Oracle收集统计信息的一些思考
一、问题
- Oracle在收集统计信息时默认的采样比例是DBMS_STATS.AUTO_SAMPLE_SIZE,那么AUTO_SAMPLE_SIZE的值具体是多少?
- 假设采样比例为10%,那么在计算单个列的distinct时与实际的差别大吗?
- 有哪些采样算法?
二、实验
准备三张实验表,t1/t2/t3,这三张表的数据内容完全一致,我们分别使用100%、10%、AUTO_SAMPLE_SIZE的比例去收集他们的统计信息。
SQL> begin
2 dbms_stats.gather_table_stats(
3 ownname => 'BAO',
4 tabname => 'T1',
5 estimate_percent => 100
6 );
7 end;
8 /
PL/SQL procedure successfully completed.
SQL> begin
2 dbms_stats.gather_table_stats(
3 ownname => 'BAO',
4 tabname => 'T2',
5 estimate_percent => 10
6 );
7 end;
8 /
PL/SQL procedure successfully completed.
SQL> begin
2 dbms_stats.gather_table_stats(
3 ownname => 'BAO',
4 tabname => 'T3',
5 estimate_percent => dbms_stats.auto_sample_size
6 );
7 end;
8 /
PL/SQL procedure successfully completed.
查看这三张表的统计信息,可以看到采用100%和AUTO_SAMPLE_SIZE这两种方式收集的统计信息的SAMPLE_SIZE相同,都是全量收集。
SQL> select table_name, num_rows, sample_size from user_tables where table_name in ('T1', 'T2', 'T3');
TABLE_NAME NUM_ROWS SAMPLE_SIZE
-------------- ---------- -----------
T1 145334 145334
T2 146190 14619
T3 145334 145334
官方文档并没有说明AUTO_SAMPLE_SIZE具体的值是多少,但是从实验结果来看,这个值就是100。这就回答了文章的第一个问题。
Oracle为什么会默认采用100%的方式来收集统计信息呢,在ASKTOM有同行就提出过这个问题“DBMS_STATS.AUTO_SAMPLE_SIZE seems to always generate 100%”,他们的回复是为了得到精确的distinct列值。接下来我们就来看下全量采集和部分采集列的distinct区别。
SQL> select a.column_name, a.num_distinct "t1.num_distinct", b.num_distinct "t2.num_distinct",
2 round((a.num_distinct - b.num_distinct) * 100 / a.num_distinct, 1) "diff",
3 a.sample_size "t1.sample_size", b.sample_size "t2.sample_size"
4 from (select table_name, column_name, num_distinct, sample_size from user_tab_col_statistics where table_name in ('T1')) a,
5 (select table_name, column_name, num_distinct, sample_size from user_tab_col_statistics where table_name in ('T2')) b
6 where a.column_name = b.column_name and a.num_distinct > 0 order by "diff" desc;
COLUMN_NAME t1.num_distinct t2.num_distinct diff t1.sample_size t2.sample_size
------------------------------ --------------- --------------- ---------- -------------- --------------
OBJECT_NAME 64552 10300 84 145334 14619
SUBOBJECT_NAME 1015 385 62.1 68251 6856
TIMESTAMP 2585 1240 52 145212 14610
LAST_DDL_TIME 2490 1257 49.5 145212 14610
CREATED 2312 1209 47.7 145334 14619
NAMESPACE 21 15 28.6 145212 14610
OBJECT_TYPE 45 39 13.3 145334 14619
OWNER 80 71 11.3 145334 14619
TEMPORARY 2 2 0 145334 14619
DUPLICATED 1 1 0 145334 14619
STATUS 2 2 0 145334 14619
SHARDED 1 1 0 145334 14619
GENERATED 2 2 0 145334 14619
SECONDARY 1 1 0 145334 14619
SHARING 4 4 0 145334 14619
EDITIONABLE 2 2 0 25433 2531
ORACLE_MAINTAINED 2 2 0 145334 14619
APPLICATION 1 1 0 145334 14619
DEFAULT_COLLATION 1 1 0 16886 1705
DATA_OBJECT_ID 77785 78100 -.4 77822 7813
OBJECT_ID 145212 146100 -.6 145212 14610
T1表是全量收集,T2表是按10%的比例收集,从上面的结果可以看到,对于大部分字段通过部分采样的方式都能估算得很准确。但对于OBJECT_NAME这个列,估算出来的值和全量统计的差别很大,我们来看一下是什么原因导致的。
SQL> select count(*), object_name from t1 group by object_name order by count(*) desc;
COUNT(*) OBJECT_NAME
---------- -----------------
690 S_AAA_CCD
690 S_ABA_CED
690 S_ACA_CCD
690 S_ADA_CCD
690 PK_AEA_CED
...
