从C过渡到C++——换一个视角深入数组[初始化](1)
从C过渡到C++——换一个视角深入数组[初始化](1)
数组的初始化
我一直很迷惑一个问题,就是到底在哪些地方的进行数组的初始化可以直接将数组的内容全部置为0呢?这样的情况在C和C++中有不一样吗?要测试这个内容我们要首先要理解变量的作用域、链接属性、还有存储类型。
从C入手
作用域
当变量在程序某个部分被声明的时候,他只有在程序的一定区域内才能被访问。这个区域由标识符的作用域决定。标识符的作用域就是程序中该标识符可以被使用的区域。
C的编译器可以确认四种不同类型的作用域:
- 文件作用域
- 函数作用域
- 代码块作用域
- 原型作用域
标识符声明的位置决定了它的作用域。
我们来看下面一段程序:
int a;//作用域1
int b ( int c/*作用域3*/);//作用域2
int d(int e/*作用域5*/)//作用域4
{
int f;//*作用域6*/——代码块作用域
int g (int h/*作用域8*/);//*作用域7*/——代码块作用域
{
int f,g,i;//*作用域9*/——代码块作用域
}
{
int i;//*作用域10*/——代码块作用域
}
}
代码块作用域
上述代码中一共包含了10个作用域,其中6、7、9、10作用域就是代码块作用域,当代码块处于嵌套的时候,声明于内层的代码块的标识符的作用域结束于代码块的尾部,也就是},需要特别注意的是:
内层的标识符与外层标识符相同的时候内层的标识符就会将外层的标识符隐藏起来,也就是说,对于作用域6的f和作用域9的f,这两者代表的是不同的变量。前者在内层代码块中是无法访问的。
对于代码块作用域我们只需要知道每一个代码块中变量都是独立的,每个代码块作用域互相并不关联,代码块作用域会屏蔽其他被嵌套的作用域。
文件作用域
任何在所有代码块之外的声明的标识符都是处于文件作用域,他表示这些标识符从他们的声明之处直到现在所在的源文件结尾处都是可以访问的。上文中的作用域1和作用域2都是文件作用域的例子。眼尖的你也会注意的作用域4也具有文件作用域,因为函数名本身并不包含在任何代码块。
这里需要注意的点是某些在头文件中编写并通过#include指令包含到其他文件中的声明就好像他们直接写在那些文件中一样,他们的作用域不局限于头文件的文件尾部。
原型作用域
原型作用域中的原型指的是函数声明的原型参数,如上文中的作用域3和作用域8所示,在原型中(与函数的定义不相同)参数的名字并不是一定需要的。但是如果出现参数名,则可以给他们取任何名字,他们不必与函数定义中的参数名相匹配,也不必与传递的实际参数名相同,原型作用域防止这些参数名和程序其他部分名字冲突。
事实上,唯一可能出现的冲突就是在同一个原型中不止一次使用同一个名字。
函数作用域
最后一种作用域类型是函数作用域。它只适用于语句标签,语句标签用于goto语句,这里不介绍仔细,概括为一个函数中的所有语句标签必须唯一,强烈不建议大家在自己的程序中使用goto语句。
链接属性
当一个程序的各个源文件被分别编译以后,所有的目标文件以及那些从一个或者多个库函数中引用的函数连接在一起,形成可执行文件。这也是上一小节说的include,然而这会造成一个问题就是相同的标识符出现在几个不同的文件中,他们表示的是同一块内存吗?还是说每一个都是独立的呢?这就是标识符的链接属性要决定的内容,标识符的作用域与他的链接属性有关,但这两个属性并不相同,经常会有人把这两个属性混为一谈。
链接属性包含三种:
- 外部external
- 内部internal
- 无none
当你的标识符的链接属性是none的时候他总是被当作单独的实体,也就是说该标识符的多个声明被当作不同的独立实体。
属于internal链接属性的标识符在同一个源文件内的所有声明都属于同一个实体,但位于不同源文件的多个声明则分别属于不同的实体。
external链接属性的标识符无论声明多少次,位于几个源文件都表示同一个实体。
下面的代码展示了不同链接属性的声明:
typedef char *a;/*链接属性声明1*/
int b;/*链接属性声明2*/
