第十七天python3 文件IO(三)
CSV文件
csv是一个被行分隔符、列分隔符化分成行和列的文本文件;
csv不指定字符编码;
行分隔符为\r\n,最后一行可以没有换行符;
列分隔符常为逗号或者制表符;
每一行称为一条记录record
字段可以使用双引号括起来,也可以不使用;如果字段中出现了双引号、逗号、换行符必须使用双引号括起来。如果字段的值是双引号,使用两个双引号表示一个转义,表头可选,和字段列对齐即可;
from pathlib import Path
csv_body = """\
id,name,age,comment
1,zhang,18,"I`m 18"
2,wang,20,"Hello BeiJing"
3,li,23,"你好,计算机"
"""
p = Path('C:/Users/Sunjingxue/Downloads/test.csv')
p.parent.mkdir(parents=True,exist_ok=True)
p.write_text(csv_body)
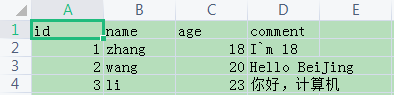
reader() 读取csv文件内容
import csv
csvname = "C:/Users/Sunjingxue/Downloads/test.csv"
with open(csvname) as f:
red = csv.reader(f)
print(red) #返回一个csv对象
for row in red:
#print(row) 返回一个列表
print(', '.join(row)) #返回结果
<_csv.reader object at 0x0000000001E2BC40>
id, name, age, comment
1, zhang, 18, I`m 18
2, wang, 20, Hello BeiJing
3, li, 23, 你好,计算机
#在python3.5.2环境下
In [1]: from pathlib import Path In [2]: import csv In [3]: p = Path('/root/test.csv') In [4]: with open(p) as f: #此时如果不将p转换成字符串类型,运行时会报错;
...: red = csv.reader(f)
...: for i in red:
...: print(i)
...:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-4-5e013681f47a> in <module>
----> 1 with open(p) as f:
2 red = csv.reader(f)
3 for i in red:
4 print(i)
5 TypeError: invalid file: PosixPath('/root/test.csv') In [5]: with open(str(p)) as f:
...: red = csv.reader(f)
...: for i in red:
...: print(i)
...:
['1', 'zhang', '18']
['2', 'wang', '19']
['3', 'li', '20']
#在python3.8.6环境下
from pathlib import Path
import csv
p = Path("C:/Users/Sunjingxue/Downloads/test.csv")
print(type(p))
with open(p) as f: #在3.8.6环境下则不需要将p转换成字符串类型;
re = csv.reader(f)
for i in re:
print(', '.join(i)) #并且re还是个生成器;可以用next()读取;print(next(re))
writer(csvfile,dialect='execl',**fmtparams) 返回DictWriter的实例
主要的方法有:
writerow() 读取1行
writerows() 读取多行
from pathlib import Path
import csv rows = [[4,'tom',22,'banana'],
(5,'jerry',24,'apple'),
(6,'lilei',25,'just\t"in'),
'abcdefg',
(('one','two'),('three','four'))
] row = ['序号','姓名','年龄','别名'] p = Path('C:/Users/Sunjingxue/Downloads/test.csv')
with open(p,'w',newline='') as f:
wr = csv.writer(f)
wr.writerow(row)
wr.writerows(rows)

从上面的例子可以看出,写入csv文件列表中的元素可以是列表,元组,字符串;在open()的时候,newline=‘ ’,如果不对换行符做处理,则每写一行就会加一行空白行(windows默认是\r\n),非常的影响观感;
ini文件处理
中括号里面的部分程为section,译作节、区、段;
每个section内,都是key=value形成的键值对,key称为option选项;
注意:这里的DEFAULT是缺省section的名字,必须大写;
#示例ini文件
[DEFAULT]
def = test [mysql]
my = True [mysqld]
datadir = /dbserver/data
port = 3306
character-set-server = urf8
sql_mode = NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
configparser模块
可以将section当做key,section存储这键值对组成的字典,可以把ini配置文件当做一个嵌套的字典,默认使用的是有序字典;
read(filenames,encoding=None) 读取ini文件,可以是单个文件,也可以是文件列表,可以指定文件编码;
sections() 返回section列表,缺省section不包括在内;
options(section) 返回section的所有option,会追加缺省的section的option;
has_option(section,options) 判断section是否存在这个option;
get(section,option,*,raw=False,vars=None[,fallback]) 从指定的段的选项上取值,如果找到返回,如果没有找到就去找DEFAULT端有没有;
