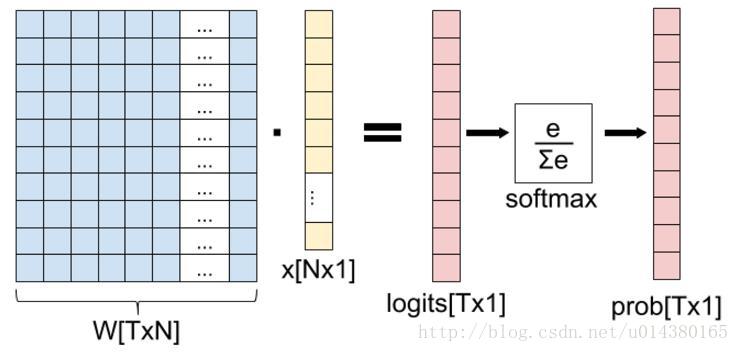
这张图的等号左边部分就是全连接层做的事,W是全连接层的参数,我们也称为权值,X是全连接层的输入,也就是特征。从图上可以看出特征X是N*1的向量,这是怎么得到的呢?这个特征就是由全连接层前面多个卷积层和池化层处理后得到的,假设全连接层前面连接的是一个卷积层,这个卷积层的输出是100个特征(也就是我们常说的feature map的channel为100),每个特征的大小是4*4,那么在将这些特征输入给全连接层之前会将这些特征flat成N*1的向量(这个时候N就是100*4*4=1600)。解释完X,再来看W,W是全连接层的参数,是个T*N的矩阵,这个N和X的N对应,T表示类别数,比如你是7分类,那么T就是7。我们所说的训练一个网络,对于全连接层而言就是寻找最合适的W矩阵。因此全连接层就是执行WX得到一个T*1的向量(也就是图中的logits[T*1]),这个向量里面的每个数都没有大小限制的,也就是从负无穷大到正无穷大。然后如果你是多分类问题,一般会在全连接层后面接一个softmax层,这个softmax的输入是T*1的向量,输出也是T*1的向量(也就是图中的prob[T*1],这个向量的每个值表示这个样本属于每个类的概率),只不过输出的向量的每个值的大小范围为0到1。
现在你知道softmax的输出向量是什么意思了,就是概率,该样本属于各个类的概率!
那么softmax执行了什么操作可以得到0到1的概率呢?先来看看softmax的公式(以前自己看这些内容时候对公式也很反感,不过静下心来看就好了):
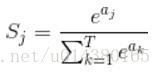
公式非常简单,前面说过softmax的输入是WX,假设模型的输入样本是I,讨论一个3分类问题(类别用1,2,3表示),样本I的真实类别是2,那么这个样本I经过网络所有层到达softmax层之前就得到了WX,也就是说WX是一个3*1的向量,那么上面公式中的aj就表示这个3*1的向量中的第j个值(最后会得到S1,S2,S3);而分母中的ak则表示3*1的向量中的3个值,所以会有个求和符号(这里求和是k从1到T,T和上面图中的T是对应相等的,也就是类别数的意思,j的范围也是1到T)。因为e^x恒大于0,所以分子永远是正数,分母又是多个正数的和,所以分母也肯定是正数,因此Sj是正数,而且范围是(0,1)。如果现在不是在训练模型,而是在测试模型,那么当一个样本经过softmax层并输出一个T*1的向量时,就会取这个向量中值最大的那个数的index作为这个样本的预测标签。
因此我们训练全连接层的W的目标就是使得其输出的WX在经过softmax层计算后其对应于真实标签的预测概率要最高。
举个例子:假设你的WX=[1,2,3],那么经过softmax层后就会得到[0.09,0.24,0.67],这三个数字表示这个样本属于第1,2,3类的概率分别是0.09,0.24,0.67。
弄懂了softmax,就要来说说softmax loss了。
那softmax loss是什么意思呢?如下:
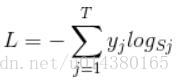
首先L是损失。Sj是softmax的输出向量S的第j个值,前面已经介绍过了,表示的是这个样本属于第j个类别的概率。yj前面有个求和符号,j的范围也是1到类别数T,因此y是一个1*T的向量,里面的T个值,而且只有1个值是1,其他T-1个值都是0。那么哪个位置的值是1呢?答案是真实标签对应的位置的那个值是1,其他都是0。所以这个公式其实有一个更简单的形式:
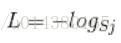
当然此时要限定j是指向当前样本的真实标签。