int c/*链接属性声明3*/(int d)/*链接属性声明4*/
{
int e;/*链接属性声明5*/ none
int f(int g);/*链接属性声明6*/
}
在缺省情况下,标识符b、c、f的链接属性为external,其余所有的标识符链接属性为none。因此如果另一个源文件中也包含了b的类似声明并调用函数c,他们实际上访问的是这个源文件中定义的实体。f的链接属性之所以是external,是因为它是一个函数,在理的声明所指向的实际上是其他源文件所定义的函数,甚至这个函数定义可能出现在某一个函数库中。
总结一下,缺省情况下除了typedef声明在文件作用域的都是external。声明在代码块中的除了函数都是none。
改变链接属性的关键字
在了解基本的连接属性以后,我们来看一看关键字如何改变链接属性。
有两个关键字可以改变连接属性,分别是:extenal和static。
static
如果某个声明在正常情况下具有external链接属性,在她前面加上static关键字就可以使他的链接属性变为internal。例如如果将b更改为如下:
static int b
这样变量b不仅可以获得internal的链接属性也可以获得文件作用域。防止这个变量被其他文件所引用。
类似的如果这个函数不想被其他函数所调用,也可以把函数声明如下:
static int c/*链接属性声明3*/(int d)/*链接属性声明4*/
需要注意的是static关键字不仅可以作用于改变连接属性为external至internal同时也可以改变变量存储类型,这是我们需要注意的打个比方,如下所示:
static int e;/*链接属性声明5*/
这样的声明并不是改变其链接属性,因为其默认的连接属性不是external,这里改变的其存储类型,至于什么是存储上类型这个我们晚一点再说,先知道这里改变的对象并不相同。
external
external关键字相对来说就有些复杂了,他为一个标识符指定external链接属性,这样就可以访问在其他任何位置定义的这个实体,一般而言extrenal关键字针对的是声明变量,对于定义在文件作用域的变量,默认是就是external链接属性。
下面的例子充分展示了如何修改链接属性。
static int i;
int func()
{
int j;
extern int k;
extern int i;
}
如上的代码,变量k使用了extern关键字,将链接属性更改为了external,这样一来函数内的k就可以访问其他源文件的k变量了。
特别注意
你如果仔细看,会发现变量i在两个地方分别被修改了链接属性,但实际上链接属性只有第一次声明指定的链接属性才会起效。也就是说此时i的连接属性是internal。
存储类型
上文的所有内容都是为了存储类型进行铺垫,变量的存储类型是指的内存类型。变量的存储类型决定变量何时创建、何时销毁以及它的值将保存多久。有三个地方可以用于存储变量:普通内存、运行时堆栈、硬件寄存器,在这三个地方的变量各自拥有不同的特性。
静态变量
变量的缺省存储类型取决于它的声明位置。凡是在任何代码块之外的变量总是存储于静态内存之中,也就是不属于堆栈的内存,这类变量我们通常使用static来修饰,对于这类变量,无法为他们指定其他存储类型。静态变量在程序运行之前创建,在程序整个执行期间始终存在。
自动变量
在代码块内部声明的变量的缺省类型是自动的,也就是说他存储于堆栈之中,称为自动变量,有一个我们不常见的关键字auto就是这种类型,自动变量随着代码块运行结束自动进行销毁,如果变量在函数中进行初始化当这部分代码块的语句再次运行的时候,这些变量就会重新进行初始化等一系列操作,可以说这部分变量完全和上一次运行毫无关系。
寄存器变量
寄存器变量提示机器这些变量应该存储于寄存器而不是内存中,通常,寄存器变量比存储于内存的变量访问效率要高一点,但是编译器不一定理睬他的定义关键字register,如果有太多的变量被声明为register,他只选择前几个实际存储于寄存器中,其余就按auto变量进行处理。
