12. Fluentd部署:多Workers进程模式
介绍如何使用Fluentd的多worker模式处理高访问量的日志事件。此模式会运行多个worker进程以最大利用多核CPU。
- 原理
默认情况下,一个Fluentd实例会运行一个监控进程和一个工作进程。工作进程包含了Input/Filter/Output各类插件。
多worker模式就是一个实例中启动了多个工作进程,这些工作进程负责处理日志事件,接受监控进程的管理和调度。如下图所示:
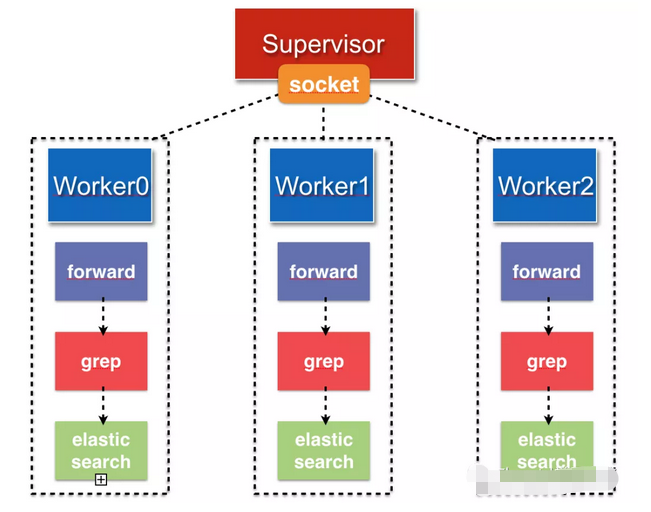
Fluentd提供了一些特性以支持多worker模式,我们通过配置就能方便地使用这些特性。
- 配置
2.1 workers参数
可在中设置工作进程的数目。
<system>
workers 4
</system>
2.2 指令
有些插件不支持在多worker上运行,比如tail。
对这类插件,我们可通过<worker N>指定其在哪个worker上运行。
N代表worker的索引,起始为0.
<system>
workers 4
</system>
# work on multi process workers. worker0 - worker3 run in_forward
<source>
@type forward
</source>
# work on only worker 0. worker1 - worker3 don't run in_tail
<worker 0>
<source>
@type tail
</source>
</worker>
# <worker 1>, <worker 2> or <worker 3> is also ok
这个例子中,启动了4个工作进程。tail插件被放置在<worker 0>中,表明tail只运行在索引为0的工作进程上。
这种配置可以混合使用多进程插件和单进程插件。
2.3 指令
Fluentd v1.4.0开始支持<worker N-M>指令。这个很容易理解。
N-M代表工作进程索引范围,指定了插件可以运行在哪些工作进程中。
<system>
workers 6
</system>
<worker 0-1>
<source>
@type forward
</source>
<filter test>
@type record_transformer
enable_ruby
<record>
worker_id ${ENV['SERVERENGINE_WORKER_ID']}
</record>
</filter>
<match test>
@type stdout
</match>
</worker>
# work on worker 0 and worker 1.
<worker 2-3>
<source>
@type tcp
<parse>
@type none
</parse>
tag test
</source>
<filter test>
@type record_transformer
enable_ruby
<record>
worker_id ${ENV['SERVERENGINE_WORKER_ID']}
</record>
</filter>
<match test>
@type stdout
</match>
</worker>
# work on worker 2 and worker 3.
<worker 4-5>
<source>
@type udp
<parse>
@type none
</parse>
tag test
</source>
<filter test>
@type record_transformer
enable_ruby
<record>
worker_id ${ENV['SERVERENGINE_WORKER_ID']}
</record>
</filter>
<match test>
@type stdout
</match>
</worker>
# work on worker 4 and worker 5.
2.4 root_dir/@id参数
使用文件作为buffer时,需要配置这几个参数。
在多worker模式中,不能指定固定的path作为文件buffer,因为这会不同进程中引起冲突。
<system>
workers 2
</system>
<match pattern>
@type forward
<buffer>
@type file
path /var/log/fluentd/forward # This is not allowed
</buffer>
</match>
Fluentd提供了基于root_dir和@id的动态path配置,实际的buffer路径为:${root_dir}/worker${worker index}/${plugin @id}/buffer
<system>
workers 2
root_dir /var/log/fluentd
</system>
<match pattern>
@type forward
@id out_fwd
<buffer>
@type file
</buffer>
</match>
- 操作
每个worker使用单独的内存和磁盘空间,因此需要仔细配置缓存空间,并对内存和磁盘使用情况做好监控。
12. Fluentd部署:多Workers进程模式的更多相关文章
- Linux Rsync备份服务介绍及部署守护进程模式
rsync介绍 rsync是一款开源的.快速的.多功能的.可实现全量及增量的本地或远程数据同步备份工具 在常驻模式(daemon mode)下,rsync默认监听TCP端口873,以原生rsync传输 ...