来举个例子吧。假设一个5分类问题,然后一个样本I的标签y=[0,0,0,1,0],也就是说样本I的真实标签是4,假设模型预测的结果概率(softmax的输出)p=[0.1,0.15,0.05,0.6,0.1],可以看出这个预测是对的,那么对应的损失L=-log(0.6),也就是当这个样本经过这样的网络参数产生这样的预测p时,它的损失是-log(0.6)。那么假设p=[0.15,0.2,0.4,0.1,0.15],这个预测结果就很离谱了,因为真实标签是4,而你觉得这个样本是4的概率只有0.1(远不如其他概率高,如果是在测试阶段,那么模型就会预测该样本属于类别3),对应损失L=-log(0.1)。那么假设p=[0.05,0.15,0.4,0.3,0.1],这个预测结果虽然也错了,但是没有前面那个那么离谱,对应的损失L=-log(0.3)。我们知道log函数在输入小于1的时候是个负数,而且log函数是递增函数,所以-log(0.6) < -log(0.3) < -log(0.1)。简单讲就是你预测错比预测对的损失要大,预测错得离谱比预测错得轻微的损失要大。
———————————–华丽的分割线———————————–
理清了softmax loss,就可以来看看cross entropy了。
corss entropy是交叉熵的意思,它的公式如下:
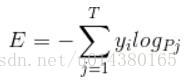
是不是觉得和softmax loss的公式很像。当cross entropy的输入P是softmax的输出时,cross entropy等于softmax loss。Pj是输入的概率向量P的第j个值,所以如果你的概率是通过softmax公式得到的,那么cross entropy就是softmax loss。这是我自己的理解,如果有误请纠正。
深度学习基础理论探索(二): cross-entropy损失函数的前世今生
https://blog.csdn.net/qq_25552539/article/details/78255217
前面我们讲到,克服梯度消失有两个方向,1.用rule激活函数。2.改进损失函数用cross_entropy。
ok,首先我们先看为什么代价损失函数可以用Cross_entropy.
以前使用的二次代价函数很好理解:

即:计算值与真实值的残差。
它有两个特点:
1.损失函数永远大于0.
2.计算值与真实值越接近,损失函数越小。两者差距越大,损失函数越大。
我们现在假设这是损失函数的基本要求。
那cross-entropy损失函数满足这些要求吗?

首先,可以证明该函数是大于0的
其次,当y=0时(即真实值为0)若a=0(计算值为0),c = 0*ln0 + 1*ln1 等于0(前项等于0,后项也等于0)。
当y=1时,若a=0, c = ln0 + 0*ln1等于无穷大。
即:计算值与真实值差距越大,损失函数越大。反之亦然。
所以cross-entropy满足我们对损失函数的定义。所以他是个合格的损失函数
这里我们其实会发现 当y=0,a=1这样的极端情况出现时,损失函数无穷大。程序会出问题,我们可以对cross-entropy做一个修改:y*ln((a+0.05)/1.05))+(1-y)*ln((1.05-a)/1.05)
ok,下一个话题。为什么cross-entroy可以抑制梯度消失。
根据上个话题我们知道了激活函数为sigmoid、损失 函数为二次代价函数时,w、b的跟新速度与激活函数的导数相关。
那么损失函数换成cross-entropy会怎样呢
再来一波公式:

由以上推导可得w、b对损失函数的偏导,即w、b的更新速度只与(a-y)有关,也就是只与预测值与真实值的差距有关。不同于二次代价函数的更新速度和激活函数的导数成正比(上篇提到)。
这样就会有一个比较好的性质:
计算值与实际值差距越大,w、b的更新速度越快
具体推导过程,可参见
http://neuralnetworksanddeeplearning.com/chap3.html
为何要选泽交叉熵函数
https://blog.csdn.net/lanchunhui/article/details/50970625
1. 交叉熵理论
交叉熵与熵相对,如同协方差与方差。
熵考察的是单个的信息(分布)的期望:
交叉熵考察的是两个的信息(分布)的期望:
详见 wiki Cross entropy
y = tf.placeholder(dtype=tf.float32, shape=[None, 10])
.....