寄存器变量是一个很复杂的特殊类型,用不好就会导致使用起来效率还没有一般auto高,这就导致了一个很尴尬的问题,什么时候使用register效率会更高呢?简单来说一般情况下,在访问频率比较高的变量中使用register比较合适,但是多高算高呢?这里就不再详细介绍,重点不在这里,有兴趣的可以Google一下。
改变变量存储类型的关键字
static
很有意思的是,static关键字不仅可以用于修改变量的链接属性也可以用于修改变量的存储类型,这是C的特性,同一个关键字因为所处的上下文的不同而产生不同的作用,对于在代码块内部声明的变量,如果给它加上关键字static,可以使它的存储类型从自动变量变为静态变量,具有静态存储类型的变量在整个程序的执行过程中一直存在,而不仅仅在声明它的代码块执行的时候存在。注意,修改变量的存储类型,并不代表修改了其作用域,他仍然只能在代码块中按名字访问,其他地方无法访问,下面的代码展示了如何进行修改:
int test()
{
static int test;
}
变量的初始化与static的联系
现在让我们把话题转移回到针对变量的初始化之上。同时根据变量存储类型的不同对变量的初始化进行探讨。
自动类型变量和静态变量的重要差别就在于,在静态变量的初始化中,我们可以把可执行程序想要初始化的值放在程序执行的时候变量要使用的位置。当可执行程序载入到内存的时候,这个已经保存了正确初始值的位置将赋值给那个变量,完成这个任务并不需要额外的指令和时间,变量将会得到正确的值。如果不显式初始化,静态变量将初始化为0。
自动变量初始化需要更多的开销,因为程序链接的时候还无法判断变量的存储位置。事实上,函数的局部变量在函数的每次调用中都可能占据不同的位置,基于这个理由,自动变量没有缺省初始值,而显式的初始化将在代码的起始处插入一条隐式的赋值语句,注意这里需要明确区分开赋值语句和初始化语句的区别。
我们举个例子,把对应的代码反编译成为汇编代码看一看。
这里简单说一下如何利用GCC进行反汇编处理,看看汇编的代码都包含些什么:
c的代码如下:
#include<stdio.h>
int main(){
static int sta_var;
int auto_var;
auto_var++;
}
汇编代码如下:
call __main
add DWORD PTR -4[rbp], 1
mov eax, 0
add rsp, 48
pop rbp
ret
.seh_endproc
.lcomm sta_var.0,4,4
.ident "GCC: (Rev3, Built by MSYS2 project) 12.1.0"
我们可以看到如果没有添加自动变量初始化的汇编,是不对变量进行任何初始化操作的。只有add DWORD PTR -4[rbp], 1其实就是对变量auto_var进行了+1的操作。
那你会问我的静态变量呢?我静态变量的定义呢?
.lcomm sta_var.0,4,4
就是对静态变量的定义,这就涉及一点更深层次的内容了,我们简单来说一下,.lcomm为一个有符号表示的变量预留一定的长度,这里就是为sta_var.0 预留一个int的长度,也就是4。但是为什么说默认静态变量不初始化为0也是0呢?这要就考虑到.lcomm 实际预留的区域了,.lcomm 预留的内容被分配在bss部分,所以在运行时字节开始为零。
块起始符号(缩写为.bss或bss)是对象文件、可执行文件或汇编语言代码中包含静态分配的变量的部分,这些变量已被声明但尚未被赋值。它通常被称为 "bss部分 "或 "bss段"。
通常情况下,只有bss段的长度,而没有数据,被存储在对象文件中。程序加载器在加载程序时为bss部分分配了内存。通过将没有数值的变量放在.bss部分,而不是放在需要初始值数据的.data或.rodata部分,可以减少对象文件的大小。
在一些平台上,部分或全部的bss部分被初始化为零。Unix-like系统和Windows将bss部分初始化为零,允许将C和C++静态分配的变量初始化为所有比特为零的值,并放入bss段中。
这就是真实的原因。为什么不用初始化数据就是为0。
你可能会去尝试输出这里的auto_var的大小,你会发现还是1,不应该是随机的吗?按照上文叙述,这里不因该是一个随机的值吗?
