【python基础】第11回 数据类型内置方法 02
本章内容概要
列表内置方法
字典内置方法
元组内置方法
集合内置方法
可变类型与不可变类型
本章内容详细
1.列表内置方法 list
列表在调用内置方法之后不会产生新的值
1.1 统计列表中的数据值的个数
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
l2 = [77, 22, 55, 33, 44, 99]
# 统计列表中数据的个数
print(len(l1)) # 5
print(len(l2)) # 6

2.增
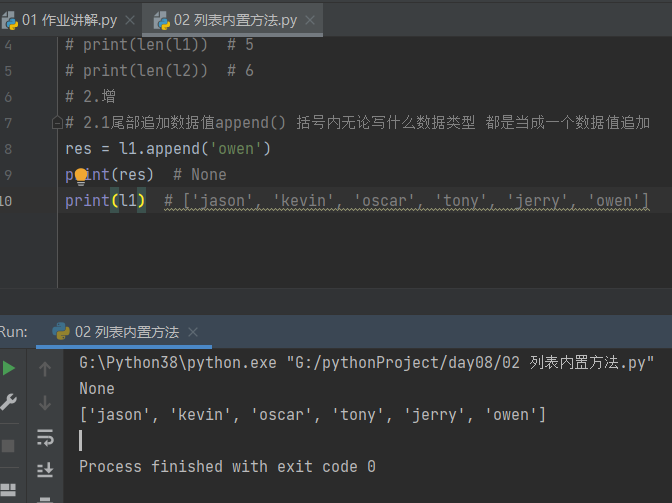
2.1 尾部追加数据值append() 括号内无论写什么数据类型 都是当成一个数据值增加
# 2.1尾部追加数据值append() 括号内无论写什么数据类型 都是当成一个数据值追加
res = l1.append('owen')
print(res) # None 空
print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry', 'owen']
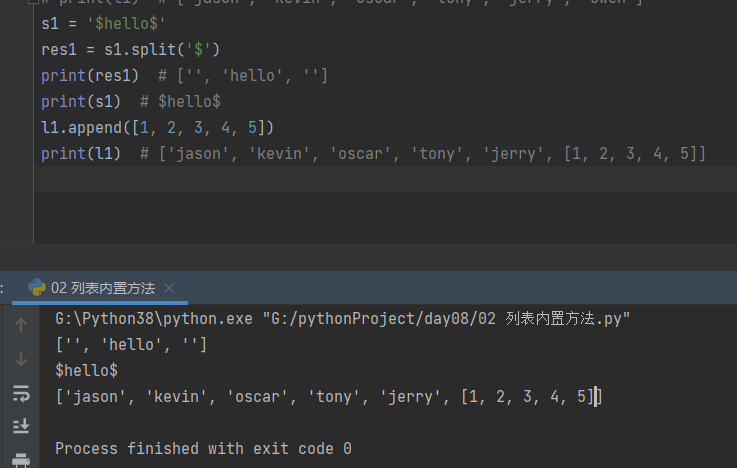
s1 = '$hello$'
res1 = s1.split('$')
print(res1) # ['', 'hello', '']
print(s1) # $hello$
l1.append([1, 2, 3, 4, 5])
print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry', [1, 2, 3, 4, 5]]
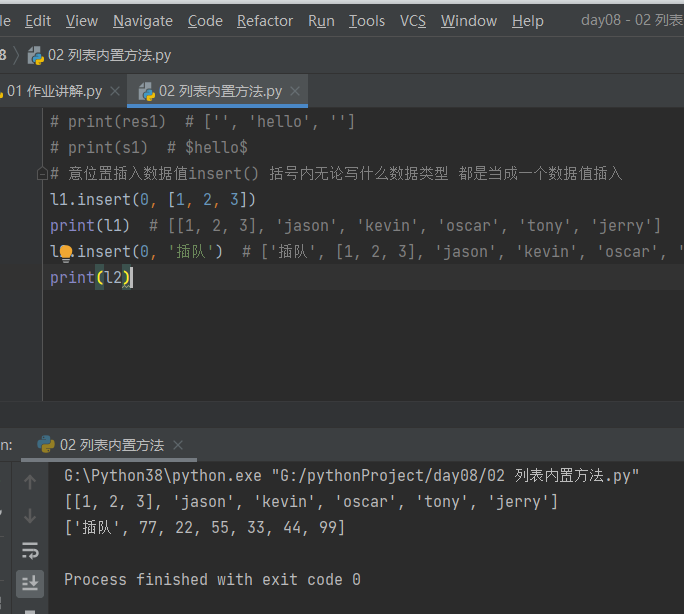
2.2 任意位置插入数据值insert 括号内i而什么数据类型 都是当成一数据子方恒
# 意位置插入数据值insert() 括号内无论写什么数据类型 都是当成一个数据值插入
l1.insert(0, [1, 2, 3])
print(l1) # [[1, 2, 3], 'jason', 'kevin', 'oscar', 'tony', 'jerry']
l2.insert(0, '插队') # ['插队', [1, 2, 3], 'jason', 'kevin', 'oscar', 'tony', 'jerry']
print(l2)
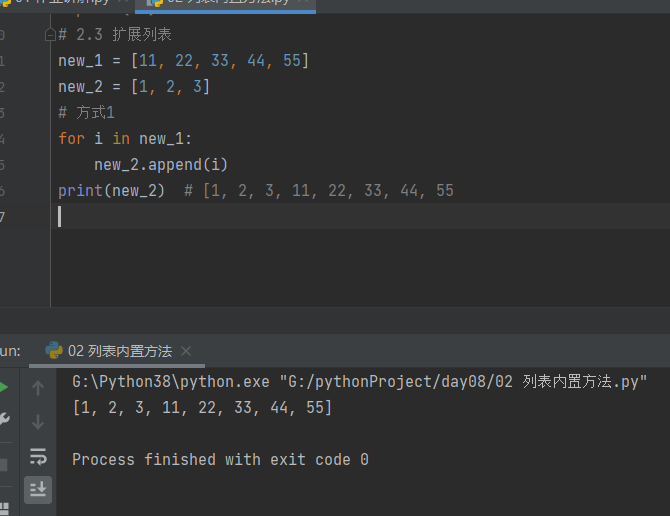
2.3 扩展列表
方式1
# 2.3 扩展列表
new_1 = [11, 22, 33, 44, 55]
new_2 = [1, 2, 3]
# 方式1
for i in new_1:
new_2.append(i)
print(new_2) # [1, 2, 3, 11, 22, 33, 44, 55
方式2
# 方式2
print(new_1 + new_2) # [11, 22, 33, 44, 55, 1, 2, 3]
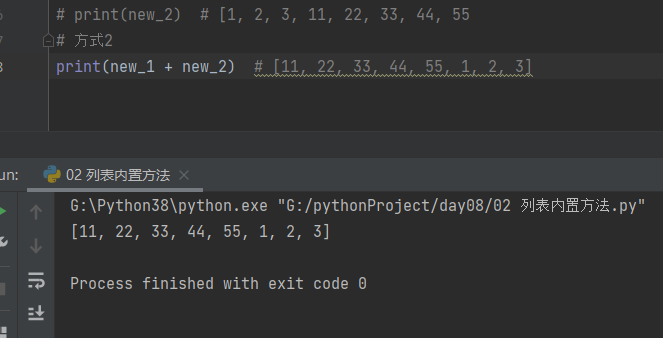
方式3(推荐使用) extend
# 方式3(推荐使用)
new_1.extend(new_2) # 括号里面必须是支持for循环的数据类型 for循环+append()
print(new_1) # [11, 22, 33, 44, 55, 1, 2, 3]
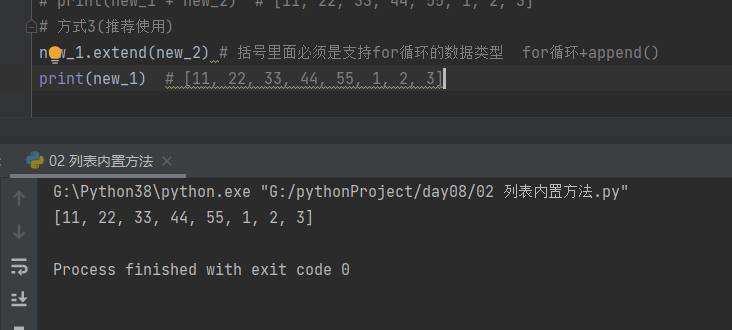