scores = tf.matmul(h, w) + b
probs = tf.nn.softmax(scores)
loss = -tf.reduce_sum(y*tf.log(probs))- 1
- 2
- 3
- 4
- 5
- 6
- 7
2. 交叉熵代价函数
xx 表示原始信号,zz 表示重构信号,以向量形式表示长度均为 dd,又可轻易地将其改造为向量内积的形式。
3. 交叉熵与 KL 散度(也叫相对熵)
- Intuitively, why is cross entropy a measure of distance of two probability distributions?
- 熵、交叉熵、相对熵(KL 散度)意义及其关系
- 机器学习基础(五十八)—— 香农熵、相对熵(KL散度)与交叉熵
所谓相对,自然在两个随机变量之间。又称互熵,Kullback–Leibler divergence(K-L 散度)等。设 p(x) 和 q(x) 是 X 取值的两个概率分布,则 p 对 q 的相对熵为:
(在稀疏型自编码器损失函数的定义中,基于 KL 散度的惩罚项常常定义成如下的形式:
其中:ρ^=1k∑i=1khiρ^=1k∑i=1khi(遍历的是层内的所有输出,∑mj=1∑j=1m 则是遍历所有的层))
4. 神经网络中的交叉熵代价函数
为神经网络引入交叉熵代价函数,是为了弥补 sigmoid 型函数的导数形式易发生饱和(saturate,梯度更新的较慢)的缺陷。
首先来看平方误差函数(squared-loss function),对于一个神经元(单输入单输出),定义其代价函数:
其中 a=σ(z),z=wx+ba=σ(z),z=wx+b,然后根据对权值(ww)和偏置(bb)的偏导(为说明问题的需要,不妨将 x=1,y=0x=1,y=0):
根据偏导计算权值和偏置的更新:
无论如何简化,sigmoid 型函数的导数形式 σ′(z)σ′(z) 始终阴魂不散,上文说了 σ′(z)σ′(z) 较容易达到饱和,这会严重降低参数更新的效率。
为了解决参数更新效率下降这一问题,我们使用交叉熵代价函数替换传统的平方误差函数。
对于多输入单输出的神经元结构而言,如下图所示:
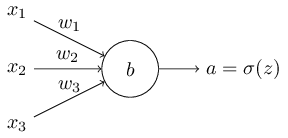
我们将其损失函数定义为:
其中 a=σ(z),z=∑jwjxj+ba=σ(z),z=∑jwjxj+b
最终求导得:
就避免了 σ′(z)σ′(z) 参与参数更新、影响更新效率的问题;


Softmax vs. Softmax-Loss VS cross-entropy损失函数 Numerical Stability(转载)的更多相关文章
- 卷积神经网络系列之softmax,softmax loss和cross entropy的讲解
我们知道卷积神经网络(CNN)在图像领域的应用已经非常广泛了,一般一个CNN网络主要包含卷积层,池化层(pooling),全连接层,损失层等.虽然现在已经开源了很多深度学习框架(比如MxNet,Caf ...
- softmax,softmax loss和cross entropy的区别
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u014380165/article/details/77284921 我们知道卷积神经网络(CNN ...
- softmax,softmax loss和cross entropy的讲解
1 softmax 我们知道卷积神经网络(CNN)在图像领域的应用已经非常广泛了,一般一个CNN网络主要包含卷积层,池化层(pooling),全连接层,损失层等.这一篇主要介绍全连接层和损失层的内容, ...
