使用Kubernetes中的Nginx来改善第三方服务的可靠性和延迟
使用Kubernetes中的Nginx来改善第三方服务的可靠性和延迟
译自:How we improved third-party availability and latency with Nginx in Kubernetes
本文讨论了如何在Kubernetes中通过配置Nginx缓存来提升第三方服务访问的性能和稳定性。这种方式基于Nginx来实现,优点是不需要进行代码开发即可实现缓存第三方服务的访问,但同时也缺少一些定制化扩展。不支持缓存写操作,多个pod之间由于使用了集中式共享方式,因而缓存缺乏高可用。
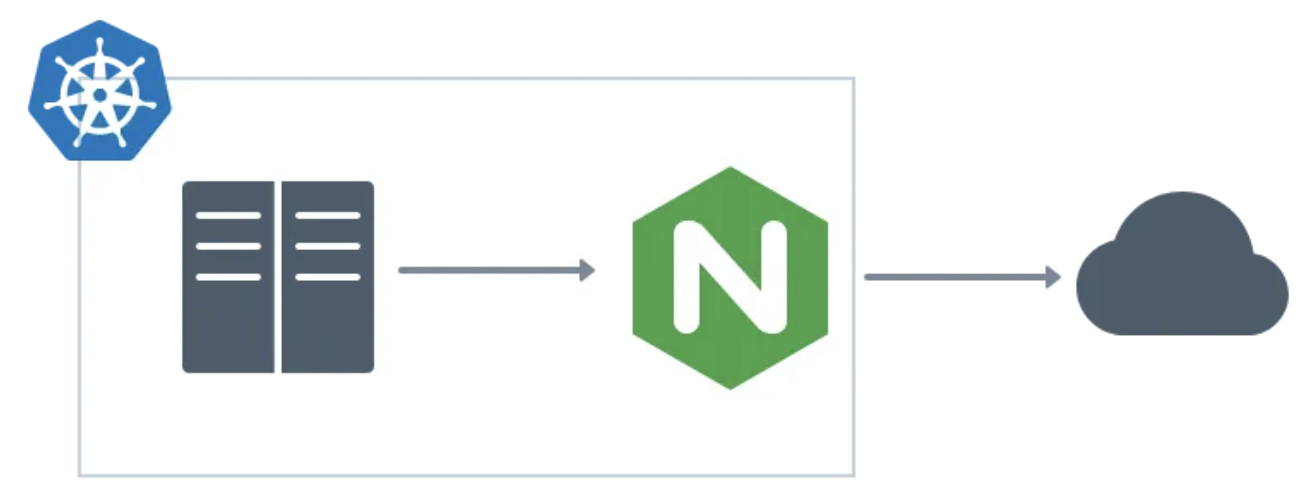
使用Nginx作为网关来缓存到第三方服务的访问
第三方依赖
技术公司越来越依赖第三方服务作为其应用栈的一部分。对外部服务的依赖是一种快速拓展并让内部开发者将精力集中在业务上的一种方式,但部分软件的失控可能会导致可靠性和延迟降级。
在Back Market,我们已经将部分产品目录划给了一个第三方服务,我们的团队需要确保能够在自己的Kubernetes集群中快速可靠地访问该产品目录数据。为此,我们使用Nginx作为网关代理来缓存所有第三方API的内部访问。
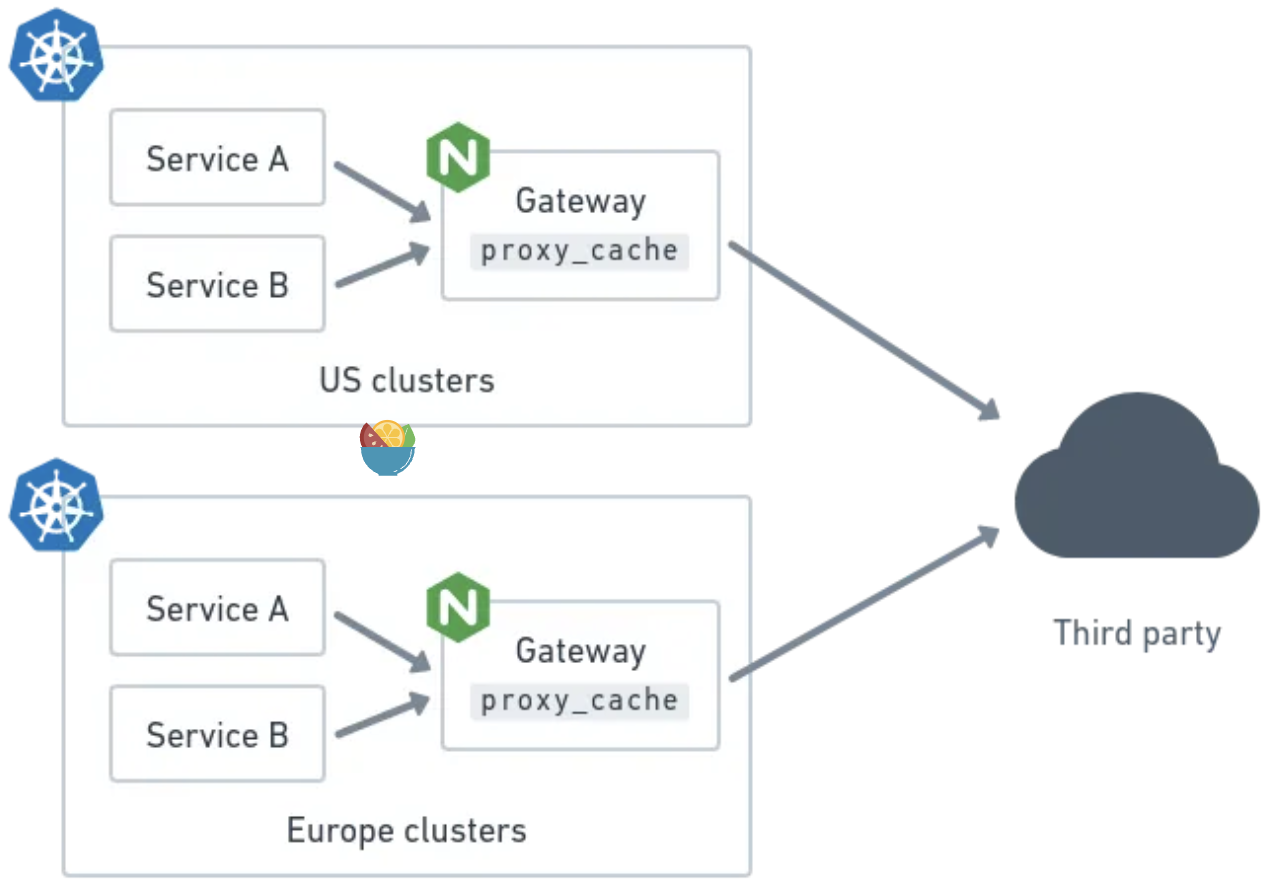
多集群环境中使用Nginx作为网关来缓存第三方API的访问
使用结果
在我们的场景下,使用网关来缓存第三方的效果很好。在运行几天之后,发现内部服务只有1%的读请求才需要等待第三方的响应。下面是使用网关一周以上的服务请求响应缓存状态分布图:
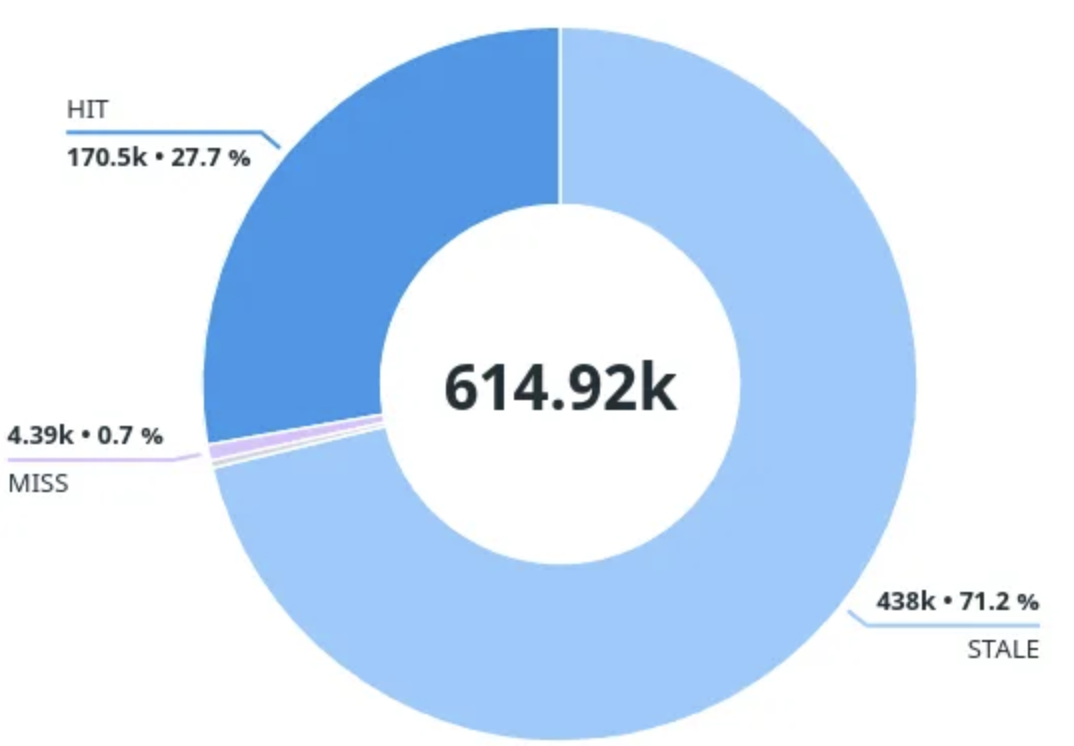
HIT:缓存中的有效响应 ->使用缓存
STALE:缓存中过期的响应 ->使用缓存,后台调用第三方
