一图看懂Hadoop中的MapReduce与Spark的区别:从单机数据系统到分布式数据系统经历了哪些?
今日博主思考了一个问题:Hadoop中的MapReduce与Spark他们之间到底有什么关系?
直到我看到了下面这张图
废话不多说先上图
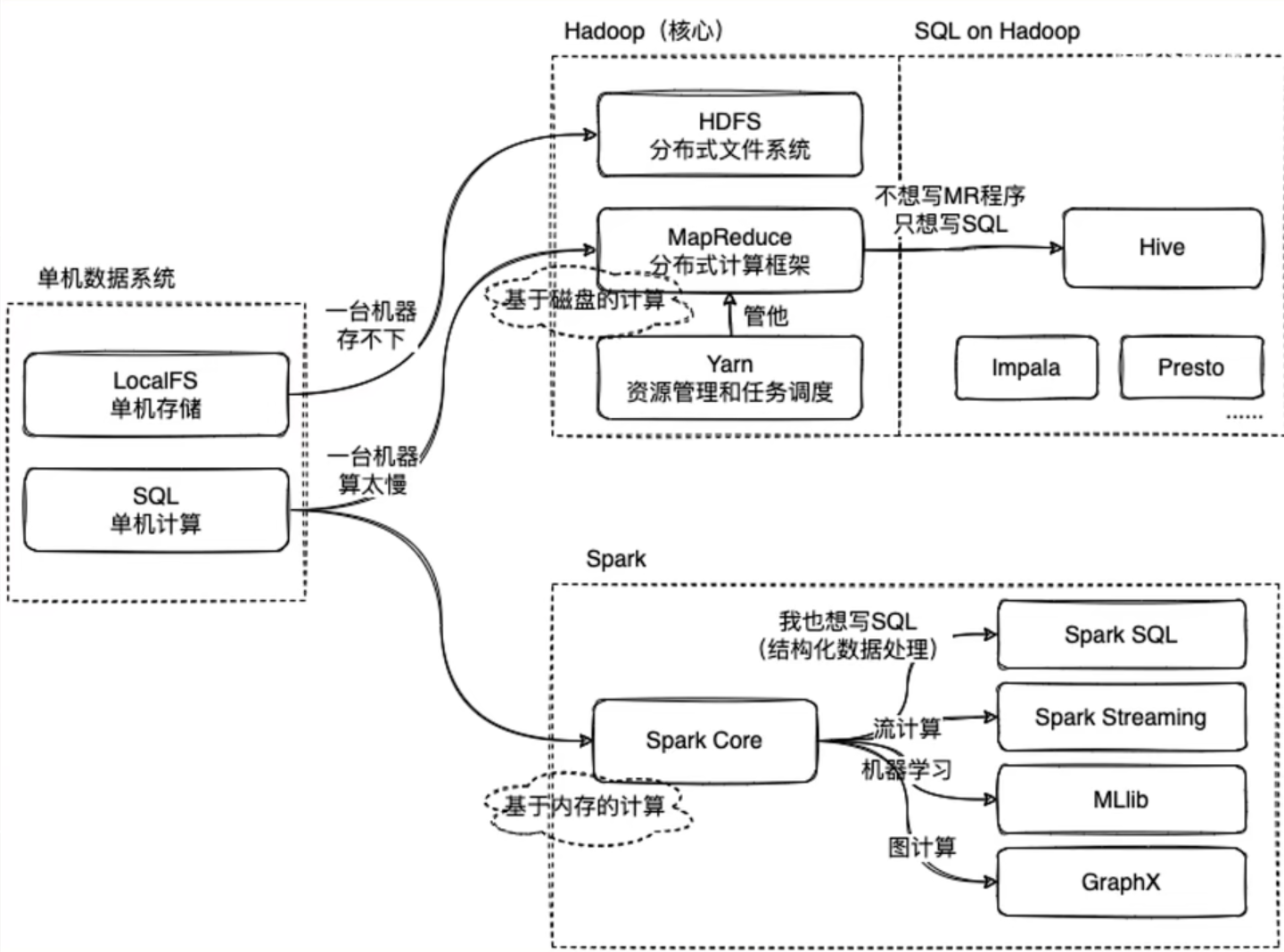
我们知道,单机数据系统,在本地主机上针对数据有单机本地存储操作(localFS)和单机计算操作(SQL)
这是在数据量比较小方便在一台主机就完成任务的情况。
那当我们的业务需要的数据足够大,一台机器完全应付不过来的时候应该怎么办?