- softmax分类器+cross entropy损失函数的求导
softmax是logisitic regression在多酚类问题上的推广,\(W=[w_1,w_2,...,w_c]\)为各个类的权重因子,\(b\)为各类的门槛值.不要想象成超平面,否则很难理解 ...
- 【机器学习基础】交叉熵(cross entropy)损失函数是凸函数吗?
之所以会有这个问题,是因为在学习 logistic regression 时,<统计机器学习>一书说它的负对数似然函数是凸函数,而 logistic regression 的负对数似然函数 ...
- softmax、cross entropy和softmax loss学习笔记
之前做手写数字识别时,接触到softmax网络,知道其是全连接层,但没有搞清楚它的实现方式,今天学习Alexnet网络,又接触到了softmax,果断仔细研究研究,有了softmax,损失函数自然不可 ...
- 关于交叉熵损失函数Cross Entropy Loss
1.说在前面 最近在学习object detection的论文,又遇到交叉熵.高斯混合模型等之类的知识,发现自己没有搞明白这些概念,也从来没有认真总结归纳过,所以觉得自己应该沉下心,对以前的知识做一个 ...
- 一篇博客:分类模型的 Loss 为什么使用 cross entropy 而不是 classification error 或 squared error
https://zhuanlan.zhihu.com/p/26268559 分类问题的目标变量是离散的,而回归是连续的数值. 分类问题,都用 onehot + cross entropy traini ...
- 【转】TensorFlow四种Cross Entropy算法实现和应用
http://www.jianshu.com/p/75f7e60dae95 作者:陈迪豪 来源:CSDNhttp://dataunion.org/26447.html 交叉熵介绍 交叉熵(Cross ...
随机推荐
- Spring+Shiro搭建基于Redis的分布式权限系统(有实例)
摘要: 简单介绍使用Spring+Shiro搭建基于Redis的分布式权限系统. 这篇主要介绍Shiro如何与redis结合搭建分布式权限系统,至于如何使用和配置Shiro就不多说了.完整实例下载地址 ...
- OpenERP函數字段的應用
在ERP開發過程中經常會使用到某字段的值是由其他字段計算得來,並且有些還需要將計算的結果存入資料庫. 以上功能上OpenERP中是用field.function實現的 其中有種模式 a). 只計算,不 ...
- 深入理解javascript闭包【整理】
原文链接:http://www.cn-cuckoo.com/2007/08/01/understand-javascript-closures-72.html 英文原文:http://www.jibb ...
- windows 设置定时锁屏
设置间隔指定时间电脑自动锁屏 CreateTime--2017年7月3日10:16:14Author:Marydon 参考地址:电脑爱好者杂志 举例:实现每间隔45分钟,电脑自动锁屏 实现思路: ...
- 【微信公众号】微信关于网页授权access_token和普通access_token的区别及两种不同方式授权
微信官网网址:https://mp.weixin.qq.com/wiki/17/c0f37d5704f0b64713d5d2c37b468d75.html#.E9.99.84.EF.BC.9A.E6. ...
- 转载【linux】Linux学习之CentOS6.x+7.x---网卡的配置
转载至:http://www.cnblogs.com/smyhvae/p/3932903.html [正文] Linux系统版本:Centos 6.5 Linux系统版本:Centos 7 目的:将c ...
- Motion Detection Algorithms视频中运动检测算法源代码及演示代码
原文地址:http://www.codesoso.com/code/Motion_Detection.aspx 本文实现了在连续视频数据流中几种不同的运动检测算法,他们都是基于当前帧图像和前一帧图像的 ...
- JAVA中的字节流与字符流
字节流与字符流的区别? 字节流与和字符流的使用非常相似,两者除了操作代码上的不同之外,是否还有其他的不同呢? 实际上字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流在操作时使用 ...
- springboot 整合 rabbitmq
http://blog.720ui.com/2017/springboot_06_mq_rabbitmq/
- informix遇到错误 25571:Cannot create an user thread
今天发现informix数据库不能用dbaccess访问,报错: 25571: Cannot create an user thread. On NT check username, and IX ...