3.查询数据与修改数据
# 3.查询数据与修改数据
print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry']
print(l1[0]) # jason
print(l1[1:4]) # ['kevin', 'oscar', 'tony']
l1[0] = 'jasonNM'
print(l1) # ['jasonNM', 'kevin', 'oscar', 'tony', 'jerry']
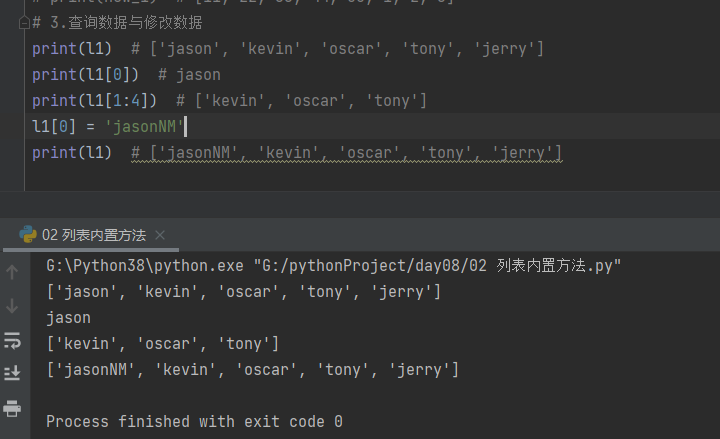
4.删除数据
4.1通用数据策略
# 4.1通用数据策略
del l1[0] # 通过索引即可
print(l1) # ['kevin', 'oscar', 'tony', 'jerry']
4.2指名道姓的删除 remove
# 4.2 指名道姓删除
res = l1.remove('jason') # 括号内必须填写明确的数据值
print(l1, res) # ['kevin', 'oscar', 'tony', 'jerry'] None
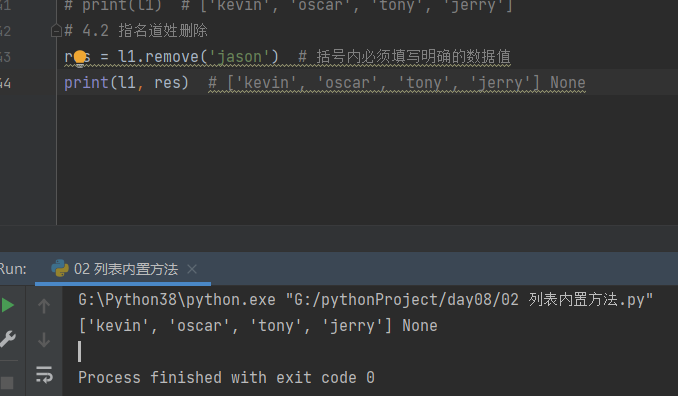
4.3 先取出数值 在删除 pop
# 4.3 先取出数据值 然后再删
res = l1.pop() # 默认取出列表尾部数据值 然后再删
print(l1, res) # ['jason', 'kevin', 'oscar', 'tony'] jerry
res = l1.pop(0)
print(res, l1) # jason ['kevin', 'oscar', 'tony']
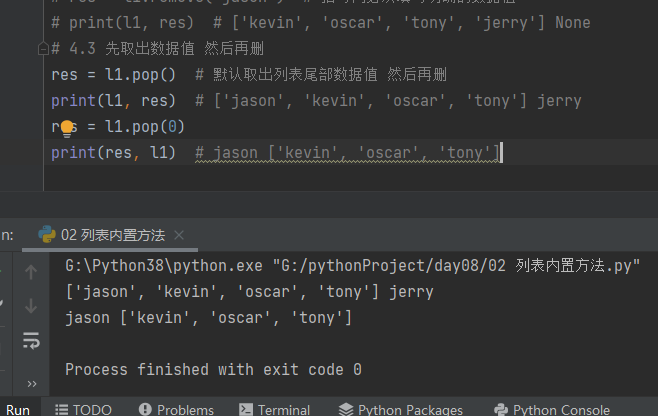
5.查看索引值 index
# 5.查看数据值对于的索引值
print(l1.index('jason'))
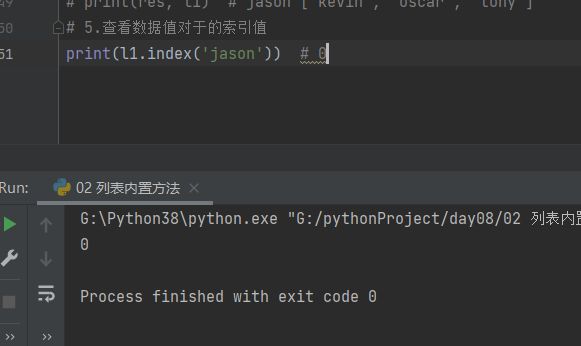
6.统计某个数据值出现的数据 append
# 6.统计某个数据值出现的次数
l1.append('jason')
print(l1.count('jason')) # 2
7.排序 sort 升序 sort(reverse=True) 降序 b.sort(key=a.index) 去重b按a的列表排序
l2.sort() # 升序 [22, 33, 44, 55, 77, 99]
print(l2)
l2.sort(reverse=True) # 降序
print(l2) # [99, 77, 55, 44, 33, 22]
8.翻转 reverse
l1.reverse() # 前后跌倒
print(l1) # ['jerry', 'tony', 'oscar', 'kevin', 'jason']
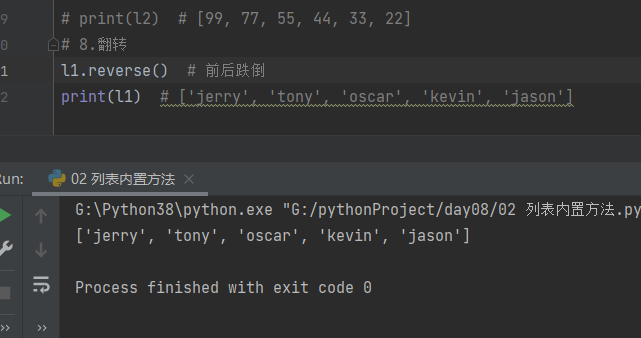
9.比较运算
new_1 = [99, 22]
new_2 = [11, 22, 33, 44]
print(new_1 > new_2) # True 是按照位置顺序一一比较
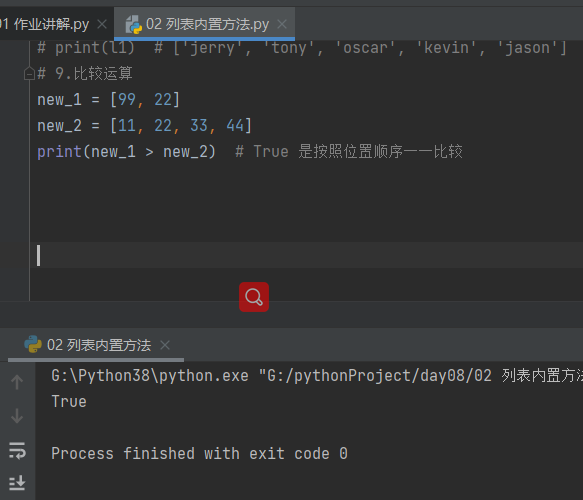
new_1 = ['a', 11]
new_2 = [11, 22, 33, 44]
print(new_1 > new_2) # 不同数据类型之间默认无法直接做操作
