最近公共祖先(LCA)学习笔记 | P3379 【模板】最近公共祖先(LCA)题解
研究了LCA,写篇笔记记录一下。
讲解使用例题 P3379 【模板】最近公共祖先(LCA)。
什么是LCA
最近公共祖先简称 LCA(Lowest Common Ancestor)。两个节点的最近公共祖先,就是这两个点的公共祖先里面,离根最远的那个。
—— 摘自 OI Wiki
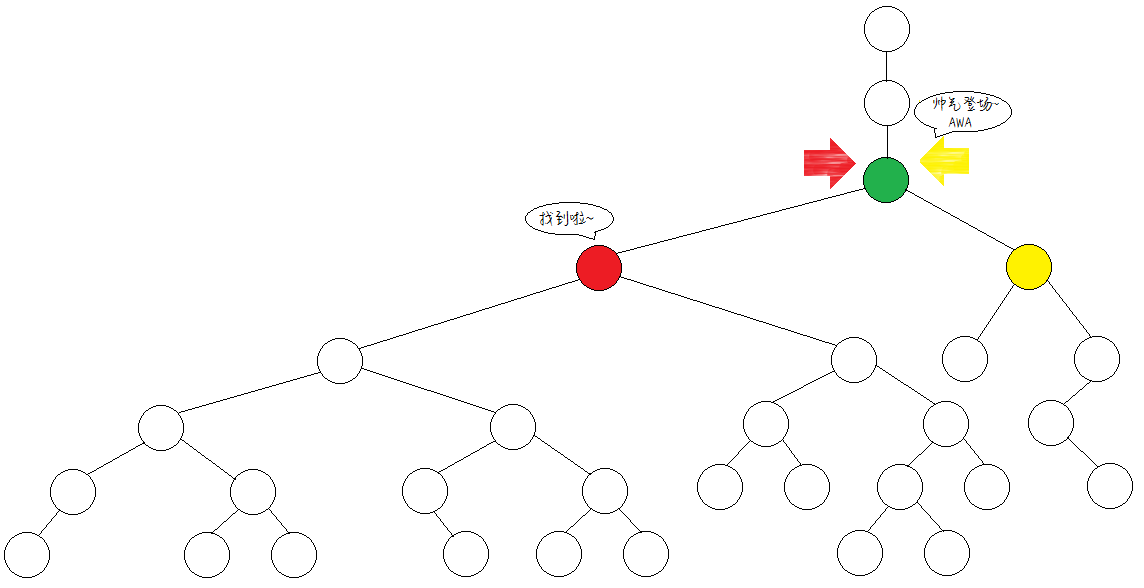