你不用慌张相信我讲的没问题,并尝试理解一下以下下边的代码:
#include<stdio.h>
void test()
{
int auto_var;
printf("%d",auto_var);
auto_var=999;
}
int main(){
static int sta_var;
test();
test();
}
我在这里调用了两次test,根据函数调用的栈结构,两次所占用的空间应该是同一片空间,所以这里的auto_var的内存指向也应该是相同的,我们在第一次调用的时候将他输出完之后设定一个值,然后再次输出,你会发现,两次结果并不一样,实际上上边输出0的原因,是因为这片内存真的是0,两次输出的结果如下:
总结
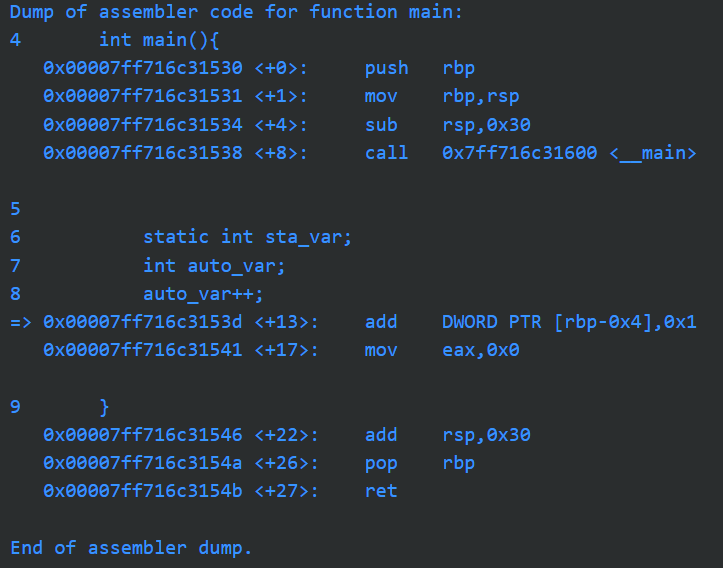
相信你读到这里对所有变量的初始化,有了更深刻的了解,我们把这些内容转移到数组之上也是完全相同的,同样是取决于他们的存储类型。存储于静态内存的数组也只初始化一次,默认情况下数据为0,需要注意的是,程序并不需要执行指令把这些值放到合适的位置,我们观察汇编就会发现实际上汇编指令把对应区域的内存早已通过运行前设置.data端的内容初始化好了,此时并没有使用指令去一个一个初始化。
详细的代码如下所示:
Dump of assembler code for function main:
9 int main(){
0x00007ff6016415ae <+0>: push rbp
0x00007ff6016415af <+1>: mov rbp,rsp
0x00007ff6016415b2 <+4>: sub rsp,0x20
0x00007ff6016415b6 <+8>: call 0x7ff601641690 <__main>
10
11 static int sta_var[]={1,2,3,4,5};
12 sta_var[0]++;
=> 0x00007ff6016415bb <+13>: mov eax,DWORD PTR [rip+0x6a4f] # 0x7ff601648010 <sta_var.0>
0x00007ff6016415c1 <+19>: add eax,0x1
0x00007ff6016415c4 <+22>: mov DWORD PTR [rip+0x6a46],eax # 0x7ff601648010 <sta_var.0>
0x00007ff6016415ca <+28>: mov eax,0x0
13
14 }
0x00007ff6016415cf <+33>: add rsp,0x20
0x00007ff6016415d3 <+37>: pop rbp
0x00007ff6016415d4 <+38>: ret
End of assembler dump.