我们很容易想到,既然一台机器办不到的事情,我们就交给10台机器、100台机器去办。
没错!
当我们的数据量足够庞大时,我们需要多台机器协同完成业务,此时我们就需要将数据一份份分成足够让一台机器能处理运行的小部分,布置给多台机器共同完成,这就是所谓的分布式数据系统
Hadoop就是为这样的业务场景服务的
Apache Hadoop是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架,有助于使用许多计算机组成的网络来解决数据、计算密集型的问题。基于MapReduce计算模型,它为大数据的分布式存储与处理提供了一个软件框架。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。————wikipedia
Apache Hadoop的核心模块分为存储和计算模块,前者被称为Hadoop分布式文件系统(HDFS),后者即MapReduce计算模型。Hadoop框架先将文件分成数据块并分布式地存储在集群的计算节点中,接着将负责计算任务的代码传送给各节点,让其能够并行地处理数据。这种方法有效利用了数据局部性,令各节点分别处理其能够访问的数据。与传统的超级计算机架构相比,这使得数据集的处理速度更快、效率更高。
其中HDFS分布式文件系统做到了利用多台机器的分布式文件存储,而MapReduce则实现了对数据的计算,而我们还需要一个对他们实现调度管理的“帮手”——Yarn
Mapreduce的实现需要自己编写计算框架,这很麻烦。
所以为什么不能有像单机数据系统的SQL一样方便的操作呢?
于是Hive就诞生了。
那,Spark又是怎么回事?
Spark对标的是Hadoop中的计算模块MapReduce,而一般情况下Spark会比MapReduce快2~3倍,
这是因为,MapReduce是基于磁盘的计算,而Spark是基于内存的计算。
而Spark中也有像Hive一样为了方便而诞生的只用写SQL语句就能完成数据处理的方式——Spark SQL
在Spark中还有一些格外的功能,例如针对机器学习使用的Spark MLib、针对流计算的Spark streaming以及针对图计算的Spark GraphX等等
以上就是Hadoop中的MapReduce与Spark 的区别,以及他们实现为了实现结构化数据处理进行的SQL实现。
一图看懂Hadoop中的MapReduce与Spark的区别:从单机数据系统到分布式数据系统经历了哪些?的更多相关文章
- 一图看懂hadoop分布式文件存储系统HDFS工作原理
一图看懂hadoop分布式文件存储系统HDFS工作原理
- 一图看懂hadoop MapReduce工作原理
MapReduce执行流程及单词统计WordCount示例
- 一张图看懂JavaScript中数组的迭代方法:forEach、map、filter、reduce、every、some
好吧,竟然不能单发一张图,不够200字啊不够200字! 在<JavaScript高级程序设计>中,分门别类介绍了非常多数组方法,其中迭代方法里面有6种,这6种方法在实际项目有着非常广泛的作 ...
- 一图看懂hadoop Spark On Yarn工作原理
hadoop Spark On Yarn工作原理
- 一图看懂hadoop Yarn工作原理
Hadoop 资源调度框架Yarn运行流程
- 一张图看懂AI、机器学习和深度学习的区别
AI(人工智能)是未来,是科幻小说,是我们日常生活的一部分.所有论断都是正确的,只是要看你所谈到的AI到底是什么. 例如,当谷歌DeepMind开发的AlphaGo程序打败韩国职业围棋高手Lee Se ...