UPDATING:缓存中过期的响应(后台已经更新) ->使用缓存
MISS:缓存中没有响应 ->同步调用第三方
即使在第三方下线12小时的情况下,也能够通过缓存保证96%的请求能够得到响应,即保证大部分终端用户不受影响。
内部网关的响应要远快于直接调用第三方API的方式(第三方位于Europe,调用方位于US)。
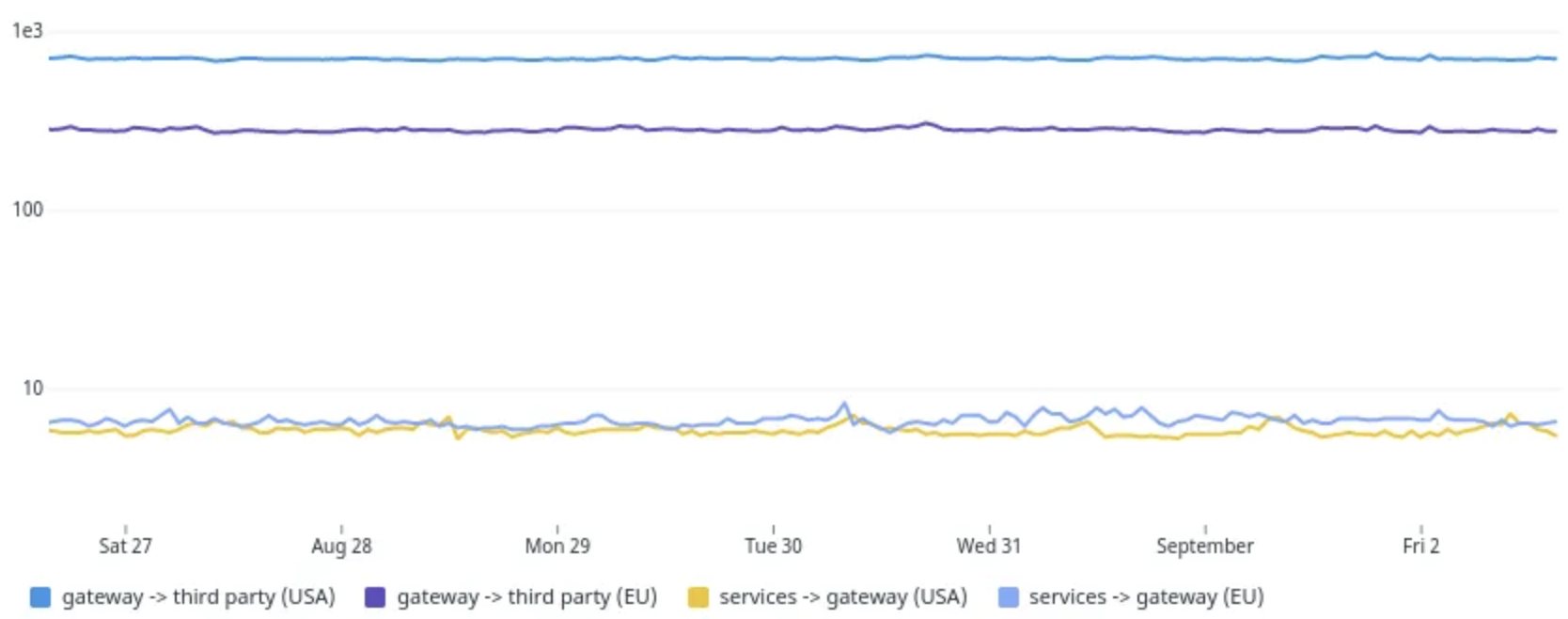
以 ms 为单位的缓存路径的请求持续时间的 P90(1e3为1秒)
下面看下如何配置和部署Nginx。
Nginx 缓存配置
可以参见官方文档、Nginx缓存配置指南以及完整的配置示例
proxy_cache_path ... max_size=1g inactive=1w;
proxy_ignore_headers Cache-Control Expires Set-Cookie;
proxy_cache_valid 1m;
proxy_cache_use_stale error timeout updating
http_500 http_502 http_503 http_504; proxy_cache_background_update on;
配置的目标是最小化第三方服务的读请求(如HTTP GET)。
如果缓存中不存在响应,则需要等待第三方响应,这也是我们需要尽可能避免的情况,这种现象可能发生在从未请求一个给定的URL或由于响应过期一周而被清除(inactive=1w),或由于该响应是最新最少使用的,且达到了全局的缓存大小的上限(max_size=1g)而被清除。
如果响应位于缓存中,当设置proxy_cache_background_update on时,即使缓存的响应超过1分钟,也会将其直接返回给客户端。如果缓存的响应超过1分钟(proxy_cache_valid 1m),则后台会调用第三方来刷新缓存。这意味着缓存内容可能并不与第三方同步,但最终是一致的。
