csv数据集按比例分割训练集、验证集和测试集,即分层抽样的方法
一、一种比较通俗理解的分割方法
1.先读取总的csv文件数据:
import pandas as pd
data = pd.read_csv('D:\BaiduNetdiskDownload\weibo_senti_100k\weibo_senti_100k\weibo_senti_100k.csv')
data.head(10)#输出前十行

data.label.value_counts()#查看标签类别及数目
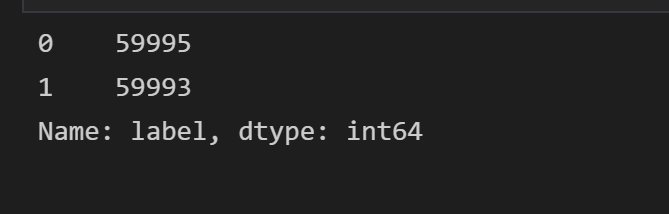
2.按照标签将总的dataframe分割为两份,一份为标签为1,一份为标签为0
groups = data.groupby(data.label)
data_true = groups.get_group(1)
data_false = groups.get_group(0)
data_true.head(10),data_false.head(10)

3.
data_true = data_true.sample(frac=1.0) # 全部打乱
data_false = data_false.sample(frac=1.0) # 全部打乱
#给测试集两种标签各600个,按照大概8:1:1的比例取
test_true = data_true.iloc[:600, :]
test_false = data_false.iloc[:600, :]
test_data = pd.concat([test_true, test_false], axis = 0, ignore_index=True).sample(frac=1)
#验证集
valid_true = data_true.iloc[600:1200, :]
valid_false = data_false.iloc[600:1200, :]
valid_data = pd.concat([valid_true, valid_false], axis = 0, ignore_index=True).sample(frac=1)
#训练集
train_true = data_true.iloc[1200:, :]
train_false = data_false.iloc[1200:, :]
train_data = pd.concat([train_true, train_false], axis = 0, ignore_index=True).sample(frac=1)
4.生成csv文件
test_data.to_csv('test.csv')
valid_data.to_csv('val.csv')
train_data.to_csv('train.csv')
二、不通俗方法
可以看出上面的方法不断地生成新的dataframe太麻烦了些,虽然直观醒目,但在代码编写上很是繁冗,于是可以使用apply方法避免这种问题
1.为便于讲解,先生成一个简单的dataframe:
df = pd.DataFrame({'label':[0,0,0,0,1,1,1,1], 'review':['aa', 'bb', 'cc', 'dd', 'ee', 'ff', 'gg', 'hh']})
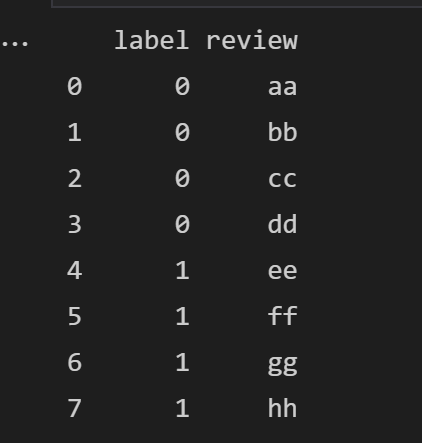
2.首先定义一个简单的分层取样函数,frac为取样概率,group为一个单独的dataframe
def simpleSampling(group, frac):
return group.sample(frac=frac)
3.接下来使用apply函数对分组后的每一个组(即一个dataframe)进行函数操作
train_df = df.groupby(df.label).apply(simpleSampling, 0.5)
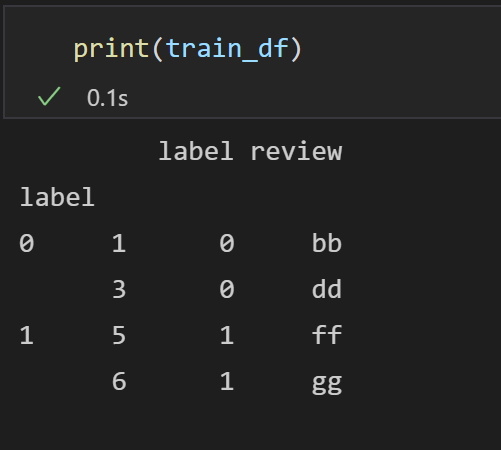
可以看到多了一列label标签,可以使用sample(frac=1, ignore_index = True)消除它
4.在生成了train数据集后,我们需要把train从原df中删除掉,但是dataframe没有直接删除的方法,我们迂回的使用删除重复行的方法:
df = df.append(train_df.sample(frac=1, ignore_index=True)).drop_duplicates(keep = False)
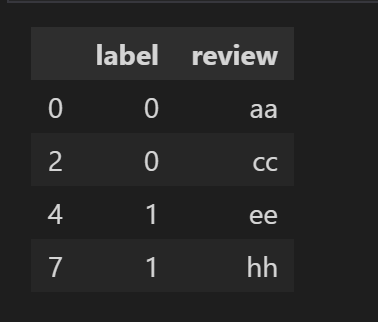
可以看到df只剩上图的几行了,接下来生成测试集和验证集
5.我们如果要生成原数据集0.25比例的验证集,那么需要注意的是,在将train删除后,在新的数据集中我们的比例就变成了p(val) = p(test) = 0.25 / 0.5 = 0.5
val_df = df.groupby(df.label).apply(simpleSampling, 0.5).sample(frac=1, ignore_index = True)
test_df = df.append(val_df).drop_duplicates(keep=False)
train_df.to_csv('train_csv')
val_df.to_csv('val_csv')
test_df.to_csv('test_csv')
至此我们的数据集就已经成功分割了,以上两种方法原理相同,只是第二种方法巧妙地应用了apply函数,避免了一个接一个的新的dataframe的生成。
csv数据集按比例分割训练集、验证集和测试集,即分层抽样的方法的更多相关文章
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- 【深度学习的实用层面】(一)训练,验证,测试集(Train/Dev/Test sets)
在配置训练.验证.和测试数据集的过程中做出正确的决策会更好地创建高效的神经网络,所以需要对这三个名词有一个清晰的认识. 训练集:用来训练模型 验证集:用于调整模型的超参数,验证不同算法,检验哪种算法更 ...