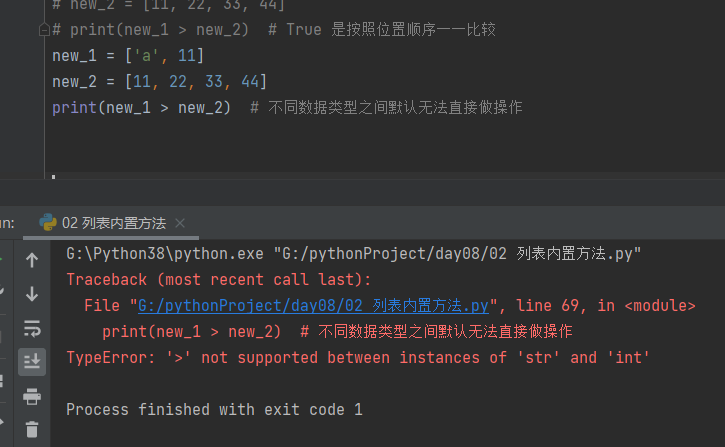
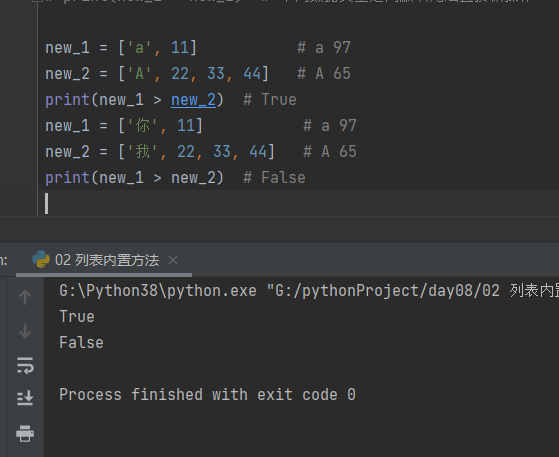
new_1 = ['a', 11] # a 97
new_2 = ['A', 22, 33, 44] # A 65
print(new_1 > new_2) # True
new_1 = ['你', 11] # a 97
new_2 = ['我', 22, 33, 44] # A 65
print(new_1 > new_2) # False
2.字典内置方法 dict
字典很少涉及到类型转换 都是直接定义使用
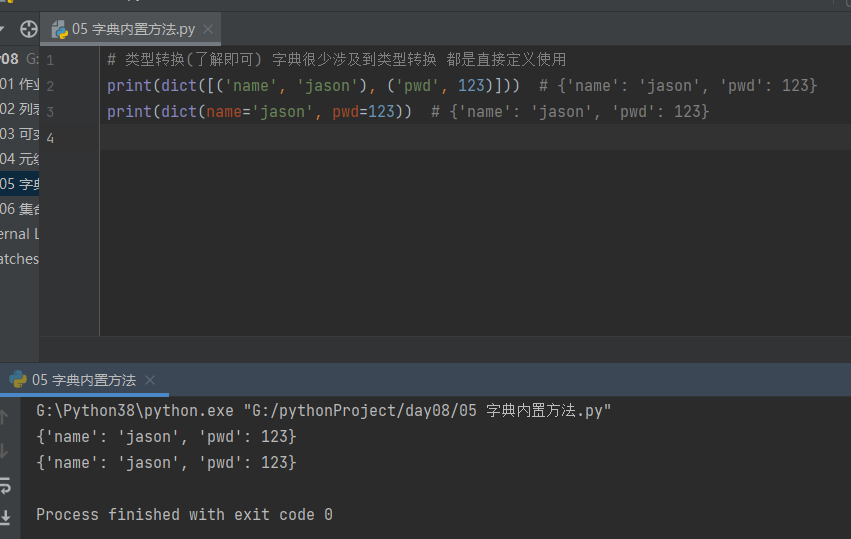
# 类型转换(了解即可) 字典很少涉及到类型转换 都是直接定义使用
print(dict([('name', 'jason'), ('pwd', 123)])) # {'name': 'jason', 'pwd': 123}
print(dict(name='jason', pwd=123)) # {'name': 'jason', 'pwd': 123}
1.字典内k:v键值对是无序的
2.取值
# 2.取值操作
print(info['username']) # 不推荐使用 键不存在会直接报错
print(info['xxx']) # 不推荐使用 键不存在会直接报错
print(info.get('username')) # jason
print(info.get('xxx')) # None
print(info.get('username', '键不存在返回的值 默认返回None')) # jason
print(info.get('xxx', '键不存在返回的值 默认返回None')) # 键不存在返回的值 默认返回None
print(info.get('xxx', 123)) # 123
print(info.get('xxx')) # None
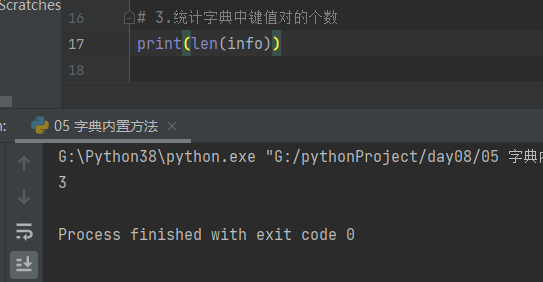
3.统计字典中键值对的个数 len
print(len(info)) # 3
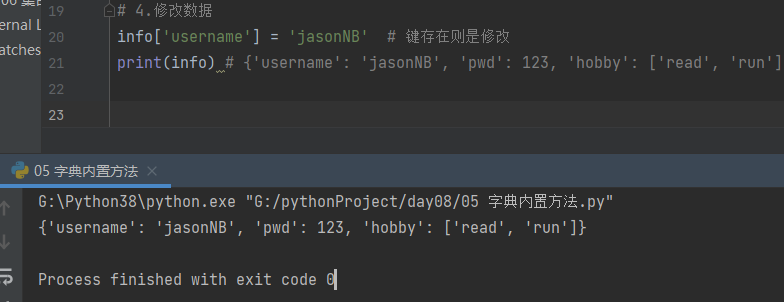
4.修改数据 info
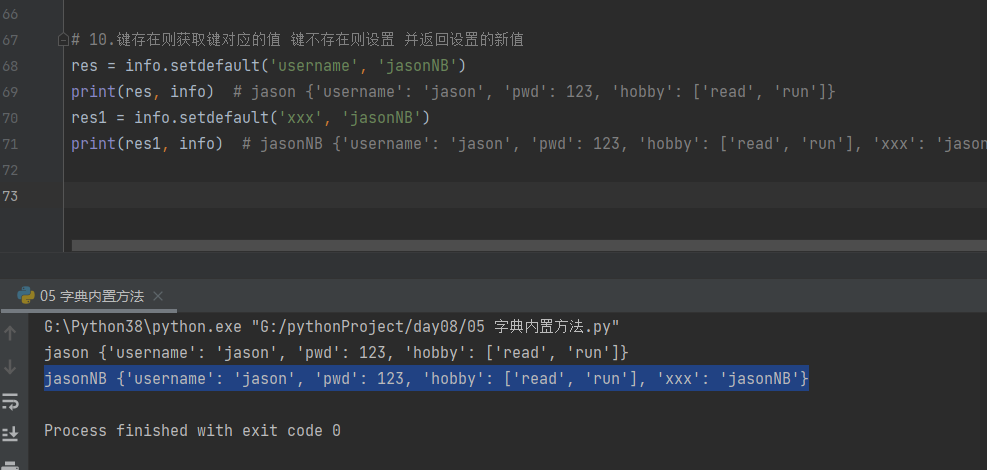
info['username'] = 'jasonNB' # 键存在则是修改
print(info) # {'username': 'jasonNB', 'pwd': 123, 'hobby': ['read', 'run']}
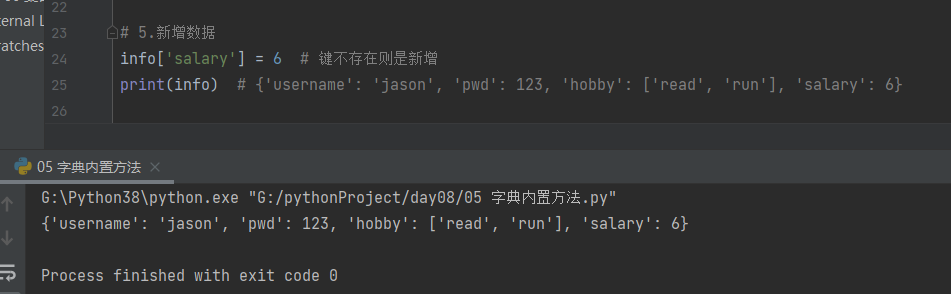
5.新增数据 info
# 5.新增数据
info['salary'] = 6 # 键不存在则是新增
print(info) # {'username': 'jason', 'pwd': 123, 'hobby': ['read', 'run'], 'salary': 6}
6.删除数据
方式1
# 方式1
del info['username']
print(info) # {'pwd': 123, 'hobby': ['read', 'run']}
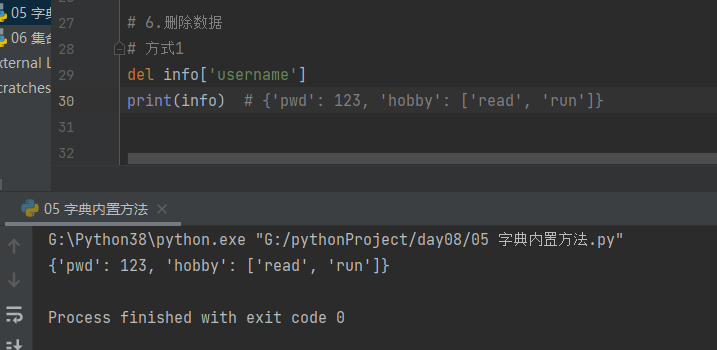
方式2
res = info.pop('username')