比如下图红、黄两点的LCA就是绿点。
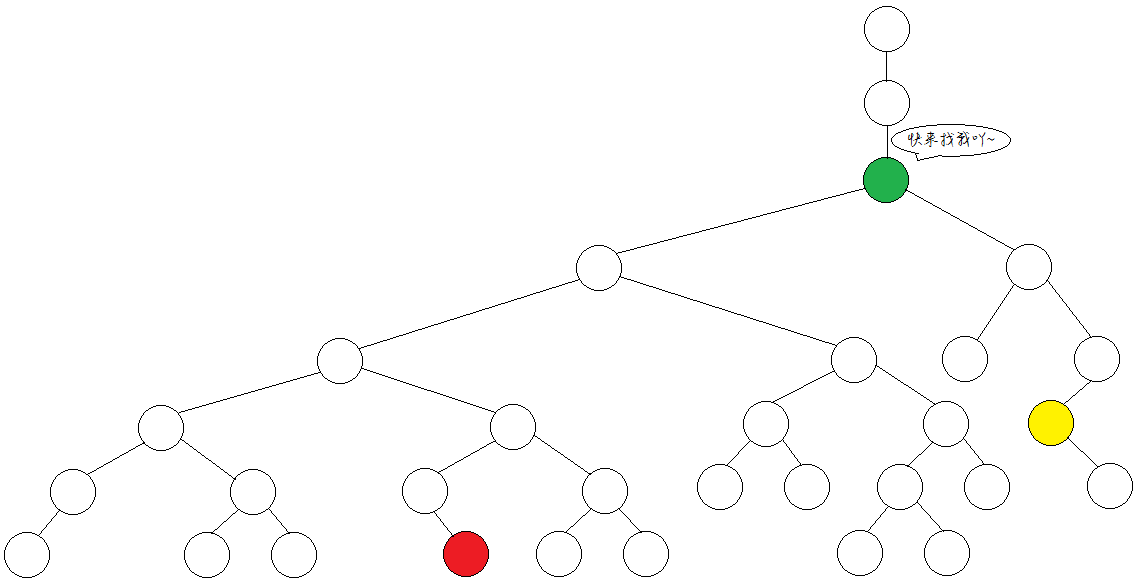
LCA的几种实现方式
向上标记法
从 x 点一直向上走直到到达根节点,在走的过程中标记所有经过的点。
从 y 点一直向根节点走,遇到的第一个标记过的点即为两点的LCA。
代码略
树上倍增法
首先,我们将要求、lca的两点跳到同一深度,如下图:
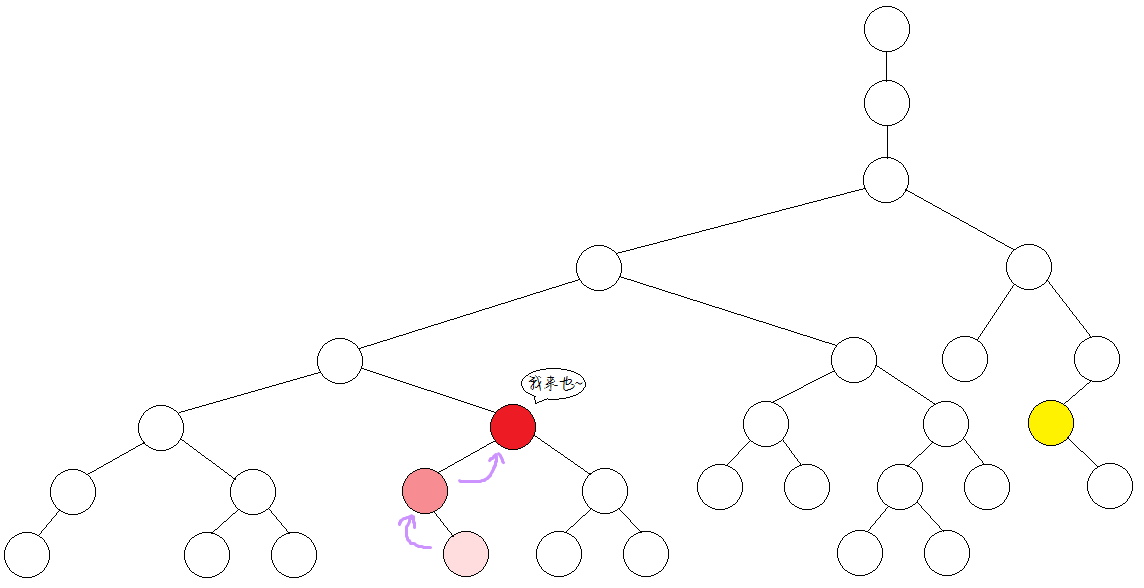
