学习Redis(二)
1、Redis应用场景
- 1、缓存(键过期时间)
- 1) 缓存session会话
- 2) 缓存用户信息,找不到再去mysql查,查到然后回写到redis
- 3) 商城优惠卷过期时间
- 2、排行榜(列表&有序集合)
- 1) 热度排名排行榜
- 2) 发布时间排行榜
- 3、计数器(自增)
- 1) 帖子浏览数
- 2) 视频播放次数
- 3) 商品浏览数
- 4、社交网络(集合)
- 1) 踩/赞,粉丝,共同好友/喜好,推送,打标签
- 5、消息队列系统-发布订阅
- 1) 配合elk实现日志收集
2、Redis安装部署
- 1、安装
- # mkdir -p /server/tools
- # mkdir -p /opt/redis/redis_6379/{conf,logs,pid}
- # tar xf redis-3.2.9.tar.gz -C /opt/
- # ln -s redis-3.2.9 redis
- # make && make install #make install 生成二进制文件,并放到/usr/local/bin
- # ./utils/install_server.sh #生成配置、log、数据文件,启动脚本
- 2、配置文件
- # vim redis.conf
- daemonize yes
- bind 10.0.0.51 127.0.0.1
- port 6379
- logfile /data/redis_6379/redis.log
- pidfile /var/run/redis6379.pid
- databases 16
- dir /data/redis_6379
- dbfilename redis_6379.rdb
- 3、启动和关闭
- # redis-server 6379.conf #启动
- # redis-cli shutdown #关闭
3、Redis安全配置
- 1、设置密码
- # vim redis.conf
- protected-mode yes #开启保护模式
- bind 10.0.0.51 127.0.0.1 #绑定绑定ip
- requirepass 123456 #设置登录密码
- 6379> CONFIG SET requirepass 123 #在线修改
- # redis-cli -a 123456 #密码登录
- # redis-cli
- 6379> auth 123456
- 2、禁用危险命令
- 1) 禁用命令
- rename-command KEYS ""
- rename-command FLUSHALL ""
- rename-command FLUSHDB ""
- rename-command CONFIG ""
- 2) 危险命令重命名
- rename-command KEYS "aaaa"
- rename-command FLUSHALL "bbbb"
- rename-command FLUSHDB "cccc"
- rename-command CONFIG "dddd"
4、全局命令
- 6379> KEYS * #查看所有key(禁用)
- 6379> DBSIZE #查看有多少个key(大约)
- 6379> EXISTS key #查看KEY是否存在(0:不存在,1:存在)
- 6379> DEL key #删除key(0:不存在,1:存在并删除)
- 6379> EXPIRE key 10 #设置key的过期时间(0:不存在,1:存在并设置,单位是秒)
- 6379> PERSIST key #取消key的过期时间(0:不存在,1:存在并取消)
- 6379> TTL key #查看key是否过期,过期后的key会删除(-1:存在,-2:不存在)
- 6379> TYPE key #查看key的类型
- 6379> RENAME key key01 #更改key的名
- 6379> BGSAVE #缓存的数据保存到磁盘
5、string(字符串)
- 6379> SET k1 v1 #设置一个key
- 6379> GET k1 #查看一个key
- 6379> MSET k1 v1 k2 v2 #设置多个key
- 6379> MGET k1 k2 #查看多个key
- 6379> set k1 1 #设置一个key
- 6379> INCR k1 #自增1
- 6379> DECR k1 #自减1
- 6379> INCRBY k1 100 #自增100
- 6379> INCRBY k1 -100 #自减100
- 6379> DECRBY k1 100 #自减100
6、list(列表)
- 6379> LPUSH list1 A #从列表左(头部)插入数据
- 6379> RPUSH list1 B #从列表右(尾部)插入数据
- 6379> LLEN list1 #查看列表的长度
- 6379> LRANGE list1 0 -1 #查看列表的内容
- 6379> LPOP list1 #从列表左(头部)删除
- 6379> RPOP list1 #从列表右(尾部)删除
- 6379> DEL list1 #删除列表
7、hash(哈希)
- 1、mysql数据和redis哈希对比
- 1)mysql数据(user表)
- uid name age job
- 1 tom 28 it
- 2)mysql查询数据:
- select * from user where id=3
- 3)redis缓存mysql数据
- key名 key1 key1值 key2 key2值 key3 key3值
- uid:1 name tom age 28 job it
- 2、设置和查看哈希值
- 6379> HSET uid:1 name tom #设置一个哈希值
- 6379> HMSET uid:1 name tom age 28 job it #设置多个哈希值