print(info, res) # {'pwd': 123, 'hobby': ['read', 'run']} jason
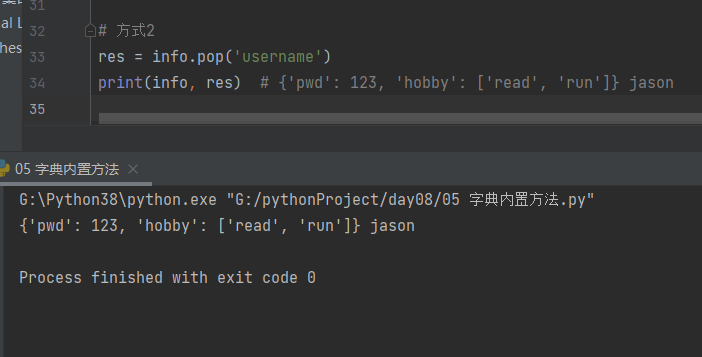
方式3
# 方式3
info.popitem() # 随机删除
print(info) # {'username': 'jason', 'pwd': 123}
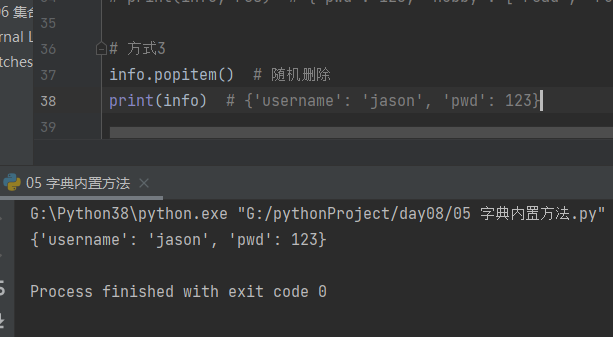
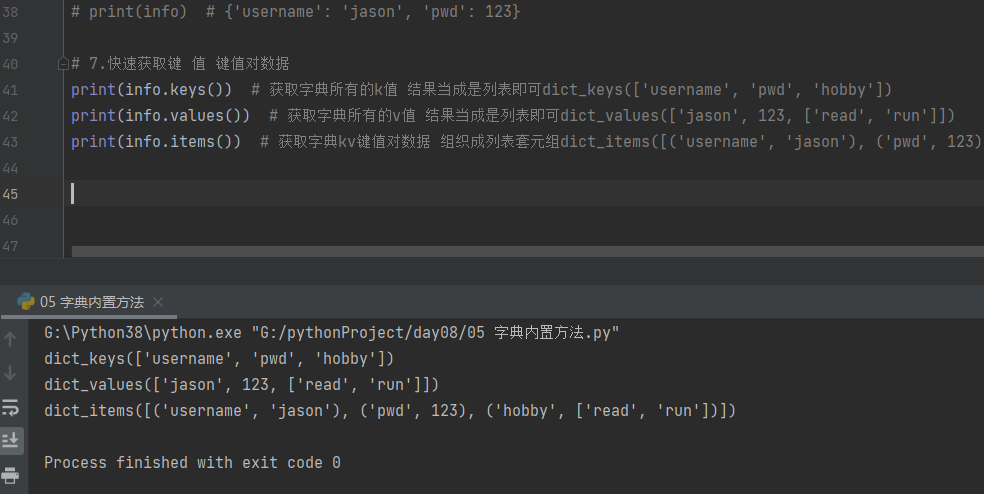
7.快速获取键 值 键值对数据
print(info.keys()) # 获取字典所有的k值 结果当成是列表即可dict_keys(['username', 'pwd', 'hobby'])
print(info.values()) # 获取字典所有的v值 结果当成是列表即可dict_values(['jason', 123, ['read', 'run']])
print(info.items()) # 获取字典kv键值对数据 组织成列表套元组dict_items([('username', 'jason'), ('pwd', 123), ('hobby', ['read', 'run'])])
8.修改字典数据 键存在则是修改 键不存在则是新增
# 8.修改字典数据 键存在则是修改 键不存在则是新增
info.update({'username':'jason123'})
print(info) # {'username': 'jason123', 'pwd': 123, 'hobby': ['read', 'run']}
info.update({'xxx':'jason123'})
print(info) # {'username': 'jason123', 'pwd': 123, 'hobby': ['read', 'run'], 'xxx': 'jason123'}

9.快速构造字典 给的值默认情况下所有的键都用一个
# 9.快速构造字典 给的值默认情况下所有的键都用一个
res = dict.fromkeys([1, 2, 3], None)
print(res) # {1: None, 2: None, 3: None}
new_dict = dict.fromkeys(['name', 'pwd', 'hobby'], []) # {'name': [], 'pwd': [], 'hobby': []}
new_dict['name'] = []
new_dict['name'].append(123)
new_dict['pwd'].append(123)
new_dict['hobby'].append('read')
print(new_dict) # {'name': [123], 'pwd': [123, 'read'], 'hobby': [123, 'read']}

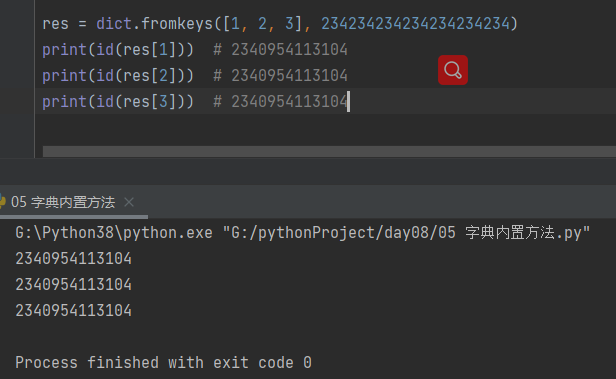
res = dict.fromkeys([1, 2, 3], 234234234234234234234)
print(id(res[1])) # 2340954113104
print(id(res[2])) # 2340954113104
print(id(res[3])) # 2340954113104
10.键存在则获取键对应的值 键不存在则设置 并返回设置的新值
3.元组内置方法 tuple