- 机器学习入门06 - 训练集和测试集 (Training and Test Sets)
原文链接:https://developers.google.com/machine-learning/crash-course/training-and-test-sets 测试集是用于评估根据训练 ...
- [机器学习] 训练集(train set) 验证集(validation set) 测试集(test set)
在有监督(supervise)的机器学习中,数据集常被分成2~3个即: 训练集(train set) 验证集(validation set) 测试集(test set) 一般需要将样本分成独立的三部分 ...
- 训练集(train set) 验证集(validation set) 测试集(test set)
转自:http://www.cnblogs.com/xfzhang/archive/2013/05/24/3096412.html 在有监督(supervise)的机器学习中,数据集常被分成2~3个, ...
- 随机切分csv训练集和测试集
使用numpy切分训练集和测试集 觉得有用的话,欢迎一起讨论相互学习~Follow Me 序言 在机器学习的任务中,时常需要将一个完整的数据集切分为训练集和测试集.此处我们使用numpy完成这个任务. ...
- 训练集(train set) 验证集(validation set) 测试集(test set)。
训练集(train set) 验证集(validation set) 测试集(test set). http://blog.sina.com.cn/s/blog_4d2f6cf201000cjx.ht ...
- AI---训练集(train set) 验证集(validation set) 测试集(test set)
在有监督(supervise)的机器学习中,数据集常被分成2~3个即: 训练集(train set) 验证集(validation set) 测试集(test set) 一般需要将样本分成独立的三部分 ...
- sklearn学习3----模型选择和评估(1)训练集和测试集的切分
来自链接:https://blog.csdn.net/zahuopuboss/article/details/54948181 1.sklearn.model_selection.train_test ...
- sklearn——train_test_split 随机划分训练集和测试集
sklearn——train_test_split 随机划分训练集和测试集 sklearn.model_selection.train_test_split随机划分训练集和测试集 官网文档:http: ...
随机推荐
- Crypto入门 (三)Morse
前言: Morse电码(Morsecode)是大家耳熟能详的编码方式,很多人都误认为它是一种加密方式,但其实它是一种编码,因为它并不存在密钥.在只能使用电报长短音传递信息的条件下,使用摩斯电码是为了方 ...
- C# DevExpress gridview 字符串尾部带数字如何排序
我们经常遇到这样的问题,字符串尾部带数字,如何正确排序; 首先设置GridView ,Columns 的相关列,设置属性中,SortMode为Custom 解决思路,把字符串尾缀数字,分离出来.先比较 ...
- SAP B1如何找回被误删的许可证号
SAP B1的许可证分配记录,保存在安装目录下的B1Upf.xml文件下,如果你发现许可证用户不小心误删了, 但又不知道是哪个用户名了,打开此文件,便可发现该用户名.接下来,你只要再建立一个和误删除的 ...
- C++ || 求一个数中1的位数
点击查看代码 #include<iostream> using namespace std; int f(int x) { int count = 0; while(x) { if (x ...
- 使用IDEA的webservice工具解析生成的客户端调用远程接口
由于这个接口的报文格式比较麻烦,是XML的请求头加上JSON格式的请求体,所以看起来比较复杂,也可以用RPC的方式调用,那样需要将请求头和请求体,响应头和响应体建实体.public JSONObjec ...
- C/C++ 数据结构优先级队列的实现(使用二级指针)
#include <iostream> #include <Windows.h> #include <iomanip> //优先级队列的实现 using names ...
- 转帖:巧用Stream优化老代码,太清爽了!
Java8的新特性主要是Lambda表达式和流,当流和Lambda表达式结合起来一起使用时,因为流申明式处理数据集合的特点,可以让代码变得简洁易读 放大招,流如何简化代码 如果有一个需求,需要对数据库 ...
- 求pi
参考自:https://www.zhihu.com/question/402311979 由 \[\frac{\pi^4}{90}={\textstyle \sum_{n=1}^{\infty }} ...
- python-GUI-tkinter之excel密码破解工具
python gui 之熟悉tkinter部分控件使用.一个简单的excel暴力密码破解,核心很简单,基本就是一个函数外面加了GUI,写的很啰嗦,希望大家可以在优化改良下,主要是为了再熟悉下tkint ...
- unlua
安装 复制 Plugins 目录到你的UE工程根目录. 重新启动你的UE工程 注意点 新建工程后,必须重新拷贝插件,重新编译.不能从老项目中拷贝,会崩溃~ 加载c++类和蓝图类 -- c++类 loc ...