可以看到我们的主函数只有对累加进行操作的指令,初始化实际上不在主函数中进行,而是独立出来,在主函数运行前将对应区域内存初始化。并不占据函数运行时的空间。
sta_var.0:
.long 1
.long 2
.long 3
.long 4
.long 5
.ident "GCC: (Rev3, Built by MSYS2 project) 12.1.0"
.def __mingw_vfprintf; .scl 2; .type 32; .endef
到此为止本篇详细讨论了C的变量和数组的静态初始化,还有变量的动态初始化。但是没有详细讨论数组的动态声明,数组的动态声明是和变量一样的吗?事实上是不相同的,我们来看看具体的代码,为什么这样说:
void test()
{
int auto_var[20]={0};
printf("%d",auto_var[2]);
auto_var[2]=999;
}
我们把这个函数反汇编一下,看一看初始化的时候进行了什么操作:
5 int auto_var[20]={0};
0x00007ff79a2c158c <+8>: pxor xmm0,xmm0
0x00007ff79a2c1590 <+12>: movups XMMWORD PTR [rbp-0x50],xmm0
0x00007ff79a2c1594 <+16>: movups XMMWORD PTR [rbp-0x40],xmm0
0x00007ff79a2c1598 <+20>: movups XMMWORD PTR [rbp-0x30],xmm0
0x00007ff79a2c159c <+24>: movups XMMWORD PTR [rbp-0x20],xmm0
0x00007ff79a2c15a0 <+28>: movups XMMWORD PTR [rbp-0x10],xmm0
他如果在数组后边加入了{0},就意味着要初始化,你会看到汇编代码中,有很多操作使用初始化的,他将xmm0的数据清零以后再把xmm0寄存器的0搬移进来。这就是数组实现清零的具体实现。
如果不加这个{0}呢?你会发现并没有从xmm0寄存器中搬迁过来0,下边的操作都是关于printf的,所以数组的初始化稍微有一些特殊,不加{0}就会导致空间内容是随机的。
5 int auto_var[20];
6 printf("%d",auto_var[2]);
0x00007ff6a68a158c <+8>: mov eax,DWORD PTR [rbp-0x48]
0x00007ff6a68a158f <+11>: mov edx,eax
0x00007ff6a68a1591 <+13>: lea rax,[rip+0x7a68]
0x00007ff6a68a1598 <+20>: mov rcx,rax
0x00007ff6a68a159b <+23>: call 0x7ff6a68a1530 <printf>
结论
所有静态类型不管是数组还是变量,不用初始化都是0,且如果初始化不需要占用程序运行时间,所有自动类型的变脸报告和数组都需要初始化,不初始化都是随机的,数组初始化直接使用={0},所有数组内容都是0。
一点补充
当然你也看到了上文的汇编代码是交错着C源码生成的,这里是使用GDB进行 反汇编生成的,其给出的反汇编可以伴随着代码注释,使用命令如下:
切换到intel汇编:

使用GDB进行反汇编:
-exec disassemble /m,不过存在的问题是只能获取某一个函数的反汇编,我还不知道如何获取全部文件的反汇编。所以下面的反汇编实际上并不完全。
参考文章:
https://sourceware.org/binutils/docs/as/Lcomm.html
https://en.wikipedia.org/wiki/.bss
https://blog.csdn.net/moonsheep_liu/article/details/39099969
从C过渡到C++——换一个视角深入数组[初始化](1)的更多相关文章
- 从C过渡到C++——换一个视角深入数组[真的存在高效吗?](2)
从C过渡到C++--换一个视角深入数组[真的存在高效吗?](2) C风格高效的数组遍历 在过渡到C++之前我还是想谈一谈如何书写高效的C的代码,这里的高效指的是C代码的高效,也就是在不开启编译器优化下 ...
- 【机器学习基础】——另一个视角解释SVM
SVM的另一种解释 前面已经较为详细地对SVM进行了推导,前面有提到SVM可以利用梯度下降来进行求解,但并未进行详细的解释,本节主要从另一个视角对SVM进行解释,首先先回顾之前有关SVM的有关内容,然 ...
- ytu 1050:写一个函数,使给定的一个二维数组(3×3)转置,即行列互换(水题)
1050: 写一个函数,使给定的一个二维数组(3×3)转置,即行列互换 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 154 Solved: 112[ ...