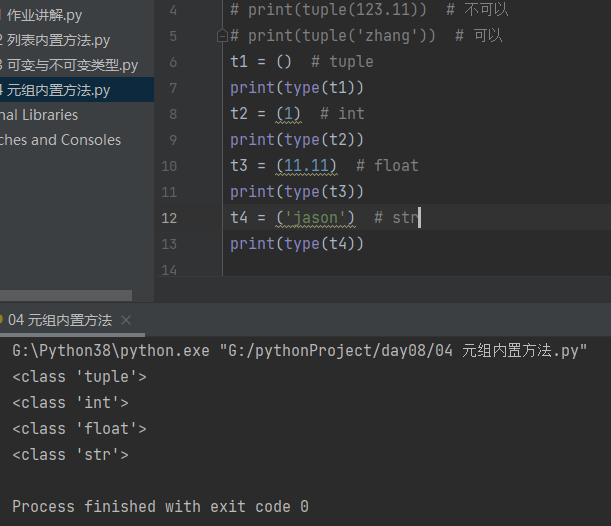
# 关键字 tuple
# 类型转换 支持for循环的数据类型都可以转元组
print(tuple(123)) # 不可以
print(tuple(123.11)) # 不可以
print(tuple('zhang')) # 可以
t1 = () # tuple
print(type(t1))
t2 = (1) # int
print(type(t2))
t3 = (11.11) # float
print(type(t3))
t4 = ('jason') # str
print(type(t4))
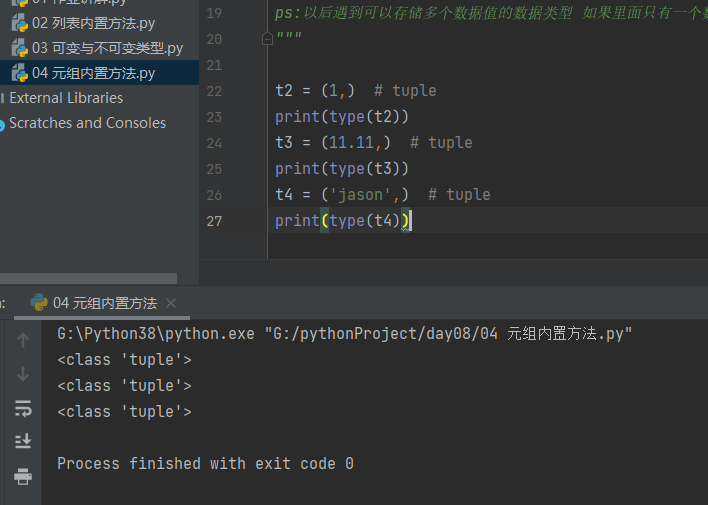
当元组内只有一个数据值的时候 逗号不能省略,如果省略了 那么括号里面是什么数据类型就是什么数据类型
建议:编写元组 逗号加上 哪怕只有一个数据(111, ) ('jason', )ps:以后遇到可以存储多个数据值的数据类型 如果里面只有一个数据 逗号也趁机加上
t2 = (1,) # tuple
print(type(t2))
t3 = (11.11,) # tuple
print(type(t3))
t4 = ('jason',) # tuple
print(type(t4))
1.统计元组内个数
t1 = (11, 22, 33, 44, 55, 66)
# 1.统计元组内数据值的个数
print(len(t1)) # 6
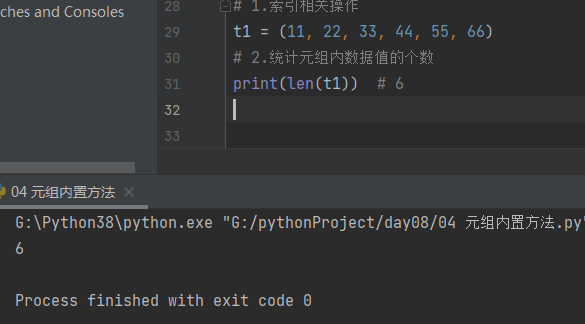
2.查与改
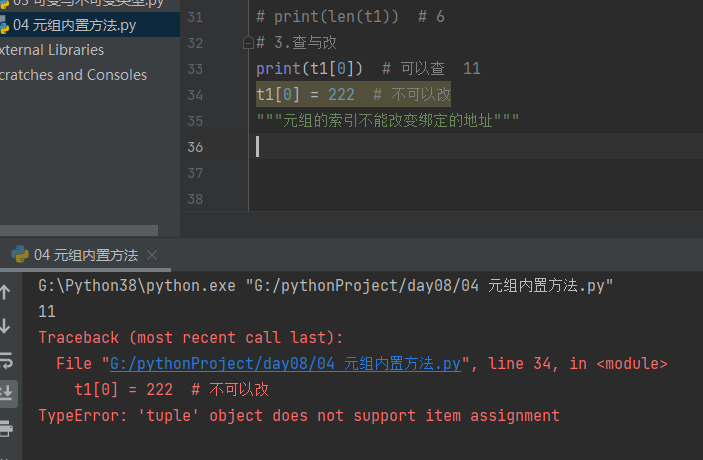
# 2.查与改
print(t1[0]) # 可以查 11
t1[0] = 222 # 不可以改
"""元组的索引不能改变绑定的地址"""
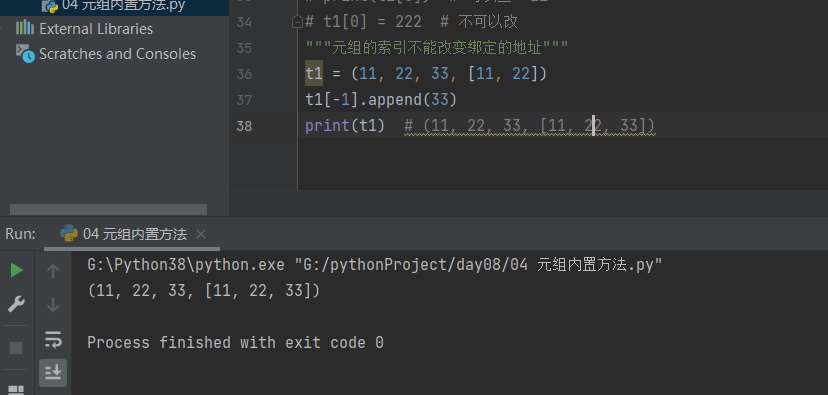
t1 = (11, 22, 33, [11, 22])
t1[-1].append(33)
print(t1) # (11, 22, 33, [11, 22, 33])
4.集合内置方法 set
set() 类型转换 支持for循环的 并且数据必须是不可变类型
1.定义空集合需要使用关键字才可以
2.集合内数据必须是不可变类型(整型 浮点型 字符串 元组 布尔值)
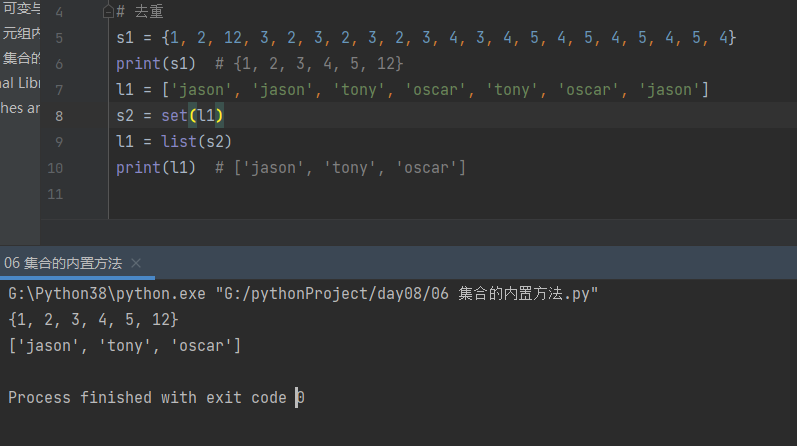
3.去重
# 去重
s1 = {1, 2, 12, 3, 2, 3, 2, 3, 2, 3, 4, 3, 4, 5, 4, 5, 4, 5, 4, 5, 4}
print(s1) # {1, 2, 3, 4, 5, 12}
l1 = ['jason', 'jason', 'tony', 'oscar', 'tony', 'oscar', 'jason']
s2 = set(l1)
l1 = list(s2)
print(l1) # ['jason', 'tony', 'oscar']
4.模拟两个人的好友集合
1.求f1和f2的共同好友
f1 = {'jason', 'tony', 'oscar', 'jerry'}
f2 = {'kevin', 'jerry', 'jason', 'lili'}
# 1.求f1和f2的共同好友
print(f1 & f2) # {'jason', 'jerry'}
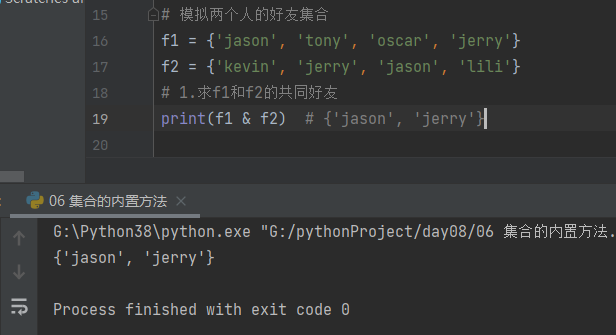