然后两点同时向上从大到小倍增,直到到的两点不相同,继续往上跳。
先尝试向能跳的最远处跳(4步)。
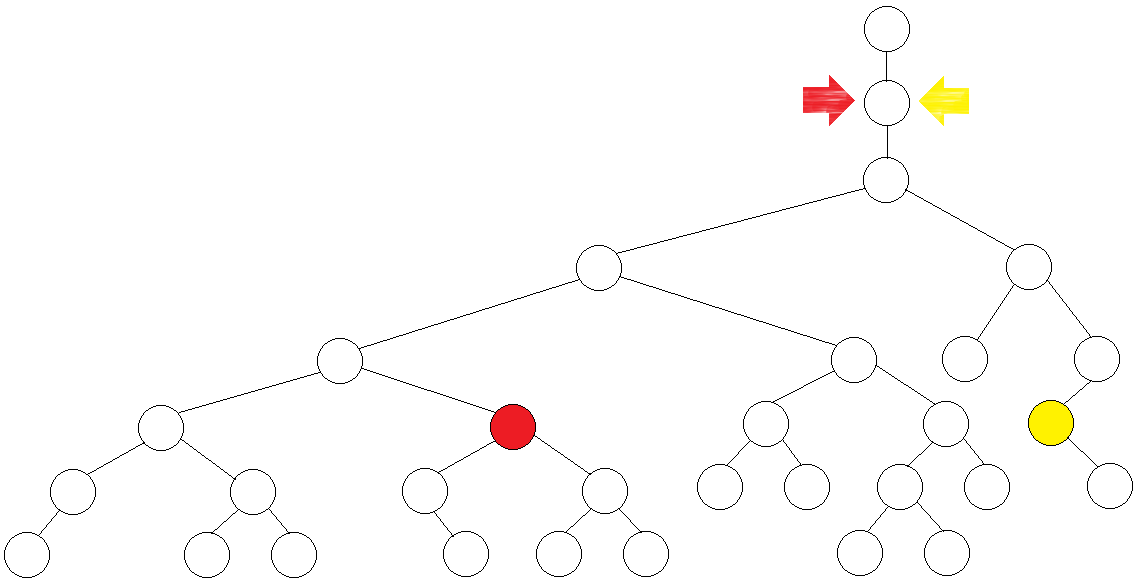
我们发现两个点在同处汇合,不行,考虑少跳一半(2步)。
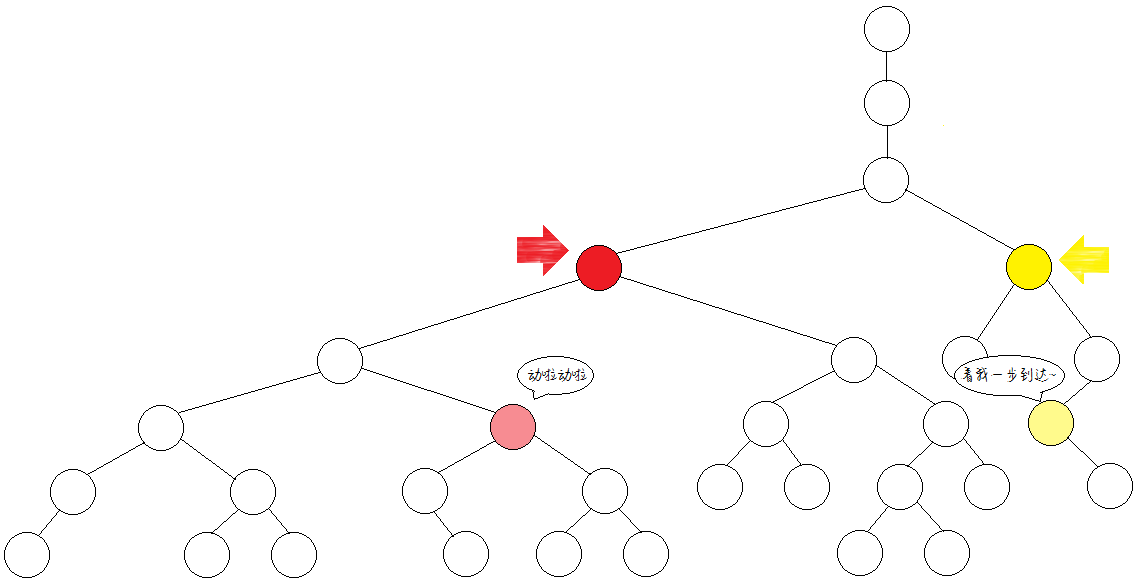
不同点,跳上。继续少跳一半(1步)。
同一个点,不跳。
此时,所有的跳跃尝试结束。由于目前两点不在同处,故再往上跳一步。
于是就找到这两个点的LCA啦!