- 一图看懂Spring获取对象与java new对象区别
Spring获取对象与java new对象的区别,图片被压缩了,请点击图片放大查看
- 一张图看懂ANSYS17.0 流体 新功能与改进
一张图看懂ANSYS17.0 流体 新功能与改进 提交 我的留言 加载中 已留言 一张图看懂ANSYS17.0 流体 新功能与改进 原创2016-02-03ANSYS模拟在线模拟在线 模拟在线 ...
- 一篇文章一张思维导图看懂Android学习最佳路线
一篇文章一张思维导图看懂Android学习最佳路线 先上一张android开发知识点学习路线图思维导图 Android学习路线从4个阶段来对Android的学习过程做一个全面的分析:Android初级 ...
- 一张图看懂开源许可协议,开源许可证GPL、BSD、MIT、Mozilla、Apache和LGPL的区别
一张图看懂开源许可协议,开源许可证GPL.BSD.MIT.Mozilla.Apache和LGPL的区别 首先借用有心人士的一张相当直观清晰的图来划分各种协议:开源许可证GPL.BSD.MIT.Mozi ...
随机推荐
- ProxySQL(10):读写分离方法论
文章转载自:https://www.cnblogs.com/f-ck-need-u/p/9318558.html 不同类型的读写分离 数据库中间件最基本的功能就是实现读写分离,ProxySQL当然也支 ...
- nacos基础知识理解
概念 Nacos是阿里巴巴开源的一款支持服务注册与发现,配置管理以及微服务管理的组件.用来取代以前常用的注册中心(zookeeper , eureka等等),以及配置中心(spring cloud c ...
- 通过堡垒机上传文件报错ssh:没有权限的问题
背景描述 一台有公网IP的主机安装的有jumpserver,假设为A主机,另外几台没有公网ip的主机,假设其中一个为B主机. 操作 1.通过主机A的公网IP和端口等登录到jumpserver的管理员用 ...
- Linux恢复误删除的文件或者目录
文章转载自:https://www.jianshu.com/p/662293f12a47 linux不像windows有个回收站,使用rm -rf *基本上文件是找不回来的. 那么问题来了: 对于li ...
- PVC-U排水管的断管与接管
1. PVC-U管的常用切割工具 2. PVC-U管的胶粘剂 3. 用胶粘剂粘接PVC-U管与管件
- SQL通用语法和SQL分类
SQL通用语法 1.SQL 语句可以单行或多行书写,以分号结尾 2.可使用空格和缩进来增强语句的可读性 3.MySQL 数据库的SQL语句不区分大小写,关键字建议使用大写 4.3种注释 单行注释: - ...
- C#-2 C#程序
一 C#程序是一组类型声明 C#程序或DLL的源代码是一组一种或多种类型声明. 对于可执行程序,类型声明中必须有一个包含Main方法的类. 命名空间是一种把相关的类型声明分组并命名的方法.是类在程序集 ...
- 媒介查询兼容各种端口的响应式范围取值(移动端、PC端、ipad、移动端侧屏)
!!!(chrome作者亲测)!!!数据仅供参考 /*ipad*/@media screen and (min-width:760px) and (max-width:1000px) /*移动端*/@ ...
- 关于Struts访问不到静态资源的问题
今天重新配置了Struts的项目进行开发,但是项目静态资源一直访问不到. 将一些静态资源放在WebRoot下的static包下面便于管理. 一开始以为采用拦截.do,只拦截do后缀的请求,解决了静态资 ...
- Period of an Infinite Binary Expansion 题解
Solution 简单写一下思考过程,比较水的数论题 第一个答案几乎已经是可以背下来的,在此不再赘述 考虑我们已经知道了\((p,q)\),其中\((p \perp q) \wedge (q \per ...