- 6379> HGET uid:1 name #查看一个哈希值
- 6379> HMGET uid:1 name age job #查看多个哈希值
- 6379> HGETALL uid:1 #查看所有哈希值
8、set(集合)
- 1、无序集合
- 6379> SADD set1 1 2 3 #创建集合1(不允许重复的值)
- 6379> SADD set2 1 3 5 7 #创建集合2(有去重功能)
- 6379> SMEMBERS set1 #查看集合
- 6379> SREM set1 2 #删除指定的值
- 6379> SDIFF set1 set2 #查看集合的差集(set1减去set2,答案是2)
- 6379> SDIFF set2 set1 #查看集合的差集(以set2为基准对比,set2减set1)
- 6379> SINTER set1 set2 #查看集合的交集(set1和set2共同的值)
- 6379> SUNION set1 set2 #查看集合的并集(set1加set2,去重的值)
- 2、有序集合
- 6379> ZADD mysql 100 zhang3 #创建集合mysql(zhang3分数100)
- 6379> ZADD mysql 90 li4 50 wang5 10 zhao6 #添加集合
- 6379> ZCARD mysql #查看集合个数
- 6379> ZSCORE mysql zhang3 #查看zhang3的分数
- 6379> ZRANK mysql zhang3 #降序(从大到小,3:下面有3个人)
- 6379> ZREVRANK mysql li4 #升序(从小到大,1:上面有1个人)
- 6379> ZINCRBY mysql 5 li4 #加5个分数
- 6379> ZINCRBY mysql -5 li4 #减5个分数
- 6379> ZRANGE mysql 0 -1 withscores #升序(从小到大,取所有的值)
- 6379> ZRANGE mysql 0 2 withscores #升序(从小到大,取0到2的值)
- 6379> ZREVRANGE mysql 0 -1 withscores #降序(从大到小,取所有的值)
- 6379> ZRANGEBYSCORE mysql 50 100 withscores #查看指定分数的人
- 6379> ZCOUNT mysql 50 100 #统计指定分数的个数
- 6379> ZREN mysq li4 #删除li4及分数
9、Redis持久化
- 1、RDB和AOF介绍
- 1) RDB持久化
- 介绍: 在指定的时间内生成快照,并把内存的数据写到磁盘上,
- 优点: 恢复速度快,适合用于做备份,主从复制基于RDB持久化功能实现
- 缺点: 可能会丢失数据
- 2) AOF持久化
- 介绍: 类似于MySQL的binlog,记录所有写的操作,每次操作或1秒写一次,服务启动时,会重新执行命令还原数据
- 优点: 安全,有可能会丢失1秒数据
- 缺点: 文件比较大,恢复速度慢
- 2、配置RDB
- # vim redis.conf
- save 900 1 #900秒1个改变
- save 300 10 #300秒10个改变
- save 60 10000 #60秒1万个改变
- dir /data/redis_6379/
- dbfilename redis_6379.rdb
- 3、配置AOF
- # vim redis.conf
- appendonly yes #是否打开aof日志功能
- appendfsync always #每1个命令,都立即同步到aof
- appendfsync everysec #每秒写1次
- appendfsync no #写入交给系统,由系统判断缓冲区大小,统一写入到aof
- appendfilename "appendonly.aof"
- 4、redis持久化方式有哪些?有什么区别?
- rdb: 基于快照的持久化,速度快,一般用作备份,主从复制依赖于rdb持久化功能
- aof: 类似于MySQL的binlog,记录redis所有写的操作,安全性高
- 5、总结
- 1) 配置持久化参数,正常关闭(shutdown)时,会先执行bgsave,后在执行shutdown
- 2) pkill、kill、killall等,类似于shutdown命令,会触发持久化(bgsave命令)
- 3) 执行kill -9,redis不会触发持久化
- 4) rdb和aof同时存在,redis会优先读取aof文件
10、Redis主从复制
- 1、配置主从
- 方法1: 临时生效
- # redis-cli -h 10.0.0.52
- 6379> SLAVEOF 10.0.0.51 6379
- # redis-cli SLAVEOF 10.0.0.51 6379
- 方法2: 永久生效
- # vim 6379.conf
- masterauth 123456 #主库密码
- SLAVEOF 10.0.0.51 6379
- 方法3: 永久生效
- # redis-server redis.conf SLAVEOF 10.0.0.51 6379
- 2、解除主从
- 6379> SLAVEOF no one
- # redis-cli SLAVEOF no one
- 3、主从复制流程
- 1) 从库通过slaveof命令,连接主库,并发送同步请求SYNC给主库
- 2) 主库收到SYNC后,触发bgsave,后台保存RDB,并把rdb文件发送给从库
- 3) 从库收到rdb文件后,清空自己的数据,载入收到的rdb文件到的内存,并生成自己的rdb文件
- 4、总结
- 1、执行主从复制之前,先备份数据,从库会清空原有数据
- 2、在业务低峰期做主从复制,主从同步会占用网络带宽
- 3、配置主从复制后,从库只读不能写
- 4、从库不会自动故障转移,会一直同步主库
- 5、vim应用