- 10. Fluentd部署:高可用配置
对于高访问量的web站点或者服务,可以采用Fluentd的高可用配置模式. 消息分发语义 Fluentd设计初衷主要是用作事件日志分发系统的.这类系统支持几种不同的分发模式: 至多一次.消息被立即发送 ...
- Flink 集群运行原理兼部署及Yarn运行模式深入剖析
1 Flink的前世今生(生态很重要) 原文:https://blog.csdn.net/shenshouniu/article/details/84439459 很多人可能都是在 2015 年才听到 ...
- 在nginx上部署vue项目(history模式)--demo实列;
在很早之前,我写了一篇 关于 在nginx上部署vue项目(history模式) 但是讲的都是理论,所以今天做个demo来实战下.有必要让大家更好的理解,我发现搜索这类似的问题还是挺多的,因此在写一篇 ...
- suse 12 编译部署Keepalived + nginx 为 kube-apiserver 提供高可用
文章目录 编译部署nginx 下载nginx源码包 编译nginx 配置nginx.conf 配置nginx为systemctl管理 分发nginx二进制文件和配置文件 启动kube-nginx服务 ...
- suse 12 二进制部署 Kubernetets 1.19.7 - 第05章 - 部署kube-nginx
文章目录 1.5.部署kube-nginx 1.5.0.下载nginx二进制文件 1.5.1.编译部署nginx 1.5.2.配置nginx.conf 1.5.3.配置nginx为systemctl管 ...
- suse 12 二进制部署 Kubernetets 1.19.7 - 第07章 - 部署kube-controller-manager组件
文章目录 1.7.部署kube-controller-manager 1.7.0.创建kube-controller-manager请求证书 1.7.1.生成kube-controller-manag ...
- suse 12 二进制部署 Kubernetets 1.19.7 - 第10章 - 部署kube-proxy组件
文章目录 1.10.部署kube-proxy 1.10.0.创建kube-proxy证书 1.10.1.生成kube-proxy证书和秘钥 1.10.2.创建kube-proxy的kubeconfig ...
- Fluentd部署详解
Fluentd系统配置项 https://www.cnblogs.com/sanduzxcvbnm/p/13920972.html Fluentd自身日志 https://www.cnblogs.co ...
随机推荐
- SpringBoot接口 - 如何生成接口文档之非侵入方式(通过注释生成)Smart-Doc?
通过Swagger系列可以快速生成API文档,但是这种API文档生成是需要在接口上添加注解等,这表明这是一种侵入式方式: 那么有没有非侵入式方式呢, 比如通过注释生成文档? 本文主要介绍非侵入式的方式 ...
- Linux下IPC之共享内存的使用方法
基本参考 <Unix环境高级编程>第14.9节共享内存来学习. 参考blog:https://blog.csdn.net/weixin_45794138/article/details/1 ...
- nginx反向代理缓存配置
关于nginx的反向代理缓存配置,用的最多的就是CDN公司,目前CDN公司用纯nginx做缓存的已经很少了,基本都用tnginx(阿里的).openresty:但是这两款软件都是基于nignx开发的, ...
- 定时脚本删除docker容器中内容
今天在我同步mongo数据库的时候,服务器的磁盘突然就被占满了导致同步中断,mongo容器也停止工作了.然后就想要弄一个能够定时清理同步过程中留存在docker容器中的mongo数据的脚本.话不多说, ...
- 关于奇妙的 Fibonacci 的一些说明
奇妙的 Fibonacci,多次模拟赛中出现 同时也是 BZOJ 2813 一 Fibonacci 的 GCD 如果 \(F\) 是 Fibonacci 数列,那么众所周知的有 \(\gcd(F_i, ...
- (一)、数字图像处理(DIP)
1.什么是图像? 图像是人类视觉的基础,是自然景物的客观事实,是人类认识世界和人类本身的重要源泉:也可以说图像是客观对象的一种表示. '图'是物体反射或透射光的分布:'像'是人的视觉系统所接受的图,在 ...
- MMDetection 使用示例:从入门到出门
前言 最近对目标识别感兴趣,想做一些有趣目标识别项目自己玩耍,本来选择的是 YOLOV5 的,但无奈自己使用 YOLOV5 环境训练模型时,不管训练多少次 mAP 指标总是为 0,而其它 pytorc ...
- Luogu2869 [USACO07DEC]美食的食草动物Gourmet Grazers (贪心,二分,数据结构优化)
贪心 考场上因无优化与卡常T掉的\(n \log(n)\) //#include <iostream> #include <cstdio> #include <cstri ...
- Linux 10 安装JDK
参考源 https://www.bilibili.com/video/BV187411y7hF?spm_id_from=333.999.0.0 版本 本文章基于 CentOS 7.6 这里使用 rpm ...
- 如何自定义一个Collector
Collectors类提供了很多方便的方法,假如现有的实现不能满足需求,我们如何自定义一个Collector呢? Collector接口提供了一个of方法,调用该方法就可以实现定制Collecto ...