当第三方在线且经常使用URLs时,可以认为缓存的TTL是1分钟(加上后台缓存刷新时间)。这种方式非常适用于不经常变更的产品数据。
假设全局缓存大小没有达到上限,如果一周内第三方不可达或出现错误,此时就可以使用缓存的响应。当一周内某个URL完全没有被调用时也会发生这种情况。
为了进一步降低第三方的负载,取消了URL的后台并行刷新功能:
proxy_cache_lock on;
第三方API可能会在其响应中返回自引用绝对链接(如分页链接),因此必须重写URLs来保证这些链接指向正确的网关:
sub_filter 'https:\/\/$proxy_host' '$scheme://$http_host'; sub_filter_last_modified on;
sub_filter_once off;
sub_filter_types application/json;
由于sub_filter不支持gzip响应,因此在重写URLs的时候需要禁用gzip响应:
# Required because sub_filter is incompatible with gzip reponses: proxy_set_header Accept-Encoding "";
回到一开始的配置,可以看到启用了proxy_cache_background_update,该标志会启用后台更新缓存功能,这种方式听起来不错,但也存在一些限制。
当一个客户端请求触发后台缓存更新(由于缓存状态为STALE)时,无需等待后台更新响应就会返回缓存的响应(设置proxy_cache_use_stale updating),但当Nginx后续接收到来自相同客户端连接上的请求时,需要在后台更新响应之后才会处理这些请求(参见ticket)。下面配置可以保证为每个请求都创建一条客户端连接,以此保证所有的请求都可以接收到过期缓存中的响应,不必再等待后台完成缓存更新。