- 1) f+要定位的数字(英文)
- 2) Ctrl + a 加1, 3 + Ctrl + a 加3
- 3) Ctrl + x 减1, 3 + Ctrl + x 减3
- 4) 命令模式下,:! 可执行liunx命令
11、Redis哨兵
- 1、介绍
- 1) redis-sentinel是Redis自带的命令
- 2) sentinel不断监控主库和从库状态(监控)
- 3) 当redis服务器有问题,可通过API向应用程序发送通知(提醒)
- 4) 当主库有问题,会自动故障迁移到从库上,并通知程序新主库的地址
- 5) 基于Redis的主从复制结构
- 2、安装部署redis-sentinel
- 1) 提前部署Redis的1主2从(3个节点)
- 2) 创建配置文件(3个节点)
- # vim 26379.conf
- bind 10.0.0.51 #绑定ip(3个节点不同)
- port 26379
- daemonize yes
- logfile /opt/redis/redis_26379/logs/redis_26379.log
- dir /opt/redis/redis_26379/data/
- sentinel monitor mymaster 10.0.0.51 6379 2 #监控mymaster(自定义组名)主库ip,1个节点必须2票,才切换主
- sentinel down-after-milliseconds mymaster 3000 #主库宕机3秒,进行切库(单位是毫秒)
- sentinel parallel-syncs mymaster 1 #向新主库发起主从复制的个数,1 轮询发起复制
- sentinel failover-timeout mymaster 18000 #故障转移的超时时间
- 3) 启动哨兵
- # redis-sentinel redis_26379.conf
- 3、Redis哨兵+主从+密码
- 2) 配置主
- # vim redis_6379.conf
- requirepass "123456" #本身密码
- 2) 配置从
- # vim redis_6379.conf
- masterauth "123456" #主库密码
- 3) 配置哨兵
- # vim 26379.conf
- sentinel auth-pass mymaster 123456 #主库密码
- 4、哨兵常用命令
- 26379> Info Sentinel #哨兵主库和从库信息
- 26379> Sentinel masters #所有主库信息
- 26379> Sentinel master <master name> #指定主库信息
- 26379> Sentinel slaves <master name> #所有从库信息
- 26379> Sentinel sentinels <master name> #查看指定组的列表及状态
- 26379> Sentinel get-master-addr-by-name <master name> #查看指定组的主库的ip和端口
- 26379> Sentinel failover <master name> #强制执行故障转移
- 26379> Sentinel flushconfig #强制重写配置信息到配置文件
- 26379> Sentinel reset <pattern> #重置所有节点的配置,清除主节点相关状态,重新发现主和从节点
- 26379> Sentinel ckquorum <master name> #检测当前的节点总数
- 5、手动故障转移
- 1) 查看节点的权重
- # redis-cli -h 10.0.0.51 -p 6379 CONFIG GET slave-priority
- # redis-cli -h 10.0.0.52 -p 6379 CONFIG GET slave-priority
- # redis-cli -h 10.0.0.53 -p 6379 CONFIG GET slave-priority
- 2) 设置节点的权重(51为100,52和53为0)
- # redis-cli -h 10.0.0.52 -p 6379 CONFIG SET slave-priority 0
- # redis-cli -h 10.0.0.53 -p 6379 CONFIG SET slave-priority 0
- 3) 手动执行故障转移
- # redis-cli -h 10.0.0.51 -p 26379 sentinel failover mymaster
- 4) 查看结果
- # redis-cli -h 10.0.0.51 -p 26379 Sentinel get-master-addr-by-name mymaster
- 5) 恢复默认的权重(防止主库不能故障转移)
- # redis-cli -h 10.0.0.52 -p 6379 CONFIG SET slave-priority 100
- # redis-cli -h 10.0.0.53 -p 6379 CONFIG SET slave-priority 100
- 5) 总结
- 权重的id大的优先,默认是100,设置100以上可能有问题,推荐0-100
12、Redis Cluster集群
- 1、介绍
- 1) redis集群,无论有几个节点,一共只有16384个槽
- 2) 所有的槽位都必须分配,哪怕有1个槽位不正常,整个集群都不能用
- 3) 每个节点的槽的顺序不重要,重点是数量
- 4) hash算法足够随机,足够平均
- 5) 每个槽被分配到数据的概率是相当的
- 6) 集群的高可用依赖于主从复制
- 7) 集群拥有自己的配置文件,动态更新,不要手欠修改
- 8) 集群通讯会使用基础端口号+10000的端口,这个是自动创建的,不是配置文件配置的
- 9) 集群槽位分配比例允许误差在%2之间
- 2、环境规划