(是不是讲的云里雾里的,结合代码理解一下吧~)
代码实现
- dfs获取每个点的深度
int p[N], dep[N];
void dfs(int x, int f) {
p[x] = f;
for (int i = last[x]; i; i = e[i].next) { //我用邻接表存的图
int v = e[i].to;
if (v == f) continue;
dep[v] = dep[x] + 1;
dfs(v, x);
}
}
dep[s] = 1;
dfs(s, s); //将起点的父节点设为自己,这样跳多了也不会出锅
- 预处理倍增跳到的点
for (int i = 1; i <= n; i++) f[0][i] = p[i];
for (int j = 1; j <= lg; j++) // 跳 2^j 步 lg 为 log2(n)
for (int i = 1; i <= n; i++) // 第 i 个点
f[j][i] = f[j - 1][f[j - 1][i]];
// 跳 2^j 步到的点即为先跳 2^(j-1) 步再跳 2^(j-1) 步到的点
- 处理LCA
(没有写成函数QAQ)
int a = read(), b = read();
if (dep[a] > dep[b]) swap(a, b); //使 a 的深度小于等于 b
for (int i = lg; i >= 0; i--)
if (dep[f[i][b]] >= dep[a]) b = f[i][b]; //将 a 与 b 跳到同一深度
for (int i = lg; i >= 0; i--) //从最远的距离开始尝试 (跳 2^i 步)
if (f[i][b] != f[i][a]) b = f[i][b], a = f[i][a]; //不是同一个点就跳上去
if (a != b) a = p[a];
//结束后不是同一个点,那么LCA就是目前这个点的父节点,所以也可以写成 b = p[b] 然后输出 b
printf("%d\n", a);
- 为什么尝试跳只用从 log2(n) 循环一遍到 0 就行?
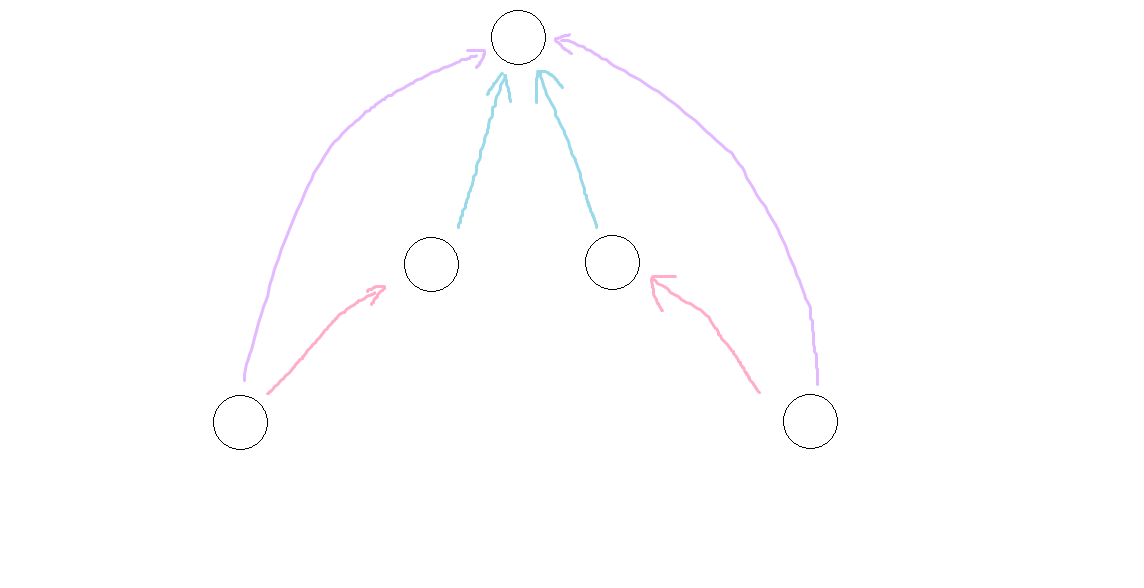
按照代码思路,我们会先尝试沿紫色路径跳 2^j 步,由于不成功,我们折半跳 2^(j-1) 步,沿粉边跳上。
此时若在沿蓝边跳 2^(j-1) 步,又跳到了原来粉边指向的点,我们已经知道那个点不行,所以不用尝试跳上,而应该继续尝试跳 2^(j-2) 步。
完整代码(点击查看)
#include<bits/stdc++.h>
using namespace std;
#define ll long long
inline ll read() {
ll s = 0, w = 1;
char ch = getchar();