# Required to ensure no request waits for background cache updates:
keepalive_timeout 0;
缺电是客户端需要为每个请求创建一个新的连接。在我们的场景中,成本要低得多,而且这种行为也比让一些客户端随机等待缓存刷新要可预测得多。
Kubernetes部署
上述Nginx配置被打包在了Nginx的非特权容器镜像中,并跟其他web应用一样部署在了Kubernetes集群中。Nginx配置中硬编码的值会通过Nginx容器镜像中的环境变量进行替换(参见Nginx容器镜像文档)。
集群中的网关通过Kubernetes Service进行访问,网关pod的数量是可变的。由于Nginx 缓存依赖本地文件系统,这给缓存持久化带来了问题。
非固定pod的缓存持久化
正如上面的配置中看到的,我们使用了一个非常长的缓存保留时间和一个非常短的缓存有效期来刷新数据(第三方可用的情况下),同时能够在第三方关闭或返回错误时继续使用旧数据提供服务。
我们需要不丢失缓存数据,并在Kubernetes pod扩容启动时能够使用缓存的数据。下面介绍了一种在所有Nginx实例之间共享持久化缓存的方式--通过在pod的本地缓存目录和S3 bucket之间进行同步来实现该功能。每个Nginx pod上除Nginx容器外还部署了两个容器,这两个容器共享了挂载在/mnt/cache路径下的本地卷emptyDir,两个容器都使用了AWS CLI容器镜像,并依赖内部Vault来获得与AWS通信的凭据。
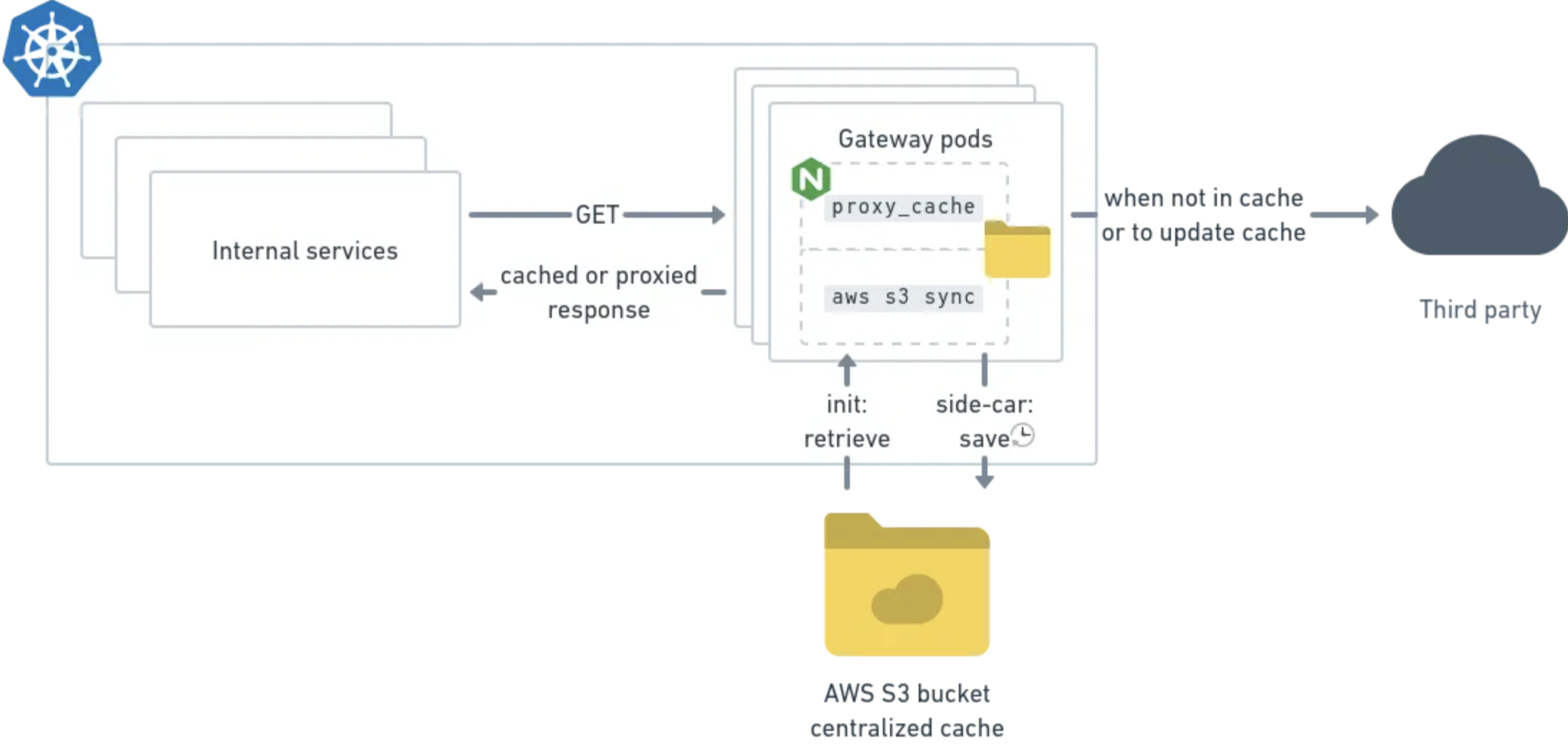
init容器会在Nginx启动前启动,负责在启动时将S3 bucket中保存的缓存拉取到本地。