- 主节点 db01: 10.0.0.51:6380 db02: 10.0.0.52:6380 db03: 10.0.0.53:6380
- 从节点 db02: 10.0.0.52:6381 db03: 10.0.0.53:6381 db01: 10.0.0.51:6381
- 3、安装部署
- 1) 创建目录(所有节点)
- # mkdir -p /opt/redis_{6380,6381}/{conf,logs,pid}
- # mkdir -p /data/redis_{6380,6381}
- 2) 创建配置文件(所有节点,ip地址不同)
- # vim /opt/redis_6380/conf/redis_6380.conf
- bind 10.0.0.51
- port 6380
- daemonize yes
- pidfile "/opt/redis_6380/pid/redis_6380.pid"
- logfile "/opt/redis_6380/logs/redis_6380.log"
- dbfilename "redis_6380.rdb"
- dir "/data/redis_6380/"
- appendonly yes
- appendfilename "redis.aof"
- appendfsync everysec
- cluster-enabled yes #开启集群模式
- cluster-config-file nodes_6380.conf #集群node配置文件(动态更新)
- cluster-node-timeout 15000 #集群的超时时间
- # vim /opt/redis_6381/conf/redis_6381.conf
- bind 10.0.0.51
- port 6381
- daemonize yes
- pidfile "/opt/redis_6381/pid/redis_6381.pid"
- logfile "/opt/redis_6381/logs/redis_6381.log"
- dbfilename "redis_6381.rdb"
- dir "/data/redis_6381/"
- appendonly yes
- appendfilename "redis.aof"
- appendfsync everysec
- cluster-enabled yes
- cluster-config-file nodes_6381.conf
- cluster-node-timeout 15000
- 3) 启动集群(所有节点)
- # redis-server /opt/redis_6380/conf/redis_6380.conf
- # redis-server /opt/redis_6381/conf/redis_6381.conf
- 4、集群手动发现节点
- # redis-cli -h db01 -p 6380 CLUSTER MEET 10.0.0.52 6380 #节点发现
- # redis-cli -h db01 -p 6380 CLUSTER MEET 10.0.0.53 6380
- # redis-cli -h db01 -p 6380 CLUSTER MEET 10.0.0.51 6381
- # redis-cli -h db01 -p 6380 CLUSTER MEET 10.0.0.52 6381
- # redis-cli -h db01 -p 6380 CLUSTER MEET 10.0.0.53 6381
- # redis-cli -h db01 -p 6380 CLUSTER NODES #查看节点
- 5、Redis Cluster 通讯流程
- 1) 集群中的每一个节点,内部通信的端口号,在基础端口上加10000(6380+10000)
- 2) 每个节点在固定周期内发送 ping 消息
- 3) 收到 ping 消息的节点,用 pong 消息作为响应
- 4) meet消息是通知新节点加入
- 5) fail消息是节点宕机后,正常的节点会发送faill消息给其他节点
- 6、Redis Cluster手动分配槽位
- redis集群一共有16384个槽,所有的槽都必须分配完,有一个槽没分配,整个集群都不可用
- 1) 槽位规划
- db01:6380 0-5460
- db02:6380 5461-10921
- db03:6380 10922-16383
- 2) 分配槽位
- # redis-cli -h db01 -p 6380 CLUSTER ADDSLOTS {0..5460}
- # redis-cli -h db02 -p 6380 CLUSTER ADDSLOTS {5461..10921}
- # redis-cli -h db03 -p 6380 CLUSTER ADDSLOTS {10922..16382}
- # redis-cli -h 10.0.0.53 -p 6380 CLUSTER ADDSLOTS 16383
- 3) 查看集群状态
- # redis-cli -h db01 -p 6380 CLUSTER info
- # redis-cli -h db01 -p 6380 CLUSTER NODES
- 7、手动部署复制关系
- 1) 询集群的id
- # redis-cli -h 10.0.0.51 -p 6380 CLUSTER NODES
- 2) 设置主从复制
- # redis-cli -h db01 -p 6381 CLUSTER REPLICATE 35b56a(db02上6380的id)
- # redis-cli -h db02 -p 6381 CLUSTER REPLICATE 65baft(db03上6380的id)
- # redis-cli -h db03 -p 6381 CLUSTER REPLICATE a1d85c(db01上6380的id)