while (ch < '0' || ch > '9'){if (ch == '-') w = -1; ch = getchar();}
while (ch >= '0' && ch <= '9'){s = (s << 3) + (s << 1) + (ch ^ 48); ch = getchar();}
return s * w;
}
const int N = 500010;
int n, m, s;
int last[N], cnt;
struct edge {
int to, next;
} e[N << 1];
void addedge(int x, int y) {
e[++cnt].to = y;
e[cnt].next = last[x];
last[x] = cnt;
}
int p[N], dep[N];
void dfs(int x, int f) {
p[x] = f;
for (int i = last[x]; i; i = e[i].next) {
int v = e[i].to;
if (v == f) continue;
dep[v] = dep[x] + 1;
dfs(v, x);
}
}
int f[19][N], lg;
int main() {
n = read(), m = read(), s = read();
lg = log2(n);
for (int i = 1; i < n; i++) {
int u = read(), v = read();
addedge(u, v), addedge(v, u);
}
dep[s] = 1;
dfs(s, s);
for (int i = 1; i <= n; i++) f[0][i] = p[i];
for (int j = 1; j <= lg; j++)
for (int i = 1; i <= n; i++)
f[j][i] = f[j - 1][f[j - 1][i]];
while (m--) {
int a = read(), b = read();
if (dep[a] > dep[b]) swap(a, b);
for (int i = lg; i >= 0; i--)
if (dep[f[i][b]] >= dep[a]) b = f[i][b];
for (int i = lg; i >= 0; i--)
if (f[i][b] != f[i][a]) b = f[i][b], a = f[i][a];
if (a != b) a = p[a];
printf("%d\n", a);
}
return 0;
}
LCA的Tarjan算法
本质来说,其实就是用并查集对“向上标记法”进行优化。
注意:操作是离线的。
从根节点开始进行 DFS,对于每个搜到的点打上标记,在回溯时将该结点并入其父节点的集合,具体操作见下。
- 如何离线?