2.求f1/f2独有好友
print(f1 - f2) # {'oscar', 'tony'}
print(f2 - f1) # {'lili', 'kevin'}
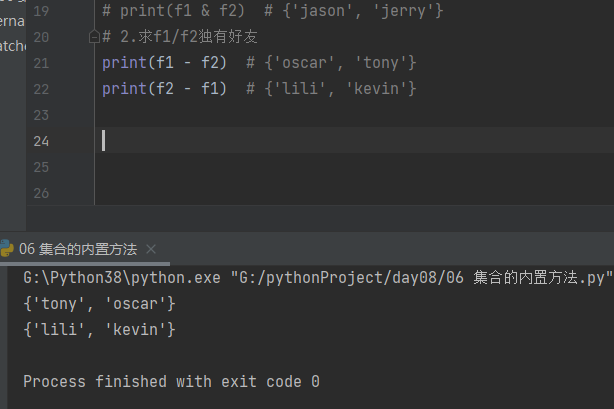
3.求f1和f2所有的好友
print(f1 | f2) # {'jason', 'kevin', 'lili', 'oscar', 'jerry', 'tony'}
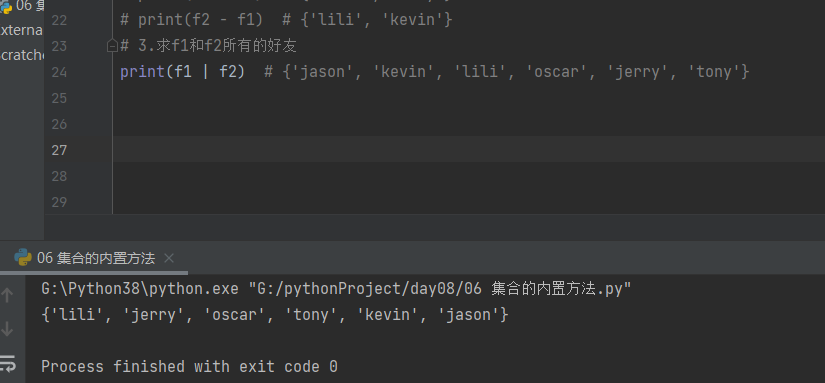
4.求f1和f2各自独有的好友(排除共同好友)
print(f1 ^ f2) # {'kevin', 'lili', 'tony', 'oscar'}
5.父集 子集
# 5.父集 子集
s1 = {1, 2, 3, 4, 5, 6, 7}
s2 = {3, 2, 1}
print(s1 > s2) # s1是否是s2的父集 s2是不是s1的子集
print(s1 < s2)

5.可变类型与不可变类型
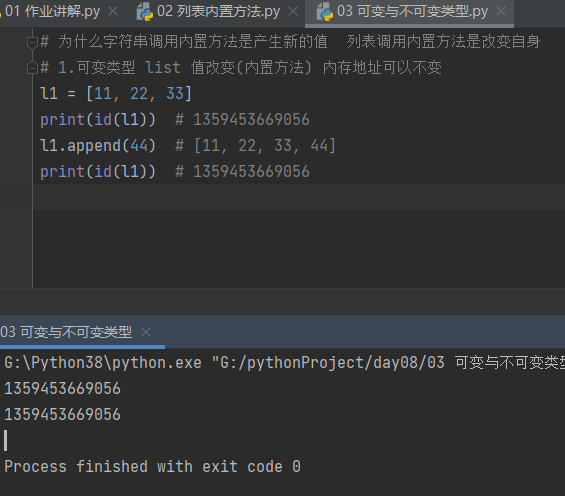
为什么字符串调用内置方法是产生新的值 列表调用内置方法是改变自身
1.可变类型 list 值改变(内置方法) 内存地址可以不变
# 为什么字符串调用内置方法是产生新的值 列表调用内置方法是改变自身
# 1.可变类型 list 值改变(内置方法) 内存地址可以不变
l1 = [11, 22, 33]
print(id(l1)) # 1359453669056
l1.append(44) # [11, 22, 33, 44]
print(id(l1)) # 1359453669056
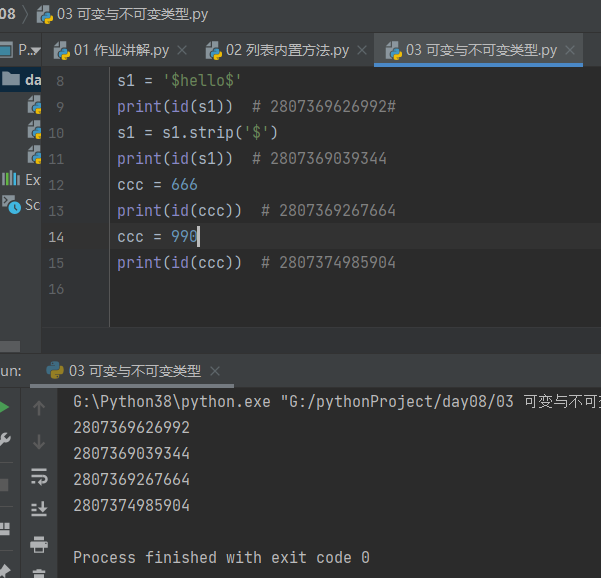
2.不可变类型 str int float 值改变(内置方法),内存地址肯定变
# 2.不可变类型 str int float 值改变(内置方法),内存地址肯定变
s1 = '$hello$'
print(id(s1)) # 2807369626992#
s1 = s1.strip('$')
print(id(s1)) # 2807369039344
ccc = 666
print(id(ccc)) # 2807369267664
ccc = 990
print(id(ccc)) # 2807374985904
作业
# 1.
# 利用列表编写一个员工姓名管理系统
# 输入1执行添加用户名功能
# 输入2执行查看所有用户名功能
# 输入3执行删除指定用户名功能
# ps: 思考如何让程序循环起来并且可以根据不同指令执行不同操作
# 提示: 循环结构 + 分支结构
# 拔高: 是否可以换成字典或者数据的嵌套使用完成更加完善的员工管理而不是简简单单的一个用户名(能写就写不会没有关系)
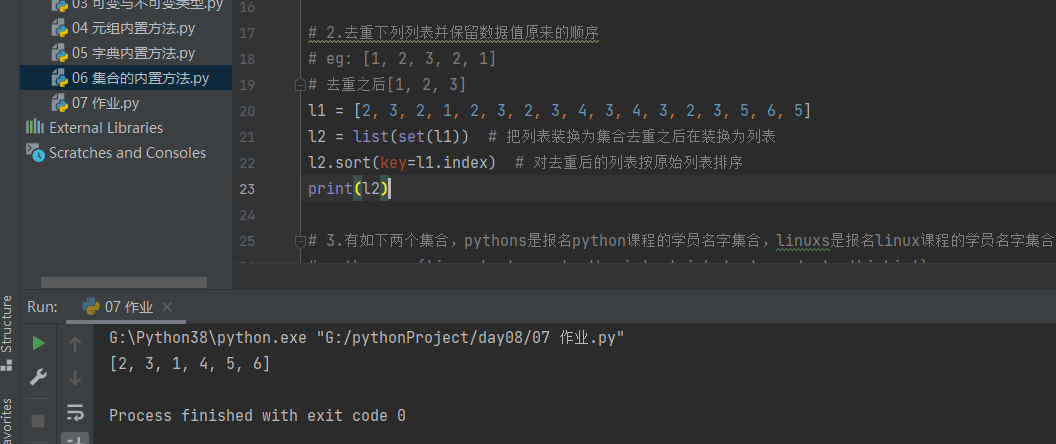
# 2.去重下列列表并保留数据值原来的顺序
# eg: [1, 2, 3, 2, 1]
# 去重之后[1, 2, 3]
l1 = [2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5]
l2 = list(set(l1)) # 把列表装换为集合去重之后在装换为列表
l2.sort(key=l1.index) # 对去重后的列表按原始列表排序
print(l2)
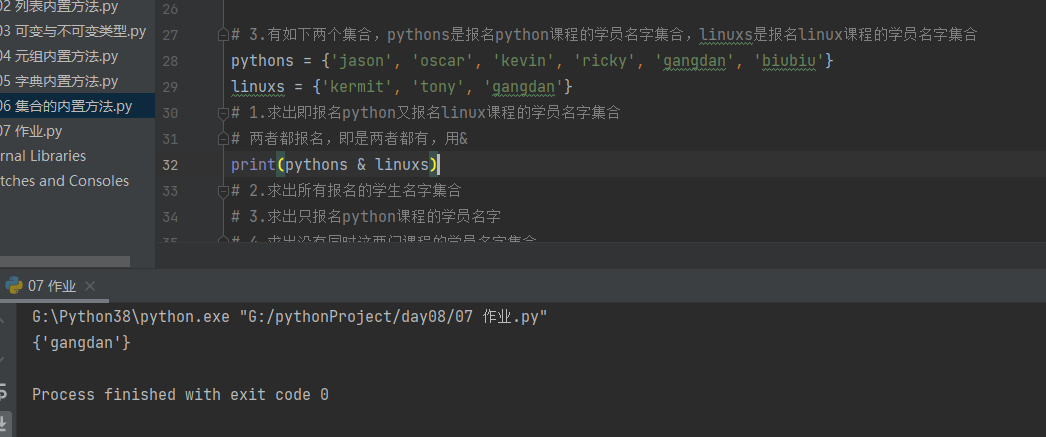