- 3) 检查复制关系
- # redis-cli -h db01 -p 6380 CLUSTER NODES
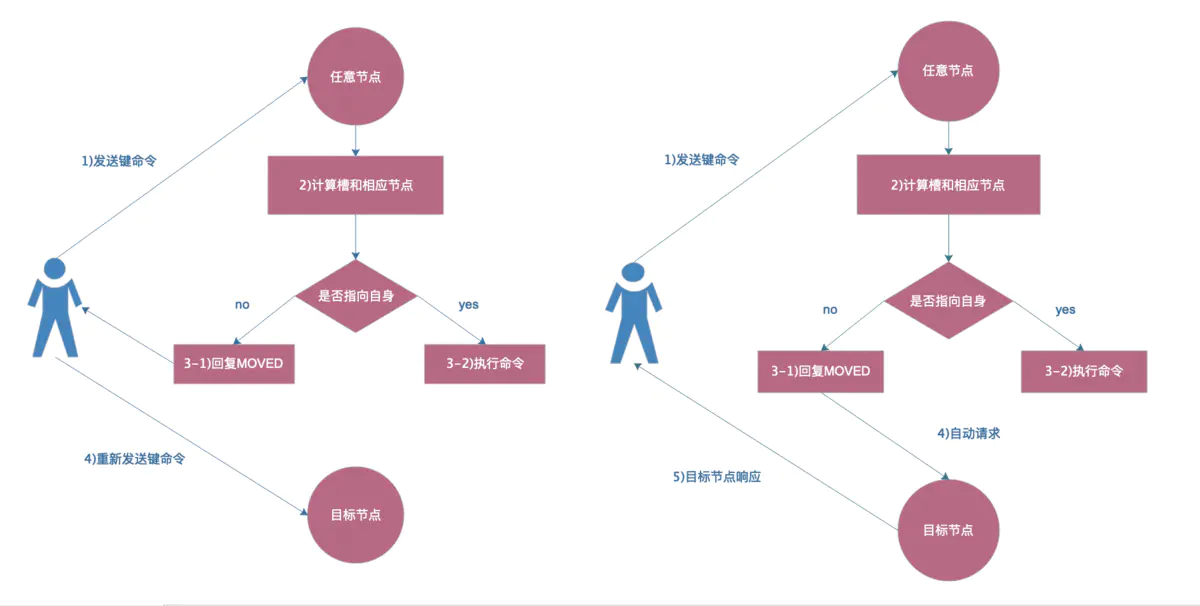
- 8、Redis Cluster ASK路由
- 1) 集群插入数据
- 6380> set k1 v1
- 2) 目前的现象
- 在db01的6380节点,插入数据有时候可以,有时候不行
- 3) 问题原因
- 因为集群模式有ASK路由规则,加-c参数,会自动跳转到目标节点处理,最后由目标节点返回信息
- 9、验证集群数据的随机和是否平均
- 1) 测试写入数据
- # for i in {1..10000};do redis-cli -c -h db01 -p 6380 set k_${i} v_${i};echo ${i};done
- 2) 查看key数量是否平均(所有节点)
- 6380> DBSIZE
- 3) 验证随机
- # redis-cli -c -h db03 -p 6380 keys \* > keys_all.txt
- # cat keys_all.txt |awk -F "_" '{print $2}'|sort -rn
- 4) 允许节点误差2%
- # redis-cli --cluster rebalance 10.0.0.51 6380(5.0版本)
- # redis-trib.rb rebalance 10.0.0.51:6380(4.0版本,命令依赖ruby环境)
- 5) 检查集群健康状态
- # redis-cli --cluster info 10.0.0.51 6380
- # redis-trib.rb check 10.0.0.51:6380
- 10、使用工具自动部署redis集群(新版本)
- 1) 恢复集群初始化(所有节点)
- # redis-cli -h db01 -p 6380 FLUSHALL
- # redis-cli -h db01 -p 6381 FLUSHALL
- # redis-cli -h db01 -p 6380 CLUSTER RESET
- # redis-cli -h db01 -p 6381 CLUSTER RESET
- 2) 使用工具初始化
- # redis-cli --cluster create 10.0.0.51:6380 10.0.0.52:6380 10.0.0.53:6380 10.0.0.51:6381 10.0.0.52:6381 10.0.0.53:6381 --cluster-replicas 1
- 3) 检查集群
- # redis-cli -h db01 -p 6380 CLUSTER NODES
- # redis-cli --cluster info 10.0.0.51 6380
- # redis-cli --cluster check 10.0.0.51 6380
- 11、使用工具自动部署redis集群(老版本)
- 1) 安装ruby环境
- # yum install rubygems
- # gem sources --remove https://rubygems.org/
- # gem sources -a http://mirrors.aliyun.com/rubygems/
- # gem update –system
- # gem install redis -v 3.3.5
- 2) 恢复集群初始化(所有节点)
- # pkill redis
- # rm -rf /data/redis_cluster/redis_6380/
- # rm -rf /data/redis_cluster/redis_6381/
- 3) 启动集群节点(所有节点)
- # redis-server /opt/redis_6380/conf/redis_6380.conf
- # redis-server /opt/redis_6381/conf/redis_6381.conf
- 4) 使用工具部署集群(一台部署)
- # cd /opt/redis/src/
- # ./redis-trib.rb create --replicas 1 10.0.0.51:6380 10.0.0.52:6380 10.0.0.53:6380 10.0.0.51:6381 10.0.0.52:6381 10.0.0.53:6381
- 5) 修改复制关系(工具部署的集群,存在主从在一台服务器上)
- # redis-cli -h db01 -p 6380 CLUSTER NODES
- # redis-cli -h db02 -p 6381 CLUSTER REPLICATE a38fc2b2
- # redis-cli -h db03 -p 6381 CLUSTER REPLICATE afd9311d
- 6) 检查集群完整性
- # ./redis-trib.rb check 10.0.0.51:6380
- 7) 检查集群负载平均
- # ./redis-trib.rb rebalance 10.0.0.51:6380
- 8) 查看集群信息
- # ./redis-trib.rb info 10.0.0.51:6380
- 12、案例
- ① 背景
- 部署集群时,不小心把所有的槽分配到1个节点上,写入了数据后,才发现问题
- ② 现象
- # redis-cli --cluster info 10.0.0.51 6380
- 10.0.0.51:6380 (ccaa5dcb...) -> 1000 keys | 16384 slots | 3 slaves.
- 10.0.0.53:6380 (a69e46ea...) -> 0 keys | 0 slots | 0 slaves.
- 10.0.0.52:6380 (b2719c41...) -> 0 keys | 0 slots | 0 slaves.