1 GV_$CON_SYSSTAT
1 GV_$DATAFILE
1 GV_$TABLESPACE
1 GV_$ROLLSTAT
1 GV_$PARAMETER
可以看到OBJECT_NAME这个列的数据分布极不均匀。因此对于分布不均匀的列,通过部分采样方式得到的distinct值与实际的distinct值差别就会比较大。这就回答了文章的第二个问题。
三、采样算法
以下是个人的一些娱乐性思考
等比放大,即(采样得到distinct值 / 采样行数) x 总行数。
举个例子,假设表有1000行数据,只采样100行,A列有95个不同的值,即count(distinct A) / count(A) = 95%,那么等比放大很容易推导出1000行数据,有950个A的不同值。但是如果这100行中B列只有2个不同的值,即count(distinct B) / count(B) = 2%,那么对于1000行的表来讲,B的不同值是不是等于2% * 1000呢?很有可能不是,说不定全表就这两个不同值,例如性别。所以通过等比放大得到的distinct值就不准。这种算法有明显的缺陷。按增长率估算,即将采样得到的前5%作为一个基数,采样得到的后5%作为一个增长率。(假设采样比例是10%)
还是举个例子,假设表有1000行数据,只采样100行,采样的前50行,C列有40个不同值。采样的后50行,C列又多了30个不同值,即总共有70个不同值。那么后面的90%都会保持这个增长速度。则总体的C列不同值为40 + 30 * ((100-5)/5) = 610。再来看一种情况,假设采样的前50行,D列有2个不同值。采样的后50行,D列多了0个不同值,即不同值总数保持不变。那么后面的90%都会保持这个增长速度。则总体的D列不同值仍为2。这种方式似乎比等比采样更加合乎实际情况一点。接下来就用python去实现这个算法,看看与oracle的估算差别有多大。以下为python代码。
import random
import cx_Oracle
def func(ins):
SAMPLE_PERCENT = 10 # 采样比例%
sample_size = int(len(ins) * SAMPLE_PERCENT / 100)
# 对数据进行采样
sample = random.sample(ins, sample_size)
head_half_sample = sample[0:int(len(sample)/2)] # 采样数据的前一半
head_half_sample_distinct = len(set(head_half_sample)) # 采样数据的前一半的distinct值
full_sample_distinct = len(set(sample)) # 采样数据的全量distinct值
tail_half_inc = full_sample_distinct - head_half_sample_distinct # 采样数据的distinct增量
estimate_distinct = round(head_half_sample_distinct + tail_half_inc * (100 - SAMPLE_PERCENT/2) / (SAMPLE_PERCENT/2))
return estimate_distinct
def test(colname):
DATABASE_URL = 'xxxxx'
conn = cx_Oracle.connect(DATABASE_URL)
curs = conn.cursor()
sql = 'select {} from t1'.format(colname)
curs.execute(sql)
tmpdata = []
for i in curs.fetchall():
tmpdata.append(i[0])
res = func(tmpdata)
curs.close()
conn.close()
return res