我们先把 m 次询问都读入,然后再相关的两个结点上分别挂上询问。
- 为什么要两点都挂上询问
因为我们并不知道两个点谁先访问谁后访问,不好处理。
比如现在给一棵树,询问红、黄两点的 LCA 。
我们对这棵树进行 DFS,目前已经搜到了黄点,上方的三个不同深度的橙点表示 DFS 过程中栈里的点。
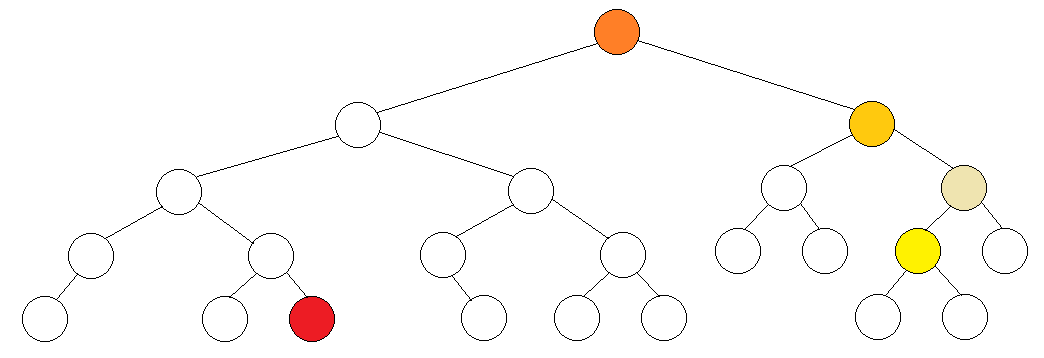
由于已经搜过了根节点的左子树,所以红点已打过标记。根节点的左子树与根节点属于一个集合,第二层的黄点的左子树与它自己属于一个集合。
现在在黄点上打个标记,发现黄点上挂的关于红点的询问可以处理了(两点都已搜到)。
红、黄两点的LCA即为红点所在集合的根节点,即图中树的根节点。
(讲的有亿点点乱诶)
代码实现
- 存储询问
struct node { //为了保证输出顺序,不仅要把询问挂在点上,还要额外存一下
int x, y, ans;
} ask[N];
vector <int> g[N]; //每个点上挂的询问
for (int i = 1; i <= m; i++) {
ask[i].x = read(), ask[i].y = read(), ask[i].ans = -1;
g[ask[i].x].push_back(i);
g[ask[i].y].push_back(i);
}
- DFS
int p[N];
bool vis[N]; //访问标记
int r[N]; //一个集合实际的根节点(并查集是按秩合并的,根节点不能保证是我们要的根节点)
void dfs(int x, int f) {
p[x] = f;
for (int i = last[x]; i; i = e[i].next) {
int v = e[i].to;
if (v == f) continue;
vis[v] = 1;
for (int j : g[v]) { //遍历所有询问
int o = ask[j].x;
if (o == v) o = ask[j].y;
if (!vis[o]) continue;
ask[j].ans = r[a.root(o)]; //记录询问答案
}
dfs(v, x);
a.merge(x, v); //合并两个集合
r[a.root(x)] = x; //标记实际根节点
}
}
vis[s] = 1;
dfs(s, s);
完整代码(点击查看)
#include<bits/stdc++.h>
using namespace std;
#define ll long long
inline ll read() {
ll s = 0, w = 1;
char ch = getchar();
while (ch < '0' || ch > '9'){if (ch == '-') w = -1; ch = getchar();}
while (ch >= '0' && ch <= '9'){s = (s << 3) + (s << 1) + (ch ^ 48); ch = getchar();}
return s * w;
}
const int N = 500010;
int n, m, s;
struct Disjoint_Set {
int p[N], size[N];
void build() {
for (int i = 1; i <= n; i++) p[i] = i, size[i] = 1;
}
int root(int x) {
if (p[x] != x) return p[x] = root(p[x]);
return x;
}
void merge(int x, int y) {
x = root(x), y = root(y);
if (size[x] > size[y]) swap(x, y);
p[x] = y;
size[y] += size[x];
}
bool check(int x, int y) {
x = root(x), y = root(y);
return x == y;
}
} a;
int last[N], cnt;
struct edge {
int to, next;
} e[N << 1];
void addedge(int x, int y) {
e[++cnt].to = y;
e[cnt].next = last[x];
last[x] = cnt;
}
struct node {
int x, y, ans;
} ask[N];
vector <int> g[N];
int p[N];
bool vis[N];
int r[N];
void dfs(int x, int f) {
p[x] = f;
for (int i = last[x]; i; i = e[i].next) {
int v = e[i].to;
if (v == f) continue;
vis[v] = 1;
for (int j : g[v]) {
int o = ask[j].x;
if (o == v) o = ask[j].y;
if (!vis[o]) continue;
ask[j].ans = r[a.root(o)];
}
dfs(v, x);
a.merge(x, v);
r[a.root(x)] = x;
}
}
int main() {
n = read(), m = read(), s = read();
a.build();
for (int i = 1; i <= n; i++) {
r[i] = i;
}