- ③ 解决方法1(获得所有key及value,再导入到集群)
- 1) 收集所有的key及value
- # redis-cli -c -h db01 -p 6380 keys \* > keys_all.txt
- 2) 编写脚本(批量设置key及value)
- # vim get_key.sh
- #!/bin/bash
- for key in $(cat keys_all.txt)
- do
- value=$(redis-cli -c -h 10.0.0.51 -p 6380 get ${key})
- echo redis-cli -c -h 10.0.0.51 -p 6380 set ${key} ${value} >> backup_all_key.txt
- done
- 3) 重新初始化集群(所有节点)
- # redis-cli -h db01 -p 6380 FLUSHALL
- # redis-cli -h db01 -p 6381 FLUSHALL
- # redis-cli -h db01 -p 6380 CLUSTER RESET
- # redis-cli -h db01 -p 6381 CLUSTER RESET
- 4) 重新分配槽位
- # redis-cli -h db01 -p 6380 CLUSTER MEET 10.0.0.52 6380
- # redis-cli -h db01 -p 6380 CLUSTER MEET 10.0.0.53 6380
- # redis-cli -h db01 -p 6380 CLUSTER ADDSLOTS {0..5460}
- # redis-cli -h db02 -p 6380 CLUSTER ADDSLOTS {5461..10921}
- # redis-cli -h db03 -p 6380 CLUSTER ADDSLOTS {10922..16383}
- # redis-cli -h db01 -p 6380 CLUSTER NODES
- # redis-cli --cluster info 10.0.0.51 6380
- 5) 执行导入脚本
- # bash backup_all_key.txt
- 6) 检查集群的数据
- # redis-cli --cluster info 10.0.0.51 6380
- ④ 使用redis-cli工具重新分配槽位
- 重新分配槽位
- # redis-cli --cluster reshard 10.0.0.51:6380
- 第一次交互:输入迁出的槽的数量
- How many slots do you want to move (from 1 to 16384)? 5461
- 第二次交互:输入接受的ID
- What is the receiving node ID? afd9311d(db02的ID)
- 第三次交互:输入发送者的ID
- Please enter all the source node IDs.
- Type 'all' to use all the nodes as source nodes for the hash slots.
- Type 'done' once you entered all the source nodes IDs.
- Source node #1: a38fc2b2(db01的ID)
- Source node #2: done
- 第四次交互:YES!
- 重复上面的操作,分配所有的槽位
- ⑤ 直接使用工具在线导入
- # redis-cli --cluster import 10.0.0.51:6380 --cluster-copy --cluster-replace --cluster-from 10.0.0.51:6379
- 10.0.0.51:6380 #集群地址
- 10.0.0.51:6379 #外部redis(备份数据的Redis,把aof文件复制过来的)
- ⑥ 流水线 pipline
- 新版本redis默认开启混合模式,重新分配槽位,导入旧aof文件
- # redis-cli -c -h 10.0.0.51 -p 6380 --pipe < redis.aof
- # redis-cli -c -h 10.0.0.52 -p 6380 --pipe < redis.aof
- # redis-cli -c -h 10.0.0.53 -p 6380 --pipe < redis.aof
- 13、使用工具扩容节点
- 1) 创建新节点
- # mkdir -p /opt/redis_{6390,6391}/{conf,logs,pid}
- # mkdir -p /data/redis_{6390,6391}
- # cp redis_6380.conf redis_6390/conf/redis_6390.conf
- # cp redis_6380.conf redis_6391/conf/redis_6391.conf
- # sed -i 's#6380#6390#g' redis_6390/conf/redis_6390.conf
- # sed -i 's#6380#6391#g' redis_6391/conf/redis_6391.conf
- 2) 启动节点
- # redis-server /opt/redis_6390/conf/redis_6390.conf
- # redis-server /opt/redis_6391/conf/redis_6391.conf
- 3) 发现节点
- # redis-cli -c -h db01 -p 6380 cluster meet 10.0.0.54 6390
- # redis-cli -c -h db01 -p 6380 cluster meet 10.0.0.54 6391
- 或用工具
- # ./redis-trib.rb add-node 10.0.1.54:6390 10.0.1.51:6380
- # ./redis-trib.rb add-node 10.0.1.54:6391 10.0.1.51:6380
- 4) 用工具扩容
- # redis-cli --cluster reshard 10.0.0.51:6380 #重新分配槽位
- How many slots do you want to move (from 1 to 16384)? 4096 #每个节点分配多少个槽位
- What is the receiving node ID? daf93ab(6390的ID) #目标节点ID
- Source node #1: all #源节点ID(只能输入一个节点的ID,再输入done,或输入all)
- 5) 检查集群完整性
- # ./redis-trib.rb check 10.0.0.51:6380
- 6) 检查集群负载均衡
- # ./redis-trib.rb rebalance 10.0.0.51:6380
- 7) 调整主从关系
- # redis-cli -h 10.0.0.51 -p 6381 CLUSTER REPLICATE df23ew36(db04的6390主的ID)
- # redis-cli -h 10.0.0.54 -p 6391 CLUSTER REPLICATE u38s02ld(db01的6380主的ID)
- 14、使用工具收缩节点
- 1) 重新分配槽位
- # redis-cli --cluster reshard 10.0.0.51:6380 #重新分配槽位
- How many slots do you want to move (from 1 to 16384)? 1365 #每个节点分配多少个槽位
- What is the receiving node ID? w3k18ylq(db01-6380-ID) #目标节点ID
- Source node #1: daf93ab(6390-ID) #源节点ID(只能输入一个节点的ID)
- Source node #2: done
- 重复操作,分配6390所有的槽位
- 2) 检查集群状态,确认6390没有槽位
- # redis-cli --cluster info 10.0.0.51:6380
- # ./redis-trib.rb info 10.0.0.51:6380