aws s3 sync s3://thirdparty-gateway-cache /mnt/cache/complete
除此之外还会启动一个sidecar容器,用于将本地存储中的缓存数据保存到S3 bucket:
while true
do
sleep 600
aws s3 sync /mnt/cache/complete s3://thirdparty-gateway-cache
done
为了避免上传部分写缓存条目到bucket,使用了Nginx的use_temp_path 选项(使用该选项可以将):
proxy_cache_path /mnt/cache/complete ... use_temp_path=on;
proxy_temp_path /mnt/cache/tmp;
默认的aws s3 sync不会清理bucket中的数据,可以配置bucket回收策略:
<LifecycleConfiguration>
<Rule>
<ID>delete-old-entries</ID>
<Status>Enabled</Status>
<Expiration>
<Days>8</Days>
</Expiration>
</Rule>
</LifecycleConfiguration>
限制
如果可以接受最终一致性且请求是读密集的,那么这种解决方式是一个不错的选项。但它无法为很少访问的后端提供同等的价值,也不支持写请求(POST、DELETE等)。
鉴于使用了纯代理方式,因此它不支持在第三方的基础上提供抽象或自定义。
除非某种类型的客户端服务认证(如通过服务网格头)作为缓存密钥的一部分,否则会在所有客户端服务之间共享缓存结果。这种方式可以提高性能,但也会给需要多级认证来访问第三方数据的内部服务带来问题。我们的场景中不存在这种问题,因为生产数据对内部服务是公开的,且缓存带来的"认证共享"只会影响读请求。