3.有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
linuxs = {'kermit', 'tony', 'gangdan'}
1.求出即报名python又报名linux课程的学员名字集合
print(pythons & linuxs)
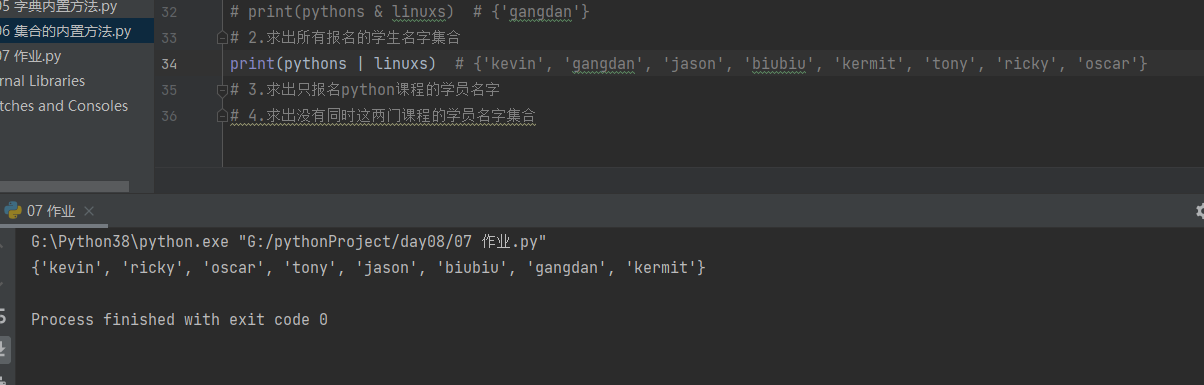
2.求出所有报名的学生名字集合
print(pythons | linuxs) # {'kevin', 'gangdan', 'jason', 'biubiu', 'kermit', 'tony', 'ricky', 'oscar'}
3.求出只报名python课程的学员名字
print(pythons - linuxs) # {'kevin', 'oscar', 'ricky', 'jason', 'biubiu'}

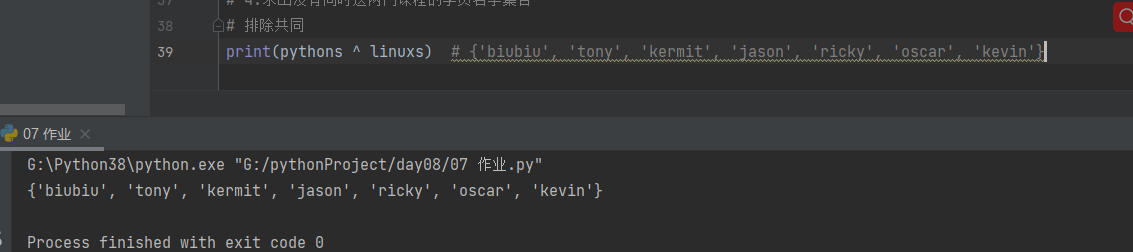
4.求出没有同时这两门课程的学员名字集合
print(pythons ^ linuxs) # {'biubiu', 'tony', 'kermit', 'jason', 'ricky', 'oscar', 'kevin'}
【python基础】第11回 数据类型内置方法 02的更多相关文章
- 【python基础】第09回 数据类型内置方法 01
本章内容概要 1.数据类型的内置方法简介 2.整型相关方法 3.浮点型相关方法 4.字符串相关方法 5.列表相关方法 本章内容详情 1.数据类型的内置方法简介 数据类型是用来记录事物状态的,而事物的状 ...
- python基础语法18 类的内置方法(魔法方法),单例模式
类的内置方法(魔法方法): 凡是在类内部定义,以__开头__结尾的方法,都是类的内置方法,也称之为魔法方法. 类的内置方法,会在某种条件满足下自动触发. 内置方法如下: __new__: 在__ini ...
- python for循环while循环数据类型内置方法
while 条件: 条件成立之后循环执行的子代码块 每次执行完循环体子代码之后都会重新判断条件是否成立 如果成立则继续执行子代码如果不成立则退出 break用于结束本层循环 ### 一:continu ...
- python基础操作以及其常用内置方法
#可变类型: 值变了,但是id没有变,证明没有生成新的值而是在改变原值,原值是可变类型#不可变类型:值变了,id也跟着变,证明是生成了新的值而不是在改变原值,原值是不可变 # x=10# print( ...
- python基础-字符串(str)类型及内置方法
字符串-str 用途:多用于记录描述性的内容 定义方法: # 可用'','''''',"","""""" 都可以用于定义 ...
- python循环与基本数据类型内置方法
今天又是充满希望的一天呢 一.python循环 1.wuile与else连用 当while没有被关键'break'主动结束的情况下 正常结束循环体代码之后会执行else的子代码 "" ...
- python常用数据类型内置方法介绍
熟练掌握python常用数据类型内置方法是每个初学者必须具备的内功. 下面介绍了python常用的集中数据类型及其方法,点开源代码,其中对主要方法都进行了中文注释. 一.整型 a = 100 a.xx ...
- python中其他数据类型内置方法