getint(section,option,*,raw=False,vars=None[,fallback])
getfloat(section,option,*,raw=False,vars=None[,fallback])
getboolean(section,option,*,raw=False,vars=None[,fallback])
上面3个方法和get一样,返回指定类型数据;
from configparser import ConfigParser filename = 'C:/Users/Sunjingxue/Downloads/test.ini'
cfg = ConfigParser()
cfg.read(filename)
#打印所有section,不包括默认section;
print(cfg.sections())
#打印section的所有options,并且会追加默认section的option;
print(cfg.options('mysqld'))
#判断指定section中的指定option是否存在
print(cfg.has_option('mysqld','port'))
#判断section是否存在;
print(cfg.has_section('client'))
#从指定的section中取指定的option的值,如果不存在则去DEFAULT找,如果DEFAULT中没有则报错
print(cfg.get('mysqld','port'))
print(cfg.get('mysqld','def'))
#返回int类型的数值
print(cfg.getint('mysqld','port'))
#返回float类型的数值
print(cfg.getfloat('mysqld','port'))
#返回布尔值类型的数值
print(cfg.getboolean('mysql','my'))
#如果指定了section,则返回该section名和option,组成二元组;如果不指定seciton,则返回所有section的类;
#######################
返回结果:
['mysql', 'mysqld', 'China']
['datadir', 'port', 'character-set-server', 'sql_mode', 'def']
True
False
3306
test
3306
3306.0
True
items(raw=False,vars=None)
items(section,raw=False,vars=None)
没有section,则返回所有section名字及其对象,如果指定section,则返回这个指定的section的键值对组成二元组;
#如果指定了section,则返回该section名和option,组成二元组;如果不指定seciton,则返回所有section的类;
print(cfg.items('mysql'))
print(cfg.items())
for k,v in cfg.items():
print(k,type(v))
print(k,cfg.items(k)) #执行结果
[('def', 'test'), ('my', 'True')]
ItemsView(<configparser.ConfigParser object at 0x0000000001DF8FD0>)
DEFAULT <class 'configparser.SectionProxy'>
DEFAULT [('def', 'test')]
mysql <class 'configparser.SectionProxy'>
mysql [('def', 'test'), ('my', 'True')]
mysqld <class 'configparser.SectionProxy'>
mysqld [('def', 'test'), ('datadir', '/dbserver/data'), ('port', '3306'), ('character-set-server', 'urf8'), ('sql_mode', 'NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES')]
China <class 'configparser.SectionProxy'>
China [('def', 'test'), ('gansu', 'lanzhou'), ('shanxi', 'changan')]
add_section(section_name) 增加一个section;
set(section,option,value)
section存在的情况下,写入option=value,要求option、value必须是字符串;
remove_section(section) 移除section及其所有option;
remove_section(section,option) 移除section下的option;
write(fileobject,spece_around_delimiters=True) 将当前config的所有内容写入fileobject中,一般open函数使用w模式;
if cfg.has_section('China') == True:
pass
else:
cfg.add_section('China')
with open(filename,'w') as f:
cfg.set('China', 'gansu', 'lanzhou')
cfg.set('China', 'shanxi', 'changan')
cfg.write(f)
#通过字典操作修改ini文件中的值;
#cfg['section']['option'] = 'value'
#cfg['section'] = {'option' = 'value'}
cfg['mysqld']['port'] = '3308'
cfg['mysql'] = {'my':'False'}
#修改完成之后写入文件
with open(filename,'w') as f:
cfg.write(f)
执行结果:
第十七天python3 文件IO(三)的更多相关文章
- 第十五天python3 文件IO(一)
一.文件打开 open(path,flag[,encoding][,errors]) 参数说明: path:要打开文件的路径 flag:打开方式( r:以只读的方式打开文件,文件的描述符放在文件开头 ...
- 第十六天python3 文件IO(二)
BytesIO操作 io模块中的类 from io import BytesIO 内存中,开辟的一个二进制模式的buffer,可以像文件对象一样操作它: 当close方法被调用的时候,这个buffer ...