for i in ['OBJECT_NAME', 'SUBOBJECT_NAME', 'TIMESTAMP', 'LAST_DDL_TIME', 'CREATED', 'NAMESPACE', 'OBJECT_TYPE',
'OWNER', 'TEMPORARY', 'DUPLICATED', 'STATUS', 'SHARDED', 'GENERATED', 'SECONDARY', 'SHARING', 'EDITIONABLE',
'ORACLE_MAINTAINED', 'APPLICATION', 'DEFAULT_COLLATION', 'DATA_OBJECT_ID', 'OBJECT_ID']:
print(i, '估算的distinct->', test(i))
运行结果
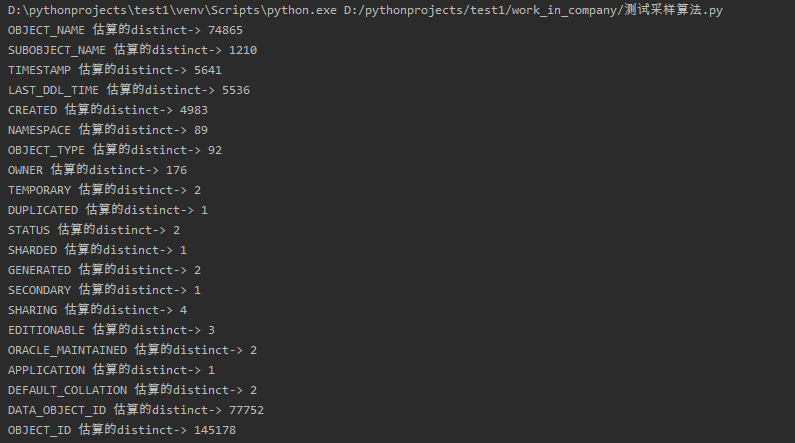
再来跟之前的一个表格进行对比,按增长率的方式估算的distinct值看上去也能接受。
COLUMN_NAME 实际的distinct 数据库估算的distinct python估算的distinct
------------------------------ --------------- -------------------- --------------------
OBJECT_NAME 64552 10300 74865
SUBOBJECT_NAME 1015 385 1210
TIMESTAMP 2585 1240 5641
LAST_DDL_TIME 2490 1257 5536
CREATED 2312 1209 4983
NAMESPACE 21 15 89
OBJECT_TYPE 45 39 92
OWNER 80 71 176
TEMPORARY 2 2 2
DUPLICATED 1 1 1
STATUS 2 2 2
SHARDED 1 1 1
GENERATED 2 2 2
SECONDARY 1 1 1
SHARING 4 4 4
EDITIONABLE 2 2 3
ORACLE_MAINTAINED 2 2 2
APPLICATION 1 1 1
DEFAULT_COLLATION 1 1 2
DATA_OBJECT_ID 77785 78100 77752
OBJECT_ID 145212 146100 145178
限于时间,测试到此结束。后面有时间再学点统计相关的知识。
Oracle收集统计信息的一些思考的更多相关文章
- 验证Oracle收集统计信息参数granularity数据分析的力度
最近在学习Oracle的统计信息这一块,收集统计信息的方法如下: DBMS_STATS.GATHER_TABLE_STATS ( ownname VARCHAR2, ---所有者名字 tabname ...
- ORACLE收集统计信息
1. 理解什么是统计信息 优化器统计信息就是一个更加详细描述数据库和数据库对象的集合,这些统计信息被用于查询优化器,让其为每条SQL语句选择最佳的执行计划.优化器统计信息包括: · ...
- ORACLE 收集统计信息
1. 理解什么是统计信息优化器统计信息就是一个更加详细描述数据库和数据库对象的集合,这些统计信息被用于查询优化器,让其为每条SQL语句选择最佳的执行计划.优化器统计信息包括: · ...
- Oracle 收集统计信息11g和12C在差异
Oracle 基于事务临时表11g和12C下,能看到临时表后收集的统计数据,前者记录被清除,后者没有,这是一个很重要的不同. 关于使用企业环境12C,11g,使用暂时表会造成时快时慢.之前我有帖子ht ...
- Oracle重建表索引及手工收集统计信息
Oracle重建所有表的索引的sql: SELECT 'alter index ' || INDEX_NAME || ' rebuild online nologging;' FROM USER_IN ...