在安全方面,还需要注意,任何可以访问bucket的人都可以读取甚至修改网关的响应。因此需要确保bucket是私有的,只有特定人员才能访问。
集中式的缓存存储会导致缓存共享(即所有pod会共享S3 bucket中的缓存,并在网关扩展时将缓存复制到pod中),因此这不是Nginx推荐的高可用共享缓存。未来我们会尝试实现Nginx缓存的主/备架构。
使用Kubernetes中的Nginx来改善第三方服务的可靠性和延迟的更多相关文章
- kubernetes下的Nginx加Tomcat三部曲之二:细说开发
本文是<kubernetes下的Nginx加Tomcat三部曲>的第二章,在<kubernetes下的Nginx加Tomcat三部曲之一:极速体验>一文我们快速部署了Nginx ...
- 关于 Kubernetes 中的 Volume 与 GlusterFS 分布式存储
容器中持久化的文件生命周期是短暂的,如果容器中程序崩溃宕机,kubelet 就会重新启动,容器中的文件将会丢失,所以对于有状态的应用容器中持久化存储是至关重要的一个环节:另外很多时候一个 Pod 中可 ...
- 苹果下如果安装nginx,给nginx安装markdown第三方插件
用brew install nginx 这样安装的是最新版的nginx, 但是在有些情况下,安装第三方插件需要特定的版本,更高一级的版本可能装不上. 它的原理是下载安装包进行自动安装,建立软链,这样就 ...
- 《深入理解Nginx》阅读与实践(三):使用upstream和subrequest访问第三方服务
本文是对陶辉<深入理解Nginx>第5章内容的梳理以及实现,代码和注释基本出自此书. 一.upstream:以向nginx服务器的请求转化为向google服务器的搜索请求为例 (一)模块框 ...