for (int i = 1; i < n; i++) {
int u = read(), v = read();
addedge(u, v), addedge(v, u);
}
for (int i = 1; i <= m; i++) {
ask[i].x = read(), ask[i].y = read(), ask[i].ans = -1;
g[ask[i].x].push_back(i);
g[ask[i].y].push_back(i);
}
vis[s] = 1;
dfs(s, s);
for (int i = 1; i <= m; i++) printf("%d\n", ask[i].ans);
return 0;
}
LCA转RMQ
先贴代码吧,讲解后续再补
咕咕咕
完整代码(点击查看)
#include<bits/stdc++.h>
using namespace std;
#define ll long long
inline ll read() {
ll s = 0, w = 1;
char ch = getchar();
while (ch < '0' || ch > '9'){if (ch == '-') w = -1; ch = getchar();}
while (ch >= '0' && ch <= '9'){s = (s << 3) + (s << 1) + (ch ^ 48); ch = getchar();}
return s * w;
}
const int N = 500010;
int n, m, s;
int last[N], cnt;
struct edge{
int to, next;
} e[N << 1];
void addedge(int x, int y) {
e[++cnt].to = y;
e[cnt].next = last[x];
last[x] = cnt;
}
int dep[N], a[N << 1], ed, fst[N];
void dfs(int x, int f) {
a[++ed] = x;
if (!fst[x]) fst[x] = ed;
for (int i = last[x]; i; i = e[i].next) {
int v = e[i].to;
if (v == f) continue;
dep[v] = dep[x] + 1;
dfs(v, x);
a[++ed] = x;
}
}
int f[21][N << 1], lg;
int main() {
n = read(), m = read(), s = read();
lg = log2(n) + 1;
for (int i = 1; i < n; i++) {
int x = read(), y = read();
addedge(x, y), addedge(y, x);
}
dep[s] = 1;
dfs(s, s);
for (int i = 1; i <= ed; i++) f[0][i] = i;
for (int j = 1; j <= lg; j++) {
for (int i = 1; i <= ed - (1 << j) + 1; i++) {
int i2 = i + (1 << (j - 1));
if (dep[a[f[j - 1][i]]] < dep[a[f[j - 1][i2]]]) f[j][i] = f[j - 1][i];
else f[j][i] = f[j - 1][i2];
}
}
for (int i = 1; i <= m; i++) {
int x = read(), y = read();
if (fst[x] > fst[y]) swap(x, y);
int len = fst[y] - fst[x] + 1, ans;
int lg2 = log2(len);
int i2 = fst[y] - (1 << lg2) + 1;
if (dep[a[f[lg2][fst[x]]]] < dep[a[f[lg2][i2]]]) ans = a[f[lg2][fst[x]]];
else ans = a[f[lg2][i2]];
printf("%d\n", ans);
}
return 0;
}
最近公共祖先(LCA)学习笔记 | P3379 【模板】最近公共祖先(LCA)题解的更多相关文章
- OpenCV 学习笔记(模板匹配)
OpenCV 学习笔记(模板匹配) 模板匹配是在一幅图像中寻找一个特定目标的方法之一.这种方法的原理非常简单,遍历图像中的每一个可能的位置,比较各处与模板是否"相似",当相似度足够 ...
- Python Flask学习笔记之模板
Python Flask学习笔记之模板 Jinja2模板引擎 默认情况下,Flask在程序文件夹中的templates子文件夹中寻找模板.Flask提供的render_template函数把Jinja ...
- poj1330 lca 最近公共祖先问题学习笔记
首先推荐两个博客网址: http://dongxicheng.org/structure/lca-rmq/ http://scturtle.is-programmer.com/posts/30055. ...
- Angular 5.x 学习笔记(1) - 模板语法
Angular 5.x Template Syntax Learn Note Angular 5.x 模板语法学习笔记 标签(空格分隔): Angular Note on github.com 上手 ...