- Oracle自动统计信息的收集原理及实验
[日期:2014-11-21]来源:Linux社区 作者:stevendbaguo[字体:大 中 小] 从Oracle Database 10g开始,Oracle在建库后就默认创建了一个名为GATH ...
- Oracle 手动收集统计信息
收集oracle统计信息 优化器统计范围: 表统计: --行数,块数,行平均长度:all_tables:NUM_ROWS,BLOCKS,AVG_ROW_LEN: 列统计: --列中唯一值的数量(NDV ...
- Oracle 11g系统自己主动收集统计信息的一些知识
在11g之前,当表的数据量改动超过总数据量的10%,就会晚上自己主动收集统计信息.怎样推断10%.之前的帖子有研究过:oracle自己主动统计信息的收集原理及实验.这个STALE_PERCENT=10 ...
- Oracle 判断 并 手动收集 统计信息 脚本
CREATE OR REPLACE PROCEDURE SchameB.PRC_GATHER_STATS AUTHID CURRENT_USER IS BEGIN SYS.DBMS_STATS.GAT ...
随机推荐
- Hive存储格式之ORC File详解,什么是ORC File
目录 概述 文件存储结构 Stripe Index Data Row Data Stripe Footer 两个补充名词 Row Group Stream File Footer 条纹信息 列统计 元 ...
- 从零开始Blazor Server(15)--总结
我们用了14篇文章,基本上把一个后台管理系统需要的UI部分都说的差不多了.所以这套文章也该到了结束的时候了. 这里面有很多问题,比如我们直接使用UI来拉数据库信息而没有使用service,再比如我们大 ...
- Dreamweaver8 网站制作软件使用教程
Dreamweaver是我喜欢做网站的软件.之所以喜欢Dreamweaver 8 是因为这个版本有折叠功能. 下面说说它的使用方法. 1.创建站点文件.注意看截图的顺序,如下图 2.选择你喜欢的编辑模 ...
- HTTP协议,会话跟踪,保存作用域,servlet类跳转
解决post的编码问题,防止中文乱码 request.setCharacterEncoding("utf-8"); HTTP协议: (1)由Request(请求)和Response ...
- 如何结合整洁架构和MVP模式提升前端开发体验 - 整体架构篇
本文不详细介绍什么是整洁架构以及 MVP 模式,自行查看文章结尾相关链接文章. 整洁架构粗略介绍 下图为整洁架构最原始的结构图: Entities/Models:实体层,官方说法就是封装了企业里最通用 ...
- RTSP播放器或RTMP播放器常用的Evnet事件回调设计
很多开发者在开发RTSP或RTMP播放器的时候,不晓得哪些event回调事件是有意义的,针对此,我们以大牛直播SDK(github)的Android平台RTSP/RTMP直播播放端为例,简单介绍下常用 ...
- 微信小程序语音提示
一. 老规矩, 先上demo图: 然后通过 wx.createInnerAudioContext 创建内部 audio 上下文 InnerAudioContext 对象 就能播放 filename ...
- 基于 vite 创建 vue3 全家桶项目(vite + vue3 + tsx + pinia)
vite 最近非常火,它是 vue 作者尤大神发布前端构建工具,底层基于 Rollup,无论是启动速度还是热加载速度都非常快.vite 随 vue3 正式版一起发布,刚开始的时候与 vue 绑定在一起 ...
- MySQL常用函数整理,建议收藏!
常见函数 字符串函数 数字函数 日期函数 聚合函数 流程控制函数 一.字符串函数 concat(s1,s2...,sn) --将s1,s2...,sn连接成字符串,如果该函数中的任何参数为 null, ...
- kubernetes中部署kube-prometheus项目解决ControllerManager与Scheduler无法监控问题
文章转载自:https://www.kococ.cn/20210302/cid=697.html 一.问题描述 在部署 kube-prometheus 到 kubernetes 集群中总会遇到一个问题 ...