- 【转】干货,Kubernetes中的Source Ip机制。
准备工作 你必须拥有一个正常工作的 Kubernetes 1.5 集群,用来运行本文中的示例.该示例使用一个简单的 nginx webserver 回送它接收到的请求的 HTTP 头中的源 IP 地址 ...
- kubernetes中的Pause容器如何理解?
前几篇文章都是讲的Kubernetes集群和相关组件的部署,但是部署只是入门的第一步,得理解其中的一些知识才行.今天给大家分享下Kubernets的pause容器的作用. Pause容器 全称infr ...
- Java进阶——带你入门分布式中的Nginx
如何实现服务器之间的协同功能呢? 通过 Nginx 提供的反向代理和负载均衡功能,可以合理的完成业务的分配,提高网站的处理能力:同时利用缓存功能,还可以将不需要实时更新的动态页面输出结果,转化为静态网 ...
- Kubernetes 中的核心组件与基本对象概述
Kubernetes 是 Google 基于 Borg 开源的容器编排调度,用于管理容器集群自动化部署.扩容以及运维的开源平台.作为云原生计算基金会 CNCF(Cloud Native Computi ...
- Kubernetes中的Configmap和Secret
本文的试验环境为CentOS 7.3,Kubernetes集群为1.11.2,安装步骤参见kubeadm安装kubernetes V1.11.1 集群 应用场景:镜像往往是一个应用的基础,还有很多需要 ...
- kubernetes下的Nginx加Tomcat三部曲之一:极速体验
在生产环境中,常用到Nginx加Tomcat的部署方式,如下图: 从本章开始,我们来实战kubernetes下部署上述Nginx和Tomcat服务,并开发spring boot的web应用来验证环境, ...
随机推荐
- GO语言内存操作指导—unsafe的使用
在unsafe包里面,官方的说明是:A uintptr is an integer, not a reference.Converting a Pointer to a uintptr creates ...
- ctfshow web入门部分题目 (更新中)
CTFSHOW(WEB) web入门 给她 1 参考文档 https://blog.csdn.net/weixin_51412071/article/details/124270277 查看链接 sq ...
- Linux 基础-查看 cpu、内存和环境等信息
Linux 基础-查看 cpu.内存和环境等信息 在使用 Linux 系统的过程中,我们经常需要查看系统.资源.网络.进程.用户等方面的信息,查看这些信息的常用命令值得了解和熟悉. 1,系统信息查看常 ...
- Aspose.Cells设置单元格背景色不生效
Style.BackgroundColor property 获取或设置样式的背景颜色.public Color BackgroundColor { get; set; } 评论 如果要设置单元格的颜 ...
- uboot引导应用程序
uboot默认是支持执行应用程序的,就像引导内核一样,我们也可以自己写一个应用程序,让uboot启动时引导. 在uboot examples/standalone 目录下,有hello_world.c ...
- postgresql函数:定期删除模式下指定天数前的表数据及分区物理表
一.现有函数-- 1.现有函数调用select ods.deletePartitionIfExists('fact_ship' || '_' || to_char(CURRENT_DATE - INT ...
- 10分钟看懂Docker和K8S,docker k8s 区别
10分钟看懂Docker和K8S,docker k8s 区别 2010年,几个搞IT的年轻人,在美国旧金山成立了一家名叫"dotCloud"的公司. 这家公司主要提供基于PaaS的 ...
- 1.5 HDFS分布式文件系统-hadoop-最全最完整的保姆级的java大数据学习资料
目录 1.5 HDFS分布式文件系统 1.5.1 HDFS 简介 1.5.2 HDFS的重要概念 1.5.3 HDFS架构 1.5 HDFS分布式文件系统 1.5.1 HDFS 简介 HDFS(全称: ...
- uniapp(vue)实现点击左侧菜单,右侧显示对应的内容
<template> <view class="container"> <view class="fication-search" ...
- 和月薪3W的聊过后,才知道自己一直在打杂...
前几天和一个朋友聊面试,他说上个月同时拿到了腾讯和阿里的offer,最后选择了阿里. 我了解了下他的面试过程,就一点,不管是阿里还是腾讯的面试,这个级别的程序员,都会考察项目管理能力,并且权重非常大. ...