- LCA学习笔记
写在前面 目录 一.LCA的定义 二.暴力法求LCA 三.倍增法求LCA 四.树链剖分求LCA 五.LCA典型例题 题目完成度 一.LCA的定义 LCA指的是最近公共祖先.具体地,给定一棵有根树,若结 ...
- 倍增求LCA学习笔记(洛谷 P3379 【模板】最近公共祖先(LCA))
倍增求\(LCA\) 倍增基础 从字面意思理解,倍增就是"成倍增长". 一般地,此处的增长并非线性地翻倍,而是在预处理时处理长度为\(2^n(n\in \mathbb{N}^+)\ ...
- LCA 学习算法 (最近的共同祖先)poj 1330
Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 20983 Accept ...
- 倍增LCA学习笔记
前言 "倍增",作为一种二进制拆分思想,广泛用于各中算法,如\(ST\)表,求解\(LCA\)等等...今天,我们仅讨论用该思想来求解树上两个节点的\(LCA\)(最近公共祖先 ...
- leetcood学习笔记-14*-最长公共前缀
笔记: python if not 判断是否为None的情况 if not x if x is None if not x is None if x is not None`是最好的写法,清晰,不 ...
随机推荐
- Blazor和Vue对比学习(基础1.7):传递UI片断,slot和RenderFragment
组件开发模式,带来了复用.灵活.性能等优势,但也增加了组件之间数据传递的繁杂.不像传统的页面开发模式,一个ViewModel搞定整个页面数据. 组件之间的数据传递,是学习组件开发,必须要攻克的难关.这 ...
- 详细剖析pyecharts大屏的Page函数配置文件:chart_config.json
目录 一.问题背景 二.揭开json文件神秘面纱 三.巧用json文件 四.关于Table图表 五.同步讲解视频 5.1 讲解json的视频 5.2 讲解全流程大屏的视频 5.3 讲解全流程大屏的文章 ...
- 最佳案例 | 游戏知几 AI 助手的云原生容器化之路
作者 张路,运营开发专家工程师,现负责游戏知几 AI 助手后台架构设计和优化工作. 游戏知几 随着业务不断的拓展,游戏知几AI智能问答机器人业务已经覆盖了自研游戏.二方.海外的多款游戏.游戏知几研发团 ...
- python将test01文件夹中的文件剪切到test02文件夹中
将test01文件夹中的文件剪切到test02文件夹中 import shutil import os def remove_file(old_path, new_path): print(old_p ...
- 使用docker创建和运行跨平台的容器化的mssql数据库
我们一般启用sql server数据库要么选择安装SQL Server实例和管理工具(SSMS),要么用vs自带的数据库.如今net跨平台成为趋势,今天给大家介绍另一种我最近在玩的方式,即使用dock ...
- 关于spring整合mybatis
第一步导入依赖 <dependencies> <dependency> <groupId>org.mybatis</groupId> <artif ...
- Abp Vnext源码解析系列文章01---EventBus
一.简介 BP vNext 封装了两种事件总线结构,第一种是 ABP vNext 自己实现的本地事件总线,这种事件总线无法跨项目发布和订阅.第二种则是分布式事件总线,ABP vNext 自己封装了一个 ...
- Kafka 负载均衡在 vivo 的落地实践
vivo 互联网服务器团队-You Shuo 副本迁移是Kafka最高频的操作,对于一个拥有几十万个副本的集群,通过人工去完成副本迁移是一件很困难的事情.Cruise Control作为Kafka的 ...
- 【题解】Codeforces Round #798 (Div. 2)
本篇为 Codeforces Round #798 (Div. 2) 也就是 CF1689 的题解,因本人水平比较菜,所以只有前四题 A.Lex String 题目描述 原题面 给定两个字符串 \(a ...
- React技巧之循环遍历对象
原文链接:https://bobbyhadz.com/blog/react-loop-through-object 作者:Borislav Hadzhiev 正文从这开始~ 遍历对象的键 在React ...