- [CareerCup] 13.10 Allocate a 2D Array 分配一个二维数组
13.10 Write a function in C called my2DAlloc which allocates a two-dimensional array. Minimize the n ...
- new一个二维数组
.定义一个二维数组 char **array1 array1 = new char *[x]; for(i=0;i<x;++i) array1[i] = new char[y]; ...用的时候 ...
- 写入数据到Plist文件中时,第一次要创建一个空的数组,否则写入文件失败
#pragma mark - 保存数据到本地Plist文件中 - (void)saveValidateCountWithDate:(NSString *)date count:(NSString *) ...
- 一天一个Java基础——数组
一天一个变成了几天一个,最近接受的新东西太多.太快,有好多需要blog的但没有时间,这些基础知识应该是要深挖并好好研究的,不应该每次都草草了事,只看个皮毛. 数组: JVM将数组存储在一个称为堆(he ...
- [原]Java面试题-输入一个整型数组,找出最大值、最小值,并交换。
[Date]2013-09-19 [Author]wintys (wintys@gmail.com) http://wintys.cnblogs.com [Content]: 1.面试题 输入一个整型 ...
- c语言题目:找出一个二维数组的“鞍点”,即该位置上的元素在该行上最大,在该列上最小。也可能没有鞍点
//题目:找出一个二维数组的“鞍点”,即该位置上的元素在该行上最大,在该列上最小.也可能没有鞍点. // #include "stdio.h" #include <stdli ...
随机推荐
- UVA471 Magic Numbers 题解
1.题目 题意很简单:输入n,枚举所有的a,b,使得 (1)满足a/b=n. (2)满足a,b各个位上的数字不相同. 2.思路 (1)对于被除数,要满足各个位上的数字,显然最大枚举到987654321 ...
- JavaScript之parseInt()方法
parseInt(string, radix):用于解析一个字符串并返回指定基数的十进制整数或者NaN string参数为被解析的值,如果该值不是一个字符串,则会隐式的使用toString()方法转化 ...
- UiPath数据抓取Data Scraping的介绍和使用
一.数据抓取(Data Scraping)的介绍 使用截据抓取使您可以将浏览器,应用程序或文档中的结构化数据提取到数据库,.csv文件甚至Excel电子表格中. 二.Data Scraping在UiP ...
- RPA应用场景-报税机器人
场景概述 报税机器人 所涉系统名称 税务网站 人工操作(时间/次) 53分钟 所涉人工数量 60 操作频率 每月 场景流程 1.通过RPA自动将财税信息从对应系统中导出 2.RPA根据不同的税务报表规 ...
- Java开发问题:Column 'AAA' in where clause is ambiguous解决办法
当在java开发中遇到了Column 'AAA' in where clause is ambiguous问题时, 你需要去看看:多表查询的时候不同的表是否出现了相同名称相同的列, 如果存在,你需要在 ...
- Fleet 使用感受
1. 前言 笔者主要使用的编程语言是 Java.平时使用的 IDE 是 JetBrains 公司的 IntelliJ IDEA.有时候也会打开该公司旗下的 PyCharm.DataGrip.WebSt ...
- java枚举和注解
枚举 一.枚举(enumeration) 是一组常量的集合,可以理解为:枚举属于一种特殊的类,里面只包含一组有限的特定的对象,构造方法默认为private. 二.枚举的两种实现方式 1.自定义实现枚举 ...
- DBPack 读写分离功能发布公告
在 v0.1.0 版本我们发布了分布式事务功能,并提供了读写分离功能预览.在 v0.2.0 这个版本,我们加入了通过 UseDB hint 自定义查询请求路由的功能,并修复了一些 bug.另外,在这个 ...
- RESTAPI 版本控制策略【eolink 翻译】
微服务,是现阶段开发建设云原生应用程序的流行趋向.API 版本控制有益于在辨别出所需要的调节时加速迭代更新的速度. 根据微服务架构的关键构件其一,是 API 的设计和规范.针对 API,版本控制是不可 ...
- k8s的部署
一.k8s的二进制部署 1.环境准备: IP 节点 172.16.10.1 k8s-master01 172.16.10.3 ...