- 3) 删除节点
- # redis-cli --cluster del-node 10.0.0.54:6390 2b7a7b78(6390的ID)
- # redis-cli --cluster del-node 10.0.0.54:6391 c2d62daf(6391的ID)
- # ./redis-trib.rb del-node 10.0.0.51:6391 2b7a7b78(6390的ID)
- # ./redis-trib.rb del-node 10.0.0.51:6390 c2d62daf(6391的ID)
- 15、案例
- 1) 背景
- 迁移过程中,ctrl+c,集群出现问题
- 2) 检查,有报错
- # ./redis-trib.rb check 10.0.0.51:6380
- 3) 解决办法(数据会丢)
- # ./redis-trib.rb fix 10.0.0.51:6380 #尝试修复
- # redis-cli -h db01 -p 6380 CLUSTER NODES #找到有问题的槽位
- # redis-cli -h db01 -p 6380 cluster delslots 773 #删除有问题的槽位
- # redis-cli -h db01 -p 6380 cluster addslots 773 #重新添加新槽位
- 16、分析键值大小
- 1) 用自带工具分析
- # redis-cli --bigkeys
- 2) 用第三方工具分析
- ① 安装
- # yum install python-pip gcc python-devel -y
- # cd /opt/
- # git clone https://github.com/sripathikrishnan/redis-rdb-tools
- # cd redis-rdb-tools
- # pip install python-lzf
- # python setup.py install
- ② 用工具分析
- # rdb -c memory redis_6380.rdb -f redis_6380.rdb.csv
- ③ 过滤分析
- # awk -F "," '{print $4,$3}' redis_6379.rdb.csv |sort -r
- 17、监控过期键
- 1) Keys * 查出来匹配的键名,然后循环读取ttl时间(Keys 重操作,不提供服务的从节点)
- # redis-cli -h 10.0.0.55 -p 6381 keys * > key_list.txt
- 2) scan * 范围查询键名,然后循环读取ttl时间
- # cat check_key.sh
- #!/bin/bash
- key_num=0
- > key_name.log
- for line in $(cat key_list.txt)
- do
- while true
- do
- scan_num=$(redis-cli -h 10.0.0.51 -p 6380 SCAN ${key_num} match ${line}\* count 1000|awk 'NR==1{print $0}')
- key_name=$(redis-cli -h 10.0.0.51 -p 6380 SCAN ${key_num} match ${line}\* count 1000|awk 'NR>1{print $0}')
- echo ${key_name}|xargs -n 1 >> key_name.log
- ((key_num=scan_num))
- if [ ${key_num} == 0 ]
- then
- break
- fi
- done
- done
- 18、新版本数据迁移
- 1) 相当于mv,集群的旧数据会删除
- # redis-cli --cluster import 10.0.0.51:6380 --cluster-from 10.0.0.51:6379
- 2) 相当于cp,集群的旧数据会保留
- # redis-cli --cluster import 10.0.0.51:6380 --cluster-copy --cluster-from 10.0.0.51:6379
- 3) 相当于cp -f,集群的旧数据会覆盖
- # redis-cli --cluster import 10.0.0.51:6380 --cluster-copy --cluster-replace --cluster-from 10.0.0.51:6379
- 19、 redis的内存管理
- 1) 限制最大内存
- 6379> config set maxmemory 2G
- 2) 内存回收机制
- noevicition 默认策略,不会删除数据,返回错误信息,拒绝所有写操作,只响应读操作
- volatile-lru 根据LRU算法,删除过期时间的key,如果没有可删除的key,则退回到默认策略
- allkeys-lru 根据LRU算法,删除所有key
- allkeys-random 随机删除所有key
- volatile-random 随机删除过期key
- volatile-ttl 删除即将过期的key
- 6379> config set maxmemory-policy volatile-lru
- 3) 性能测试
- # redis-benchmark -n 10000 -q
- 20、命令总结
- 1) redis 常用命令
- 全局命令
- keys *
- DBSIZE
- EXISTS k1
- EXPIRE k1 10
- TTL k1
- DEL k1
- 字符串:
- set k1 v1
- get k1
- mset k1 v1 k2 v2 k3 v3
- mget k1 k2 k3
- incr k1
- incrby k1 N
- 列表:
- LPUSH
- RPUSH
- LPOP
- RPOP
- LLEN
- LRANGE list1 0 -1
- HASH:
- HMSET
- HGET
- HMGET
- HGETALL
- 集合:
- SADD
- SDIFF
- SINTER
- SUNION
- SREM
- 有序集合:
- ZADD
- ZCARD
- ZSCORE
- ZRANK
- ZREVRANK
- ZRANGE
- ZRANGEBYSCORE
- ZINCRBY
- ZCOUNT
- 2) 集群常用命令
- CLUSTER INFO #集群的信息
- CLUSTER NODES #集群节点信息
- CLUSTER MEET <ip> <port> #发现节点
- CLUSTER FORGET <node_id> #移除节点
- CLUSTER REPLICATE <node_id> #设置主从复制
- CLUSTER SAVECONFIG #节点的配置保存到文件
- CLUSTER ADDSLOTS <slot> [slot ...] #添加新槽位
- CLUSTER DELSLOTS <slot> [slot ...] #移除槽位
- CLUSTER FLUSHSLOTS #移除所有槽位
- CLUSTER SETSLOT <slot> NODE <node_id> #分配槽位到指定的节点
- CLUSTER SETSLOT <slot> MIGRATING <node_id> #迁移槽位到指定的节点
- CLUSTER SETSLOT <slot> IMPORTING <node_id> #导入指定的节点的槽位
- CLUSTER SETSLOT <slot> STABLE #取消槽位的的导入或迁移
- CLUSTER KEYSLOT <key> #计算key在槽的位置
- CLUSTER COUNTKEYSINSLOT <slot> #槽中键值对的数量
- CLUSTER GETKEYSINSLOT <slot> <count> #槽中key的列表
学习Redis(二)的更多相关文章
- Redis学习笔记二 (BitMap算法分析与BitCount语法)
Redis学习笔记二 一.BitMap是什么 就是通过一个bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身.我们知道8个bit可以组成一个Byte,所以bitmap本身会极大的节省 ...