- (二) 一起学 Unix 环境高级编程 (APUE) 之 文件 IO
. . . . . 目录 (一) 一起学 Unix 环境高级编程 (APUE) 之 标准IO (二) 一起学 Unix 环境高级编程 (APUE) 之 文件 IO (三) 一起学 Unix 环境高级编 ...
- 三、文件IO——系统调用
3.1 文件描述符 文件IO 系统调用是不带缓存的,文件 I/O 系统调用不是 ANSI C 的组成部分,是 POSIX 的组成部分. 系统调用与C库: C库函数的IO 的底层还是调用系统调用 I/O ...
- 文件IO——将文件dfs的文件内容第三个字节之后的内容复制到文件dfd中
/* 使用文件IO将文件fds中的内容复制到文件fdd中去 1.创建两个文件描述符 2.使用open()方法分别以只读只写方式将文件描述符符文件连接 3.将读位置后移三位 4.将fds内容存储到缓冲区 ...
- 文件IO函数和标准IO库的区别
摘自 http://blog.chinaunix.net/uid-26565142-id-3051729.html 1,文件IO函数,在Unix中,有如下5个:open,read,write,lsee ...
- Java 文件IO续
文件IO续 File类 用来将文件和文件夹封装成对象 方便对文件和文件夹的属性信息进行操作 File对象可以作为参数传递给流的构造函数 Demo1 File的构造方法 public cla ...
- 文件IO操作
前言 本文介绍使用java进行简单的文件IO操作. 操作步骤 - 读文件 1. 定义一个Scanner对象 2. 调用该对象的input函数族进行文件读取 (参见下面代码) 3. 关闭输入流 说明:其 ...
- 文件IO
在unix世界中视一切为文件,无论最基本的文本文件还是网络设备或是u盘,在内核看来它们的本质都是一样的.大多数文件IO操作只需要用到5个函数:open . read . write . lseek 以 ...
随机推荐
- kali linux安装后乱码的解决方法
操作系统是5.3 解决方法是在终端执行命令: sudo apt-get install ttf-wqy-zenhei
- Cocos---大作业:简单H5小游戏
Cocos大作业:传统美食分分类 知识点清单: 场景切换,监听时间,碰撞组件及回调,拖动角色移动,分数记录,随机数和定时器,背景音乐控制,资源池控制,预制体,进度条... 源码+q:143144832 ...
- K8S 使用Kubeadm搭建单个Master节点的Kubernetes(K8S)~本文仅用于测试学习
01.集群规划 系统版本:CentOS Linux release 7.6.1810 (Core) 软件版本:kubeadm.kubernetes-1.15.docker-ce-18.09 硬件要求: ...
- 一文学完Linux常用命令
一.Linux 终端命令格式 1.终端命令格式 完整版参考链接:Linux常用命令完整版 command [-options] [parameter] 说明: command : 命令名,相应功能的英 ...
- 【单片机】CH32V103C8T6 ——窗口看门狗
本章教程通过串口调试助手打印显示程序运行状态,具体现象如下: 若计数器值在上窗口值和下窗口值0X40之间的时候,进行喂狗操作,计数器重新计数,程序正常运行,串口打印显示:The program run ...
- 如何用HMS Core位置和地图服务实现附近地点路径规划功能
日常出行中,路径规划是很重要的部分.用户想要去往某个地点,获取到该地点的所有路径,再根据预估出行时间自行选择合适的路线,极大方便出行.平时生活中也存在大量使用场景,在出行类App中,根据乘客的目的地可 ...
- 计算机网络 - HTTP和HTTPS的区别
计算机网络 - HTTP和HTTPS的区别 http所有传输的内容都是明文,并且客户端和服务器端都无法验证对方的身份. https具有安全性的ssl加密传输协议,加密采用对称加密. https协议需要 ...
- LoRa无线传输技术与LoRaWAN无线模块的区别
有不少人分不清LoRaWAN无线模块与LoRa网关无线传输技术到底有什么区别,他们在物联网领域的应用到底是什么样的. LoRaWAN指的是MAC层的组网协议,而LoRa是一个物理层的协议.虽然现有的L ...
- ffmpeg使用总结
2021-07-21 初稿 截图 ffmpeg -i <video> -ss <time> -vframes 1 <output_pic> 设置视频封面 ffmpe ...
- ABAP CDS-基础语法规则
The general syntax rules for the DDL and the DCL in ABAP CDS are: Keywords Keywords must be all uppe ...