补充字符串数据类型内置方法 1.移除字符串首尾的指定字符可以选择方向1: s1 = '$$$jason$$$' print(s1.strip('$')) # jason print(s1.lstrip ...
- while.for循环和基本数据类型内置方法
while循环补充说明 流程控制之for循环 基本数据类型内置方法 内容详细 1.死循环 真正的死循环是一旦执行,Cpu的功耗会急速上升 知道系统采取紧急措施 所以 尽量不要让cpu长时间不断运算. ...
随机推荐
- 【LeetCode】567. 字符串的排列
567. 字符串的排列 知识点:字符串:滑动窗口 题目描述 给你两个字符串 s1 和 s2 ,写一个函数来判断 s2 是否包含 s1 的排列.如果是,返回 true :否则,返回 false . 换句 ...
- SSM整合_年轻人的第一个增删改查_基础环境搭建
写在前面 SSM整合_年轻人的第一个增删改查_基础环境搭建 SSM整合_年轻人的第一个增删改查_查找 SSM整合_年轻人的第一个增删改查_新增 SSM整合_年轻人的第一个增删改查_修改 SSM整合_年 ...
- 最新MATLAB R2020b超详细安装教程(附完整安装文件)
摘要:本文详细介绍Matlab R2020b的安装步骤,为方便安装这里提供了完整安装文件的百度网盘下载链接供大家使用.从文件下载到证书安装本文都给出了每个步骤的截图,按照图示进行即可轻松完成安装使用. ...
- Metalama简介4.使用Fabric操作项目或命名空间
使用基于Roslyn的编译时AOP框架来解决.NET项目的代码复用问题 Metalama简介1. 不止是一个.NET跨平台的编译时AOP框架 Metalama简介2.利用Aspect在编译时进行消除重 ...
- Vue过渡和动画效果展示(案例、GIF动图演示、附源码)
前言 本篇随笔主要写了Vue过渡和动画基础.多个元素过渡和多个组件过渡,以及列表过渡的动画效果展示.详细案例分析.GIF动图演示.附源码地址获取. 作为自己对Vue过渡和动画效果知识的总结与笔记. 因 ...
- ucore lab7 同步互斥机制 学习笔记
管程的设计实在是精妙,初看的时候觉得非常奇怪,这混乱的进程切换怎么能保证同一时刻只有一个进程访问管程?理清之后大为赞叹,函数中途把前一个进程唤醒后立刻把自己挂起,完美切换.后一个进程又在巧妙的时机将自 ...
- ONNXRuntime学习笔记(二)
继上一篇计划的实践项目,这篇记录我训练模型相关的工作. 首先要确定总体目标:训练一个pytorch模型,CIFAR-100数据集测试集acc达到90%:部署后推理效率达到50ms/张, 部署平台为wi ...
- 批量安装Windows系统
今天我们利用Windows server 2019自带的Windows部署服务通过网络批量安装Win 10 一.Windows服务 1)WDS WDS(Windows Deployment Servi ...
- 【Python情感分析】用python情感分析李子柒频道视频热门评论
一.事件背景 今天是2021.12.2日,距离李子柒断更已经4个多月了,这是我在YouTube李子柒油管频道上,观看李子柒2021年7月14日上传的最后一条视频,我录制了视频下方的来自全世界各国网友的 ...
- deepin安装jdk配置环境
下载一个jdk压缩包https://download.oracle.com/java/18/latest/jdk-18_linux-x64_bin.tar.gz 这个包,不用安装,下下来,直接解压,然 ...