- python3.4学习笔记(二十五) Python 调用mysql redis实例代码
python3.4学习笔记(二十五) Python 调用mysql redis实例代码 #coding: utf-8 __author__ = 'zdz8207' #python2.7 import ...
- python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法
python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法window安装redis,下载Redis的压缩包https://git ...
- redis 学习(二)-- 通用命令
redis 学习(二)-- 通用命令 1. keys pattern 含义:查找所有符合给定模式(pattern)的key 命令 含义 keys * 遍历所有 key keys he[h-l]* 遍历 ...
- redis学习教程二《四大数据类型》
redis学习教程二<四大数据类型> 四大数据类型包括:字符串 哈希 列表 集合一 : Redis字符串 Redis字符串命令用于管理Redis中的字符串 ...
- Redis学习笔记二
学习Redis添加Object时,由于Redis只能存取字符串String,对于其它数据类型形容:Int,long,double,Date等不提供支持,因而需要设计到对象的序列化和反序列化.java序 ...
- 分布式缓存技术redis学习(二)——详细讲解redis数据结构(内存模型)以及常用命令
Redis数据类型 与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多,常用的数据类型主要有五种:String.List.Hash.Set和Sor ...
- redis学习笔记(二)——java中jedis的简单使用
redis怎么在java中使用,那就是要用到jedis了,jedis是redis的java版本的客户端实现,原本原本想上来就直接学spring整合redis的,但是一口吃个胖子,还是脚踏实地,从基础开 ...
- Redis学习——Redis持久化之AOF备份方式保存数据
新技术的出现一定是在老技术的基础之上,并且完善了老技术的某一些不足的地方,新技术和老技术就如同JAVA中的继承关系.子类(新技术)比父类(老技术)更加的强大! 在前面介绍了Redis学习--Redis ...
- 深入学习Redis(1):Redis内存模型
前言 Redis是目前最火爆的内存数据库之一,通过在内存中读写数据,大大提高了读写速度,可以说Redis是实现网站高并发不可或缺的一部分. 我们使用Redis时,会接触Redis的5种对象类型(字符串 ...
随机推荐
- React函数类组件及其Hooks学习
目录 函数类组件 函数式组件和类式组件的区别: 为什么要使用函数式组件? Hooks概念及常用的Hooks 1. useState: State的Hook 语法 useState()说明: setXx ...
- C语言中puts()和printf()区别
puts的功能更加单一,只能输出字符串:printf的功能更加广,可以格式化数据,输出多种类型的数据. puts()函数用来向标准输出设备(屏幕)写字符串并换行. 调用方式为puts(string): ...
- SevenZip.SevenZipLibraryException: Can not load 7-zip library or internal COM error! Message: failed to load library.
SevenZip.SevenZipLibraryException: Can not load 7-zip library or internal COM error! Message: failed ...
- IDEA 配置安卓(Android)开发环境
今天用idea配了一下环境,安装了SDK和Gradle.找了一些学习的资源,明天正式开始学习,配置环境的(3条消息) 用IntelliJ IDEA 配置安卓(Android)开发环境(一条龙服务,新手 ...
- WPS:编号
独立编号 只想用于表示顺序的编号,不想与标题级别挂钩 样式--编号--选择编号种类后--自定义--按照图片设置 要得到类似这样的编号格式 假设 第一章 系统介绍 为 样式 标题二 1.1 监控管理系统 ...
- 在 Debian 和 Ubuntu 上安装 Cutefish 可爱鱼
版权声明:原创文章,未经博主允许不得转载 CutefishOS 是一个可爱好看的新 Linux 发行版,当前最新版本为 0.8beta .这是一个基于 Debian 的发行版,从其镜像源配置就可以明显 ...
- 9.resultMap元素
resultMap 是 MyBatis 中最复杂的元素,主要用于解决实体类属性名与数据库表中字段名不一致的情况,可以将查询结果映射成实体对象.下面我们先从最简单的功能开始介绍. 现有的 MyBatis ...
- 4. 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识wrk、wrk2
目录 堪比JMeter的.Net压测工具 - Crank 入门篇 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识yml 堪比JMeter的.Net压测工具 - Crank 进阶篇 ...
- think php 3种验证方式
方式一:独立验证 // 验证1.独立验证 //验证的规则 $rule = [ 'name' => 'require|max:25', 'username' => 'require', 'p ...
- 02 基础 卸载JDK 安装JDK Java程序运行机制
基础 JDK:Java Development Kit(Java开发者工具 包含JRE和JVM) JRE:Java Runtime Environment(java运行时环境,包含JVM) JVM:J ...